9.13 英文词云

pip install wordcloud
wordcloud.WordCloud(font_path=None, width=400, height=200, margin=2,ranks_only=None, prefer_horizontal=0.9, mask=None,scale=1, color_func=None, max_words=200,min_font_size=4, stopwords=None, random_state=None,background_color='black', max_font_size=None,font_step=1, mode='RGB', relative_scaling='auto',regexp=None, collocations=True, colormap=None,normalize_plurals=True, contour_width=0,contour_color='black', repeat=False, include_numbers=False,min_word_length=0, collocation_threshold=30)
主要参数:
font_path:要使用的字体的路径。Linux系统下默认为DroidSansMono.ttf,用于中文词云时需要设置中文字体名,否则中文无法正常显示。
width=400, height=200:画布的默认宽度和高度
contour_color: 颜色值(默认值为“黑色”)
scale:计算和绘图之间的缩放倍数,默认为1。对于大型词云图像,使用比例而不是较大的画布大小会明显加快速度,但可能会导致对词的粗略拟合。
mask=None, (默认值=4):要使用的最小字体大小。当没有这么大的空间时就会停止。
max_words (default=200):显示词数最大值(默认值为200)
stopwords=None:将被略过的词,设为 None 时使用内置 STOPWORDS 列表。使用“generate_from_frequencies”方法时忽略此值。
background_color=’black’:背景颜色值(默认值为“黑色”)
max_font_size=None:最大字的最大字体大小,如果值是None,则使用图像的高度。
min_font_size=4:小字体大小默认为 4.
mode:默认为 RGB,当模式为“RGBA”且背景色为“无”时,将生成透明背景。
min_word_length:最小词长度,整数,默认值为0
random_state=None:随机状态数量
常用方法有以下五种
| fit_words(frequencies) | 根据词频生成词云,参数为包含词与词频的字典,为generate_from_frequencies的别名 |
|---|---|
| generate(text) | 根据文本生成词云,是generate_from_text的别名 |
| generate_from_frequencies(frequencies) | 根据词频生成词云,参数为词频字典 |
| generate_from_text(text) | 根据文本生成词云,如果参数是排序的列表,需设置’collocations=False’,否则会导致每个词出现2次。 |
| process_text(text) | 将长文本分词并去除stopwords,返回值为词频字典 |
| recolor(self[,random_state,color_func,…]) | 重着色 |
| to_array(self) | 转为 numpy数组 |
| to_file(self,filename) | 导出为图片文件 |
| to_svg(self[,embed_font,…]) | 导出为SVG |
wordcloud属性
| wordcloud属性 | 作用 |
|---|---|
| font_path | 字符串类型, 字体路径(windows下默认字体路径为C:\Windows\Fonts\如果是自行安装的字体,可能会在C:\Users\用户名\AppData\Local\Microsoft\Windows\Fonts\) |
| width | 整数类型, 生成词云的宽度, 默认:400 |
| height | 整数类型, 生成词云的高度, 默认:200 |
| prefer_horizontal | 浮点类型,词语水平方向排版出现的频率,默认:0.9 |
| mask | 遮罩图, 下方会详细介绍。默认:无 |
| scale | 浮点类型, 按照比例进行放大画布, 默认:1 |
