以字段映射为例,带你了解B端页面该如何设计!_风筝KK-站酷ZCOOL
做B端的同学,在工作中常会遇到这样几个问题:
不知道如何分析需求,原型怎么画就怎么设计
评审的时候说不出为什么这样设计
想优化产品,但是没思路
拿到产品原型,不知如何下手
设计稿总是改来改去
该如何提升呢?
这篇文章我将用实际的案例和大家分享,如何去解决这些问题。问题解决之前,我们先了解为什么会出现这些问题,主要有三个原因:
1、对业务不了解
2、对需求不清晰
3、B端设计经验少
下面我以B端数据平台中常见的字段映射为例,和大家分享如何快速了解业务;如何进行需求梳理;如何进行方案设计。
调研在设计工作流程中是重要的一环,他很大程度的决定了我们设计的可用性、易用性、客户满意度等,但是对于一般公司来说,并没有专门的UX岗、调研人员,这些工作基本都需要UE/UI的同学来做。
然而,现在很多团队都采用敏捷的开发方式,一般2周就需要迭代一次,因此,界面设计一般会前置在需求设计阶段,并且要求在需求评审时,必须交互一定量的设计稿,以供技术开发。

因此这就要求设计师必须能在短时间设计出一个可用性、易用性、客户满意度较好的设计方案。这就导致一些设计师没有太多时间思考,拿着原型就直接设计,久而久之就习惯了这种舒适圈。
如何在短时间内做出一个较好的设计方案呢?下面我以字段映射为例,和大家详细分享我的分析流程。
1、提前和PM了解下个迭代需要
