B 端必看:图表设计最易犯的 “七宗罪”

梁 17 关注作者
2021-05-24
2 评论 7711 浏览 72 收藏 26 分钟
0 基础快速入门互联网交互设计,从需求到交互文档学完就能用,写一份团队满意的交互文档,了解一下 >>
释放双眼,带上耳机,听听看~!
00:00
00:00
编辑导语:在 B 端产品设计中,图表设计是常见的工作项目。合理有效的图表设计有助于数据抽象化、可视化,体现数据真实性,并传达相关信息。在本篇文章里,作者对 B 端图表设计可能出现的问题做了相应总结,一起来看一下。

这些天在帮网友看B端测试题,几乎每份都会涉及到可视化图表。我从中提炼出一些规律,将这些梳理总结出一份七宗罪走查清单,正如芒格先生所说 “如果知道我会 si 在哪里,那我将永远不会去那个地方”,希望这份清单能帮助大家排雷扫障。
本文 5480 字,预计阅读时长 20 分钟,内含大量图表示例,建议 PC 端阅读。记得每次设计完图表后拿出来对照走查。阅读指引如下:

一、图表构成
清单中涉及一些专业词汇,为方便大家理解,我们先简单地认识一下图表构成。
图表设计规范同样由原子、分子、组件、模块、页面搭建而成,其中图表由多个组件构成,如数据标签、图例、图形主体、坐标系等。
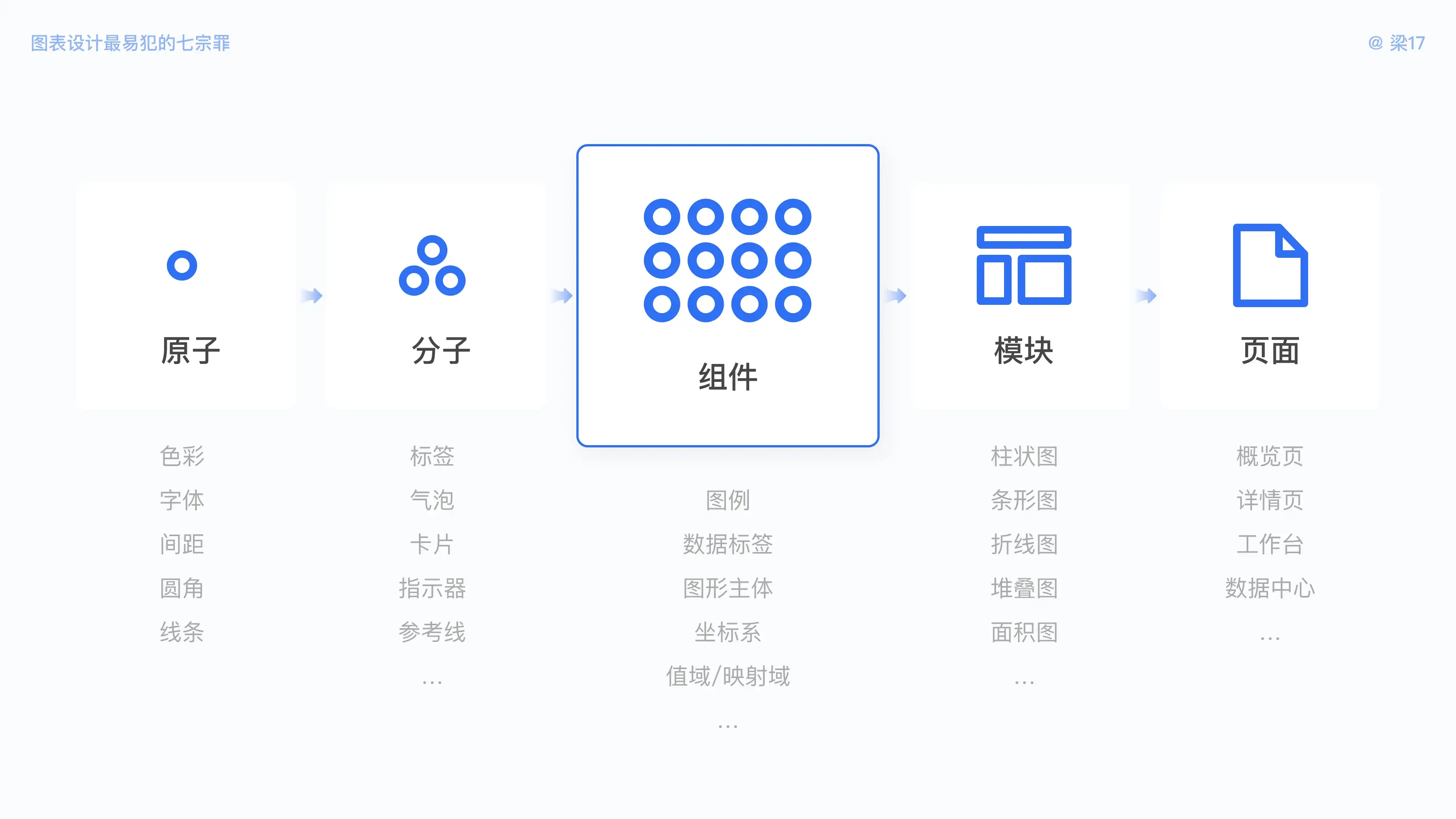
- 标题:图表内容主题,包括主标题和副标题。可以是图表内容的概括,也可以是结论。
- 切换选项:用以切换同组对象的不同维度数据,如销售量与销售额。
- 数据标签:也叫提示信息,即当前数据的内容标注。数字型的数据标签,以通常以常驻形式存在于图表;气泡型 / 卡片型的数据标签,常以交互行为(点击、长按、悬停等)触发的形式出现。
- 图例:指图表内容与数据的符号或颜色说明,它既为绘图标准,又是图表的阅读指南。
- 工具(栏):当前图表的操作项,例如编辑、刷新、导出、分享等。
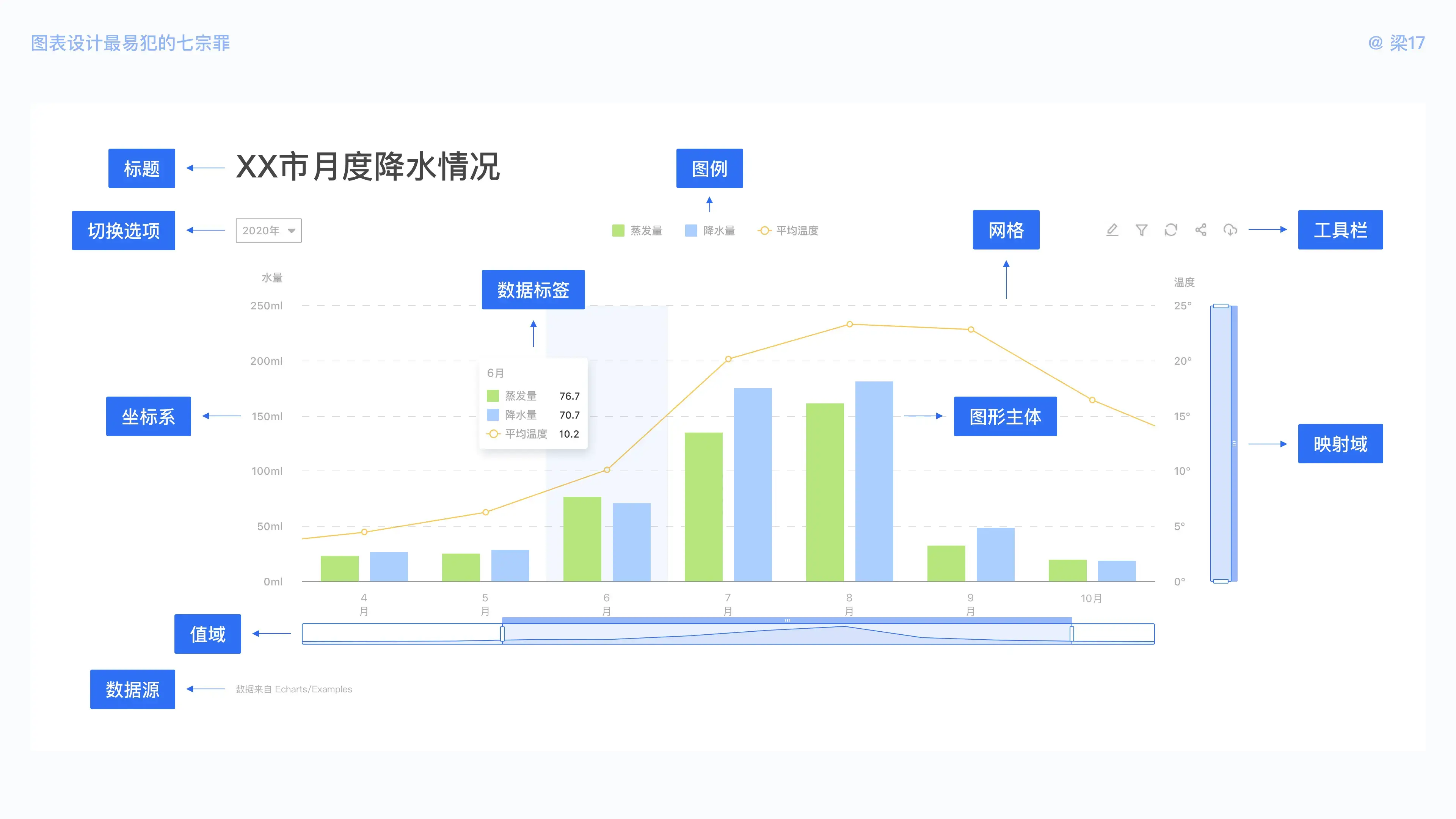
