1. 计算股票涨跌幅
涨跌幅=(最新记录收盘价-最早记录收盘价) / 最早记录收盘价 * 100
输入
最新记录收盘价
最早记录收盘价
输出
涨跌幅
new_close = float(input())old_close = float(input())up_lift = (new_close - old_close) / new_closeprint(f'涨跌幅为{up_lift * 100:.2f}%')# 8.75574016571045# 7.861959934234619# 涨跌幅为10.21%
2.分别计算股票涨幅与跌幅
new_close = float(input())old_close = float(input())up_lift = (new_close - old_close) / new_closeif up_lift >= 0:print(f'涨幅为{up_lift * 100:.2f}%')else:print(f'跌幅为{abs(up_lift) * 100:.2f}%')# 8.75574016571045# 7.861959934234619# 涨幅为10.21%# 7.861959934234619# 9.508830070495605# 跌幅为20.95%
3.股票收益计算
某股票发行价为7.14元,自登陆创业板上市以来,经历了29个涨停(每天涨幅10%)。某君在7.14元时购买1万股,输入一个29以内的整数 n 表示天数,计算第n天收盘时某君的持有股票的帐面资产。
n = int(input())for i in range(1,n+1):facevalue = 7.14 * 10000 * (1 + 0.1) ** iprint(f'第{i}个交易日帐面金额为{facevalue:.2f}')
28第1个交易日帐面金额为78540.00第2个交易日帐面金额为86394.00第3个交易日帐面金额为95033.40第4个交易日帐面金额为104536.74第5个交易日帐面金额为114990.41第6个交易日帐面金额为126489.46第7个交易日帐面金额为139138.40第8个交易日帐面金额为153052.24第9个交易日帐面金额为168357.47第10个交易日帐面金额为185193.21第11个交易日帐面金额为203712.53第12个交易日帐面金额为224083.79第13个交易日帐面金额为246492.16第14个交易日帐面金额为271141.38第15个交易日帐面金额为298255.52第16个交易日帐面金额为328081.07第17个交易日帐面金额为360889.18第18个交易日帐面金额为396978.10第19个交易日帐面金额为436675.91第20个交易日帐面金额为480343.50第21个交易日帐面金额为528377.85第22个交易日帐面金额为581215.63第23个交易日帐面金额为639337.19第24个交易日帐面金额为703270.91第25个交易日帐面金额为773598.00第26个交易日帐面金额为850957.80第27个交易日帐面金额为936053.59第28个交易日帐面金额为1029658.94
4.股票涨跌幅计算
股票涨跌幅=(售出时股价-购买时股价) / 购买时股价 * 100。<br />某股票发行价为7.14元,登陆创业板上市。某君在7.14元时购买入,在327元时抛售,计算某君的持有股票的涨幅。
up_lift = (327 - 7.14) / 327 * 100
print(up_lift) # 97.81651376146789
5.数值字符串转数值列表
输入一个用逗号分隔的多个浮点数,切分为列表并将元素转为数值类型
data_str = input()
data_ls = data_str.split(',')
data_ls_float = list(map(float,data_ls))
print(data_ls_float)
# 9.020569801330566,8.648159980773926,8.689539909362793,8.81367015838623,556497760.0,5.469565391540527
# [9.020569801330566, 8.648159980773926, 8.689539909362793, 8.81367015838623, 556497760.0, 5.469565391540527]
列表推导式实现
data_str = input()
data_ls = data_str.split(',')
data_ls_float = [float(x) for x in data_ls]
print(data_ls_float)
简洁代码
data_ls_float = [float(x) for x in input().split(',')]
data_ls_float = list(map(float,input().split(',')))
print(data_ls_float)
6.读文件中的数据到二维列表
stock_ls = []
with open('../data/csv/stock/600000.csv') as data:
for line in data:
stock_ls.append(line.strip().split(','))
print(stock_ls)
列表推导式实现
with open('../data/csv/stock/600000.csv') as data:
stock_ls = [line.strip().split(',') for line in data]
print(stock_ls)
7.读文件到二维列表转数值类型
with open('../data/csv/stock/600000.csv') as data:
stock_ls = [line.strip().split(',') for line in data]
stock_float = [stock_ls[0]] # 保留标题行
for x in stock_ls[1:]: # 略过标题行,遍历数据部分
stock_float.append([x[0]] + list(map(float, x[1:]))) # 日期列保持字符串类型
print(stock_float)
输出
[['Date', 'High', 'Low', 'Open', 'Close', 'Volume', 'Adj Close'],
['2010-01-04', 9.049530029296875, 8.75574016571045, 9.032979965209961, 8.768150329589844, 159964607.0, 5.441317081451416],
['2010-01-05', 8.929530143737793, 8.602640151977539, 8.859189987182617, 8.834360122680664, 278278034.0, 5.4824042320251465],
['2010-01-06', 8.81367015838623, 8.639880180358887, 8.809530258178711, 8.66057014465332, 233894449.0, 5.3745551109313965],
...
