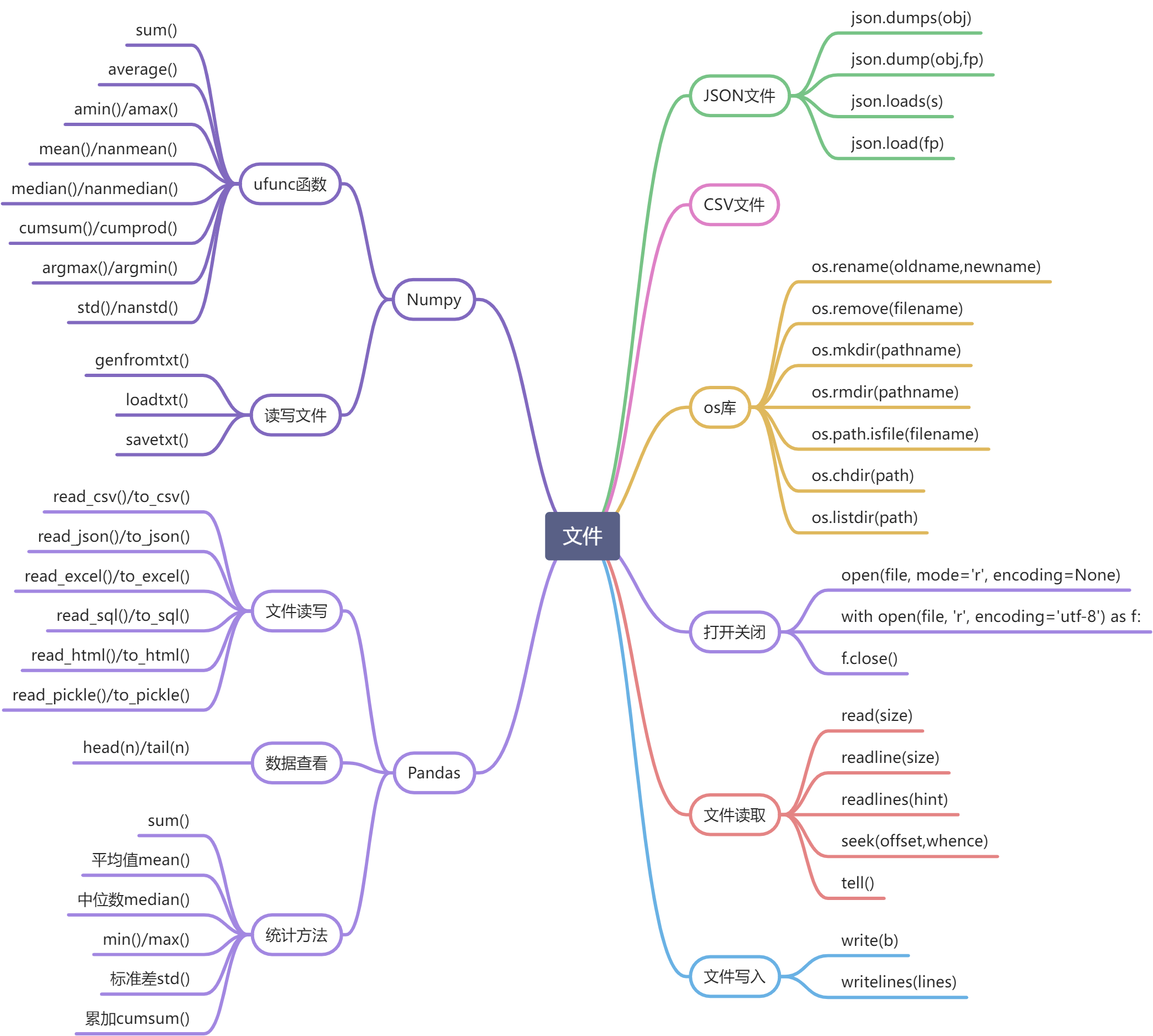
能力点1:读文件处理文件中的字符串
用于字符串处理
read() # 读文件为一个字符串readline() # 读文件的一行为一个字符串readlines() # ''.join(file.readlines())遍历拼接字符串 # 遍历文件对象拼接为字符串
file_obj = open(file, mode='r', encoding=None) # 打开文件,以读模式创建文件对象print(file_obj.read()) # 读文件对象中的数据为字符串file_obj.close() # 关闭文件对象
with open('../data/txt/gone with the wind.txt','r',encoding='utf-8') as f:s = f.read() # 读文件为字符串print(s)
with open('../data/txt/gone with the wind.txt','r',encoding='utf-8') as f:s = '' # 创建空字符串for line in f: # 遍历文件对象s = s + line # 字符串拼接print(s)
| 方法 | 描述 |
|---|---|
| read(size) | 无参数或参数为-1时,读取全部文件内容; 当参数size为大于或等于0的整数时,读取size个字符。字符串 |
| readline(size) | 无参数或参数为-1时,读取并返回文件对象中的一行数据,包括行末结尾标记’\n’,字符串类型。 当参数size为大于或等于0的整数时,最多返回当前行的前size个字符。字符串 |
| readlines(hint) | 无参数时,读取文件全部数据,返回一个列表,列表中每个元素是文件对象中的一行数据,包括行末的换行符’\n’。 当参数hint为大于或等于0的整数时,读取hint个字符所在的行。 |
| seek(offset,whence) | 改变当前文件操作指针的位置, seek(0) 指针返回文件开头 |
Twinkle,twinkle,little star.How I wonder what you are!Up above the world so high.Like a diamond in the sky.Twinkle,twinkle,little star.How I wonder what you are!
1.Mary had a little lamb,
2.Little lamb,little lamb,
3.Mary had a little lamb,
4.It's fleece was white as snow.
5.And everywhere that Mary went,
6.Mary went,Mary went
7.Everywhere that Mary went,
8.The lamb was sure to go.
def read_txt(filename):
"""接收表示文件名的字符串为参数,读取文件内容为字符串,输出字符串"""
with open(filename) as txt: # 创建文件对象,命名为txt
text = txt.read() # 读文件对象txt中的数据为一个字符串
print(text) # 输出字符串
if __name__ == '__main__':
read_txt('a.txt') # 调用函数读'a.txt'
read_txt('b.txt') # 调用函数读'b.txt'
Twinkle,twinkle,little star.How I wonder what you are!Up above the world so high.Like a diamond in the sky.Twinkle,twinkle,little star.How I wonder what you are!
1.Mary had a little lamb,
2.Little lamb,little lamb,
3.Mary had a little lamb,
4.It’s fleece was white as snow.
5.And everywhere that Mary went,
6.Mary went,Mary went
7.Everywhere that Mary went,
8.The lamb was sure to go.
def read_txt(filename):
"""接收表示文件名的字符串为参数,读取文件内容为列表,输出列表"""
with open(filename) as txt: # 创建文件对象
text = txt.readlines() # 读文件到列表,元素为文件的行,每行一个字符串
print(text)
if __name__ == '__main__':
read_txt('a.txt')
read_txt('b.txt')
['Twinkle,twinkle,little star.How I wonder what you are!Up above the world so high.Like a diamond in the sky.Twinkle,twinkle,little star.How I wonder what you are!']
['1.Mary had a little lamb,\n', '2.Little lamb,little lamb,\n', '3.Mary had a little lamb,\n', "4.It's fleece was white as snow.\n", '5.And everywhere that Mary went,\n', '6.Mary went,Mary went\n', '7.Everywhere that Mary went,\n', '8.The lamb was sure to go.']
示例 9.1 统计英文文件中的单词数
def read_txt(filename):
"""接收表示文件名的字符串为参数,读取文件内容为字符串,输出字符串"""
with open(filename) as f: # 创建文件对象,命名为f
text = f.read() # 读文件对象f中的数据为一个字符串
return text
def count_words(text):
"""接收字符串为参数,用空格替换字符串中所有标点符号,根据空格将字符串切分为列表
返回值为元素为单词的列表的长度。
"""
for ch in "!\"'#$%&()*+,-.:;<=>?@[\\]^_{|}~/": # 遍历符号
text = text.replace(ch, " ") # 所有符号替换为空格,新对象重用原名字
return len(text.split()) # 切分为列表,返回列表长度
if __name__ == '__main__':
txt = read_txt('a.txt')
print(count_words(txt)) # 32
txt = read_txt('b.txt')
print(count_words(txt)) # 48def read_txt(filename):
with open(filename) as f:
text = f.read()
return text
def count_words(text):
"""接收字符串为参数,用空格替换字符串中所有标点符号,根据空格将字符串切分为列表
返回值为元素为单词的列表"""
for ch in "!\"'#$%&()*+,-.:;<=>?@[\\]^_{|}~/":
text = text.replace(ch, " ") # 所有符号替换为空格
return len(text.split()) # 切分为列表,返回列表长度
if __name__ == '__main__':
txt = read_txt('a.txt')
print(count_words(txt))
txt = read_txt('b.txt')
print(count_words(txt))
示例 9.2 词频统计

import string
def read_file(file):
"""接收文件名为参数,将文件中的内容读为字符串,只保留文件中的英文字母和西文符号,
过滤掉中文(中文字符及全角符号Unicode编码都大于256)
将所有字符转为小写, 将其中所有标点、符号替换为空格,返回字符串 """
with open(file, 'r', encoding='utf-8') as novel:
txt = novel.read() # 读文件为字符串
# 遍历字符串,去掉非英文字符ord(x) < 256,保留所有西文字符,重新拼接为字符串
english_only_txt = ''.join([x for x in txt if ord(x) < 256])
english_only_txt = english_only_txt.lower() # 所有单词转小写
# 遍历标点符号,替换所有标点为空格,替换后产生新对象,重用原来的名字,实现重复替换
for character in string.punctuation:
english_only_txt = english_only_txt.replace(character, ' ')
return english_only_txt # 返回去除非西文字符并替换掉符号后的字符串
def count_of_words(txt):
"""接收去除标点、符号的字符串,统计并返回其中单词数量和不重复的单词数量"""
words_list = txt.split() # 字符串切分为列表
amount_of_words = len(txt.split()) # 列表长度,单词总数
amount_of_words_no_repeat = len(set(words_list)) # 集合长度,不重复单词总数
return amount_of_words, amount_of_words_no_repeat
def word_frequency(txt):
"""接收去除标点、符号的字符串,统计并返回每个单词出现的次数
返回值为字典类型,单词为键,对应出现的次数为值"""
frequency = dict() # 空字典
words_list = txt.split() # 字符串切分为列表
for word in words_list: # 遍历列表中的单词
frequency[word] = frequency.get(word, 0) + 1
# 统计词频,字典中首次出现的单词数量初值为0,每出现一次为该单词为键的值加1
return frequency # 返回词频字典
if __name__ == '__main__':
filename = '../data/txt/Who Moved My Cheese.txt' # 文件名
content = read_file(filename) # 调用函数返回字典类型的数据
frequency_result = word_frequency(content) # 统计词频
print(sorted(frequency_result.items(),key=lambda x: x[1],reverse=True))
amount_results = count_of_words(content)
print('文章共有单词{}个,其中不重复单词{}个'.format(*amount_results))
[('the', 369), ('he', 337), ('to', 333), ('and', 312), ('cheese', 214),...
...
('continue', 1), ('conversation', 1), ('opportunity', 1)]
文章共有单词10371个,其中不重复单词1407个
示例 9.3 读百家姓获得姓的列表
百家姓.txt
赵钱孙李,周吴郑王。
冯陈褚卫,蒋沈韩杨。
......
巢关蒯相,查后荆红。
游竺权逯,盖益桓公。
万俟司马,上官欧阳。
夏侯诸葛,闻人东方。
......
墨哈谯笪,年爱阳佟。
第五言福
每行读取为字符串,去除换行符、逗号和句号
前51行拼接为一个字符串,再用list()转列表,每个字为一个元素
51行以后拼接为一个字符串,每次取两个字加入列表
def read_txt(): # 根据性别生成一个姓名
"""无参数,读百家姓文件,将单字姓和复姓拆分,返回以姓为元素的列表"""
with open('百家姓.txt', 'r', encoding='utf-8') as data:
# 替换掉换行符、逗号和句号,每行转为一个字符串,得到列表
last_ls = [line.strip().replace(',', '').replace('。', '') for line in data]
print(last_ls) # ['赵钱孙李周吴郑王', '冯陈褚卫蒋沈韩杨', ...]
single = list(''.join(last_ls[:51])) # 前51行为单字姓,拼接为一个字符串转列表
print(single) # ['赵', '钱', '孙', '李', '周', '吴', '郑', '王',...]
double_txt = ''.join(last_ls[51:]) # 51行后为复姓,拼接为一个字符串
double = [] # 创建空列表
for i in range(0, len(double_txt), 2): # 遍历字符串序号,步长为2
double.append(double_txt[i: i + 2]) # 当前序号向后切2个字符,加入到列表
# double = [double_txt[i: i + 2] for i in range(0, len(double_txt), 2)] # 列表推导式方法
print(double) # ['万俟', '司马', '上官', '欧阳', '夏侯', '诸葛', '闻人', '东方', ...]
lastname = single + double # 单字姓列表与复姓列表拼接为一个列表
return lastname # 返回百家姓中所有姓的列表
if __name__ == '__main__':
family_names = read_txt() # 调用函数将文件读为列表
print(family_names) # 输出
读取整个文件为一个字符串,去除换行符、逗号和句号
前408字用list()转列表,每个字为一个元素
408字以后每次取两个字加入列表
['赵钱孙李周吴郑王', '冯陈褚卫蒋沈韩杨',
'朱秦尤许何吕施张', '孔曹严华金魏陶姜',
......