- 坐标系:将抽象的数据关系映射到具象的图表上,该图表所处的空间维度叫做 “坐标系”,用来确定数据空间位置的数组叫做 “坐标”,例如(x,y)、(北纬 N22°38′17.54″ ,东经 E114°05′52.35)。坐标系包括坐标轴和标尺。
- 图形主体 :用于数据视觉展现形式的图形,可以根据数据维度、数据差异,在同一图表使用不同图形绘制,例如常见的折柱混合、K 线图。
- 网格:以标尺刻度为基准的参考线,用以辅助数据的快速定位。
- 值域:表示图表 X 轴的缩放大小,以及可视区域,多用于存在大量数据的情况。
- 映射域:表示图表 Y 轴的缩放大小,以及可视区域,多用于数据差异较大的情况。
二、图表设计七宗罪
1. 冗余
冗余即多余的、不必要的信息,或重复内容,产生了视觉干扰,无法直观获取数据信息。
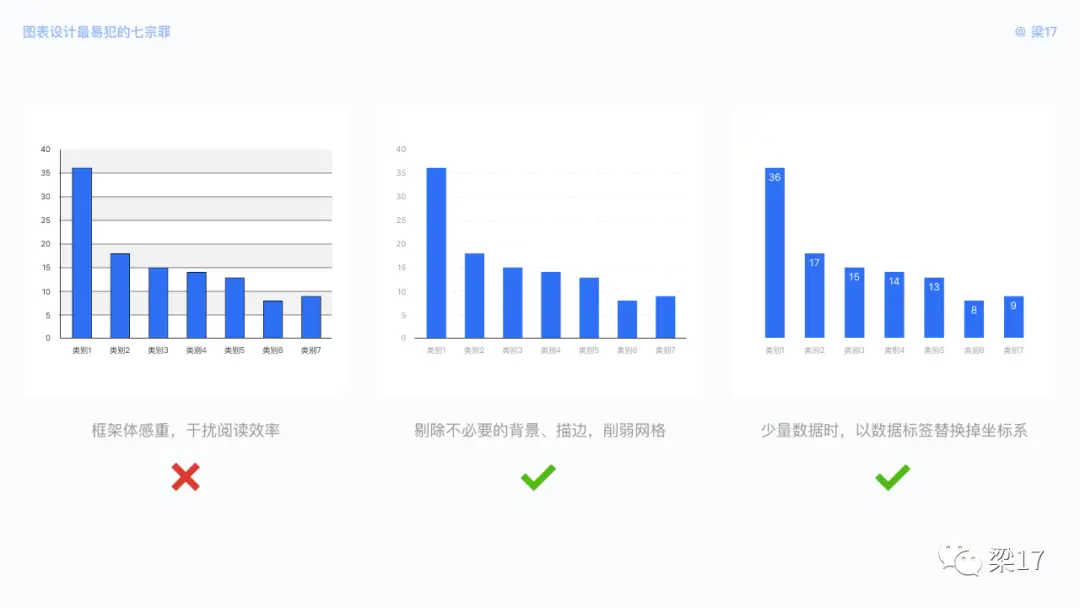
图表的价值在于使抽象的数据关系具象化、可视化,使其直观易懂。我们在设计时,可通过信息降噪来提高信息获取效率。《纽约时报》信息设计师 Jonathan Corum 曾给出指导:“显示内容,而非显示框架”。