8.读多个文件到二维列表
import os
def file_list():
"""将多个文件中的股票数据读入到列表中,返回二维列表。 """
stock_data = []
for stock in code_list:
with open(path_of_stock + stock, 'r', encoding='utf-8') as stock_file:
stock_data.append([line.strip().split(',') for line in stock_file])
return stock_data
def filename_list(path):
"""接收路径字符串为参数,获取该路径下所有文件名,以列表形式返回
os.listdir(path)以列表形式返回path路径下的所有文件名,不包括子路径中的文件名"""
name_list = os.listdir(path)
return name_list
if __name__ == '__main__':
path_of_stock = 'F:\\weiyun\\2020\\data\\csv\\sample\\' # \\转义字符\
code_list = filename_list(path_of_stock)
print(file_list())
9.创建股票代码字典
import os
def file_list():
"""将多个文件中的股票数据读入到列表中,返回二维列表。 """
stock_data = {}
with open(path_of_stock + '沪市股票top300.csv', 'r', encoding='utf-8') as stock_file:
for line in stock_file:
ls = line.strip().split(',')
stock_data[ls[0]] = ls[1]
return stock_data
if __name__ == '__main__':
path_of_stock = 'F:\\weiyun\\2020\\data\\csv\\stock\\' # \\转义字符\
print(file_list())
{'600000': '浦发银行', '600004': '白云机场', '600006': '东风汽车', '600007': '中国国贸', '600008': '首创股份', '600009': '上海机场', '600010': '钢联股份', ...
'600400': '红豆股份'}
10.股票分析
文件’沪市股票top300.csv’中包含上海股票交易所上市的多支股票的名称和股票代码,其他文件为文件名对应股票代码的股票交易数据,使用这些文件进行运算并输出结果,如跌幅最大的10支股票代码的集合、成交量最大的10支股票代码集合、最高价最高的10支股票代码的集合、最低价最低的10支股票代码集合等。(为方便统计,本题中涨跌幅计算公式设定为:(最新记录收盘价-最早记录收盘价) / 最早记录收盘价 * 100。)
交易数据文件数据内容格式为:
Date,High,Low,Open,Close,Volume,Adj Close
2018-01-02,5.929999828338623,5.829999923706055,5.860000133514404,5.909999847412109,10649302.0,5.6797099113464355
2018-01-03,5.989999771118164,5.820000171661377,5.880000114440918,5.909999847412109,14893773.0,5.6797099113464355
2018-01-04,5.889999866485596,5.829999923706055,5.869999885559082,5.849999904632568,9974470.0,5.622048854827881
2018-01-05,5.880000114440918,5.820000171661377,5.849999904632568,5.849999904632568,6584055.0,5.622048854827881
2018-01-08,5.929999828338623,5.860000133514404,5.860000133514404,5.920000076293945,11096694.0,5.689321041107178
... ...
根据用户输入,利用集合运算和这些文件数据完成以下任务:
输入’涨幅与成交量’时:
参考示例格式输出:
涨幅和成交量均在前10名的股票:
涨幅或成交量在前10名的股票:
涨幅前10名,但成交量未进前10名的股票:
涨幅和成交量不同时在前10名的股票:
输入’涨幅与最高价’时:
参考示例格式输出:
涨幅和最高价均在前10名的股票:
涨幅或最高价在前10名的股票:
涨幅前10名,但最高价未进前10名的股票:
涨幅和最高价不同时在前10名的股票:
输入’跌幅与最低价’时:
参考示例格式输出:
跌幅和最低价均在前10名的股票:
跌幅或最低价在前10名的股票:
跌幅前10名,但最低价未进前10名的股票:
跌幅和最低价不同时在前10名的股票:
输入其他数据时:
输出:’输入错误’
# -------- ------- --------
# @File : 股票分析.py
# @Author : 赵广辉
# @Contact: vasp@qq.com
# @Company: 武汉理工大学
# @Version: 1.5
# @Modify : 2021/12/06 21:28
# Python程序设计基础,高等教育出版社
# -------- ------- --------
import os
import numpy as np
# 设置常量,对应各列数据的语义,方便索引
HIGH = 0
LOW = 1
OPEN = 2
CLOSE = 3
VOLUME = 4
ADJCLOSE = 5
def file_list(file):
"""
@参数 file: 文件名,字符串类型
将文件中的股票代码与股票名称读入到字典中,返回股票代码字典。
['600000', '600004', '600006', '600007', '600008', '600009',...]