'万俟司马上官欧阳', '夏侯诸葛闻人东方',
'墨哈谯笪年爱阳佟', '第五言福']
['赵', '钱', '孙', '李', '周', '吴', '郑', '王',
......
'万俟', '司马', '上官', '欧阳'
......
'第五', '言福']
def read_txt(): # 根据性别生成一个姓名
"""无参数,读百家姓文件,将单字姓和复姓拆分,返回以姓为元素的列表"""
with open('百家姓.txt', 'r', encoding='utf-8') as data:
# 读文件为一个字符串,替换掉换行符、逗号和句号
last_txt = data.read().replace(',', '').replace('。', '').replace('\n','')
double_txt = last_txt[408:] # 第408字符以后是复姓,截取复姓字符串
double = [double_txt[i: i + 2] for i in range(0, len(double_txt), 2)]
lastname = list(last_txt[408:]) + double # 单字姓列表与复姓列表拼接为一个列表
return lastname # 返回百家姓中所有姓的列表
if __name__ == '__main__':
family_names = read_txt() # 调用函数将文件读为列表
print(family_names) # 输出
能力点2:读文件处理文件中的数据
with open(file, mode='r', encoding=None) as file_obj:
ls = [] # 遍历并切分为列表
for x in file_obj:
ls.append(x.strip().split(',')) # split()参数根据文件中的分隔符确定
with open(file, mode='r', encoding=None) as file_obj:
ls = [x.strip().split(',') for x in file_obj] # 遍历并切分为列表,split()参数根据文件中的分隔符确定
姓名,C语言,Java,Python,C#,C++
罗明,95,96,85,63,91
朱佳,75,93,66,85,88
李思,86,76,96,93,67
郑君,88,98,76,90,89
王雪,99,96,91,88,86
with open('../data/csv/5.7 score.csv','r',encoding='utf-8') as fr:
score_ls = [x.strip().split(',') for x in fr]
print(score_ls)
定义为函数,类似问题只修改文件名和切分时使用的分隔符即可重用此代码。
def read_file(filename):
"""接收文件名为参数,读取文件中的数据为二维列表"""
with open(filename,'r',encoding='utf-8') as fr:
score_ls = [x.strip().split(',') for x in fr]
return score_ls
if __name__ == '__main__':
score_lst = read_file('../csv/5.7 score.csv')
print(score_lst)
def read_file(filename):
"""接收文件名为参数,读取文件中的数据为二维列表"""
with open(filename,'r',encoding='utf-8') as fr:
return score_ls = [x.strip().split(',') for x in fr]
if __name__ == '__main__':
score_lst = read_file('../csv/5.7 score.csv')
print(score_lst)
[['姓名', 'C语言', 'Java', 'Python', 'C#', 'C++'],
['罗明', '95', '96', '85', '63', '91'],
['朱佳', '75', '93', '66', '85', '88'],
['李思', '86', '76', '96', '93', '67'],
['郑君', '88', '98', '76', '90', '89'],
['王雪', '99', '96', '91', '88', '86']]
利用列表拼接,将二维列表的每个子列表拼接到一个空列表上,使二维列表转为一维列表
score_ls = [] # 创建一个空列表
with open('../csv/5.7 score.csv', 'r', encoding='utf-8') as fr:
for x in fr: # 遍历文件对象
score_ls = score_ls + x.strip().split(',') # 每行切为列表,拼接到列表上score_ls
print(score_ls)
def read_file(filename):
"""接收文件名为参数,读取文件中的数据为一维列表"""
score_ls = []
with open(filename, 'r', encoding='utf-8') as fr:
for x in fr:
score_ls = score_ls + x.strip().split(',')
return score_ls
if __name__ == '__main__':
score_lst = read_file('../csv/5.7 score.csv')
print(score_lst)
利用sum()降维,将二维列表的每个子列表拼接到一个初值为空的列表上,使二维列表转为一维列表
with open('../csv/5.7 score.csv','r',encoding='utf-8') as fr:
score_ls = [x.strip().split(',') for x in fr]
score_lst = sum(score_ls, []) # 将二维列表的每个子列表拼接到一个初值为空的列表上
print(score_lst)
def read_file(filename):
"""接收文件名为参数,读取文件中的数据为一维列表"""
with open(filename, 'r', encoding='utf-8') as fr:
score_ls = [x.strip().split(',') for x in fr]
return sum(score_ls, [])
if __name__ == '__main__':
score_lst = read_file('../csv/5.7 score.csv')
print(score_lst)
得到一维列表
['姓名', 'C语言', 'Java', 'Python', 'C#', 'C++', '罗明', '95', '96', '85', '63', '91', '朱佳', '75', '93', '66', '85', '88', '李思', '86', '76', '96', '93', '67', '郑君', '88', '98', '76', '90', '89', '王雪', '99', '96', '91', '88', '86']
用切片方法获得各列数据
with open('../data/csv/5.7 score.csv','r',encoding='utf-8') as fr:
score_ls = [x.strip().split(',') for x in fr]
score_lst = sum(score_ls, [])
print(score_lst[::6]) # 获取姓名列
# ['姓名', '罗明', '朱佳', '李思', '郑君', '王雪']
print(score_lst[3::6]) # 获取python成绩
# ['Python', '85', '66', '96', '76', '91']
利用zip()实现转置
with open('../data/csv/5.7 score.csv','r',encoding='utf-8') as fr:
score_ls = [x.strip().split(',') for x in fr]
score_trans = list(zip(*score_ls)) # 依序取每个子列表中的元素组合起来
print(score_trans)
print(score_trans[0]) # # 获取姓名列
# ('姓名', '罗明', '朱佳', '李思', '郑君', '王雪')
print(score_trans[3]) # # 获取python成绩
# ('Python', '85', '66', '96', '76', '91')
[('姓名', '罗明', '朱佳', '李思', '郑君', '王雪'),
('C语言', '95', '75', '86', '88', '99'),
('Java', '96', '93', '76', '98', '96'),
('Python', '85', '66', '96', '76', '91'),
('C#', '63', '85', '93', '90', '88'),
('C++', '91', '88', '67', '89', '86')]
示例 9.4 成绩分析
涉及数据处理,直接读取为列表,多行数据直接读取为二维列表
需要注意的是,列表中的数据都是字符串,做数值运算和比较前需要转为数值类型
附件文件 “成绩分析综合.csv”中记录了学生实验课的成绩,其中8次实验占总成绩的70%,作业成绩占总成绩的30%,请完成以下任务:
1. 计算每位同学的总成绩
2. 在平时成绩后增加总成绩,按总成绩降序排序,总成绩相同时按学号降序排序,写到文件“成绩分析汇总.csv”中
3. 计算总平均分
4. 统计90分以上的人数及所占比例(百分比)
5. 统计80-89分的人数及所占比例(百分比)
6. 统计70-79分的人数及所占比例(百分比)
7. 统计60-69分的人数及所占比例(百分比)
8. 统计60分以下的人数及所占比例(百分比)
将3-8项任务的结果追加到文件“成绩分析汇总.csv”的末尾。
成绩分析综合.csv
姓名,学号,实验一,实验二,实验三,实验四,实验五,实验六,实验七,实验八,作业成绩
叶灿,0121701100312,100,100,100,100,100,100,60,100,96
朱宇轩,0121701100702,100,100,100,100,100,100,90,100,99
陈一帆,0121701100730,100,100,100,100,50,100,80,75,89.25
王璐,0121701100733,100,100,100,100,100,100,100,100,100
def read_txt(filename):
with open(filename, encoding='utf-8') as f:
score_ls = f.readlines()
return score_ls
if __name__ == '__main__':
score = read_txt('成绩分析综合.csv')
print(score)
得到一维列表,后续处理不方便
['姓名,学号,实验一,实验二,实验三,实验四,实验五,实验六,实验七,实验八,作业成绩\n', '叶灿,0121701100312,100,100,100,100,100,100,60,100,96\n', '朱宇轩,0121701100702,100,100,100,100,100,100,90,100,99\n', '陈一帆,0121701100730,100,100,100,100,50,100,80,75,89.25\n', '王璐,0121701100733,100,100,100,100,100,100,100,100,100\n', '陈锦妍,0121701100735,100,100,100,100,50,33.33333333,30,50,70.5\n', '张欣燕,0121701100736,100,100,100,100,100,100,90,75,95.25\n', '田超,0121701100814,100,100,100,100,100,100,80,100,98\n', '姚炜临,0121701100903,100,100,50,50,100,33.33333333,0,50,62.5\n', '钟坤哲,0121701100906,100,100,100,100,100,100,0,100,90\n', '罗震,0121701100910,100,100,100,100,100,100,0,100,90\n', '张文吉,0121701100913,100,100,0,0,50,100,0,100,65\n', '谢凡,0121701100920,100,100,100,100,100,100,90,100,99\n', '曹志诚,0121701100921,100,100,100,100,100,100,60,100,96\n', '戴兆晖,0121701100926,100,100,100,100,100,100,80,100,98\n', '丁昊,0121701100928,100,100,100,100,50,100,0,100,85\n', '张雯雪,0121701100931,100,100,100,100,100,100,30,100,93\n', '何文倩,0121701100932,100,100,100,100,50,100,90,100,94\n', '黎颜菲,0121701100933,100,100,100,100,100,100,0,100,90\n', '郭非凡,0121701101001,100,100,100,100,100,100,10,100,91\n', '李春晖,0121701101002,100,100,100,100,100,100,100,100,100\n', '马世荣,0121701101003,100,100,100,100,100,100,20,100,92\n', '胡晗,0121701101004,100,100,100,100,100,100,70,100,97\n', '田博文,0121701101005,0,0,0,0,0,0,0,0,0\n', '李东阳,0121701101013,100,100,100,100,50,100,50,100,90\n', '赵佳彤,0121701101030,100,100,100,100,100,100,90,100,99\n', '甄昕,0121701101034,100,100,100,100,100,100,80,100,98\n', '吴淇,0121701101102,100,100,50,0,100,100,30,100,78\n', '邓拓,0121701101103,100,100,100,0,100,100,0,75,76.25\n', '叶功翔,0121701101120,100,100,100,100,50,100,100,75,91.25\n', '陈昊,0121701101125,100,100,100,100,100,100,100,100,100\n', '武浩,0121701101127,100,100,100,100,100,100,0,100,90\n', '林静怡,0121701101129,100,100,100,100,100,100,80,100,98\n', '杨倩倩,0121701101130,100,100,100,100,100,100,30,100,93\n', '庞婉君,0121701101131,100,100,100,100,100,100,80,100,98\n', '谭天美,0121701101132,100,100,100,100,100,100,40,100,94\n', '徐仔怡,0121701101133,100,100,100,100,100,100,40,100,94\n', '宁金松,0121701101204,100,100,100,100,100,100,0,100,90\n', '程周耀,0121701101213,100,100,100,100,50,100,10,100,86\n', '陈子昂,0121701101214,100,100,100,100,100,100,80,100,98\n', '肖壮,0121701101215,100,100,100,0,50,100,0,100,75\n', '程振鑫,0121701101216,100,100,50,50,50,100,0,50,67.5\n', '刘鑫,0121701101219,100,100,100,100,100,100,100,100,100\n', '胡佳平,0121701101221,100,100,100,100,100,100,90,100,99\n', '张帆,0121701101225,100,100,50,50,100,0,0,100,65\n', '邓谋,0121701101226,100,100,100,100,100,100,0,100,90\n', '周奇俊,0121701101227,100,50,50,50,50,33.33333333,10,25,47.25\n', '陈海雪,0121701101229,100,100,50,100,0,100,10,100,76\n', '朱昱颖,0121701101231,100,100,100,100,100,100,30,100,93\n', '姚歆玥,0121701101233,100,100,100,100,100,100,100,100,100\n', '张心萍,0121701101234,100,100,100,100,0,100,80,100,88\n', '柯筱婧,0121713570418,100,100,100,100,100,100,80,75,94.25\n', '周欣茹,0121713590116,100,0,100,0,100,100,0,50,57.5\n', '罗明丽,0121713590312,100,0,0,0,0,100,0,0,30\n', '毛希阳,0121713590319,100,100,0,100,0,100,0,100,70\n', '王延旭,0121719650105,100,0,100,0,0,0,20,25,30.75\n', '林君茹,0121719650122,100,0,0,0,0,100,0,0,30\n', '许清华,0121719650202,100,100,50,0,0,100,0,100,65\n', '赵丁儒,0121719640112,100,100,100,0,0,100,20,100,72\n', '谈烟,0121719640113,100,100,100,0,100,100,20,100,82\n', '李松蔚,0121719640114,100,100,100,0,50,100,0,100,75\n', '徐晓旭,0121719640116,80,100,0,0,0,100,0,0,42\n', '欧阳许岩,0121719640117,100,100,100,0,0,100,20,100,72\n', '詹谣,0121719640119,70,0,0,0,0,100,0,0,25.5\n', '续惠敏,0121719640121,100,100,100,0,0,100,0,75,66.25\n', '刘畅,0121719640123,100,100,100,0,0,100,20,75,68.25\n', '古丽巴努·玉散,0121719640124,100,100,0,0,0,100,10,50,53.5\n', '明月,0121719640125,60,0,0,0,0,100,0,0,24\n', '李芯蕾,0121719640127,100,0,100,0,0,100,20,50,49.5\n', '张笑语,0121719640128,100,100,100,0,0,100,20,75,68.25\n', '曹思诗,0121719640129,100,100,0,0,0,100,40,25,52.75\n', '吴春盈,0121719640130,100,100,100,0,0,100,30,100,73\n', '杨永泽,0121719650101,0,0,0,0,0,0,0,75,11.25\n', '李宁澳,0121719650102,100,100,100,100,100,100,30,100,93\n', '国怀东,0121719650106,100,0,0,0,0,0,50,0,20\n', '罗宇翔,0121719650107,100,100,100,0,0,100,0,100,70\n', '曲桑次仁,0121719650109,10,0,0,0,0,0,10,0,2.5\n', '萨依拉提,0121719650110,80,0,0,0,0,0,0,0,12\n', '陈玉洁,0121719650111,100,100,0,0,0,100,0,100,60\n', '余孝雯,0121719650112,80,100,0,0,0,100,10,100,58\n', '许熙扬,0121719650113,100,100,100,100,100,100,60,100,96\n', '范茹婷,0121719650114,100,100,100,100,50,100,40,100,89\n', '陈玉萍,0121719650115,100,0,0,0,0,100,0,100,45\n', '王夏虹,0121719650116,100,100,100,0,0,100,0,100,70\n', '王冰,0121719650118,100,100,50,0,0,100,30,100,68\n', '安静,0121719650119,100,100,100,0,0,100,20,100,72\n', '孙昕月,0121719650120,100,100,100,0,0,100,30,100,73\n', '徐若彤,0121719650121,100,100,50,100,50,100,0,100,80\n', '石妍露,0121719650123,100,100,100,0,0,100