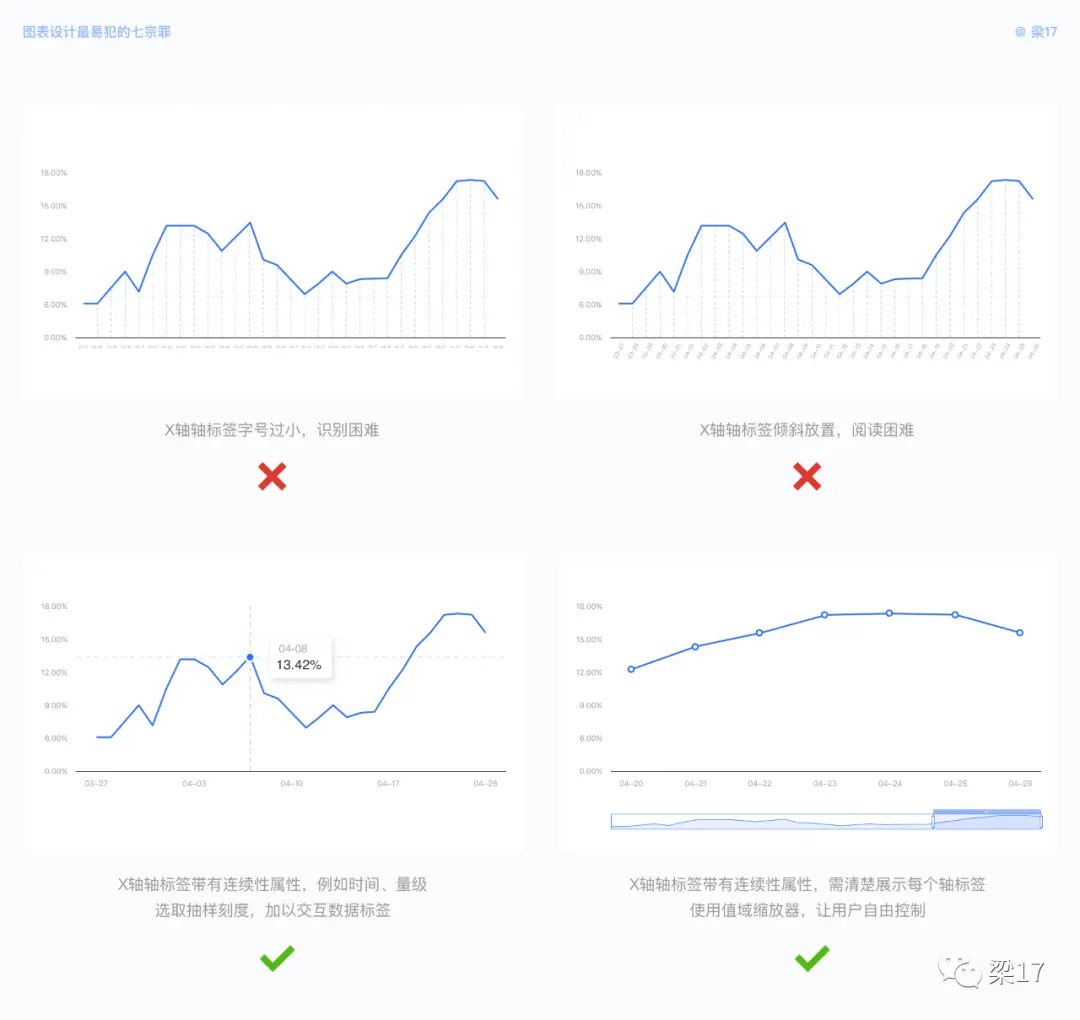
例如下图斑马纹背景、黑色的网格,作者试图给柱形添加描边来提高阅读性,使得图表更加地混乱不堪。当我们去掉斑马纹与描边,适当削弱网格,图表是否变得干净起来?接着我们添加数据标签,剔除坐标系,不仅使得图表更清爽,阅读效率也有大步提升。
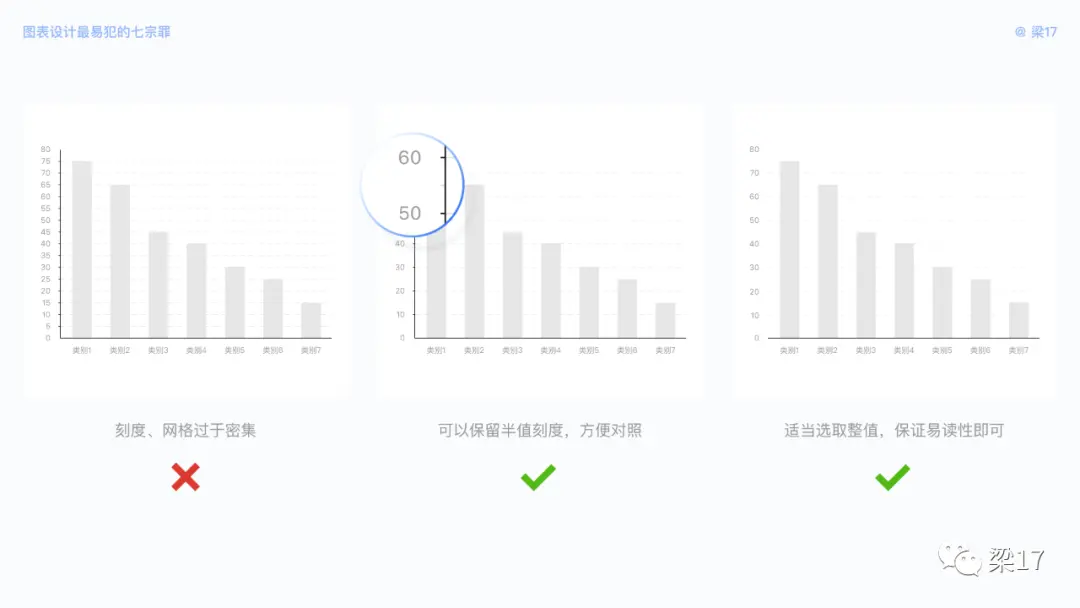
再者,刻度值选取也是较容易忽视的地方。
我们的设计原则为:在保证易读取坐标的基础上做最简化。例如我们可以保留半个刻度值,灰色显示,方便用户快速读取数值。如果你的图表用只来展示对比情况,无需精确读值,亦或者有交互行为触发数据标签,那么你完全可以只选取合适的整值刻度。
可视化的数据集一般分为展示类和业务类,展示类只做某些确定的数据集展示,如项目提案、工作汇报等;业务类围绕着业务数据,包含已有的确定数据集与未知的数据集,如物流监控、天气预监、数据埋点监测等等。