"""
stock_name = {}
with open(file, 'r', encoding='utf-8') as stock_file:
for line in stock_file:
x = line.strip().split(',')
stock_name[x[0]] = x[1]
return stock_name # 股票代码与股票名字典
def filename_list(path):
"""接收路径字符串为参数,获取该路径下所有文件名,以列表形式返回
os.listdir(path)以列表形式返回path路径下的所有文件名,不包括子路径中的文件名"""
name_list = os.listdir(path)
return name_list
def statistics_of_all(code_list):
"""
@参数 code_list:股票代码列表,列表类型
接收股票数据文件名列表,逐个统计各股票数据文件涨跌幅、总成交量、最高价和最低价。
涨跌幅计算公式为:(最新记录收盘价-最早记录收盘价) / 最早记录收盘价 * 100
为方便处理,读入数据时,略过日期列。
"""
statistics_of_stock = []
for code in code_list:
data_of_code = np.genfromtxt('../data/' + code, dtype=None,
usecols=[1, 2, 3, 4, 5, 6], delimiter=',',
skip_header=1)
# 计算当前股票涨跌幅、总成交量、最高价和最低价
uplift_or_fall = round((data_of_code[:, CLOSE][-1] - data_of_code[:, CLOSE][0]) / data_of_code[:, CLOSE][0] * 100, 2)
volumes = round(sum(data_of_code[:, VOLUME]), 2)
high = round(max(data_of_code[:, HIGH]), 2)
low = round(min(data_of_code[:, LOW]), 2)
statistics_of_stock.append([code[:6], uplift_or_fall, volumes, high, low])
return statistics_of_stock # 每支股票涨跌幅、总成交量、最高价和最低价
def top_10_uplift(statistics_of_stock):
"""
@参数 statistics_of_stock:每支股票涨跌幅、总成交量、最高价和最低价统计信息,列表类型
按涨幅降序排序,涨幅相同时按股票代码降序排序,取排名前10的股票,
返回排名前10的股票代码,返回值为列表类型。
"""
sort_by_uplift = sorted(statistics_of_stock, key=lambda x: (x[1], x[0]), reverse=True)[:10]
top_uplift = [x[0] for x in sort_by_uplift]
return top_uplift
def top_10_fall(statistics_of_stock):
"""
@参数 statistics_of_stock:每支股票涨跌幅、总成交量、最高价和最低价统计信息,列表类型
按跌幅升序排序,跌幅相同时,按股票代码升序排序,取排名前10的股票,返回跌幅最大的10支股
票代码的集合。
"""
sort_by_fall = sorted(statistics_of_stock, key=lambda x: (x[1], x[0]))[:10]
top_fall = [x[0] for x in sort_by_fall]
return top_fall
def top_10_volumes(statistics_of_stock):
"""
@参数 statistics_of_stock:每支股票涨跌幅、总成交量、最高价和最低价统计信息,列表类型
按成交量降序排序,成交量相同时,按股票代码降序排序,取成交量前10的股票代码,返回成交量
最大的10支股票代码列表。
"""
sort_by_volumes = sorted(statistics_of_stock, key=lambda x: (x[2], x[0]))[-1:-11:-1]
top_volumes = [x[0] for x in sort_by_volumes]
return top_volumes
def top_10_high(statistics_of_stock):
"""
@参数 statistics_of_stock:每支股票涨跌幅、总成交量、最高价和最低价统计信息,列表类型
按最高价降序排序,最高价相同时,按股票代码降序排序返回,取排名前10的股票,返回最高价最
高的10支股票代码的列表。
"""