建议在PM原型阶段就可以询问下个迭代要做什么,利用空余时间提前了解业务,快速的体验下相关竞品,实在体验不了的产品,就去查看下他的产品文档,视频介绍等,一些大平台在B站一般都有相关的讲解,也可以去看看,帮助理解。
具体怎么找资料,这里我就不献丑了,和大家分享下我收集了哪些资料:一些竞品的截图和语雀整理的《阿里云、AWS数据同步对比》。

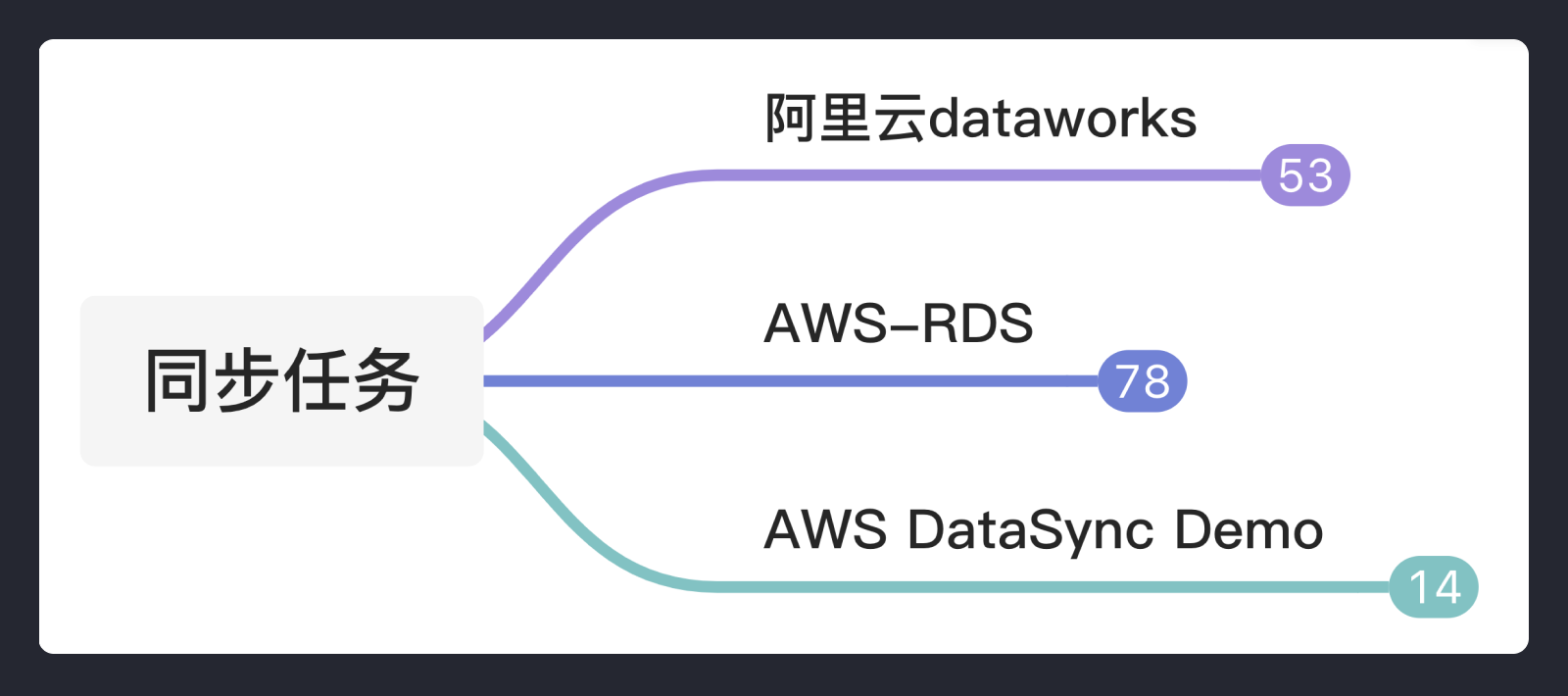
以上这些内容看着多,由于针对性比较强,只花了三个晚上就收集好了,资料我放在文末,大家有需求可以自取。
2、对竞品进行分析
体验完竞品后,我大概了解什么是字段映射,为什么要做字段映射,各竞品关于数据同步、字段映射的设计流程和方案,完整的流程可直接看产品文档。
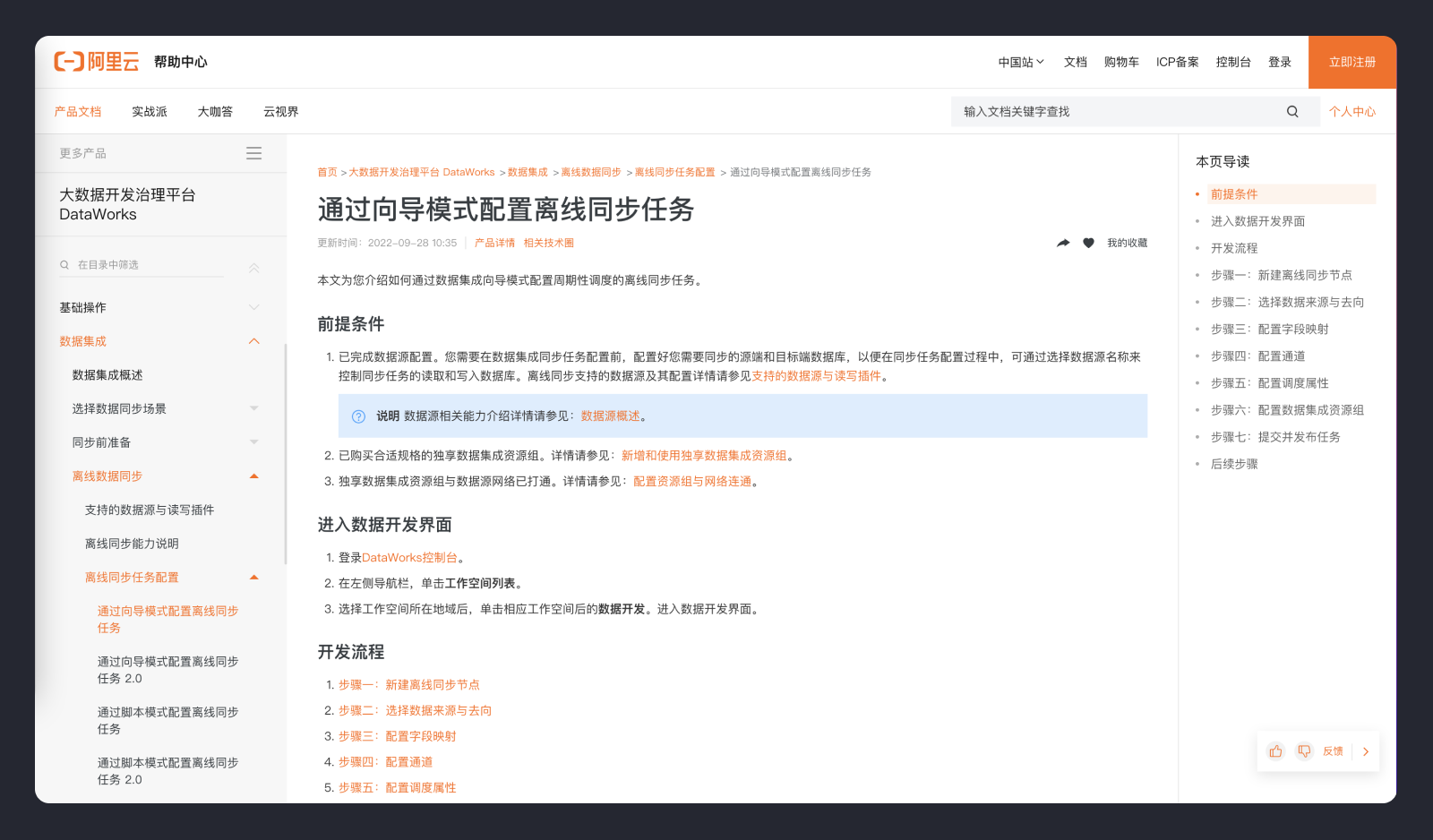
通过了解的深入,我发现字段映射可以抽象为设计模式中的一对一匹配,针对一对一匹配我们很自然想到连线法、拖拽法,但是他们显然都有很明显的缺点。
连线法:当连线过多,会变得很乱,同时数据量大时,如果要从第一个连接最后一个,交互就会很难操作。
拖拽法:也可叫拖拽交换法,他的操作难度,大家可以看下面一个小学教具——汉诺塔。目标是将左边柱子上的圆盘,移动到右边柱子上,要求只能一个一个的移动,同时要求大的不能压小的,中间的柱子可以借用,其难度大家来感受下~

有没有更好的解决方案呢?于是找到了Hozin关于《一对一匹配方案》的详细讲解,主要包括:连线法、拖拽法、预设匹配。