业务数据集大多随时间推演而变化,缩小字号与斜置 X 轴轴标签都会影响数据阅读。建议抽样选取轴标签,并辅以交互行为触发数据标签。也可以完整保留轴标签,用值域缩略器控制显示范围与轴刻度大小。
题外话,当展示类数据集遇到类别名称较长,又不具备连续性时,建议使用条形图。

潜在风险
过多不必要的视觉噪音,干扰信息读取效率,图表内容得不到凸显,失去直观、形象的价值。
如何避免
- 剔除不必要的非数据元素(如轮廓、网格线、背景),将重点放在数据元素;
- 弱化坐标系(坐标轴、刻度线),保持其清晰但不起眼;
- 当你设计了常驻数据标签时,甚至可以剔除坐标系;
- 数据集具有连续性时,坐标轴抽样显示,或使用值域缩略器。
2. 繁杂
即多而杂乱,分为设计语言繁杂、数据集繁杂,和视觉浏览动线繁杂。
相比其设计冗余,设计繁杂时阅读更为困难,甚至出现无法读取信息的情况。
1)设计语言繁杂
在同一套系统中各个模块,分别使用蓝绿科技风、黑金尊贵风、玫紫时尚风、驼色休闲风等等等。纷繁多样的设计语言,不仅使用户困惑、认知困难,还加大了开发成本。
虽在业内没有明确的规范,大家可应根据载体终端,将产品原设计系统衍生出一份图表设计规范。