| min_font_size | 整数类型, 显示的最小的字体大小, 默认:4 |
| max_font_size | 整数类型, 显示的最大的字体大小, 默认:无 |
| margin | 整数类型, 边缘空白宽度, 默认:2 |
| font_step | 整数类型, 字体步长, 默认:1 |
| max_words | 整数类型,要显示的词的最大个数 ,默认:200 |
| background_color | 字符串类型, 背景颜色,默认:黑色 |
| stopwords | 设置需要屏蔽的词,如果为空,则使用内置的STOPWORDS |
| relative_scaling | 浮点类型,词频和字体大小的关联性,默认:auto。 |
| regexp | 字符串类型,使用正则表达式分隔输入的文本 |
| collocations | 布尔类型, 是否包括两个词的搭配 |
| colormap | 给每个单词随机分配颜色,若指定color_func,则忽略该方法。 |
| normalize_plurals | 布尔类型,是否删除单词中的s,如果使用generate_from_frequencies,则将其忽略。默认:True |
| contour_width | 浮点类型,如果mask遮罩不是None和contour_width > 0,则绘制mask遮罩轮廓。默认:0 |
| contour_color | 字符串类型, mask遮罩轮廓颜色。默认: black |
| repeat | 布尔类型,是否重复单词和短语,直到达到max_words或min_font_size。默认:False |
| include_numbers | 布尔类型,是否将数字包含为短语。默认:False |
| min_word_length | 整数类型,一个单词必须包含的最小字母数。默认:0 |
| mode | 颜色模式,默认“RGB”。如果想设置透明底色的云词图,那么可以设置background_color=None, mode=“RGBA” |
gone with the wind.txt
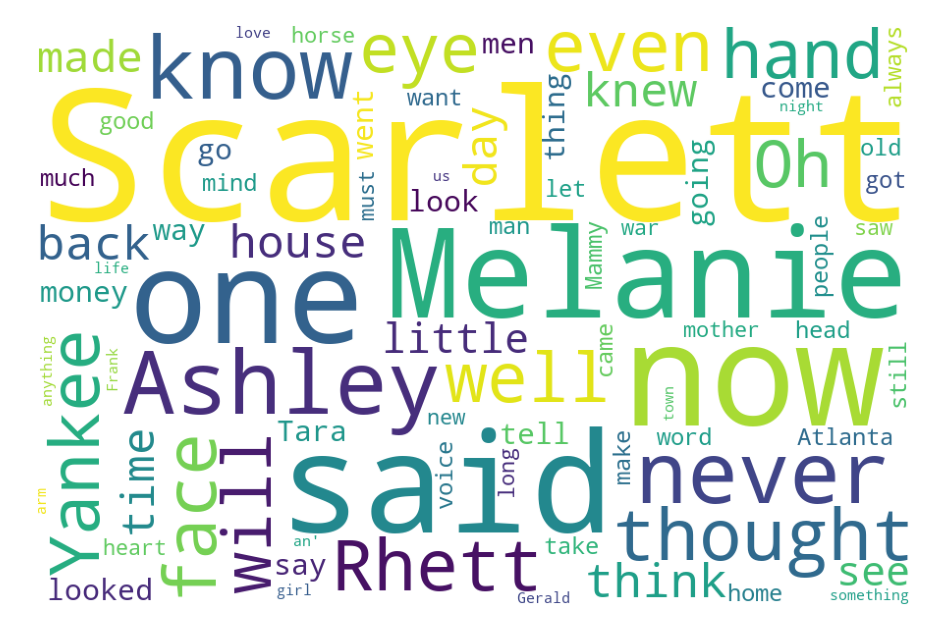
英文文本中单词间用空格进行分隔,所以英文文本的词云制作比较简单,将读取文本文件对象作为参数传递给WordCloud()的generate()函数就可以了,默认词云的背景为黑色,下面例子将背景色设为白色。
从绘制结果可以发现,里面有很多无意义的虚词,如:of、the、and、is、to等,可以考虑加停用词将其过滤掉。停用词可以用内置的STOPWORDS,也可以自己构建:
from wordcloud import WordCloud, STOPWORDSimport matplotlib.pyplot as pltdef file_to_string(filename): # 读取文件,返回字符串with open(filename, 'r', encoding='utf-8') as f: # 文字来源return f.read() # 返回读取文件内容得到的字符串def draw(text): # 绘制词云,设定各参数,传入参数为字符串wc = WordCloud(max_words=80, #设置显示高频单词数量width=600, # 设置图片的宽度height=400, # 设置图片的高度background_color='White', # 设置背景颜色max_font_size=150, # 设置字体最大值stopwords=STOPWORDS, # 去除停用词margin=5, # 设置图片的边缘scale=1.5) #按照比例进行放大画布,如设置为1.5,则长和宽都是原来画布的1.5倍。wc.generate(text) # 根据文本内容直接生成词云plt.imshow(wc) # 负责对图像进行处理,并显示其格式,但是不能显示。plt.axis("off") # 不显示坐标轴wc.to_file('dream.png') # 词云保存为图片plt.show() # 显示图像if __name__ == '__main__':filename = 'gone with the wind.txt' # 用于生成词云的文本文件名txt = file_to_string(filename) # 读取文件中的文本,生成字符串draw(txt) # 绘制词云
9.14 中文词云
中文词之间无分隔,所以中文词云的制作略麻烦,需要提前对文本进行分词处理。