什么是预设匹配,Hozin说了几种交互方式,这里我们选择一列固定另外一列选择的方式,如果冲突就单独列出冲突列表。
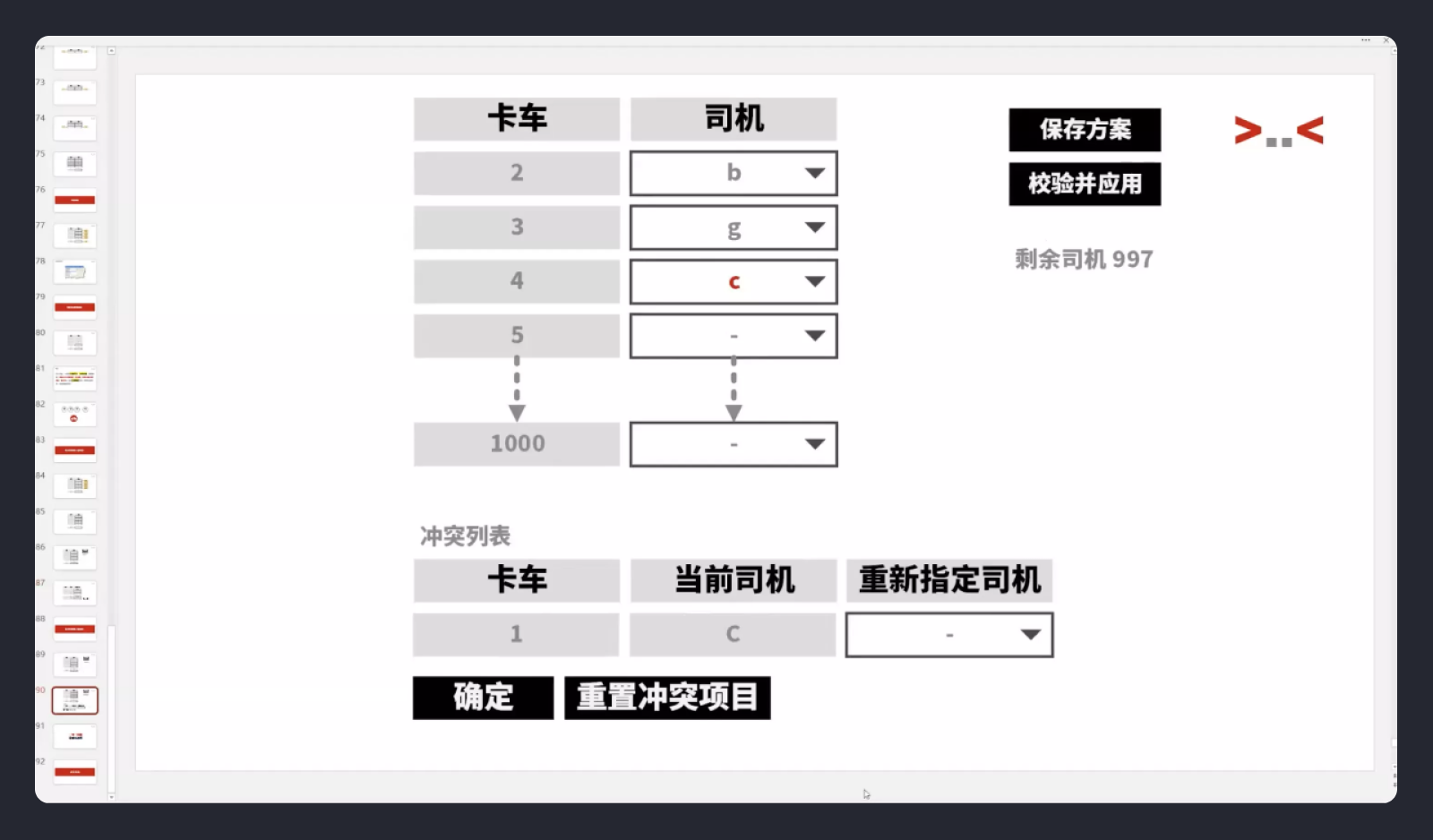
相比连线法和拖拽交换法,该方案大大降低了连接的成本。确定采用预设匹配的方案后,我们继续结合竞品来分析。分析内容见上篇文章《【B端】字段映射如计?别被大厂方案禁锢了》大家可以参考。
最后将分析结果和PM、技术讨论,确定该方式比连线方式合适,最后采用了预设匹配的方案。
第二、如何进行需求梳理
需求出来后,就需要对产品的具体需求进行梳理,以确定该方案是否易用,拓展性如何。下面继续用案例和大家详细讲解。
字段映射原始需求:
新建同步任务界面中,选择数据来源和数据去向后,指定源表和目标表的字段映射关系,配置好后,任务将根据映射关系,将源表字段写入目标表对应的字段中(简单来说就是将业务数据库中的表,同步或采集云端数据库中的表来,形成元数据,便于数据的管理)。
功能说明:
1、支持同名映射、同行映射、清除映射
2、当源表字段类型和目标表类型不一致时,暂时以目标表字段为准
3、支持添加常量
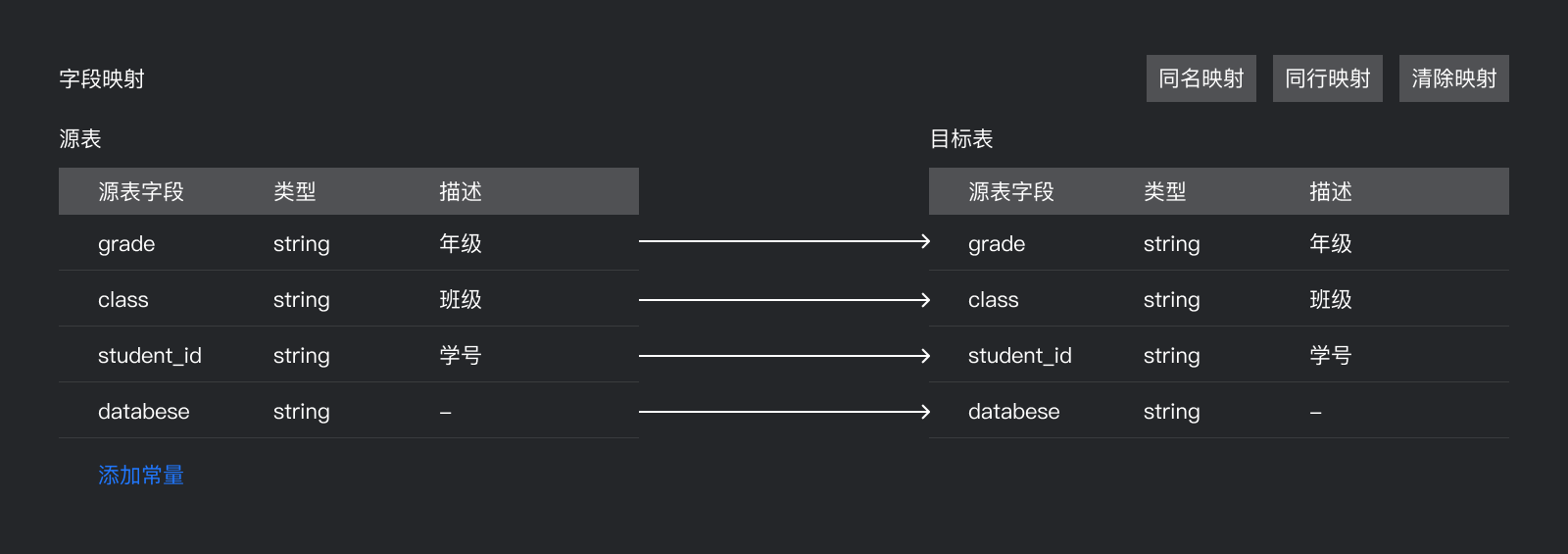
脱敏后的虚拟需求
以上需求看上去很简单,但是我们之前做了竞品分析,就知道这个里面有很多问题原型没有交代清楚,比如:
1、源表字段排列顺序和目标表一致吗?
