一般的抓取网页的使用 beautifulsoup就足够了,只有做复杂的爬虫类的应用才需要用到PySpider等类型的框架。下面给出直接用python源码写的抓取新浪爱彩双色球开奖数据的代码。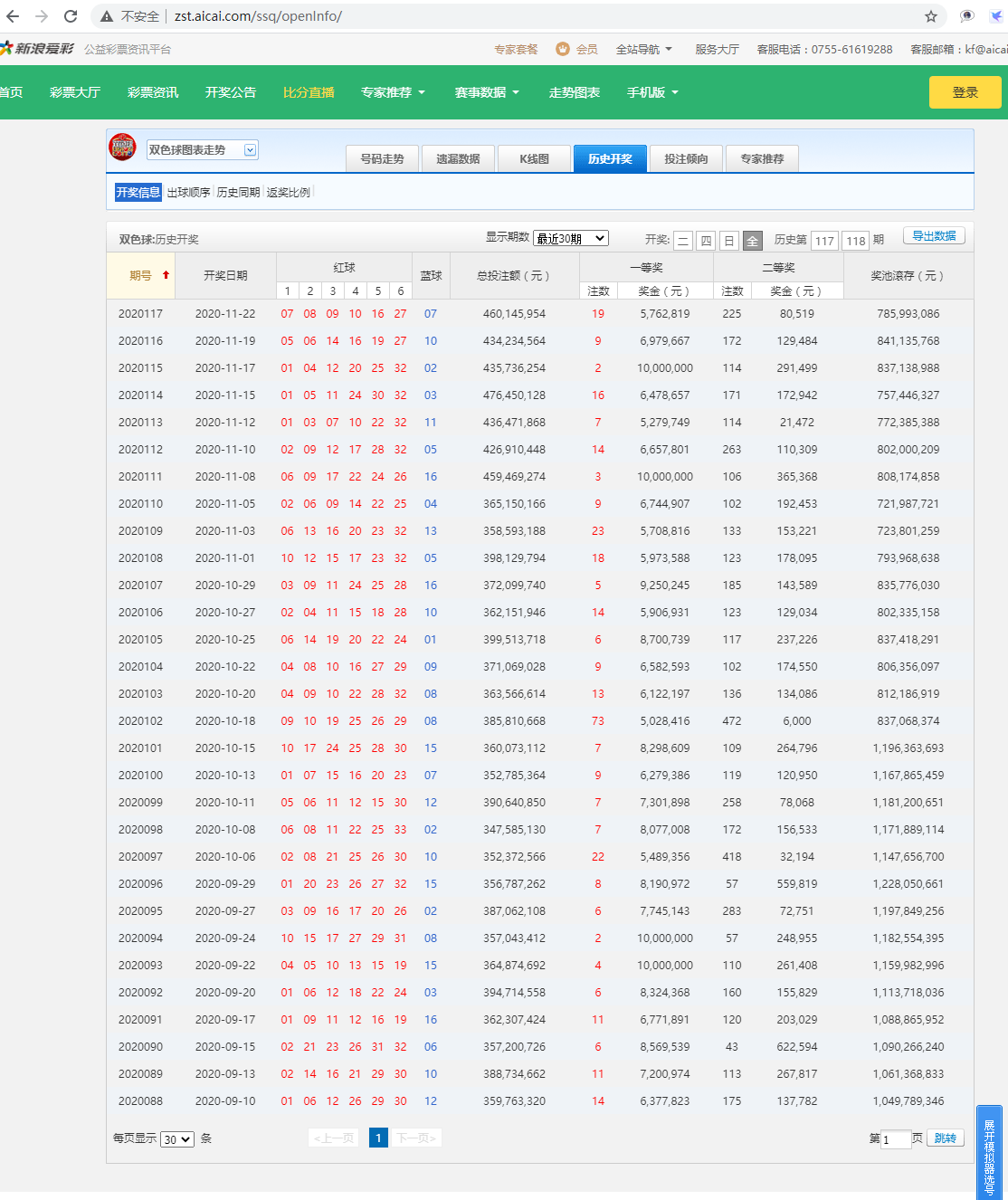
import urllib.requestimport urllib.parseimport http.cookiejardef getHtml(url):cj = http.cookiejar.CookieJar()opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))opener.addheaders = [('User-Agent','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.101 Safari/537.36'),('Cookie', '4564564564564564565646540')]urllib.request.install_opener(opener)html_bytes = urllib.request.urlopen(url).read()html_string = html_bytes.decode('utf-8')return html_string# 获取网页的HTML内容html = getHtml("http://zst.aicai.com/ssq/openInfo/")# 开奖信息在表格中,获取表格<table class="fzTab nbt"></table>中的数据table = html[html.find('<table class="fzTab nbt">'): html.find('</table>')]print(table) # 查看获取到的表格中的数据
table = html[html.find('<table class="fzTab nbt">'): html.find('</table>')]
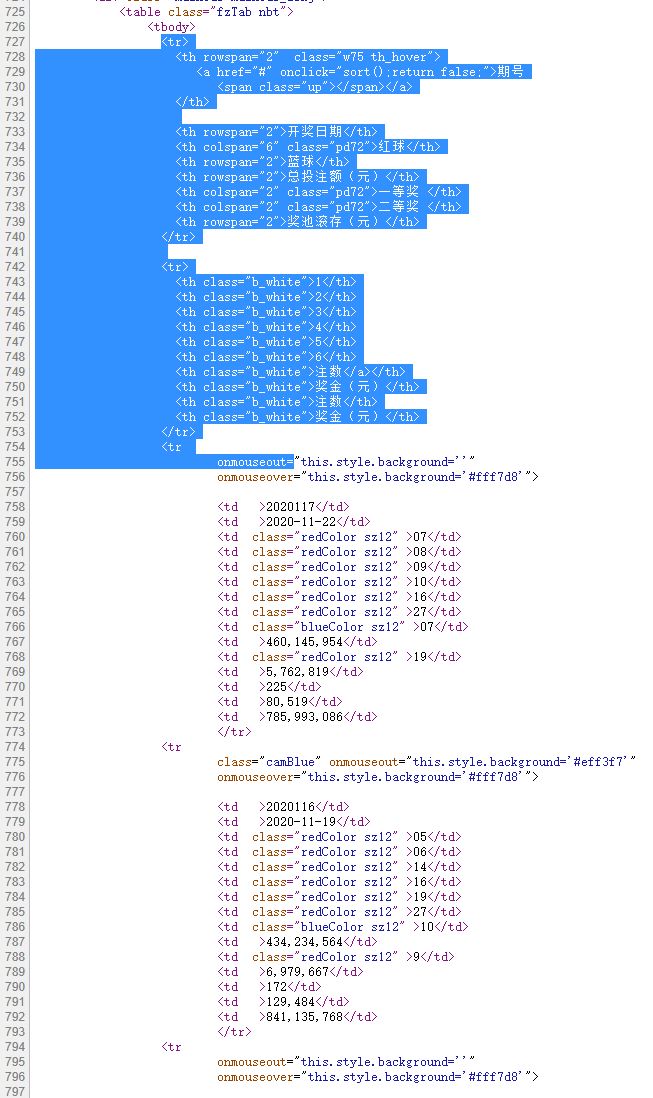
# 根据'<tr \r\n\t\t onmouseout=' 将得到的字符串切分为列表tmp = table.split('<tr \r\n\t\t onmouseout=')print(tmp[1])
"this.style.background=''"onmouseover="this.style.background='#fff7d8'"><td >2020134</td><td >2020-12-31</td><td class="redColor sz12" >02</td><td class="redColor sz12" >09</td><td class="redColor sz12" >10</td><td class="redColor sz12" >20</td><td class="redColor sz12" >22</td><td class="redColor sz12" >26</td><td class="blueColor sz12" >01</td><td >399,565,532</td><td class="redColor sz12" >48</td><td >5,382,786</td><td >275</td><td >83,517</td><td >704,501,324</td></tr><trclass="camBlue" onmouseout="this.style.background='#eff3f7'"onmouseover="this.style.background='#fff7d8'"><td >2020133</td><td >2020-12-29</td><td class="redColor sz12" >03</td><td class="redColor sz12" >19</td><td class="redColor sz12" >22</td><td class="redColor sz12" >23</td><td class="redColor sz12" >27</td><td class="redColor sz12" >29</td><td class="blueColor sz12" >07</td><td >370,330,222</td><td class="redColor sz12" >3</td><td >10,000,000</td><td >99</td><td >283,877</td><td >893,973,468</td></tr>