,0,100,70\n', '蒋秋楠,0121719650124,100,100,100,0,0,100,30,25,61.75\n', '赵语秋,0121719650125,100,100,100,0,0,100,0,25,58.75\n', '李莲花,0121719650126,0,100,100,100,100,100,40,100,79\n', '王友萌,0121719650127,100,100,0,0,0,100,0,50,52.5\n', '胡昕,0121719650128,100,100,100,0,50,100,30,100,78\n', '殷娅娴,0121719650129,100,100,100,50,50,100,40,100,84\n', '孟璐,0121719650130,100,100,100,0,0,100,0,100,70\n', '赵文朔,0121719650131,100,100,100,100,100,100,60,100,96\n', '程高洁,0121719650132,100,100,100,100,50,100,0,100,85\n', '李镓静,0121719650134,0,50,100,0,0,100,30,100,50.5\n', '丽娜·吐尔逊哈孜,0121719650135,100,100,100,100,0,100,0,100,80\n', '马莉,0121719650136,100,100,0,0,0,100,0,100,60\n', '郑洁儒,0121719650137,100,100,100,0,0,100,30,100,73\n', '刘方潇,0121719650138,100,100,100,0,50,100,20,100,77\n', '李鹏飞,0121719650201,100,100,50,50,100,100,0,50,72.5\n', '杨丹宇,0121719650203,100,100,50,50,100,100,0,50,72.5\n', '戴敬梓,0121719650204,100,100,50,0,0,100,0,0,50\n', '任加奕,0121719650207,100,100,50,50,100,100,0,50,72.5\n', '桑旦扎西,0121719650209,100,100,50,0,0,100,0,0,50\n', '刘冠廷,0121719650210,100,100,100,0,0,100,10,100,71\n', '胡欢,0121719650211,100,100,0,0,50,100,20,100,67\n', '王倩怡,0121719650214,100,100,0,100,0,100,40,25,62.75\n', '庞诗云,0121719650215,100,100,0,0,0,100,0,25,48.75\n', '肖佳宁,0121719650217,100,100,100,0,0,100,0,0,55\n', '宋婉莹,0121719650219,100,100,100,0,50,100,20,0,62\n', '周玉婷,0121719650220,100,100,50,50,50,100,40,100,79\n', '陈铭,0121719650221,100,100,100,100,100,100,30,100,93\n', '向凝颖,0121719650223,100,100,100,0,0,100,0,75,66.25\n', '徐博雅,0121719650224,100,100,100,50,50,100,20,100,82\n', '虞静涵,0121719650225,100,100,100,50,100,100,40,100,89\n', '付鑫鑫,0121719650226,100,100,100,0,0,100,0,100,70\n', '朱笑,0121719650227,100,100,100,50,100,100,20,100,87\n', '姜婷婷,0121719650228,100,100,100,100,100,100,40,100,94\n', '王朦,0121719650229,100,100,0,0,0,100,30,25,51.75\n', '杨宇星,0121719650230,100,100,0,0,0,100,0,100,60\n', '杨毓,0121719650231,80,100,0,0,0,100,0,25,45.75\n', '苗泽露,0121719650232,100,100,100,0,50,100,0,100,75\n', '阿亚古丽·苏里旦哈孜,0121719650235,80,100,0,0,0,100,0,100,57\n', '彭馨瑶,0121719650236,100,100,0,0,0,100,0,25,48.75\n', '季叶桐,0121719650237,100,100,100,0,0,100,20,100,72\n', '李林晏,0121719650238,100,100,0,0,0,100,20,100,62\n', '周佳银,0121719640118,100,100,100,0,0,100,40,100,74\n', '刘子雨,0121701100507,80,100,100,100,100,100,80,100,95\n', '刘后傲,0121701100510,80,100,50,50,50,100,0,75,68.25\n', '张自强,0121701100512,100,100,100,100,100,100,90,100,99\n', '吴逸飞,0121701100516,100,100,100,100,100,100,100,100,100\n', '孙金新,0121701100521,80,100,100,100,100,100,70,100,94\n', '杨旺霖,0121701100527,100,100,100,100,100,100,80,100,98\n', '孙钰伟,0121701100623,100,100,100,100,100,100,70,100,97\n', '张竣皓,0121701100624,100,50,100,100,50,100,70,100,84.5\n', '马全志,0121701100627,100,100,100,100,50,100,70,50,84.5\n', '刘钰婷,0121701100631,80,100,100,100,100,100,50,100,92\n', '张书玥,0121701100635,80,100,100,100,100,100,20,100,89\n', '禹策,0121701101024,80,100,100,50,50,100,0,100,77\n', '吴伊民,0121701101113,80,100,100,50,100,100,0,50,74.5\n', '朱金成,0121701101117,100,100,100,100,100,100,70,100,97\n', '徐庆庆,0121701101206,80,100,100,100,100,100,70,100,94\n', '杨彪,0121701101212,100,100,100,100,100,100,100,100,100\n', '石士鹏,0121713590101,100,100,100,100,50,100,0,100,85\n', '王浩,0121713590105,90,100,100,100,100,100,20,100,90.5\n', '胡鹏乾,0121713590106,100,100,100,100,0,100,0,100,80\n', '庄婧雯,0121713590107,100,100,100,100,100,100,0,100,90\n', '蔡渲渲,0121713590108,100,100,100,100,100,100,70,100,97\n', '陈蔚彤,0121713590109,90,100,100,0,100,100,40,100,82.5\n', '吴清清,0121713590111,100,100,100,100,100,100,70,100,97\n', '赖韦潇,0121713590112,100,100,100,100,100,100,100,100,100\n', '龙玉凤,0121713590113,100,100,100,100,100,100,10,100,91\n', '周梦瑶,0121713590114,80,100,100,100,100,100,90,100,96\n', '黄梦圆,0121713590115,90,100,100,100,100,100,0,100,88.5\n', '孙冉祺,0121713590118,80,100,100,100,50,100,30,100,85\n', '王蕾,0121713590119,100,100,100,100,50,100,20,100,87\n', '向欣然,0121713590120,80,100,100,0,0,100,60,100,73\n', '郑宇轩,0121713590122,100,0,100,0,0,100,70,0,47\n', '杨晶晶,0121713590123,100,100,100,100,100,100,0,100,90\n', '张雪迎,0121713590124,40,100,100,0,0,100,0,100,61\n', '买玉花,0121713590125,100,0,0,0,0,0,10,0,16\n', '龚馨雅,0121713590127,80,100,100,0,0,100,70,25,62.75\n', '柳茵茵,0121713590128,100,100,100,0,0,100,0,100,70\n', '胡馨,0121713590129,60,0,0,0,0,0,0,0,9\n', '赛乌来,0121713590130,80,0,100,0,0,100,0,75,48.25\n', '麦热帕提·玉山江,0121713590131,40,0,0,0,0,0,0,25,9.75\n', '胡蝶,0121713590132,80,100,100,100,100,100,60,100,93\n', '陈灵锋,0121713590201,100,100,100,0,50,100,0,100,75\n', '安闯,0121713590202,90,100,100,100,100,100,0,100,88.5\n', '周富成,0121713590204,100,100,100,0,100,100,0,100,80\n', '吴俊霖,0121713590205,100,100,100,100,100,100,30,100,93\n', '益西索朗,0121713590206,40,0,0,0,50,100,0,50,33.5\n', '刘天斯,0121713590207,90,100,100,100,100,100,20,100,90.5\n', '林欣洁,0121713590208,100,100,100,100,100,100,0,100,90\n', '张倩雯,0121713590209,100,100,100,100,100,100,100,100,100\n', '卢柔蓉,0121713590210,100,100,100,0,0,100,0,100,70\n', '黎敏琴,0121713590211,100,100,0,0,0,100,0,100,60\n', '张子薇,0121713590212,100,100,50,0,100,100,0,100,75\n', '张萌萌,0121713590213,100,100,100,100,100,100,20,100,92\n', '史思琪,0121713590215,100,100,100,0,50,100,0,75,71.25\n', '程赛,0121713590217,80,100,100,100,100,100,0,100,87\n', '王佳慧,0121713590218,100,100,100,100,100,100,100,100,100\n', '蒋依帆,0121713590219,80,100,100,100,100,100,0,100,87\n', '喻明珠,0121713590221,100,100,100,100,100,100,100,100,100\n', '赵雅如,0121713590224,100,100,100,100,100,100,10,100,91\n', '马明昊,0121713590225,80,100,100,0,0,100,0,0,52\n', '张奕博,0121713590226,90,100,100,0,50,100,0,75,69.75\n', '郑姗姗,0121713590227,100,100,100,100,100,100,90,100,99\n', '阿依巴努·阿里木江,0121713590229,60,0,0,0,100,0,40,0,23\n', '许展,0121713590230,80,100,100,50,100,100,20,100,84\n', '阿丽亚·阿布都热西提,0121713590231,90,100,100,0,50,100,0,75,69.75\n', '张攀,0121713590232,100,100,100,0,0,100,0,100,70\n', '郭琳,0121713590303,70,50,50,50,50,100,0,100,63\n', '张宁,0121713590304,90,100,100,100,100,100,80,100,96.5\n', '杨逸谦,0121713590305,100,100,100,50,100,100,0,100,85\n', '陈晶晶,0121713590306,80,100,100,100,50,100,20,100,84\n', '曹端宏,0121713590307,100,100,0,0,0,0,0,50,37.5\n', '闫梦菲,0121713590308,80,100,100,100,100,100,70,100,94\n', '魏瑜,0121713590313,80,100,100,0,0,100,0,75,63.25\n', '景明慧,0121713590315,80,100,100,100,0,100,0,100,77\n', '刘思洁,0121713590316,80,100,50,0,50,100,0,100,67\n', '陈慧玲,0121713590317,100,100,100,0,0,100,0,100,70\n', '王颖,0121713590318,100,100,100,100,100,100,10,100,91\n', '崔美晶,0121713590321,90,50,100,50,50,100,0,100,71\n', '翟云琪,0121713590322,90,0,0,0,0,0,0,25,17.25\n', '马怡宁,0121713590324,40,100,100,0,0,100,0,0,46\n', '李雅楠,0121713590326,100,100,100,0,50,100,10,100,76\n', '刘淼淼,0121713590327,80,100,100,100,100,100,20,100,89\n', '次旺巴珍,0121713590328,100,0,0,0,0,0,0,0,15\n', '爱克达·阿斯哈尔,0121713590329,100,0,100,0,50,100,30,0,48\n', '丁家玉,0121713590330,100,100,100,0,0,100,0,100,70\n', '关灵爽,0121713590331,80,100,100,50,100,100,20,100,84\n', '史雨阳,0121415940402,0,0,0,0,0,0,0,0,0\n', '杨俊,0121713590203,100,100,100,0,0,100,0,100,70\n']
直接采用遍历读取的方法得到二维列表,后续处理方便
def read_txt(filename):
"""读文件到二维列表"""
with open(filename, encoding='utf-8') as f:
return [x.strip().split(',') for x in f]
if __name__ == '__main__':
score = read_txt('成绩分析综合.csv')
print(score)
[['姓名', '学号', '实验一', '实验二', '实验三', '实验四', '实验五', '实验六', '实验七', '实验八', '作业成绩'],
['叶灿', '0121701100312', '100', '100', '100', '100', '100', '100', '60', '100', '96'],
['朱宇轩', '0121701100702', '100', '100', '100', '100', '100', '100', '90', '100', '99'],
['陈一帆', '0121701100730', '100', '100', '100', '100', '50', '100', '80', '75', '89.25'], ['王璐', '0121701100733', '100', '100', '100', '100', '100', '100', '100', '100', '100'], ['陈锦妍', '0121701100735', '100', '100', '100', '100', '50', '33.33333333', '30', '50', '70.5'], ['张欣燕', '0121701100736', '100', '100', '100', '100', '100', '100', '90', '75', '95.25'], ['田超', '0121701100814', '100', '100', '100', '100', '100', '100', '80', '100', '98'], ['姚炜临', '0121701100903', '100', '100', '50', '50', '100', '33.33333333', '0', '50', '62.5'], ['钟坤哲', '0121701100906', '100', '100', '100', '100', '100', '100', '0', '100', '90'], ['罗震', '0121701100910', '100', '100', '100', '100', '100', '100', '0', '100', '90'], ['张文吉', '0121701100913', '100', '100', '0', '0', '50', '100', '0', '100', '65'], ['谢凡', '0121701100920', '100', '100', '100', '100', '100', '100', '90', '100', '99'], ['曹志诚', '0121701100921', '100', '100', '100', '100', '100', '100', '60', '100', '96'], ['戴兆晖', '0121701100926', '100', '100', '100', '100', '100', '100', '80', '100', '98'], ['丁昊', '0121701100928', '100', '100', '100', '100', '50', '100', '0', '100', '85'], ['张雯雪', '0121701100931', '100', '100', '100', '100', '100', '100', '30', '100', '93'], ['何文倩', '0121701100932', '100', '100', '100', '100', '50', '100', '90', '100', '94'], ['黎颜菲', '0121701100933', '100', '100', '100', '100', '100', '100', '0', '100', '90'], ['郭非凡', '0121701101001', '100', '100', '100', '100', '100', '100', '10', '100', '91'], ['李春晖', '0121701101002', '100', '100', '100', '100', '100', '100', '100', '100', '100'], ['马世荣', '0121701101003', '100', '100', '100', '100', '100', '100', '20', '100', '92'], ['胡晗', '0121701101004', '100', '100', '100', '100', '100', '100', '70', '100', '97'], ['田博文', '0121701101005', '0', '0', '0', '0', '0', '0', '0', '0', '0'], ['李东阳', '0121701101013', '100', '100', '100', '100', '50', '100', '50', '100', '90'], ['赵佳彤', '0121701101030', '100', '100', '100', '100', '100', '100', '90', '100', '99'], ['甄昕', '0121701101034', '100', '100', '100', '100', '100', '100', '80', '100', '98'], ['吴淇', '0121701101102', '100', '100', '50', '0', '100', '100', '30', '100', '78'], ['邓拓', '0121701101103', '100', '100', '100', '0', '100', '100', '0', '75', '76.25'], ['叶功翔', '0121701101120', '100', '100', '100', '100', '50', '100', '100', '75', '91.25'], ['陈昊', '0121701101125', '100', '100', '100', '100', '100', '100', '100', '100', '100'], ['武浩', '0121701101127', '100', '100', '100', '100', '100', '100', '0', '100', '90'], ['林静怡', '0121701101129', '100', '100', '100', '100', '100', '100', '80', '100', '98'], ['杨倩倩', '0121701101130', '100', '100', '100', '100', '100', '100', '30', '100', '93'], ['庞婉君', '0121701101131', '100', '100', '100', '100', '100', '100', '80', '100', '98'], ['谭天美', '0121701101132', '100', '100', '100', '100', '100', '100', '40', '100', '94'], ['徐仔怡', '0121701101133', '100', '100', '100', '100', '100', '100', '40', '100', '94'], ['宁金松', '0121701101204', '100', '100', '100', '100', '100', '100', '0', '100', '90'], ['程周耀', '0121701101213', '100', '100', '100', '100', '50', '100', '10', '100', '86'], ['陈子昂', '0121701101214', '100', '100', '100', '100', '100', '100', '80', '100', '98'], ['肖壮', '0121701101215', '100', '100', '100', '0', '50', '100', '0', '100', '75'], ['程振鑫', '0121701101216', '100', '100', '50', '50', '50', '100', '0', '50', '67.5'], ['刘鑫', '0121701101219', '100', '100', '100', '100', '100', '100', '100', '100', '100'], ['胡佳平', '0121701101221', '100', '100', '100', '100', '100', '100', '90', '100', '99'], ['张帆', '0121701101225', '100', '100', '50', '50', '100', '0', '0', '100', '65'], ['邓谋', '0121701101226', '100', '100', '100', '100', '100', '100', '0', '100', '90'], ['周奇俊', '0121701101227', '100', '50', '50', '50', '50', '33.33333333', '10', '25', '47.25'], ['陈海雪', '0121701101229', '100', '100', '50', '100', '0', '100', '10', '100', '76'], ['朱昱颖', '0121701101231', '100', '100', '100', '100', '100', '100', '30', '100', '93'], ['姚歆玥', '0121701101233', '100', '100', '100', '100', '100', '100', '100', '100', '100'], ['张心萍', '0121701101234', '100', '100', '100', '100', '0', '100', '80', '100', '88'], ['柯筱婧', '0121713570418', '100', '100', '100', '100', '100', '100', '80', '75', '94.25'], ['周欣茹', '0121713590116', '100', '0', '100', '0', '100', '100', '0', '50', '57.5'], ['罗明丽', '0121713590312', '100', '0', '0', '0', '0', '100', '0', '0', '30'], ['毛希阳', '0121713590319', '100', '100', '0', '100', '0', '100', '0', '100', '70'], ['王延旭', '0121719650105', '100', '0', '100', '0', '0', '0', '20', '25', '30.75'], ['林君茹', '0121719650122', '100', '0', '0', '0', '0', '100', '0', '0', '30'], ['许清华', '0121719650202', '100', '100', '50', '0', '0', '100', '0', '100', '65'], ['赵丁儒', '0121719640112', '100', '100', '100', '0', '0', '100', '20', '100', '72'], ['谈烟', '0121719640113', '100', '100', '100', '0', '100', '100', '20', '100', '82'], ['李松蔚', '0121719640114', '100', '100', '100', '0', '50', '100', '0', '100', '75'], ['徐晓旭', '0121719640116', '80', '100', '0', '0', '0', '100', '0', '0', '42'], ['欧阳许岩', '0121719640117', '100', '100', '100', '0', '0', '100', '20', '100', '72'], ['詹谣', '0121719640119', '70', '0', '0', '0', '0', '100', '0', '0', '25.5'], ['续惠敏', '0121719640121', '100', '100', '100', '0', '0', '100', '0', '75', '66.25'], ['刘畅', '0121719640123', '100', '100', '100', '0', '0', '100', '20', '75', '68.25'], ['古丽巴努·玉散', '0121719640124', '100', '100', '0', '0', '0', '100', '10', '50', '53.5'], ['明月', '0121719640125', '60', '0', '0', '0', '0', '100', '0', '0', '24'], ['李芯蕾', '0121719640127', '100', '0', '100', '0', '0', '100', '20', '50', '49.5'], ['张笑语', '0121719640128', '100', '100', '100', '0', '0', '100', '20', '75', '68.25'], ['曹思诗', '0121719640129', '100', '100', '0', '0', '0', '100', '40', '25', '52.75'], ['吴春盈', '0121719640130', '100', '100', '100', '0', '0', '100', '30', '100', '73'], ['杨永泽', '0121719650101', '0', '0', '0', '0', '0', '0', '0', '75', '11.25'], ['李宁澳', '0121719650102', '100', '100', '100', '100', '100', '100', '30', '100', '93'], ['国怀东', '0121719650106', '100', '0', '0', '0', '0', '0', '50', '0', '20'], ['罗宇翔', '0121719650107', '100', '100', '100', '0', '0', '100', '0', '100', '70'], ['曲桑次仁', '0121719650109', '10', '0', '0', '0', '0', '0', '10', '0', '2.5'], ['萨依拉提', '0121719650110', '80', '0', '0', '0', '0', '0', '0', '0', '12'], ['陈玉洁', '0121719650111', '100', '100', '0', '0', '0', '100', '0', '100', '60'], ['余孝雯', '0121719650112', '80', '100', '0', '0', '0', '100', '10', '100', '58'], ['许熙扬', '0121719650113', '100', '100', '100', '100', '100', '100', '60', '100', '96'], ['范茹婷', '0121719650114', '100', '100', '100', '100', '50', '100', '40', '100', '89'], ['陈玉萍', '0121719650115', '100', '0', '0', '0', '0', '100', '0', '100', '45'], ['王夏虹', '0121719650116', '100', '100', '100', '0', '0', '100', '0', '100', '70'], ['王冰', '0121719650118', '100', '100', '50', '0', '0', '100', '30', '100', '68'], ['安静', '0121719650119', '100', '100', '100', '0', '0', '100', '20', '100', '72'], ['孙昕月', '0121719650120', '100', '100', '100', '0', '0', '100', '30', '100', '73'], ['徐若彤', '0121719650121', '100', '100', '50', '100', '50', '100', '0', '100', '80'], ['石妍露', '0121719650123', '100', '100', '100', '0', '0', '100', '0', '100', '70'], ['蒋秋楠', '0121719650124', '100', '100', '100', '0', '0', '100', '30', '25', '61.75'], ['赵语秋', '0121719650125', '100', '100', '100', '0', '0', '100', '0', '25', '58.75'], ['李莲花', '0121719650126', '0', '100', '100', '100', '100', '100', '40', '100', '79'], ['王友萌', '0121719650127', '100', '100', '0', '0', '0', '100', '0', '50', '52.5'], ['胡昕', '0121719650128', '100', '100', '100', '0', '50', '100', '30', '100', '78'], ['殷娅娴', '0121719650129', '100', '100', '100', '50', '50', '100', '40', '100', '84'], ['孟璐', '0121719650130', '100', '100', '100', '0', '0', '100', '0', '100', '70'], ['赵文朔', '0121719650131', '100', '100', '100', '100', '100', '100', '60', '100', '96'], ['程高洁', '0121719650132', '100', '100', '100', '100', '50', '100', '0', '100', '85'], ['李镓静', '0121719650134', '0', '50', '100', '0', '0', '100', '30', '100', '50.5'], ['丽娜·吐尔逊哈孜', '0121719650135', '100', '100', '100', '100', '0', '100', '0', '100', '80'], ['马莉', '0121719650136', '100', '100', '0', '0', '0', '100', '0', '100', '60'], ['郑洁儒', '0121719650137', '100', '100', '100', '0', '0', '100', '30', '100', '73'], ['刘方潇', '0121719650138', '100', '100', '100', '0', '50', '100', '20', '100', '77'], ['李鹏飞', '0121719650201', '100', '100', '50', '50', '100', '100', '0', '50', '72.5'], ['杨丹宇', '0121719650203', '100', '100', '50', '50', '100', '100', '0', '50', '72.5'], ['戴敬梓', '0121719650204', '100', '100', '50', '0', '0', '100', '0', '0', '50'], ['任加奕', '0121719650207', '100', '100', '50', '50', '100', '100', '0', '50', '72.5'], ['桑旦扎西', '0121719650209', '100', '100', '50', '0', '0', '100', '0', '0', '50'], ['刘冠廷', '0121719650210', '100', '100', '100', '0', '0', '100', '10', '100', '71'], ['胡欢', '0121719650211', '100', '100', '0', '0', '50', '100', '20', '100', '67'], ['王倩怡', '0121719650214', '100', '100', '0', '100', '0', '100', '40', '25', '62.75'], ['庞诗云', '0121719650215', '100', '100', '0', '0', '0', '100', '0', '25', '48.75'], ['肖佳宁', '0121719650217', '100', '100', '100', '0', '0', '100', '0', '0', '55'], ['宋婉莹', '0121719650219', '100', '100', '100', '0', '50', '100', '20', '0', '62'], ['周玉婷', '0121719650220', '100', '100', '50', '50', '50', '100', '40', '100', '79'], ['陈铭', '0121719650221', '100', '100', '100', '100', '100', '100', '30', '100', '93'], ['向凝颖', '0121719650223', '100', '100', '100', '0', '0', '100', '0', '75', '66.25'], ['徐博雅', '0121719650224', '100', '100', '100', '50', '50', '100', '20', '100', '82'], ['虞静涵', '0121719650225', '100', '100', '100', '50', '100', '100', '40', '100', '89'], ['付鑫鑫', '0121719650226', '100', '100', '100', '0', '0', '100', '0', '100', '70'], ['朱笑', '0121719650227', '100', '100', '100', '50', '100', '100', '20', '100', '87'], ['姜婷婷', '0121719650228', '100', '100', '100', '100', '100', '100', '40', '100', '94'], ['王朦', '0121719650229', '100', '100', '0', '0', '0', '100', '30', '25', '51.75'], ['杨宇星', '0121719650230', '100', '100', '0', '0', '0', '100', '0', '100', '60'], ['杨毓', '0121719650231', '80', '100', '0', '0', '0', '100', '0', '25', '45.75'], ['苗泽露', '0121719650232', '100', '100', '100', '0', '50', '100', '0', '100', '75'], ['阿亚古丽·苏里旦哈孜', '0121719650235', '80', '100', '0', '0', '0', '100', '0', '100', '57'], ['彭馨瑶', '0121719650236', '100', '100', '0', '0', '0', '100', '0', '25', '48.75'], ['季叶桐', '0121719650237', '100', '100', '100', '0', '0', '100', '20', '100', '72'], ['李林晏', '0121719650238', '100', '100', '0', '0', '0', '100', '20', '100', '62'], ['周佳银', '0121719640118', '100', '100', '100', '0', '0', '100', '40', '100', '74'], ['刘子雨', '0121701100507', '80', '100', '100', '100', '100', '100', '80', '100', '95'], ['刘后傲', '0121701100510', '80', '100', '50', '50', '50', '100', '0', '75', '68.25'], ['张自强', '0121701100512', '100', '100', '100', '100', '100', '100', '90', '100', '99'], ['吴逸飞', '0121701100516', '100', '100', '100', '100', '100', '100', '100', '100', '100'], ['孙金新', '0121701100521', '80', '100', '100', '100', '100', '100', '70', '100', '94'], ['杨旺霖', '0121701100527', '100', '100', '100', '100', '100', '100', '80', '100', '98'], ['孙钰伟', '0121701100623', '100', '100', '100', '100', '100', '100', '70', '100', '97'], ['张竣皓', '0121701100624', '100', '50', '100', '100', '50', '100', '70', '100', '84.5'], ['马全志', '0121701100627', '100', '100', '100', '100', '50', '100', '70', '50', '84.5'], ['刘钰婷', '0121701100631', '80', '100', '100', '100', '100', '100', '50', '100', '92'], ['张书玥', '0121701100635', '80', '100', '100', '100', '100', '100', '20', '100', '89'], ['禹策', '0121701101024', '80', '100', '100', '50', '50', '100', '0', '100', '77'], ['吴伊民', '0121701101113', '80', '100', '100', '50', '100', '100', '0', '50', '74.5'], ['朱金成', '0121701101117', '100', '100', '100', '100', '100', '100', '70', '100', '97'], ['徐庆庆', '0121701101206', '80', '100', '100', '100', '100', '100', '70', '100', '94'], ['杨彪', '0121701101