2、默认是否保留原表字段顺序?
3、默认是否直接将同名进行匹配
4、字段量大概有多少?
5、当源表字段数量大于目标表时,多余字段如何处理?
6、当源表字段数量少于目标表时,目标中同步为null,还是不写入数据?
7、必填校验:有连接才能提交吗,未连接是否能提交?
8、源表字段类型和目标表字段类型不一致时,是否能提交?
9、源表字段名和目标表字段名不一致时,是否能提交?
10、数据都是系统带出吗?可编辑吗?
对于以上疑问,及时和PM继续讨论直到需求清晰,通过讨论,最后将需求落实如下:
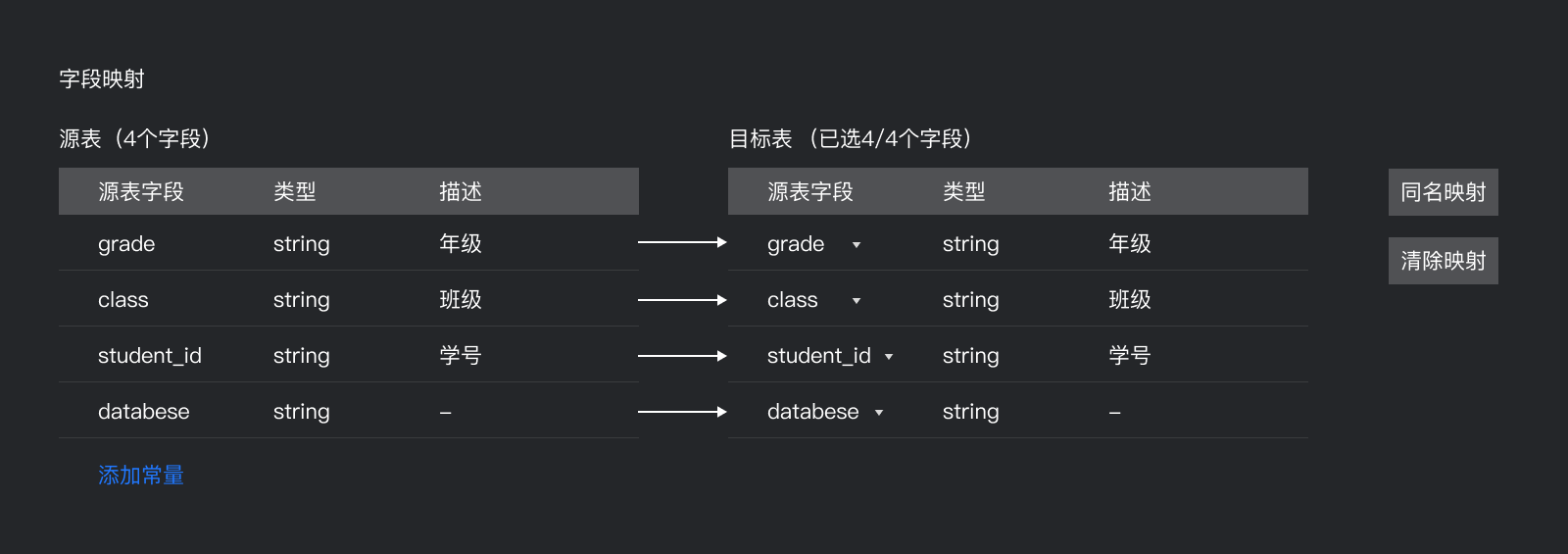
1、支持同名映射、同行映射、清除映射,支持添加常量
2、源表字段排列顺序和目标表可能一致,可能不一致,业务要求保留原字段顺序。
3、默认可不进行连接
4、字段数量不定