在可视化专业术语中,我们给图表定义的设计语言叫做视觉编码,它是数据与视觉结果之间的映射规则。其中包括了形态、大小、位置、色彩、纹理、方向等等。
感兴趣的朋友可以阅读 Jacques Bertin 的《Semiology of Graphics》,他在当中总结了有哪些视觉变量,能最有效地显示定性或定量差异。

其中比较值得注意的是图表色板的设定,我们分为定性色板、顺序色板、离散色板。
- 定性色板:基于明度、饱和度的平衡上,调整色相以区分不同类别。适用于无顺序关系的图表,多见于对比类图表,例如柱状图、条形图、面积图。
- 顺序色板:基于色相、饱和度的平衡上,调整明度以表示递进、流程、顺序等。适用于顺序关系的图表,例如于漏斗图、热图。
- 离散色板:基于中间值(例如 0)将两种顺序色板组合起来,适用于两种不同关联关系的图表,例如双向堆叠图。

注:这里的顺序关系指的是图表类型本身带有连续性、递进性、流转性,与数据本身的连续性不同。
2)数据集繁杂
数据集难免出现极限情况,例如对比几十个省份订单变化情况时,你能在左侧图中找上海的数据吗?

建议把总览图表按某种规则拆分为小组,例如按地理分区拆分为东北、华北、华中、华东、华南、西南、西北七区各省份订单对比。
也可以拆分为若干个子数据图表,如示例右侧每个省份一张图,拓展性更强,可以灵活调取任意省份进行对比。
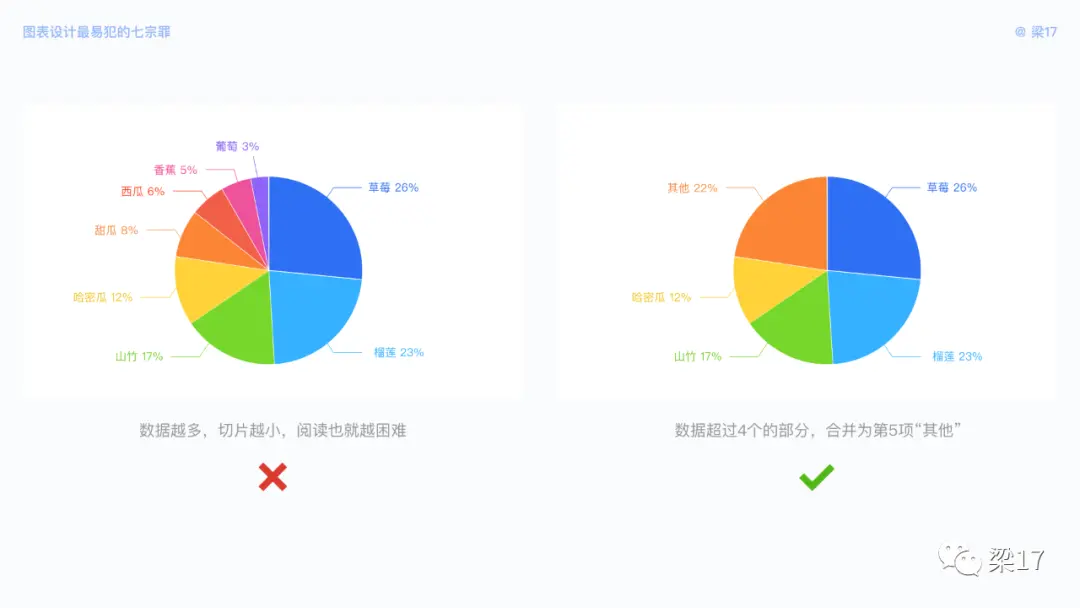
当我们要看子数据占比情况时,较多的分类会出现饼图切片过小,读取困难。当数据类别>5 时,我们可以将较小的 / 不重要的数据合并为 “其他”。
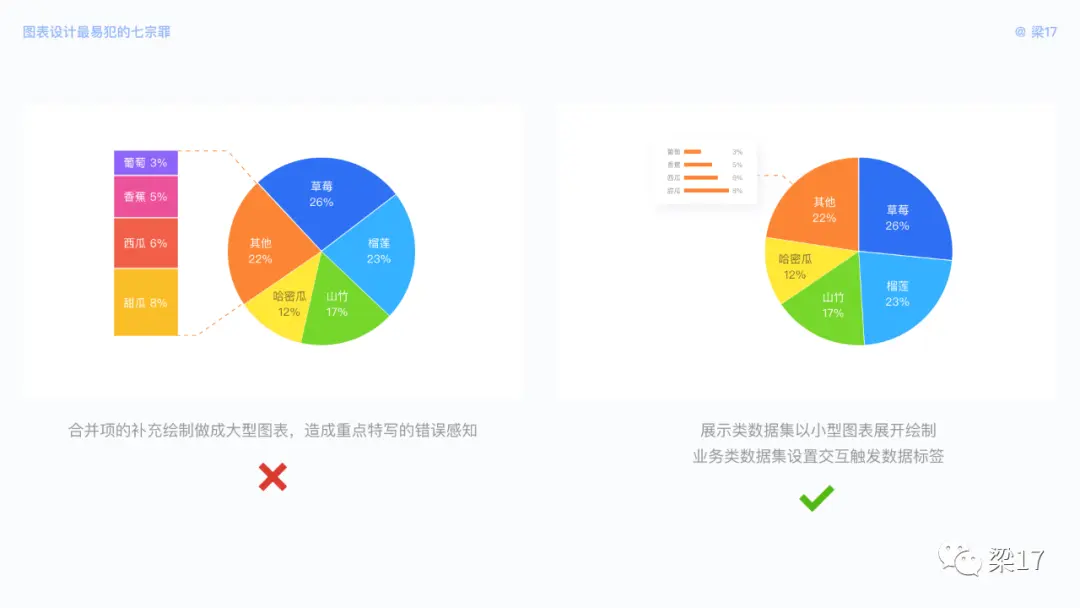
如果每个数据都很重要,合并子数据会导致信息显示不全,可以在外部展开单独绘制,但要注意合并项与总项的比例大小,避免让用户误解该合并项为重点特写部分。
3)视觉浏览动线繁杂
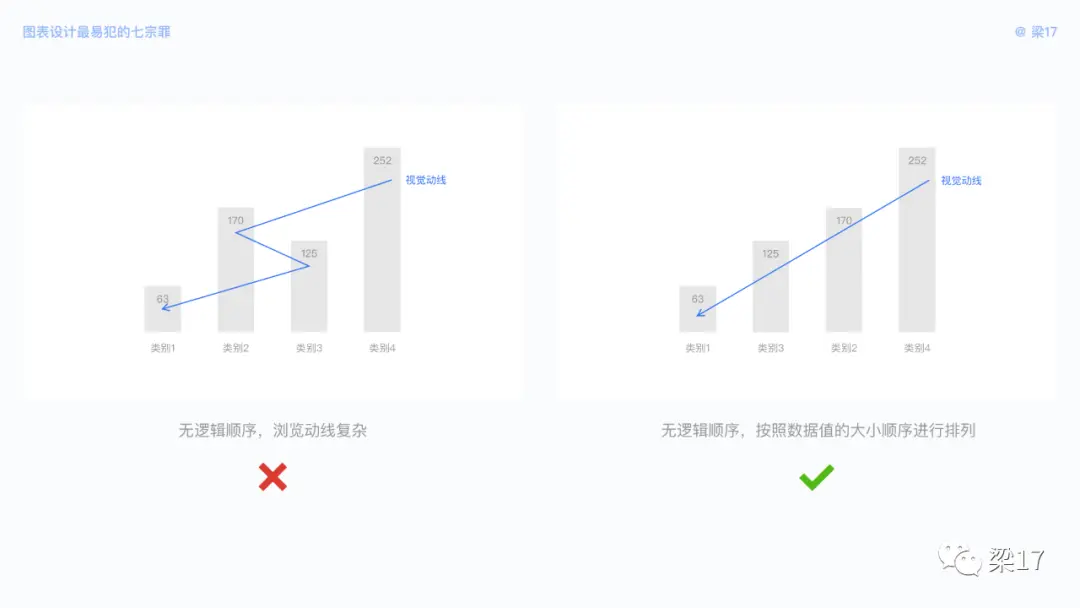
数据排列时,为帮助用户快速读取信息,我们需要将数据按照某种逻辑顺序进行排列,避免用户视线来回横跳。