sort_by_high = sorted(statistics_of_stock, key=lambda x: (x[3], x[0]))[-1:-11:-1]
top_high = [x[0] for x in sort_by_high]
return top_high
def top_10_low(statistics_of_stock):
"""
@参数 statistics_of_stock:每支股票涨跌幅、总成交量、最高价和最低价统计信息,列表类型
按最低价升序排序,最低价相同时,按股票代码升序排序,取排名前10的股票,返回最低价最低的
10支股票代码集合。
"""
sort_by_low = sorted(statistics_of_stock, key=lambda x: (x[4], x[0]))[:10]
top_low = [x[0] for x in sort_by_low]
return top_low
def uplift_and_volumes(top_uplift, top_volumes):
"""
@参数 top_high,最高价在前10名的股票代码,字符串
@参数 top_volumes,成交量在前10名的股票代码,字符串
返回一个列表,其元素依序为以下4个:
涨幅和成交量均在前10名的股票,按股票代码升序,列表
涨幅或成交量在前10名的股票,按股票代码升序,列表
涨幅前10名,但成交量未进前10名的股票,按股票代码升序,列表
涨幅和成交量不同时在前10名的股票,按股票代码升序,列表
"""
both_of = sorted(set(top_uplift) & set(top_volumes))
any_of = sorted(set(top_uplift) | set(top_volumes))
uplift_no_volumes = sorted(set(top_uplift) - set(top_volumes))
uplift_or_volumes = sorted(set(top_uplift) ^ set(top_volumes))
# print(both_of,any_of,uplift_no_volumes,uplift_or_volumes)
return [both_of,any_of,uplift_no_volumes,uplift_or_volumes]
def high_and_uplift(top_uplift, top_high):
"""
@参数 top_high,最高价在前10名的股票代码,字符串
@参数 top_uplift,涨幅在前10名的股票代码,字符串
返回一个列表,其元素依序为以下4个:
涨幅和最高价均在前10名的股票代码,按股票代码升序,列表
涨幅或最高价在前10名的股票代码,按股票代码升序,列表
涨幅前10名,但最高价未进前10名的股票代码,按股票代码升序,列表
涨幅和最高价不同时在前10名的股票,按股票代码升序,列表
票代码。
"""
both_of = sorted(set(top_uplift) & set(top_high)) # 涨幅和最高价均在前10名的股票
any_of = sorted(set(top_uplift) | set(top_high)) # 涨幅或最高价在前10名的股票
uplift_no_high = sorted(set(top_uplift) - set(top_high)) # 涨幅前10名,但最高价未进前10名的股票
uplift_or_high = sorted(set(top_uplift) ^ set(top_high)) # 涨幅和最高价不同时在前10名的股票
return [both_of, any_of, uplift_no_high, uplift_or_high]
def low_and_fall(top_fall, top_low):
"""
@参数 top_low,最低价在前10名的股票代码,字符串
@参数 top_fall,跌幅在前10名的股票代码,字符串
返回一个列表,其元素依序为以下4个
跌幅和最低价均在前10名的股票代码,按股票代码升序,列表
跌幅或最低价在前10名的股票代码,按股票代码升序,列表
跌幅前10名,但最低价未进前10名的股票代码,按股票代码升序,列表
跌幅和最低价不同时在前10名的股票,按股票代码升序,列表
"""
both_of = sorted(set(top_fall) & set(top_low)) # 跌幅和最低价均在前10名的股票
any_of = sorted(set(top_fall) | set(top_low)) # 跌幅或最低价在前10名的股票
uplift_no_high = sorted(set(top_fall) - set(top_low)) # 跌幅前10名,但最低价未进前10名的股票
uplift_or_high = sorted(set(top_fall) ^ set(top_low)) # 跌幅和最低价不同时在前10名的股票