# 获取</tr>以前的第一行数据
tr = tmp[: tmp.find('</tr>')]
print(tr)
"this.style.background=''"
onmouseover="this.style.background='#fff7d8'">
<td >2020117</td>
<td >2020-11-22</td>
<td class="redColor sz12" >07</td>
<td class="redColor sz12" >08</td>
<td class="redColor sz12" >09</td>
<td class="redColor sz12" >10</td>
<td class="redColor sz12" >16</td>
<td class="redColor sz12" >27</td>
<td class="blueColor sz12" >07</td>
<td >460,145,954</td>
<td class="redColor sz12" >19</td>
<td >5,762,819</td>
<td >225</td>
<td >80,519</td>
<td >785,993,086</td>
# 获取当前多少期,根据'<td >'切分为列表
# 序号为1的是最新一期数据
new_number = tr.split('<td >')[1]
print(new_number) # 2020117</td>
new_number = new_number.split('</td>')[0]
print(new_number) # 2020117
print(new_number + '期开奖号码:', end='') # 2020117期开奖号码:
2020117</td>
2020117
2020117期开奖号码:
# 根据'<td class="redColor sz12" >'切分,获得红色球号码
redtmp = tr.split('<td class="redColor sz12" >')
print(redtmp)
['"this.style.background=\'\'"\r\n\t\t onmouseover="this.style.background=\'#fff7d8\'">\r\n\t\t \r\n\t\t <td >2020117</td>\r\n\t\t <td >2020-11-22</td>\r\n\t\t ',
'07</td>\r\n\t\t ',
'08</td>\r\n\t\t ',
'09</td>\r\n\t\t ',
'10</td>\r\n\t\t ',
'16</td>\r\n\t\t ',
'27</td>\r\n\t\t <td class="blueColor sz12" >07</td>\r\n\t\t <td >460,145,954</td>\r\n\t\t ',
'19</td>\r\n\t\t <td >5,762,819</td>\r\n\t\t <td >225</td>\r\n\t\t <td >80,519</td>\r\n\t\t <td >785,993,086</td>\r\n\t\t ']
# 去掉第一个和最后一个没用的元素
reds = redtmp[1:len(redtmp) - 1]
print(reds)
['07</td>\r\n\t\t ',
'08</td>\r\n\t\t ',
'09</td>\r\n\t\t ',
'10</td>\r\n\t\t ',
'16</td>\r\n\t\t ',
'27</td>\r\n\t\t <td class="blueColor sz12" >07</td>\r\n\t\t <td >460,145,954</td>\r\n\t\t ']