212', '100', '100', '100', '100', '100', '100', '100', '100', '100'], ['石士鹏', '0121713590101', '100', '100', '100', '100', '50', '100', '0', '100', '85'], ['王浩', '0121713590105', '90', '100', '100', '100', '100', '100', '20', '100', '90.5'], ['胡鹏乾', '0121713590106', '100', '100', '100', '100', '0', '100', '0', '100', '80'], ['庄婧雯', '0121713590107', '100', '100', '100', '100', '100', '100', '0', '100', '90'], ['蔡渲渲', '0121713590108', '100', '100', '100', '100', '100', '100', '70', '100', '97'], ['陈蔚彤', '0121713590109', '90', '100', '100', '0', '100', '100', '40', '100', '82.5'], ['吴清清', '0121713590111', '100', '100', '100', '100', '100', '100', '70', '100', '97'], ['赖韦潇', '0121713590112', '100', '100', '100', '100', '100', '100', '100', '100', '100'], ['龙玉凤', '0121713590113', '100', '100', '100', '100', '100', '100', '10', '100', '91'], ['周梦瑶', '0121713590114', '80', '100', '100', '100', '100', '100', '90', '100', '96'], ['黄梦圆', '0121713590115', '90', '100', '100', '100', '100', '100', '0', '100', '88.5'], ['孙冉祺', '0121713590118', '80', '100', '100', '100', '50', '100', '30', '100', '85'], ['王蕾', '0121713590119', '100', '100', '100', '100', '50', '100', '20', '100', '87'], ['向欣然', '0121713590120', '80', '100', '100', '0', '0', '100', '60', '100', '73'], ['郑宇轩', '0121713590122', '100', '0', '100', '0', '0', '100', '70', '0', '47'], ['杨晶晶', '0121713590123', '100', '100', '100', '100', '100', '100', '0', '100', '90'], ['张雪迎', '0121713590124', '40', '100', '100', '0', '0', '100', '0', '100', '61'], ['买玉花', '0121713590125', '100', '0', '0', '0', '0', '0', '10', '0', '16'], ['龚馨雅', '0121713590127', '80', '100', '100', '0', '0', '100', '70', '25', '62.75'], ['柳茵茵', '0121713590128', '100', '100', '100', '0', '0', '100', '0', '100', '70'], ['胡馨', '0121713590129', '60', '0', '0', '0', '0', '0', '0', '0', '9'], ['赛乌来', '0121713590130', '80', '0', '100', '0', '0', '100', '0', '75', '48.25'], ['麦热帕提·玉山江', '0121713590131', '40', '0', '0', '0', '0', '0', '0', '25', '9.75'], ['胡蝶', '0121713590132', '80', '100', '100', '100', '100', '100', '60', '100', '93'], ['陈灵锋', '0121713590201', '100', '100', '100', '0', '50', '100', '0', '100', '75'], ['安闯', '0121713590202', '90', '100', '100', '100', '100', '100', '0', '100', '88.5'], ['周富成', '0121713590204', '100', '100', '100', '0', '100', '100', '0', '100', '80'], ['吴俊霖', '0121713590205', '100', '100', '100', '100', '100', '100', '30', '100', '93'], ['益西索朗', '0121713590206', '40', '0', '0', '0', '50', '100', '0', '50', '33.5'], ['刘天斯', '0121713590207', '90', '100', '100', '100', '100', '100', '20', '100', '90.5'], ['林欣洁', '0121713590208', '100', '100', '100', '100', '100', '100', '0', '100', '90'], ['张倩雯', '0121713590209', '100', '100', '100', '100', '100', '100', '100', '100', '100'], ['卢柔蓉', '0121713590210', '100', '100', '100', '0', '0', '100', '0', '100', '70'], ['黎敏琴', '0121713590211', '100', '100', '0', '0', '0', '100', '0', '100', '60'], ['张子薇', '0121713590212', '100', '100', '50', '0', '100', '100', '0', '100', '75'], ['张萌萌', '0121713590213', '100', '100', '100', '100', '100', '100', '20', '100', '92'], ['史思琪', '0121713590215', '100', '100', '100', '0', '50', '100', '0', '75', '71.25'], ['程赛', '0121713590217', '80', '100', '100', '100', '100', '100', '0', '100', '87'], ['王佳慧', '0121713590218', '100', '100', '100', '100', '100', '100', '100', '100', '100'], ['蒋依帆', '0121713590219', '80', '100', '100', '100', '100', '100', '0', '100', '87'], ['喻明珠', '0121713590221', '100', '100', '100', '100', '100', '100', '100', '100', '100'], ['赵雅如', '0121713590224', '100', '100', '100', '100', '100', '100', '10', '100', '91'], ['马明昊', '0121713590225', '80', '100', '100', '0', '0', '100', '0', '0', '52'], ['张奕博', '0121713590226', '90', '100', '100', '0', '50', '100', '0', '75', '69.75'], ['郑姗姗', '0121713590227', '100', '100', '100', '100', '100', '100', '90', '100', '99'], ['阿依巴努·阿里木江', '0121713590229', '60', '0', '0', '0', '100', '0', '40', '0', '23'], ['许展', '0121713590230', '80', '100', '100', '50', '100', '100', '20', '100', '84'], ['阿丽亚·阿布都热西提', '0121713590231', '90', '100', '100', '0', '50', '100', '0', '75', '69.75'], ['张攀', '0121713590232', '100', '100', '100', '0', '0', '100', '0', '100', '70'], ['郭琳', '0121713590303', '70', '50', '50', '50', '50', '100', '0', '100', '63'], ['张宁', '0121713590304', '90', '100', '100', '100', '100', '100', '80', '100', '96.5'], ['杨逸谦', '0121713590305', '100', '100', '100', '50', '100', '100', '0', '100', '85'], ['陈晶晶', '0121713590306', '80', '100', '100', '100', '50', '100', '20', '100', '84'], ['曹端宏', '0121713590307', '100', '100', '0', '0', '0', '0', '0', '50', '37.5'], ['闫梦菲', '0121713590308', '80', '100', '100', '100', '100', '100', '70', '100', '94'], ['魏瑜', '0121713590313', '80', '100', '100', '0', '0', '100', '0', '75', '63.25'], ['景明慧', '0121713590315', '80', '100', '100', '100', '0', '100', '0', '100', '77'], ['刘思洁', '0121713590316', '80', '100', '50', '0', '50', '100', '0', '100', '67'], ['陈慧玲', '0121713590317', '100', '100', '100', '0', '0', '100', '0', '100', '70'], ['王颖', '0121713590318', '100', '100', '100', '100', '100', '100', '10', '100', '91'], ['崔美晶', '0121713590321', '90', '50', '100', '50', '50', '100', '0', '100', '71'], ['翟云琪', '0121713590322', '90', '0', '0', '0', '0', '0', '0', '25', '17.25'], ['马怡宁', '0121713590324', '40', '100', '100', '0', '0', '100', '0', '0', '46'], ['李雅楠', '0121713590326', '100', '100', '100', '0', '50', '100', '10', '100', '76'], ['刘淼淼', '0121713590327', '80', '100', '100', '100', '100', '100', '20', '100', '89'], ['次旺巴珍', '0121713590328', '100', '0', '0', '0', '0', '0', '0', '0', '15'], ['爱克达·阿斯哈尔', '0121713590329', '100', '0', '100', '0', '50', '100', '30', '0', '48'], ['丁家玉', '0121713590330', '100', '100', '100', '0', '0', '100', '0', '100', '70'], ['关灵爽', '0121713590331', '80', '100', '100', '50', '100', '100', '20', '100', '84'], ['史雨阳', '0121415940402', '0', '0', '0', '0', '0', '0', '0', '0', '0'],
......
['杨俊', '0121713590203', '100', '100', '100', '0', '0', '100', '0', '100', '70']]
def read_csv(filename):
"""读文件到二维列表"""
with open(filename, 'r', encoding='utf-8') as f:
score_ls = [] # 创建空列表
for line in f: # 遍历文件对象
score_ls.append(line.strip().split(',')) # 切分后加入列表
return score_ls
def read_csv(filename):
"""读文件到二维列表,精简代码"""
with open(filename, 'r', encoding='utf-8') as f:
return [line.strip().split(',') for line in f]
def add_total(score_ls):
"""接收包含成绩的二维列表,
标题行增加”总成绩“列,计算总成绩并附加到列表中,
返回增加了总成绩的二维列表"""
total_score = [] # 创建空列表
title = score_ls[0] + ['总成绩'] # 修改标题行
total_score.append(title) # 新列表中加入标题行
for score in score_ls[1:]: # 遍历数据部分
total = round(sum(map(float, score[2:10])) / 8 * 0.7 + float(score[10]) * 0.3, 2)
total_score.append(score + [str(total)]) # 增加总成绩,加入列表
print(total_score)
return total_score
def write_file(total_score, filename):
"""接收成绩二维列表和写入文件名的字符串,
将二维列表中的数据分行写入文件,每个列表中的数据写为一行,用逗号分隔
无返回值"""
with open(filename, 'w', encoding='utf-8') as fw: # 写模式打开文件
for line in total_score: # 遍历二维列表
fw.write(','.join(line) + '\n') # 子列表元素用逗号拼接为字符串加换行符
if __name__ == '__main__':
score_lst = read_csv('../data/csv/成绩分析综合.csv')
score_all = add_total(score_lst)
write_file(score_all, '../data/csv/成绩分析综合2.csv')
[['姓名', '学号', '实验一', '实验二', '实验三', '实验四', '实验五', '实验六', '实验七', '实验八', '作业成绩', '总成绩'],
['叶灿', '0121701100312', '100', '100', '100', '100', '100', '100', '60', '100', '96', '95.3'],
能力点3:写数据到文件中
| 方法 | 描述 |
|---|---|
| write(b) | 将给定的字符串或字节流对象写入文件 |
| writelines(lines) | 将一个元素全为字符串的列表写入文件 |
示例9.5 列表写入csv文件
def write_to_csv(score):
"""接收二维列表为参数,将其写入到csv文件中"""
with open('temp.csv','w',encoding='utf-8') as fw: # 创建文件对象,写模式
for lst in score: # 遍历二维列表,依次取值为子列表,元素为字符串
line = ','.join(lst) + '\n' # 列表元素拼接为字符串,并在末尾拼接一个换行符
fw.write(line) # 把字符串line写入到文件对象fw中
if __name__ == '__main__':
score_ls = [['姓名', '学号', 'C语言', 'Java', 'Python', 'VB', 'C++', '总分'],
['朱佳', '0121701100511', '75.2', '93', '66', '85', '88', '407'],
['李思', '0121701100513', '86', '76', '96', '93', '67', '418'],
['郑君', '0121701100514', '', '98', '76', '', '89', '263'],
['王雪', '0121701100515', '99', '96', '91', '88', '86', '460'],
['罗明', '0121701100510', '95', '96', '85', '63', '91', '430']]
write_to_csv(score_ls)
temp.csv文件中的数据
姓名,学号,C语言,Java,Python,VB,C++,总分
朱佳,0121701100511,75.2,93,66,85,88,407
李思,0121701100513,86,76,96,93,67,418
郑君,0121701100514,,98,76,,89,263
王雪,0121701100515,99,96,91,88,86,460
罗明,0121701100510,95,96,85,63,91,430
JSON文件
JSON的编码过程是将一个Python对象转为JSON格式数据,
主要使用json.dumps(obj)和json.dump(obj,fp)两个方法。
json.dumps(obj, ensure_ascii=True, indent=None, sort_keys=False)
json.dump(obj,fp, ensure_ascii=True, indent=None,sort_keys=False)
json 中默认ensure_ascii=True, 会将中文等非ASCII 字符转为unicode 编码(形如\uXXXX),设置ensure_ascii=False 可以禁止JSON 将中文转为unicode 编码,保持中文原样输出。
Python中的字典数据转为JSON 默认不排序。可设置sort_keys=True使转换结果按照字典升序排序(a-z)。
indent 参数可用来对JSON 数据进行格式化输出,默认值为None,不做格式化处理,可设一个大于0 的整数表示缩进量,例如indent=4。输出的数据被格式化之后,变得可读性更好。
成绩分析综合.csv
import json
def read_csv(filename):
"""读文件到二维列表,返回二维列表"""
with open(filename, "r", encoding='utf-8') as f:
return [x.strip().split(',') for x in f]
def to_json(score_ls):
"""将二维列表标题行的元素与子列表中的元素一一组合,
禁止JSON 将中文转为unicode 编码,保持中文原样输出。
对JSON 数据进行格式化输出,缩进4个字符,
返回json格式数据"""
score_dic = []
for i in range(1, len(score_ls)):
score_dic.append(dict(zip(score_ls[0], score_ls[i])))
return json.dumps(score_dic, ensure_ascii=False, indent=4)
if __name__ == '__main__':
score_lst = read_csv('../data/csv/成绩分析综合.csv')
print(to_json(score_lst))
[
{
"姓名": "叶灿",
"学号": "0121701100312",
"实验一": "100",
"实验二": "100",
"实验三": "100",
"实验四": "100",
"实验五": "100",
"实验六": "100",
"实验七": "60",
"实验八": "100",
"作业成绩": "96"
},
{
"姓名": "朱宇轩",
"学号": "0121701100702",
"实验一": "100",
"实验二": "100",
"实验三": "100",
"实验四": "100",
"实验五": "100",
"实验六": "100",
"实验七": "90",
"实验八": "100",
"作业成绩": "99"
},
......