5、不管源表字段数量大于还是少于目标表,多余字段都不映射
6、必填校验;排重校验
7、字段类型不一致时,可提交,技术直接转换类型
8、字段名可以不一致
9、字段不可编辑,仅添加的常量可编辑
10、点击添加常量,可输入赋值内容、字段类型、描述
11、点击同名映射,可以根据名称建立相应的映射关系
12、点击清除全部,可清除全部的映射关系
第三、如何进行方案设计
需求确定好后,就可以进行方案设计了,在需求梳理阶段我们已经确定了采用预设匹配方案,但是具体该方案能否覆盖所有的交互场景,还未全部印证,因此PM让我先尝试,实在不行就用连线方案保底。
因此我快速做了一个demo草图进行验证,确定了预设匹配的方案,能够覆盖所有的交互,同时拓展性也较好,解决了连线乱,拖拽不方便的问题,同时重新匹配的操作也较为简单,如下:

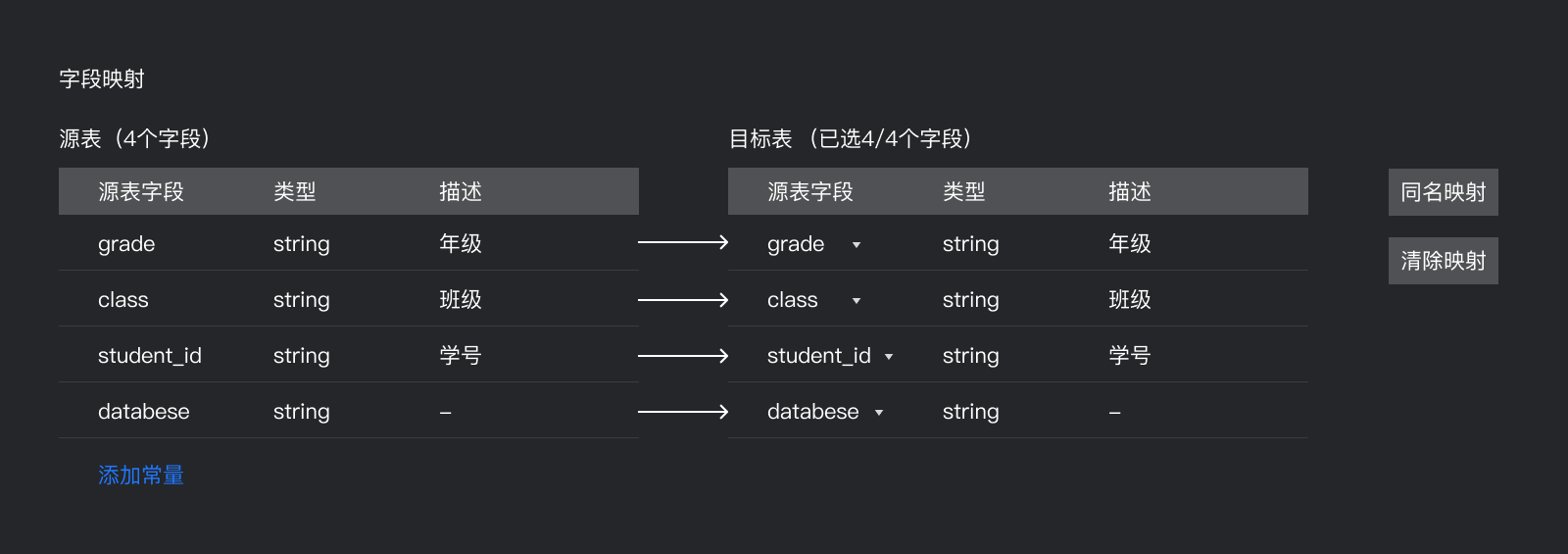
PS:大家看到中间的连线是一根假线,没有任何功能,目的是为了让用户快速的知道他们的关系。
拿着demo和PM、技术讨论后,我们都觉得没问题后,接下来就进入简单的画图阶段,风格直接继承平台整体风格即可,效果根据界面实际情况调整即可,首先画出整体操作流程(该案例以MySql数据库同步为例,其他的数据库类型不在本文复盘范围):
基础流程:将业务表中的表数据,直接同步到云端对应的数据表中
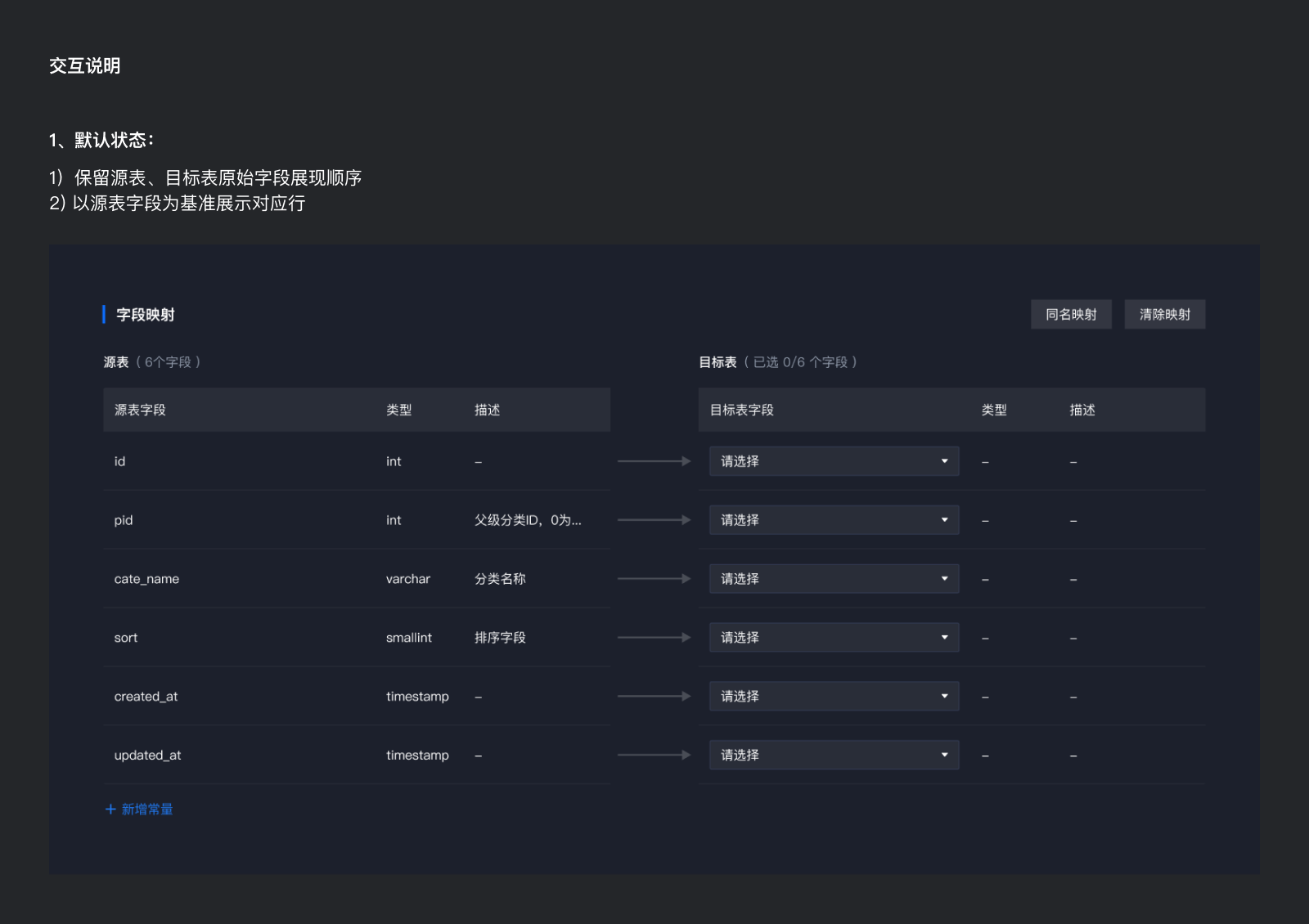
1、默认状态:
1)保留源表、目标表原始字段展现顺序
- 以源表字段为基准展示对应行

2、点击同名映射:
1)点击同名映射,系统自动以左侧为基准,将同名字段选中
2)并且将同名匹配字段前置,未匹配的字段后置