# 遍历reds列表,取出红色球号码,置于列表中
red_number = [redstr.split('</td>')[0] for redstr in reds]
print(*red_number)
07 08 09 10 16 27
# 获取蓝色球数字
print('蓝球:', end='')
blue = tr.split('<td class="blueColor sz12" >')[1].split('</td>')[0]
print(blue)
蓝球:07
完整代码如下:
import urllib.request
import urllib.parse
import http.cookiejar
def getHtml(url):
cj = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
opener.addheaders = [('User-Agent',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.101 Safari/537.36'),
('Cookie', '4564564564564564565646540')]
urllib.request.install_opener(opener)
html_bytes = urllib.request.urlopen(url).read()
html_string = html_bytes.decode('utf-8')
return html_string # 返回网页的HTML内容
# 最终输出结果格式如:2018134期开奖号码:03,16,18,31,32,33,蓝球:12
html_content = getHtml("http://zst.aicai.com/ssq/openInfo/") # 网页的HTML内容
# print(html)
# 开奖信息在表格中,获取表格中的数据
table = html_content[html_content.find('<table class="fzTab nbt">'): html_content.find('</table>')]
# print(table)
# 根据'<tr \r\n\t\t onmouseout=' 将得到的字符串切分为列表,取序号为1的元素
tmp = table.split('<tr \r\n\t\t onmouseout=')[1]
# print(tmp)
# 获取</tr>以前的第一行数据
tr = tmp[: tmp.find('</tr>')]
# print(tr)
# 获取当前多少期,根据'<td >'切分为列表
# 序号为1的是最新一期数据
new_number = tr.split('<td >')[1]
# print(new_number) # 2020117</td>
new_number = new_number.split('</td>')[0]
# print(new_number) # 2020117
print(new_number + '期开奖号码:', end='') # 2020117期开奖号码:
# 根据'<td class="redColor sz12" >'切分,获得红色球号码
redtmp = tr.split('<td class="redColor sz12" >')
# print(redtmp)
# 去掉第一个和最后一个没用的元素
reds = redtmp[1:len(redtmp) - 1]
# print(reds)
# 遍历reds列表,取出红色球号码,置于列表中
red_number = [redstr.split('</td>')[0] for redstr in reds]
print(*red_number)
# 获取蓝色球数字
print('蓝球:', end='')
blue = tr.split('<td class="blueColor sz12" >')[1].split('</td>')[0]
print(blue)
输出:
2020117期开奖号码:07 08 09 10 16 27
蓝球:07
2020134期开奖号码:02 09 10 20 22 26
蓝球:01

若有收获,就点个赞吧
0 人点赞