]
JSON的解码过程是将JSON格式数据转为Python对象。Python 的原始类型与JSON类型会相互转换,主要使用json.loads(s)和json.load(fp)两个方法。
| 方法 | 描述 |
|---|---|
| json.loads(s) | 将字符串s中的JSON数据解码为Python 数据类型,其他格式数据会转为unicode格式。 |
| json.load(fp) | 将磁盘文件对象fp中的JSON数据解码为Python 数据类型,其他格式数据会转为unicode格式。 |
import json
def read_json(filename):
"""读json文件,返回元素为字典类型的列表"""
with open(filename, "r", encoding='utf8') as f:
score_dic_ls = json.load(f)
return score_dic_ls
if __name__ == '__main__':
score_lst = read_json('../data/json/成绩分析综合.json')
print(score_lst)
直接读json可得到元素为字典的列表,数据与标题混在一起
[{'姓名': '叶灿', '学号': '0121701100312', '实验一': '100', '实验二': '100', '实验三': '100', '实验四': '100', '实验五': '100', '实验六': '100', '实验七': '60', '实验八': '100', '作业成绩': '96'},
{'姓名': '朱宇轩', '学号': '0121701100702', '实验一': '100', '实验二': '100', '实验三': '100', '实验四': '100', '实验五': '100', '实验六': '100', '实验七': '90', '实验八': '100', '作业成绩': '99'},
{'姓名': '陈一帆', '学号': '0121701100730', '实验一': '100', '实验二': '100', '实验三': '100', '实验四': '100', '实验五': '50', '实验六': '100', '实验七': '80', '实验八': '75', '作业成绩': '89.25'},
......
]
将标题提取出来,转为二维列表
import json
def read_json(filename):
"""读json文件,返回元素为字典类型的列表"""
with open(filename, "r", encoding='utf-8') as f:
score_dic_ls = json.load(f)
return score_dic_ls
def dic_to_ls(score_dic_ls):
"""元素为字典的列表转二维列表"""
score_ls = []
title = list(score_dic_ls[0].keys()) # 取标题转列表
score_ls.append(title) # 标题先加入二维列表
for i in range(0, len(score_dic_ls)): # 遍历列表
score_ls.append(list(score_dic_ls[i].values())) # 提取数据转列表
return score_ls # 返回二维列表
if __name__ == '__main__':
score_lst = read_json('../data/json/成绩分析综合.json')
dic_to_ls(score_lst)
print(dic_to_ls(score_lst))
[['姓名', '学号', '实验一', '实验二', '实验三', '实验四', '实验五', '实验六', '实验七', '实验八', '作业成绩'],
['叶灿', '0121701100312', '100', '100', '100', '100', '100', '100', '60', '100', '96'],
['朱宇轩', '0121701100702', '100', '100', '100', '100', '100', '100', '90', '100', '99'],
['陈一帆', '0121701100730', '100', '100', '100', '100', '50', '100', '80', '75', '89.25'],
......
]]
能力点4:批量自动读写文件
表 8.7 os库常用方法
| 方法 | 描述 |
|---|---|
| os.getcwd() | 获取当前工作路径 |
| os.chdir(path) | 将当前工作路径修改为path,如os.chdir(r’c:\Users’) |
| os.path.exist(name) | 判断name文件夹或文件是否存在,存在返回True,否则返回False |
| os.mkdir(pathname) | 新建一个名为pathname的文件夹 |
| os.rmdir(pathname) | 删除空文件夹pathname,文件夹不为空则报OSError错误 |
| os.path.isdir(path) | 判断path是否是文件夹,是则返回True,否则返回False |
| os.path.getsize(file) | 文件file存在,返回其大小(byte为单位),不存在则报错 |
| os.remove(filename) | 删除文件 filename,文件不存在则报错 |
| os.path.isfile(filename) | 返回filename是否是文件,是返回True,否则返回False |
| os.listdir(path) | 以列表形式返回path路径下的所有文件名,不包括子路径中的文件名 |
| os.walk(path) | 返回类型为生成器,包含数据为若干包含文件和文件夹名的元组数据 |
- P204页
表8.7中倒数第3行
os.isfile(filename)
修改为
os.path.isfile(filename)
import os
result = os.getcwd() # getcwd() 获取当前工作目录
print(result)
文件或文件夹重命名
import os
os.rename('02.txt','002.txt') # rename() 文件或文件夹重命名
获取指定文件夹中所有内容的名称列表
import os
result = os.listdir('D:/testpath/path/')
print(result)
示例9.6 批量改文件名
600000.csv
600006.csv
600007.csv
......
6000067.csv
6000068.csv
6000069.csv
import os
def read_to_dic():
"""读股票代码文件,返回以股票代码为键,以股票名为值的字典"""
stock_dic = {}
with open('../data/csv/stock/沪市股票top300.csv','r',encoding='utf-8') as stock:
for line in stock:
code, stock_name = line.strip().split(',')
stock_dic[code] = stock_name
return stock_dic
def re_name(file_ls):
"""遍历列表听文件名,修改对应文件名为股票代码对应的股票名"""
for line in file_ls: # 循环
os.rename(path + line, new_path + stock_dict.get(line[:-4],line[:-4]) + '.csv')
# 更名为Excel_01600000.csv
if __name__ == '__main__':
path = '../data/csv/stock/test_rename/' # 当前路径下的stock文件夹中有类似600000.csv的多个文件
new_path = '../data/csv/stock/test_rename/newname/' # 当前路径下的空文件夹
file_list = os.listdir(path)[:-1] # 获取文件夹中的文件名列表
# print(file_list) # ['600000.csv', '600004.csv', '600006.csv',...'沪市股票top300.csv']
stock_dict = read_to_dic() # 获取代码与股票名的字典
re_name(file_list)
['上海机场.csv', '上港集箱.csv', '东风汽车.csv', '中原高速.csv', '中国国贸.csv', '华夏银行.csv', '华能国际.csv', '宝钢股份.csv', '民生银行.csv', '浦发银行.csv', '白云机场.csv', '皖通高速.csv', '钢联股份.csv', '首创股份.csv']
示例9.7 批量处理多个文件中的数据
import os
import json
def filename_list(path):
"""接收路径字符串为参数,获取该路径下所有文件名,以列表形式返回
os.listdir(path)以列表形式返回path路径下的所有文件名,不包括子路径中的文件名"""
name_list = os.listdir(path) # 获取该路径下文件名列表
return name_list
def read_title(file):
"""接收文件名为参数,读取文件第一行为二维列表格式
文件第一行为:Date,High,Low,Open,Close,Volume,Adj Close
列表格式为:[['Stock code', 'Date', 'High', 'Low', 'Open', 'Close', 'Volume', 'Adj Close']]
"""
with open(file, 'r', encoding='utf-8') as file_title:
title = [['Stock code'] + file_title.readline().strip().split(',')]
print(title)
return title
def read_file(file):
"""接收文件名为参数,略过文件第一行,读取文件内容为二维列表格式
将主文件名部分以字符串类型加入,作为每个列表元素第一个元素
如文件名为:600000.csv
如文件的一行为: 2010-01-04,9.049530029296875,8.75574016571045,9.032979965209961,8.768150329589844,159964607.0,5.441317081451416
列表格式为:['600000', 2010-01-04,9.049530029296875,8.75574016571045,9.032979965209961,8.768150329589844,159964607.0,5.441317081451416]"""
with open(file, 'r', encoding='utf-8') as data:
data.readline()
data_ls = [[file[13:19]] + line.strip().split(',') for line in data]
print(data_ls)
return data_ls
def merge_data(path, name_list):
"""将stock下所有csv文件中的数据合并到一个列表中
列表第一个元素为['Stock code', 'Date', 'High', 'Low', 'Open', 'Close', 'Volume', 'Adj Close']"""
merge_list = read_title(path + '600000.csv')
for filename in name_list: # 遍历文件名列表
data_ls = read_file(path + filename) # 依次读取每个文件中的数据
merge_list = merge_list + data_ls # 合并数据到一个列表中
print(merge_list)
return merge_list
def list_to_dict(merge_list):
"""接收包含数据的列表,将其转为字典类型,列表第一个元素中的值分别作为键"""
list_of_dict = []
for i in range(1, len(merge_list)):
list_of_dict.append(dict(zip(merge_list[0], merge_list[i]))) # 用zip()函数将标题与其他元素中对应序号元素组成键值对
print(list_of_dict)
return list_of_dict
def dict_to_json(list_of_dict, filename):
"""接收元素为字典类型的列表和准备创建的json文件名为参数
将数据转为json格式写入文件,缩进4字符,保持中文原样输出"""
with open(filename, "w", encoding='utf-8') as dataJson:
json.dump(list_of_dict, dataJson, indent=4, ensure_ascii=False)
if __name__ == '__main__':
filepath = './data/stock/' # 文件名
stock_list = []
stock_code_list = filename_list(filepath)
merge_csv_list = merge_data(filepath, stock_code_list)
merge_csv_dict = list_to_dict(merge_csv_list)
file_in_json = './data/stock.json'
dict_to_json(merge_csv_dict, file_in_json)
能力点5:NumPy读文件
numpy.genfromtxt(fname, dtype=<class 'float'>, comments='#',
delimiter=None, skip_header=0,skip_footer=0,
missing_values=None, filling_values=None,
usecols=None, autostrip=False,
max_rows=None, encoding='bytes'…)
- fname:
文件、字符串、字符序列或生成器。生成器必须是能在Python 3 中返回字节字符类型。列表或生成器中的字符串被当成行来处理。
2. dtype:
生成数组的数据类型,默认值是dtype=float。设置dtype=None 时,每个列的类型从每行的各列数据中迭代确定。函数依次检查各列数据是否可以转换为布尔值、整数、浮点数、复数和字符串,直到满足条件为止。但这种方法处理速度明显慢于明确设置dtype 数据类型。
因数据第一行是字符串,dtype 默认值是float,字符串无法转为浮点数,此处用dtype=str 将所有数据转为字符串类型,从输出可以发现,郑君缺失的两门课的成绩被读取为空字符串。全部数据为数组类型,数据间用空格分隔。import numpy as np file = '8.5 score.csv' data = np.genfromtxt(file, dtype=str, delimiter=',', encoding='utf-8') # 字符串类型 print(data)[['姓名' '学号' 'C语言' 'Java' 'Python' 'VB' 'C++' '总分'] ['朱佳' '0121701100511' '75.2' '93' '66' '85' '88' '407'] ['李思' '0121701100513' '86' '76' '96' '93' '67' '418'] ['郑君' '0121701100514' ' ' '98' '76' ' ' '89' '263'] ['王雪' '0121701100515' '99' '96' '91' '88' '86' '460'] ['罗明' '0121701100510' '95' '96' '85' '63' '91' '430']] - comments:
字符串或字符串序列,可选参数comments 用于指明注释开始的字符,默认情况下,genfromtxt假设为comments=’#’。注释标记可以出现在该行的任何地方,注释符号后面的所有字符都会被忽略。