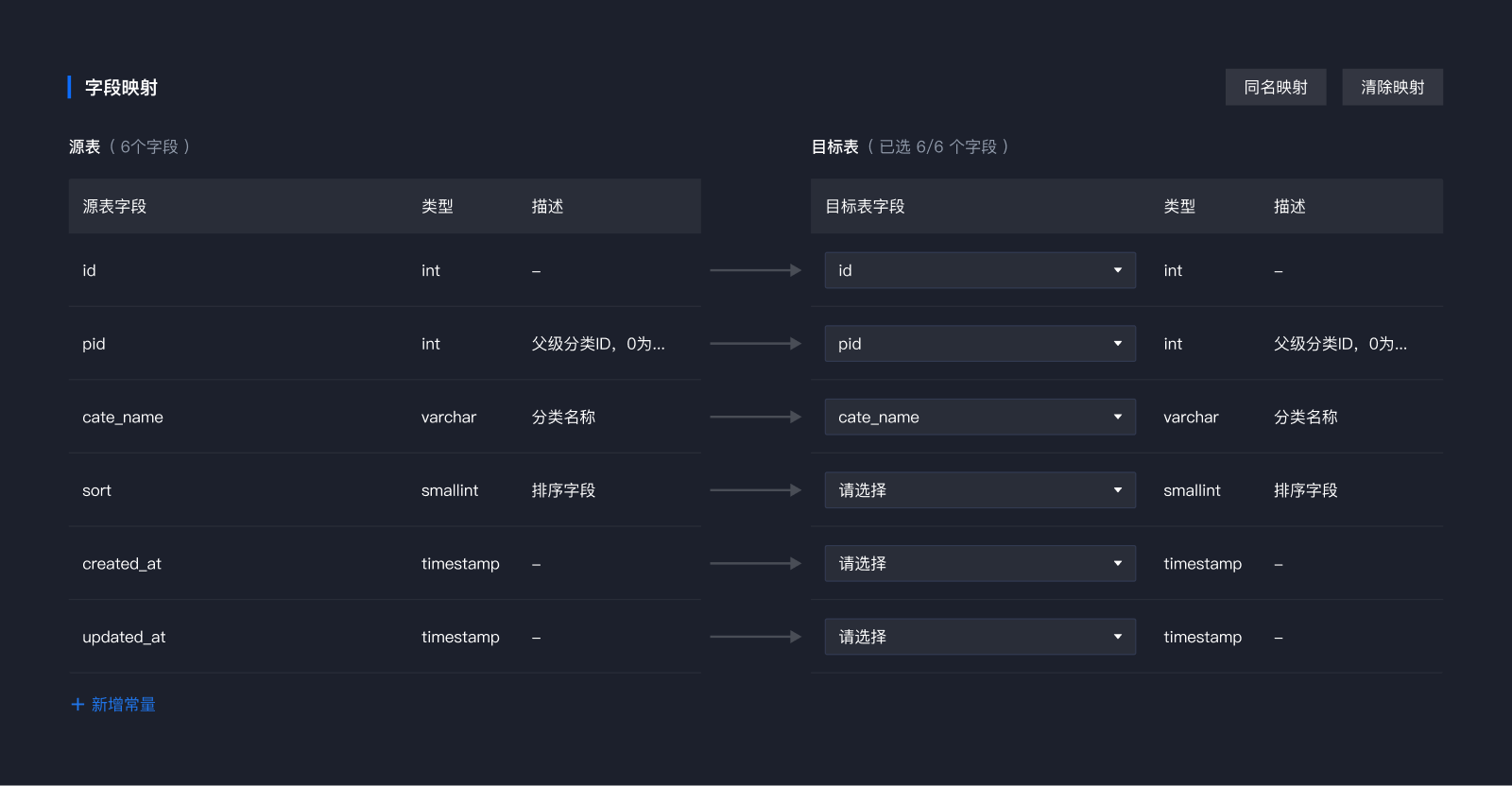
3、选择映射字段:
1)继续选择未匹配的字段
2)下拉框不做联动,保留目标表原始字段顺序,可重复选择
3)选择后自动带出字段类型和描述
4)点击清除映射,批量清除映射关系;
4)hover到下拉框可清空

4、展示效果:
1)实时对字段进行重复校验(用户可直接选择匹配,对于重复的字段,操作完后在重新选择即可,大大减少了匹配难度)
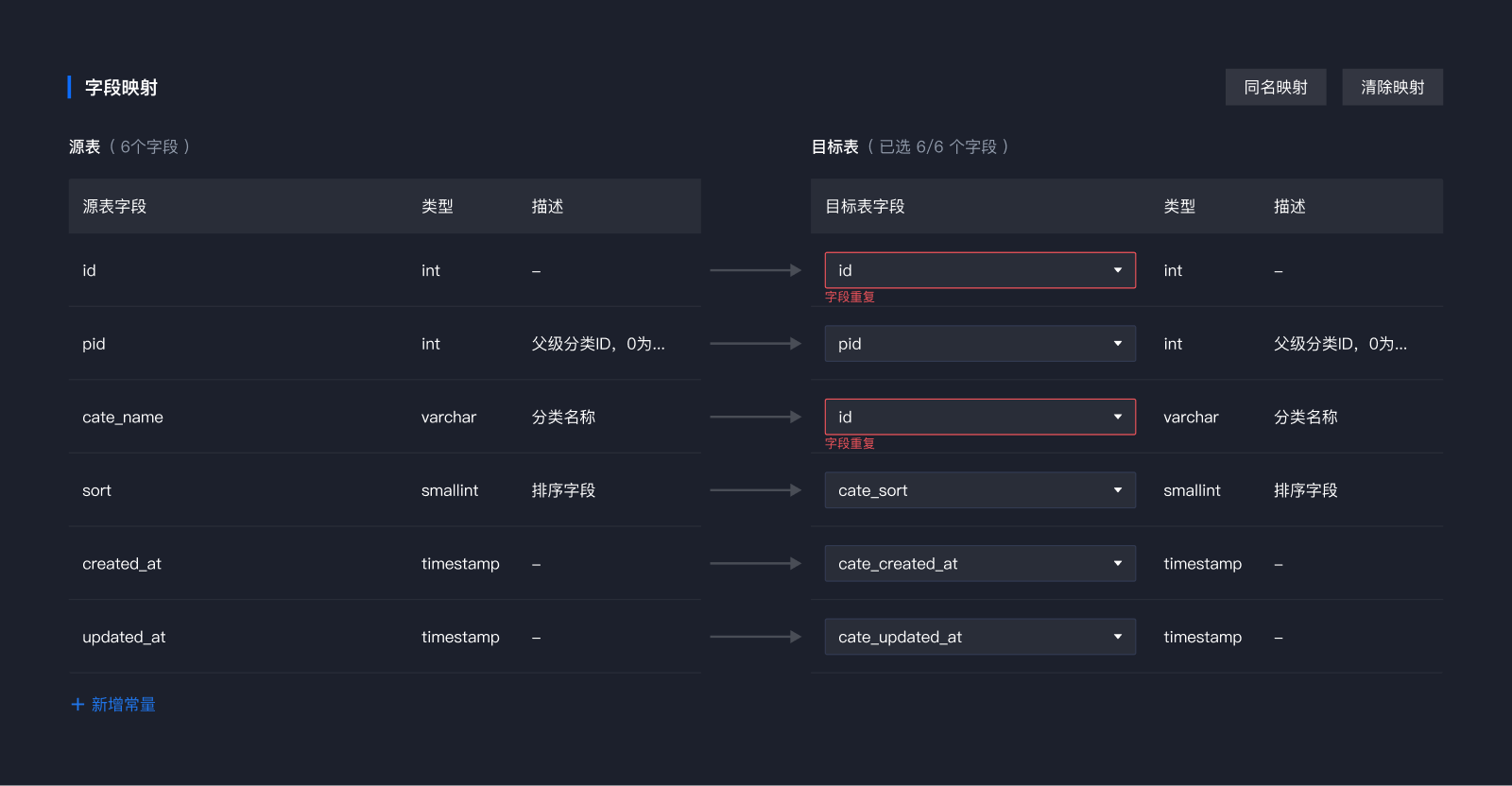
5、新增常量:
1)点击新增常量,用户可自动设置常量字段名、类型、描述,常量支持删除
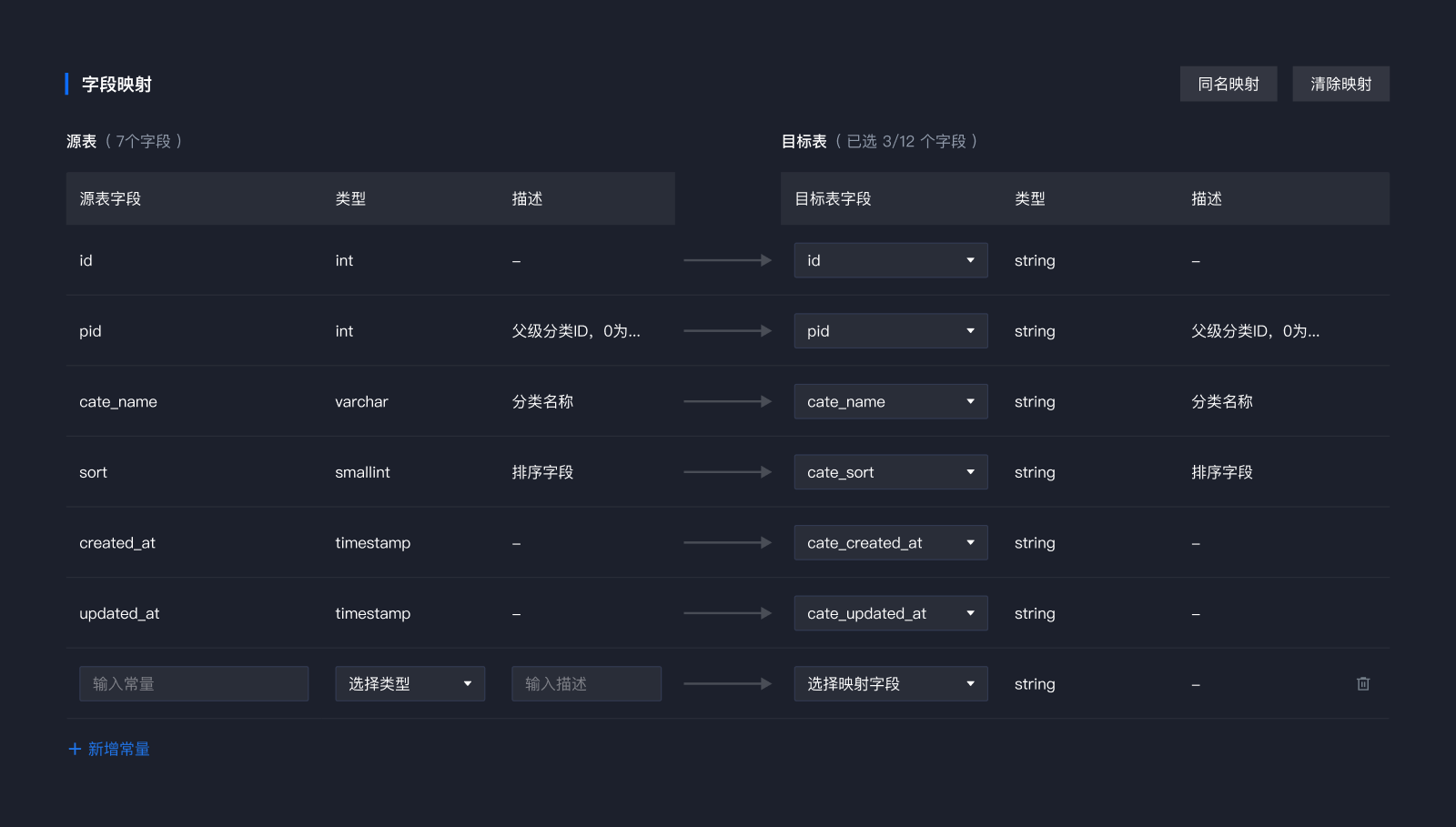
特殊情况:
1、当源表字段多于目标表字段如何处理?
