直方图又称质量分布图,它是表示资料变化情况的一种主要工具。用直方图可以解析出数据的规则性,比较直观地看出产品质量特性的分布状态,对于资料分布状况一目了然,便于判断其总体质量分布情况。直方图表示通过沿数据范围形成分箱,然后绘制矩形条以显示落入每个分箱的观测次数的数据分布。<br /> 核密度估计(Kernel Density
Estimation)是在概率论中用来估计未知的密度函数,属于非参数检验方法之一。由于核密度估计方法不利用有关数据分布的先验知识,对数据分布不附加任何假定,是一种从数据样本本身出发研究数据分布特征的方法,因而,在统计学理论和应用领域均受到高度的重视。
displot()集合了Matplotlib的直方图(hist())与核密度估计(kdeplot)的功能,增加了rugplot分布观测条显示与利用scipy库fit拟合参数分布的新颖用途。具体参数及部分参数意义如下:
seaborn.distplot(a, bins=None, hist=True, kde=True,rug=False, fit=None, hist_kws=None,kde_kws=None, rug_kws=None, fit_kws=None,color=None, vertical=False, norm_hist=False,axlabel=None, label=None, ax=None)
(1)
a : series或一维数组或列表类型的数据
(2)
bins : 设置矩形条的数量
(3)
hist : 控制是否显示条形图
(4)
kde : 控制是否显示核密度估计图
(5)
rug : 控制是否显示观测的小细条(边际毛毯)
(6)
fit : 控制拟合的参数分布图形
(7)
vertical : 显示正交控制
绘制直方图时,需要调整的主要参数是bin的数目(组数)。displot()会默认给出一个它认为比较好的组数,尝试不同的组数可能会揭示出数据不同的特征。绘制直方图时,最重要的参数是bin以及vertical,他们可以确定直方图的组数和放置位置
核密度估计图使用的较少,但他是绘制出数据分布的有用工具,与直方图类似,KDE图以一个轴的高度为准,沿着另外的轴线编码观测密度。根据Iris绘制直方图与核密度估计图的效果如图10.35所示。
接下来还是通过具体的例子来体验一下distplot的用法:
import pandas as pd # 导入pandas库import warnings # 载入当前版本seaborn库时会有警告出现,先载入warnings,忽略警告import seaborn as sns # 导入seaborn库import matplotlib.pyplot as plt # 导入matplotlib库warnings.filterwarnings("ignore") # 忽略警告sns.set(style="white", color_codes=True) # 确定主题为whiteiris = pd.read_csv("iris.csv") # 读取csv数据并转为Pandas的 DataFrame格式fig, axes = plt.subplots(1,2)sns.distplot(iris['PetalLengthCm'],ax = axes[0], kde = True, rug = True) # kde 密度曲线sns.kdeplot(iris['PetalLengthCm'],ax = axes[1], shade=True) # shade 阴影plt.show()
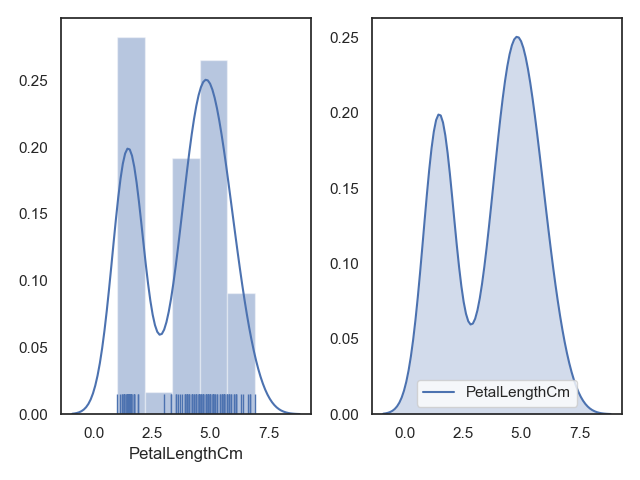
直方图与核密度估计图
可以在同一图内对数据进行分类再以直方图和核密度估计图的形式进行可视化。分类直方图与核密度估计图的效果如图所示。
import seaborn as sns # 导入seaborn库import matplotlib.pyplot as plt # 导入matplotlib库warnings.filterwarnings("ignore") # 忽略警告sns.set(style="white", color_codes=True) # 确定主题为whiteiris = pd.read_csv("iris.csv") # 读取csv数据并转为Pandas的 DataFrame格式sns.FacetGrid(iris, hue="Species",size=6).map(sns.distplot, "PetalLengthCm").add_legend()plt.show()
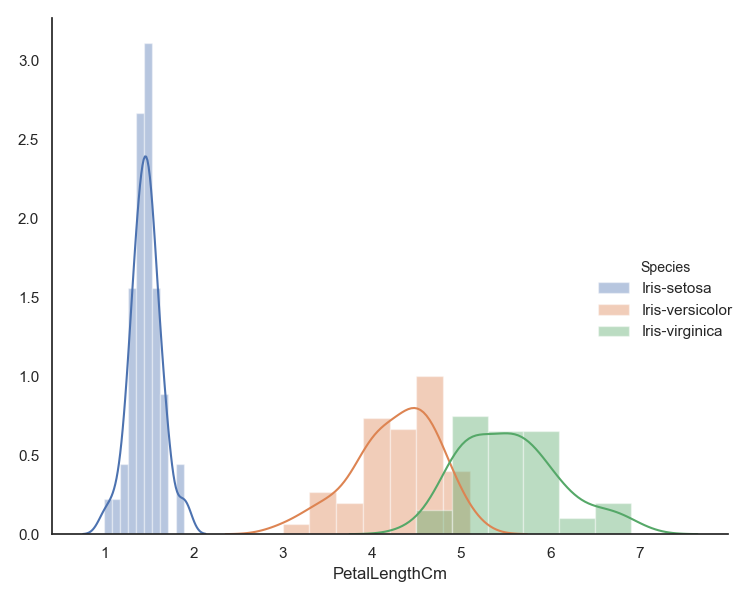
分类直方图与核密度估计图

若有收获,就点个赞吧
0 人点赞