4. delimiter:
值为字符串、整数或序列。genfromtxt() 函数将每个非空行拆分为一个字符串序列,delimiter 参数用于定义如何拆分数据行。其值为字符串时,用这个字符串作为分隔符,默认为用任何空白字符分隔,如空格、制表符等,连续多个空白字符视为一个。处理具有固定宽度的数据文件时,可用整数或整数序列确定每个字段的宽度。当所有列具有相同宽度时,值可设为单个整数;当各列宽度具有不同大小时,值可设为一个整数的序列。
5. skip_header:
值为整数。文件开头数据描述的存在可能阻碍数据处理,此时可以使用skip_header 参数。参数的值对应于在执行任何其他操作之前在文件开头跳过的行数,缺省值为skip_header=0,表示不略过任何行。类似地,我们可以使用skip_footer 属性并赋予n 的值来跳过文件的最后n 行,缺省值为skip_footer=0,表示不跳过任何行。
设置参数 skip_header =1 略过文件开头的1 行数据。后面的每列数据的类型都是相同的,可设置参数dtype =None 由系统判定各列的数据类型为整数、浮点数或字符串。由输出可以看到“姓名”列被判定为字符串类型;“C语言”成绩列因包含浮点数,所以整列被判定为浮点数,缺失数据默认用非数值类型“nan”填充;其他列被判定为整数,缺失数据用“-1”进行填充。import numpy as np file = '8.5 score.csv' data = np.genfromtxt(file, dtype=None, delimiter=',', skip_header=1, encoding='utf-8') print(data)
输出:[('朱佳', 121701100511, 75.2, 93, 66, 85, 88, 407) ('李思', 121701100513, 86. , 76, 96, 93, 67, 418) ('郑君', 121701100514, nan, 98, 76, -1, 89, 263) ('王雪', 121701100515, 99. , 96, 91, 88, 86, 460) ('罗明', 121701100510, 95. , 96, 85, 63, 91, 430)] - usecols:
整数序列,指明哪些列将被读取,序号从0 开始。在某些情况下,只希望返回其中的几个列的数据,可以使用usecols 参数选择要导入哪些列。此参数接受单个整数或对应于要导入的列的索引的整数序列。例如:“usecols = (1, 4, 5)”将读取第2 列、第5 列和第6 列数据。
7. unpack:
布尔值,默认值为False,当该值为True 时,返回的数组将被转置,以便可以使用x, y, z = genfromtxt(…) 解压参数。当unpack 参数与记录数据类型一起使用时,每个字段都返回数组。
从输出中可以看到,原来的列的数据现在变成数组中的一行,可以更方便的对原来的列数据进行统计分析,例如计算每门课的平均成绩、中位数等:import numpy as np file = '8.5 score.csv' name, python, total = np.genfromtxt(file, dtype=None, delimiter=',', usecols=(0, 4, 7), unpack=True, filling_values=0, encoding='utf-8') print(name) print(python) print(total)['姓名' '朱佳' '李思' '郑君' '王雪' '罗明'] ['Python' '66' '96' '76' '91' '85'] ['总分' '407' '418' '263' '460' '430'] - filling_values:
用设置的值做作为默认值替代缺失数据。
设置 filling_values=0 可以在输出时遇到缺失数据用数字“0”填充。import numpy as np file = '8.5 score.csv' data = np.genfromtxt(file, dtype =None, delimiter=',', filling_values=0, skip_header=1, encoding='utf-8') # filling_values=0用0填充缺失数据 print(data)[('朱佳', 121701100511, 75.2, 93, 66, 85, 88, 407) ('李思', 121701100513, 86. , 76, 96, 93, 67, 418) ('郑君', 121701100514, 0. , 98, 76, 0, 89, 263) ('王雪', 121701100515, 99. , 96, 91, 88, 86, 460) ('罗明', 121701100510, 95. , 96, 85, 63, 91, 430)] - names:
值为None、True、字符串或序列之一,当值为“True”时,跳过文件开头的skip_header 设定的行数后读取的第1行作为字段名。这行也可选被注释符号注释的行。如果names 参数的值为序列或是被逗号分隔的字符串序列,那么这些字符串将被用于定义结构化类型的字段名。如果names 参数的值为None,将使用原字段的数据类型作为字段名。
设置names = True 将读取的第一行数据作为字段名,以便用字段名作为索引对数据进行处理。例如可以同时用’姓名’、’学号’ 和’Python’ 三个列名放入一个列表做字段名进行索引,返回所有同学“Python”课程的成绩数据。import numpy as np file = '8.5 score.csv' data = np.genfromtxt(file, dtype =None,delimiter=',', names=True, filling_values=0, encoding='utf-8') print(data[['姓名','学号','Python']]) # 以多个字段为索引时,放入列表中[('朱佳', 121701100511, 66) ('李思', 121701100513, 96) ('郑君', 121701100514, 76) ('王雪', 121701100515, 91) ('罗明', 121701100510, 85)] - autostrip:
默认为False,当一行被分解为一系列字符串时,各个字符串前导或结尾的空白字符不会被删除。设置autostrip=True,可以自动删除字符串前导或结尾的空白字符。
import numpy as np
file = '8.5 score.csv'
data = np.genfromtxt(file ,dtype=None,delimiter=',',unpack=True, filling_values=0, encoding='utf-8') # unpack = True,数组转置
name, id, c,java,python,vb,cplus,sum =data
print(name) # 输出 ['姓名' '朱佳' '李思' '郑君' '王雪' '罗明']
print(python) # 输出['Python' '66' '96' '76' '91' '85']
print(sum) # 输出['总分' '407' '418' '263' '460' '430']
- max_rows:
值为整数,指明跳过开头skiprows 行后,读取的行数,值缺省时读取所有行。
12. encoding:
值为字符串,用于指定解码输入文件的编码类型,当“fname”是文件对象时不可使用此参数。当值设置为“None”时,应用操作系统的默认编码,一般windows系统默认使用CP936(GBK)编码。默认值为“bytes”,此时启用向后兼容的方案,确保在可能的情况下接收字节数据,并将拉丁编码的字符串传给转换器。重写此值将可以接收unicode 数组并将字符串作为输入传递给转换器。
NumPy库中与genfromtxt() 函数功能类似还有一个loadtxt() 函数,也可以用于读取文件中的数据。loadtxt() 函数的目标是快速读取简单格式化的文件,要求目标文件每一行具有相同数量的数据。
函数的详细参数如下,主要参数的含义和用法与genfromtxt() 函数的参数类似:
numpy.loadtxt(fname, dtype=<class 'float'>, comments='#',
delimiter=None, converters=None,skiprows=0,
usecols=None, unpack=False, ndmin=0,
encoding='bytes',max_rows=None)
示例9.8 利用NumPy 读写数据文件
文件“8.5 scoreLoad.csv” 保存学生成绩数据,中文编码类型为utf-8,分隔符为英文逗号“,”,文件的内容如下,按要求完成以下操作:
1. 将文件读入数组,数据以字符串形式输出
2. 读取除学号和总分以外的数据到数组中
3. 返回只包含成绩数据的数组,数据转为浮点型
4. 将第3步读取的数组中的数据以字符串类型写入文本文件“scoresave.txt”中,用空格作分隔符
姓名,学号,C语言,Java,Python,VB,C++,总分
朱佳,0121701100511,75,93,66,85,88,407
李思,0121701100513,86,76,96,93,67,418
郑君,0121701100514,88,98,76,90,89,441
王雪,0121701100515,99,96,91,88,86,460
罗明,0121701100510,95,96,85,63,91,430
观察文件内容,发现每一行数据的数量都相同,没有缺失数据,可以利用loadtxt() 函数完成对其的读写:
1. 数据以字符串形式输出,分隔符为逗号,指明编码类型为’utf-8’:
import numpy as np
file = '8.5 score.csv'
data = np.genfromtxt(file, dtype=str, delimiter=',', encoding='utf-8') # 字符串类型
print(data)
[['姓名' '学号' 'C语言' 'Java' 'Python' 'VB' 'C++' '总分']
['朱佳' '0121701100511' '75.2' '93' '66' '85' '88' '407']
['李思' '0121701100513' '86' '76' '96' '93' '67' '418']
['郑君' '0121701100514' ' ' '98' '76' ' ' '89' '263']
['王雪' '0121701100515' '99' '96' '91' '88' '86' '460']
['罗明' '0121701100510' '95' '96' '85' '63' '91' '430']]
2.读取除学号和总分以外的数据,用usecols 值指定读取数据列的序号:
file = '8.5 scoreLoad.csv'
data = np.loadtxt(file, str, usecols=(0, 2, 3, 4, 5, 6), delimiter=',', encoding='utf-8')
# usecols为整数序列,指明读取0, 2, 3, 4, 5, 6列,略过学号和总分
print(data)
输出
[['姓名' 'C语言' 'Java' 'Python' 'VB' 'C++']
['朱佳' '75' '93' '66' '85' '88']
['李思' '86' '76' '96' '93' '67']
['郑君' '88' '98' '76' '90' '89']
['王雪' '99' '96' '91' '88' '86']
['罗明' '95' '96' '85' '63' '91']]
- 用skiprows=1 略过第一行数据,只读取成绩数据,并转为默认数值类型(浮点型)
file = '8.5 scoreLoad.csv' data = np.loadtxt(file, usecols=(2, 3, 4, 5, 6, 7), delimiter=',', skiprows=1, encoding='utf-8') print(data)
[[ 75. 93. 66. 85. 88. 407.]
[ 86. 76. 96. 93. 67. 418.]
[ 88. 98. 76. 90. 89. 441.]
[ 99. 96. 91. 88. 86. 460.]
[ 95. 96. 85. 63. 91. 430.]]
Numpy写文件
NumPy提供了savetxt()方法用于保存数组到文本文件,其语法和参数如下,其中大数据分参数的意义与genfromtxt()函数相似,此处不再赘述。
numpy.savetxt(fname, X, fmt='%.18e', delimiter=' ',
newline='\n', header='', footer='',
comments='#', encoding=None)
参数中encoding 的值为“None”或字符串,用于指定编码输出文件的编码类型,当输出为字节流时此参数不可用。
4.将读取的数组中的数据以字符串类型写入文本文件“scoresave.txt”中
file = '8.5 scoreLoad.csv'
data = np.loadtxt(file, usecols=(2, 3, 4, 5, 6, 7), delimiter=',', skiprows=1, encoding='utf-8')
np.savetxt('8.5 scoresave.txt', data, fmt="%s", delimiter=' ', encoding='utf-8')
文件“scoresave.txt”中的数据如下:
75.0 93.0 66.0 85.0 88.0 407.0
86.0 76.0 96.0 93.0 67.0 418.0
88.0 98.0 76.0 90.0 89.0 441.0
99.0 96.0 91.0 88.0 86.0 460.0
95.0 96.0 85.0 63.0 91.0 430.0
数组统计函数
| 函数 | 描述 | 函数 | 描述 |
|---|---|---|---|
| amin()/nanmin() | 最小值/忽略非数值最小值 | amax()/nanmax() | 最大值/忽略非数值最大值 |
| argmax() | 最大值索引 | argmin() | 最小值索引 |
| cumsum() | 所有元素累加 | cumprod() | 所有元素累乘 |
| mean()/nanmean() | 平均值/忽略非数值平均值 | average() | (加权)平均值 |
| median()/nanmedian() | 中位数/忽略非数值中位数 | std()/nanstd() | 标准差/忽略非数值标准差 |
| var()/nanvar() | 方差/忽略非数值方差 | cov() | 协方差 |
| sum() | 对数组元素进行求和 | ptp() | 极差 |
import numpy as np
arr = np.random.randint(100, size=(3, 4))
print(np.max(arr), np.argmax(arr)) # 数组最大值及位置序号,输出 98 2
print(np.cumsum(arr)) # 数组元素逐个累加,[ 35 92 190 287 314 378 460 536 565 656 711 808]
print(np.mean(arr)) # 返回平均值,输出 67.33333333333333
print(np.median(arr)) # 返回中位数,输出 70.0
数组索引和切片
import numpy as np
arr = np.arange(36).reshape(6, 6) # 创建数组,转成6行6列
print(arr) # 返回数组所有元素,查看数据
[[ 0 1 2 3 4 5]
[ 6 7 8 9 10 11]
[12 13 14 15 16 17]
[18 19 20 21 22 23]
[24 25 26 27 28 29]
[30 31 32 33 34 35]]
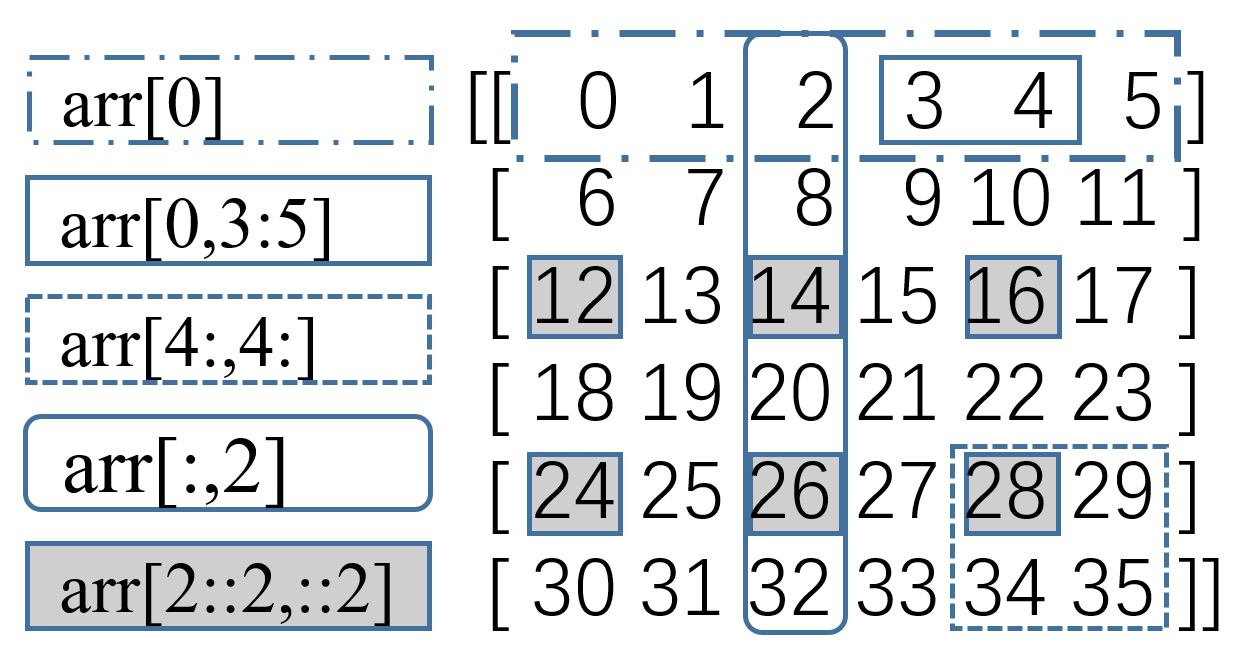
import numpy as np
arr = np.arange(36).reshape(6, 6) # 创建数组,转成6行6列
print(arr) # 返回数组所有元素,查看数据
print(arr[0]) # 返回序号0的行,[0 1 2 3 4 5]
print(arr[0,3:5]) # 返回序号0的行中列序号为3和4的数据,[3 4]