1)源表字段全部展现,以源表字段为基础,未选择字段不同步

2、当源表字段少于目标字段如何处理?
1)源表字段全部展现,以源表字段为基础,仅对应同步6个字段,目标表中未连接字段为null

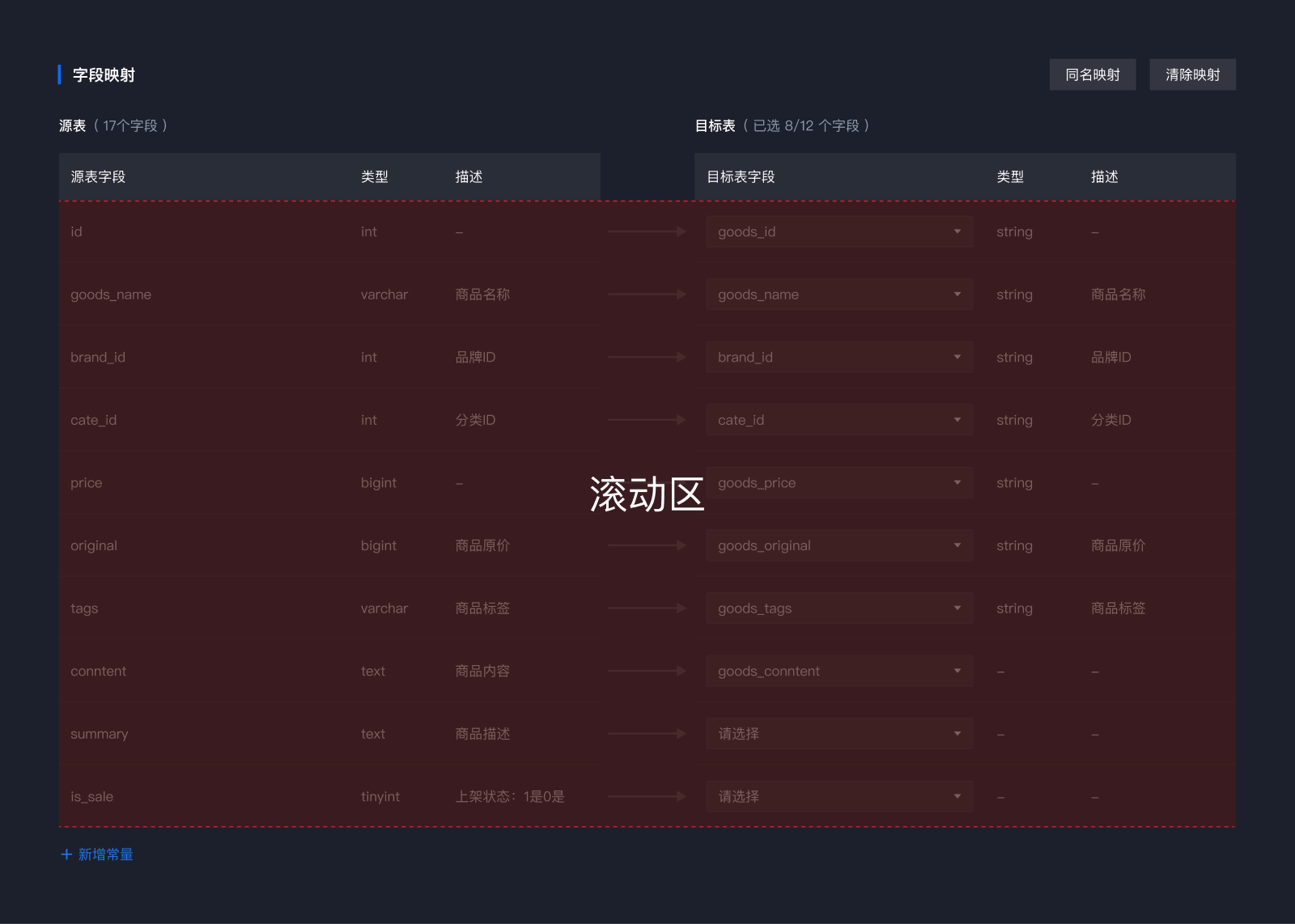
3、如何适配?
1)当数据量大时,列表最多展现10条数据,多余部分滚动展现(适配大家根据实际情况考虑即可)
4、完成交互细节,制作交互说明文档
1)界面完成后,在整体检查看还有什么交互细节需要设计,将其制作出来,比如各种hover状态,确认状态等。
2)将上述我们考虑的交互,整理到一个设计文档中,形成交互说明,便于技术查看,减少沟通成本。
PS:如果你离技术比较近,直接口诉即可,我一般时间不足时,直接和技术口述,一些小的细节会做一个交互说明。
本篇文章以B端数据平台中常见的字段映射为例,和大家分享如何快速了解业务;如何进行需求梳理;如何进行方案设计。
1、如何快速了解业务?
1)提前和PM了解下个迭代需要
2)对竞品截图进行分析
2、如何进行需求梳理?
1)和PM沟通,直至需求清晰在做设计
2)考虑可能的设计方案,和PM讨论,前期尽量确定好设计方案,以及保底方案
3、如何进行方案设计?
1)根据确定方案,快速产出demo,验证该方案是否能覆盖所有场景
2)方案设计时,尽量把交互状态都考虑完善,形成交互说明
关注海盐社公众号,后台回复数据平台竞品,免费获取竞品的截图和语雀整理的《阿里云、AWS数据同步对比》

资料参考:
一对一匹配解题思路
https://mp.weixin.qq.com/s/ad7uot6DHFXRt3Ug9FGYsQ
大数据开发治理平台DataWorks

若有收获,就点个赞吧
0 人点赞