return [both_of, any_of, uplift_no_high, uplift_or_high]
def operation():
"""接收一个字符串为参数,根据参数值调用不同函数完成任务"""
statistics_of_list = statistics_of_all(stock_lst) # 对获取的股票数据进行统计
uplift_set = top_10_uplift(statistics_of_list) # 涨幅前10名集合
fall_set = top_10_fall(statistics_of_list) # 跌幅前10名集合
volumes_set = top_10_volumes(statistics_of_list) # 成交量前10名集合
high_set = top_10_high(statistics_of_list) # 最高价前10名集合
low_set = top_10_low(statistics_of_list) # 最低价前10名集合
opt = input()
if opt == '涨幅与成交量': # 输出抽中的单词
u_and_v = uplift_and_volumes(uplift_set, volumes_set)
print('涨幅和成交量均在前10名的股票:')
print(u_and_v[0]) # 涨幅和成交量均在前10名的股票
print('涨幅或成交量在前10名的股票:')
print(u_and_v[1]) # 涨幅或成交量在前10名的股票
print('涨幅前10名,但成交量未进前10名的股票:')
print(u_and_v[2]) # 涨幅前10名,但成交量未进前10名的股票
print('涨幅和成交量不同时在前10名的股票:')
print(u_and_v[3]) # 涨幅和成交量均在前10名的股票
elif opt == '涨幅与最高价':
u_and_h = high_and_uplift(uplift_set, high_set)
print('涨幅和最高价均在前10名的股票:')
print(u_and_h[0])
print('涨幅或最高价在前10名的股票:')
print(u_and_h[1])
print('涨幅前10名,但最高价未进前10名的股票:')
print(u_and_h[2])
print('涨幅和最高价不同时在前10名的股票:')
print(u_and_h[3])
elif opt == '跌幅与最低价':
f_and_l = low_and_fall(fall_set, low_set)
print('跌幅和最低价均在前10名的股票:')
print(f_and_l[0]) # 跌幅和最低价均在前10名的股票
print('跌幅或最低价在前10名的股票:')
print(f_and_l[1]) # 跌幅或最低价在前10名的股票
print('跌幅前10名,但最低价未进前10名的股票:')
print(f_and_l[2]) # 跌幅前10名,但最低价未进前10名的股票
print('跌幅和最低价不同时在前10名的股票:')
print(f_and_l[3]) # 跌幅前10名,但最低价未进前10名的股票,和最低价前10名但跌幅没进前10名的股票
else:
print('输入错误')
if __name__ == '__main__':
filename = './data/沪市股票top300.csv' # 股票名称与代码文件
stock_lst = ['600000.csv', '600004.csv', '600006.csv',
'600007.csv', '600008.csv', '600009.csv',
'600010.csv', '600011.csv', '600012.csv',
'600015.csv', '600016.csv', '600018.csv',
'600019.csv', '600020.csv', '600026.csv',
'600028.csv', '600029.csv', '600030.csv',
'600031.csv', '600033.csv', '600036.csv']
operation()
11.蒙特卡洛模拟股票价格
在金融工程中,有下面这样一个公式,他利用目前的股价  去预测
去预测  时间之后的股价
时间之后的股价  :
:
这其中的参数我来解释一下: 表示股票收益率的期望值,这里我们设定为
表示股票收益率的期望值,这里我们设定为  ,即
,即 
 表示股票的波动率,这里设定为
表示股票的波动率,这里设定为 
 ,其中
,其中  表示整数年份,
表示整数年份,  表示在整个估算周期内,取的具体步数,就好比说
表示在整个估算周期内,取的具体步数,就好比说  为一年,
为一年,  如果取244,那么
如果取244,那么  的粒度就是每个交易日了(一年有244个交易日)。
的粒度就是每个交易日了(一年有244个交易日)。