print(arr[:,2]) # 返回每行中序号为2的数 [ 2 8 14 20 26 32]
print(arr[4:,4:]) # 返回从第4行开始,列序号大于等于4的数据
print(arr[2::2,::2]) # 返回序号从2开始的偶数行中,列序号为偶数的数
示例9.9 利用numpy 分析成绩
文件“8.6 score.csv”内容为学生成绩数据,读取文件中的数据并进行统计分析,输出python 课程的平均成绩、成绩中位数、标准差,输出罗明同学的平均成绩。
姓名,学号,高数,英语,python,物理,java,C语言
罗明,1217106,95,85,96,88,78,90
金川,1217116,85,86,90,70,88,85
戈扬,1217117,80,90,75,85,98,95
罗旋,1217119,78,92,85,72,95,75
蒋维,1217127,99,88,65,80,85,75
np.loadtxt() 可读取文件中的数据到数组中,此时数据为字符串型。
data = np.loadtxt(file, str, delimiter=',', encoding='utf-8')
data数据格式
[['姓名' '学号' '高数' '英语' 'python' '物理' 'java' 'C语言']
['罗明' '1217106' '95' '85' '96' '88' '78' '90']
['金川' '1217116' '85' '86' '90' '70' '88' '85']
['戈扬' '1217117' '80' '90' '75' '85' '98' '95']
['罗旋' '1217119' '78' '92' '85' '72' '95' '75']
['蒋维' '1217127' '99' '88' '65' '80' '85' '75']]
在进行统计分析时,数组必须是数值类型,而从文件中读取的都是字符型数据,其中非数字型的数字无法转为数字型,所以将原数组中可转为数字型的数据提取出来,重新创建一个数组,以方便后续的统计分析。
将数组data中非数字字符串部分去掉生成新数组
scoreNum = data[1:, 2:].astype(int)
切片后数据格式 :
[[95 85 96 88 78 90]
[85 86 90 70 88 85]
[80 90 75 85 98 95]
[78 92 85 72 95 75]
[99 88 65 80 85 75]]
利用NumPy进行数据统计和分析非常方便,当数据量较大时,其效率也非常高。
import numpy as np
def read_csv(file):
"""接收表示文件名的字符串为参数,读取文件中的数据到数组中,返回数组。"""
data = np.loadtxt(file, str, delimiter=',', encoding='utf-8')
return data
def statistics(data):
"""接收一个numpy数组为参数,对数组data中的数据进行统计分析,直接输出分析结果,
需要输出python平均成绩、python成绩中位数、python成绩标准差和罗明平均成绩,无返回值。
"""
score_num = data[1:, 2:].astype(int) # 切取成绩数据转整型生成新数组
print(f'{np.mean(score_num[:, 2])}') # python平均成绩:82.2
print(f'{np.median(score_num[:, 2])}') # python成绩中位数:85.0
print(f'{round(np.std(score_num[:, 2]), 2)}') # python成绩标准差:11.02
print(f'{round(np.mean(score_num[0, 0:]), 2)}') # 罗明平均成绩:88.67
if __name__ == '__main__':
filename = '8.6 score.csv' # 定义文件名,方便修改
score = read_csv(filename) # 读文件到数组 score
statistics(score) # 数组 score中的数据传给statistics进行分析
能力点6:Pandas 读写文件
Pandas输入输出API提供了对文本、二进制和结构化查询语言(SQL)等不同格式类型文件的读写函数
可以方便的读取不同类型的文件并转为另一种类型的文件
read_csv()/to_csv()
read_json()/to_json()
read_excel()/to_excel()
read_html()/to_html()
read_clipboard()/to_clipboard
read_pickle()/to_pickle()
read_sql()/to_sql()
read_gbq()/to_gbq()
示例9.10 pandas读文件转列表
import pandas as pd
def pd_read(file):
"""利用pandas读文件中的数据并转为列表
后续用python方法继续处理数据"""
df = pd.read_csv(file) # 读文件到dataframe中
title = df.columns.tolist() # 标题行转为一维列表
# ['姓名', '学号', 'C语言', 'Java', 'Python', 'VB', 'C++', '总分']
data = df.values.tolist() # 数据转二维列表
return [title] + data # 拼接为二维列表
if __name__ == '__main__':
filename = '../data/csv/8.5 score.csv'
score = pd_read(filename)
print(score)
[['姓名', '学号', 'C语言', 'Java', 'Python', 'VB', 'C++', '总分'],
['朱佳', 121701100511, '75.2', 93, 66, '85', 88, 407],
['李思', 121701100513, '86', 76, 96, '93', 67, 418],
['郑君', 121701100514, ' ', 98, 76, ' ', 89, 263],
['王雪', 121701100515, '99', 96, 91, '88', 86, 460],
['罗明', 121701100510, '95', 96, 85, '63', 91, 430]]
示例9.11 利用pandas将csv转为json文件
import pandas as pd
def pd_csv_json(file):
"""利用pandas读csv文件中并转为json文件"""
df = pd.read_csv(file) # 读文件到dataframe中
df.to_json('score2022.json', indent=4,orient="records", force_ascii=False)
if __name__ == '__main__':
filename = '../data/csv/8.5 score.csv'
pd_csv_json(filename)
[
{
"姓名":"朱佳",
"学号":121701100511,
"C语言":"75.2",
"Java":93,
"Python":66,
"VB":"85",
"C++":88,
"总分":407
},
{
"姓名":"李思",
"学号":121701100513,
"C语言":"86",
"Java":76,
"Python":96,
"VB":"93",
"C++":67,
"总分":418
},
{
"姓名":"郑君",
"学号":121701100514,
"C语言":" ",
"Java":98,
"Python":76,
"VB":" ",
"C++":89,
"总分":263
},
{
"姓名":"王雪",
"学号":121701100515,
"C语言":"99",
"Java":96,
"Python":91,
"VB":"88",
"C++":86,
"总分":460
},
{
"姓名":"罗明",
"学号":121701100510,
"C语言":"95",
"Java":96,
"Python":85,
"VB":"63",
"C++":91,
"总分":430
}
]
利用Pandas读取数据后,可采用切片的方法查看其中指定的部分数据,也可用head(n)和tail(n)方法查看开始或结尾的n行数据。
返回姓名和学号两列的前3个数据
import pandas as pd
a = pd.read_csv('8.5.2 score.csv', encoding='utf-8') # 转dataframe
print(a[['姓名', '学号']][:3]) # 返回姓名和学号两列的前3个数据
输出
姓名 学号
0 刘雨 121701100507
1 刘傲 121701100510
2 张强 121701100512
返回前 n 行数据
import pandas as pd
a = pd.read_csv('8.5.2 score.csv', encoding='utf-8') # 转dataframe
print(a.head(n=3)) # 返回前3行数据,n缺省时返回5行
姓名 学号 C C++ Java Python C# 总分
0 刘雨 121701100507 20 20 20 16 20 96
1 刘傲 121701100510 20 10 10 0 15 55
2 张强 121701100512 20 20 20 18 20 98
返回后 n 行数据
import pandas as pd
a = pd.read_csv('8.5.2 score.csv', encoding='utf-8') # 转dataframe
print(a.tail(n=3)) # 返回后3行数据,n缺省时返回5行
姓名 学号 C C++ Java Python C# 总分
84 关爽 121713590331 20 10 20 4 20 74
85 史阳 121415940402 0 0 0 0 0 0
86 杨俊 121713590203 20 0 0 0 20 40
示例 9.12利用pandas读文件中的数据并排序
根据值进行排序,“总分”是排序依据的列,默认为升序排序,如需降序排序,使用ascending=False参数。[:5]是对数据进行切片,只输出前5个数据。
import pandas as pd
a = pd.read_csv('8.5.2 score.csv', encoding='utf-8')
print(a.sort_values('总分', ascending=False)[:5])
输出:
姓名 学号 C C++ Java Python C# 总分
56 喻明 121713590221 20 20 20 20 20 100
3 吴飞 121701100516 20 20 20 20 20 100
23 赖潇 121713590112 20 20 20 20 20 100
47 张倩 121713590209 20 20 20 20 20 100
15 杨彪 121701101212 20 20 20 20 20 100
数据统计
NumPy中提供了一系列的统计函数可用于对数据的描述性统计,Pandas基于NumPy库,也可以应用这些函数。
import pandas as pd
import numpy as np
a = pd.read_csv('8.5.2 score.csv', encoding='utf-8')
print(round(np.mean(a['总分']), 2)) # 返回总分平均值63.05
Pandas也提供了一些数值型数据的统计方法,可以更方便的实现数据的统计,总分平均值的计算也可以直接使用Pandas中的mean()方法实现。表8.10 中列出了Pandas中提供的统计方法,可以用于各种统计运算。
import pandas as pd
a = pd.read_csv('8.5.2 score.csv', encoding='utf-8')
print(round(a['总分'].mean(), 2)) # 返回总分平均值63.05
表8.10 Pandas描述统计方法
| 方法名称 | 描述 | 方法名称 | 描述 |
|---|---|---|---|
| count() | 非空值数目 | std() | 样本标准差 |
| sum() | 求和 | var() | 方差 |
| mean() | 平均值 | sem() | 标准误差 |
| mad() | 平均绝对偏差 | skew() | 样本偏离 |
| median() | 中位数 | kurt() | 样本峰度 |
| min() | 最小值 | quantile() | 样本分位数 |
| max() | 最大值 | cumsum() | 累加 |
| mode() | 众数 | cumprod() | 累乘 |
| abs() | 绝对值 | cummax() | 累积最大值 |
| prod() | 乘积 | cummin() | 累积最小值 |
在数据分析的过程中,可以先将数据拆分成组,对每个分组的数据应用函数进行统计,再汇总计算结果。
示例9.13 利用Pandas 做数据分析
数据在数据库中存储时,经常要进行规范化设计,以减少冗余和方便维护。文件“8.7 scoregroup.csv”中的数据是从数据库中导出的,存放着多名同学5 门课程的成绩。请分别统计每位同学的平均成绩、最高成绩和最低成绩;每门课程的平均成绩、最高成绩和最低成绩。
姓名,学号,课程名,分数
刘雨,0121701100507,高数,80
刘雨,0121701100507,英语,88
刘雨,0121701100507,程序设计,96
刘雨,0121701100507,物理,82
刘雨,0121701100507,经济,95
刘傲,0121701100510,高数,85
......
刘婷,0121701100631,物理,85
刘婷,0121701100631,经济,90
这个问题用前面知识解决时,需要分别把每位同学的成绩提取出来再计算其平均成绩,再把每门课程的成绩分别取出来计算课程平均成绩。利用Pandas 中的索引和分组等功能可以极方便的完成。
下面先给出平均成绩的计算方法:
import pandas as pd
a = pd.read_csv('8.7 scoregroup.csv', encoding='utf-8')
print(a['分数'].groupby(a['姓名']).mean()) # 返回每个人的平均分
输出:
姓名
刘傲 77.0
刘婷 84.0
刘雨 88.2
吴飞 77.2
孙伟 82.0
孙新 76.2
张强 90.0
张皓 66.4
杨霖 69.4
马志 80.0
Name: 分数, dtype: float64
import pandas as pd
a = pd.read_csv('8.7 scoregroup.csv', encoding='utf-8')
print(a['分数'].groupby(a['课程名']).mean()) # 返回每门课的平均分
输出
课程名
物理 77.5
程序设计 78.3
经济 79.6
英语 82.1
高数 77.7
Name: 分数, dtype: float64
可以应用agg()函数对分组结果进行汇总,同时完成平均成绩、最高成绩和最低成绩的统计:
import pandas as pd
a = pd.read_csv('8.7 scoregroup.csv',encoding='utf-8')
print(a['分数'].groupby(a['姓名']).agg(['mean', 'max', 'min']))
输出
mean max min
姓名
刘傲 77.0 87 66
刘婷 84.0 90 80
刘雨 88.2 96 80
吴飞 77.2 83 69
孙伟 82.0 88 78
孙新 76.2 94 56
张强 90.0 95 85
张皓 66.4 76 58
杨霖 69.4 86 46
马志 80.0 90 67
import pandas as pd
a = pd.read_csv('8.7 scoregroup.csv',encoding='utf-8')
print(a['分数'].groupby(a['课程名']).agg(['mean', 'max', 'min']))
输出
mean max min
课程名
物理 77.5 92 56
程序设计 78.3 96 46
经济 79.6 95 63
英语 82.1 95 67
高数 77.7 88 58

若有收获,就点个赞吧
0 人点赞