jieba是目前应用较广泛的一个中文分词库,可以导入jieba利用它进行分词再绘制词云。jieba分词有三种模式:精确模式(默认)、全模式和搜索引擎模式,其参数是一个字符串,返回值是元素为中文分词的列表。下面对这三种模式分别举例介绍:
import jiebatxt = '武汉理工大学是教育部直属全国重点大学'print(jieba.lcut(txt)) # 精确模式print(jieba.lcut(txt,cut_all = True)) # 全模式print(jieba.lcut_for_search(txt)) # 搜索引擎模式
输出:
[‘武汉理工大学’, ‘是’, ‘教育部’, ‘直属’, ‘全国’, ‘重点’, ‘大学’]
[‘武汉’, ‘武汉理工’, ‘武汉理工大学’, ‘理工’, ‘理工大’, ‘理工大学’, ‘工大’, ‘大学’, ‘是’, ‘教育’, ‘教育部’, ‘直属’, ‘全国’, ‘重点’, ‘大学’]
[‘武汉’, ‘理工’, ‘工大’, ‘大学’, ‘理工大’, ‘武汉理工大学’, ‘是’, ‘教育’, ‘教育部’, ‘直属’, ‘全国’, ‘重点’, ‘大学’]
从输出结果可以看到,精确模式的可以准确的分词;全模式时,输出所有可能组合的词,冗余较多;搜索引擎模式是精确分词,再对长词进一步切分。一般情况下,推荐使用精确模式。
中文文本能够切分成词就可以用英文词云相同的方法制作词云了,一个需要注意的地方是,制作中文词云时,务必要明确指定中文字体,否则中文无法正确显示。


import jieba.analysefrom PIL import Imageimport numpy as npimport matplotlib.pyplot as pltfrom wordcloud import WordClouddef file_to_string(file):"""接收表示文件名的字符串为参数,读取文本文件内容为一个字符串,返回这个字符串。"""with open(filename, 'r', encoding='utf-8') as f: # 文字来源text = f.read() # 文章内容读取为字符串return text # 返回读取文件内容得到的字符串def text_analysis(text):"""接收一个字符串类型的参数,应用jieba.analyse.textrank()的方法分词,统计每个词的权重,将其转为词频字典并返回这个字典。"""result = jieba.analyse.textrank(text, topK=50, withWeight=True)word = dict()for i in result: # 遍历列表,生成字典word[i[0]] = i[1]return word # 返回关键字与权值字典def draw(word, image):"""接收词的权值字典和背景图片文件对象为参数,绘制背景为白色的带背景图片的词云,设置字体最大值为240,不显示坐标轴,绘制的词云保存为文件。"""graph = np.array(image) # 图片转数组wc = WordCloud(font_path='msyh.ttc', # 中文字体,未指定中文字体时词云的汉字显示为方框,可修改字体名background_color='White', # 设置背景颜色# background_color=None, # 设置透明背景# mode='RGBA',mask=graph, # 设置背景图片max_font_size=240, # 设置字体最大值scale=1.5) # 按照比例进行放大画布,如设置为1.5,则长和宽都是原来画布的1.5倍。wc.generate_from_frequencies(word)plt.imshow(wc) # 负责对图像进行处理,并显示其格式,但是不能显示。plt.axis("off") # 不显示坐标轴wc.to_file('dream.png') # 词云保存为图片plt.show() # 显示图像if __name__ == '__main__':filename = 'jybz.txt' # 用于生成词云的文本文件名txt = file_to_string(filename) # 读取文件中的文本,生成字符串words = text_analysis(txt) # 利用jieba对文本进行分词,并统计词频images = Image.open('9.14 ball.jpg') # 打开背景图片,创建文件对象draw(words, images) # 调用函数绘制词云



校长杨宗凯在2022年毕业典礼暨学位授予仪式上的讲话
张清杰校长在2021届毕业生毕业典礼上的讲话





若有收获,就点个赞吧
0 人点赞