这里面似乎所有的参数都是确定的,唯独除了  之外,
之外,  是一个服从标准正态分布的随机变量,这是这个
是一个服从标准正态分布的随机变量,这是这个  ,决定了每日的股价
,决定了每日的股价  是一个随机变量,而由股价构成的序列是一个随机过程。
是一个随机变量,而由股价构成的序列是一个随机过程。
我们同样的用蒙特卡罗方法,利用大样本来估计一下在目前股价为  的情况下,1年之后股价的概率分布情况。
的情况下,1年之后股价的概率分布情况。
import math
import numpy as np
import matplotlib.pyplot as plt
s0 =10.0
T = 1.0
n = 244 * T
mu=0.15
sigma = 0.2
n_simulation = 1000
dt = T/n
s_array = []
for i in range(n_simulation):
s = s0
for j in range(int(n)):
e = np.random.randn()
s = s+mu*s*dt+sigma*s*e*math.sqrt(dt)
s_array.append(s)
plt.hist(s_array,bins=30, edgecolor='k')
plt.show()
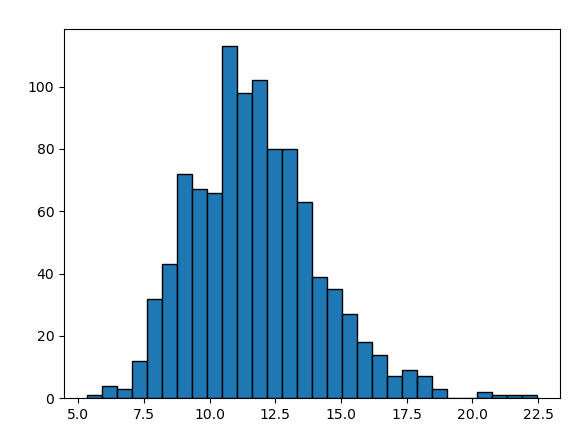
这是我们模拟了10000个样本经过上述随机过程,在一年之后股价的分布情况。
这里的核心就是:
e = numpy.random.randn()
s = s+mu*s*dt+sigma*s*e*math.sqrt(dt)
每一轮  ,我们都生成一个服从标准正态分布的随机变量
,我们都生成一个服从标准正态分布的随机变量  ,不断通过递推公式
,不断通过递推公式 ,迭代出下一个时间点的股价,循环往复直到生成一年后的最终结果,这样就模拟出了一年过程中股价随机变量序列构成的随机过程。
,迭代出下一个时间点的股价,循环往复直到生成一年后的最终结果,这样就模拟出了一年过程中股价随机变量序列构成的随机过程。
我们采用蒙特卡罗方法,设置大样本量(这里设置10000个),最终迭代出10000个对应的一年后股价,然后用柱状图就能看出其总体分布特征。
股价变化曲线的过程展现
上面我们分析的是这10000个样本在一年之后最终股价的整体分布情况,实际上我们还有一个同样重要的过程可以进行监测和展现,那就是从  时刻起到1年后的这一段时间内,每隔
时刻起到1年后的这一段时间内,每隔  时间间隔点由实时价格随机变量构成的序列,换句话说就是随机过程的整体展现。这个在上面的基础上进一步完成,其实不难,就是我们不光要计算出股票最终的价格,还有记录下每个
时间间隔点由实时价格随机变量构成的序列,换句话说就是随机过程的整体展现。这个在上面的基础上进一步完成,其实不难,就是我们不光要计算出股票最终的价格,还有记录下每个  时间点的价格,并把他记录下来。
时间点的价格,并把他记录下来。
import math
import numpy as np
import matplotlib.pyplot as plt
s0 = 10.0
T = 1.0
n = 244 * T
mu = 0.15
sigma = 0.2
n_simulation = 100
dt = T / n
random_series = np.zeros(int(n), dtype=float)
x = range(0, int(n))
for i in range(n_simulation):
random_series[0] = s0
for j in range(1, int(n)):
e = np.random.randn()
random_series[j] = random_series[j - 1] + mu * random_series[j - 1] * dt + sigma * random_series[
j - 1] * e * math.sqrt(dt)
plt.plot(x, random_series)
plt.show()
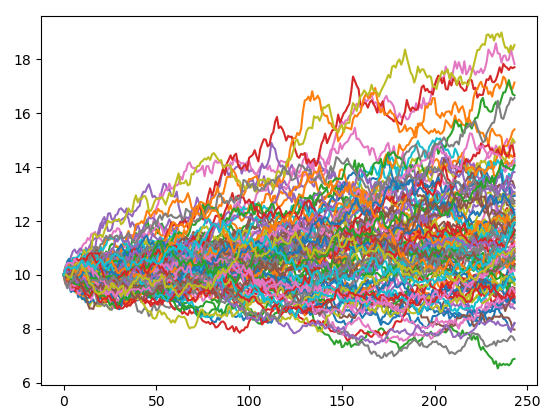
这里我们清晰的展现出了由244个  时间点的股价数据所构成的序列,这是随着时间变化的随机过程。我们为了从整体把握他的分布特征,设定了100个样本,因此模拟出了100条价格曲线。
时间点的股价数据所构成的序列,这是随着时间变化的随机过程。我们为了从整体把握他的分布特征,设定了100个样本,因此模拟出了100条价格曲线。
这种结果图表面上看起来比较凌乱,实际上可以从整体上发现许多端倪,例如股价在运行过程中的整体分布区间,上下界,集中程度等等,都可以有一个整体的把握。
因此我们不仅可以得到最终股价的分布,也可以知道股价运行变化的完整价格路径,这个价格路径代表了蒙特卡罗方法的精髓,通过这个价格路径的可视化呈现,让我们更加直观的从宏观上把握了随机过程。

若有收获,就点个赞吧
0 人点赞