① 按数据值大小排列
如数据类别无任何逻辑顺序,那么我们可以按照数据值的大小顺序进行排列。除非你的图表只用作点缀装饰。
饼图与玫瑰图除了按数据值大小排列,还应注意起始位点,最好从 12 点钟方向顺时针或逆时针绘制。以及将合并项置于最后。

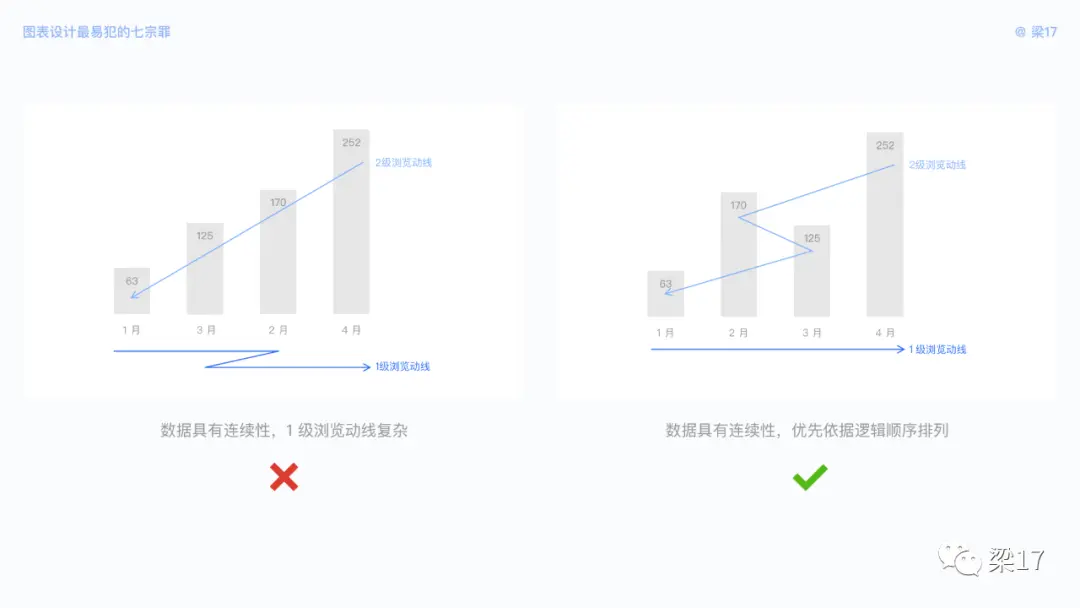
② 按逻辑顺序排列
如果你的数据类别带有连续性质,如时间、量级、年龄等,那么就按照连续顺序排列。
潜在风险
设计语言、数据集和浏览动线的繁杂,使得用户需要自行处理复杂信息,读取困难、认知成本高。
如何避免
制定视觉规范、统一有效的视觉编码,将庞大数据集拆分为多个子数据组或单一数据,按照大小、时间、年龄等逻辑顺序排列,帮助用户降低认知成本。
3. 暧昧
指关系含糊不明朗,令人难以辨别,常见于视觉编码近似、图表选择失误。
大多 B 端设计师天然喜欢克制、冷静、理性,经常在设计中使用同类色。但对比类图表如果使用同类色、邻近色,在饼图中尚且可以勉强分辨,但在折线图中就难以辨别了。
数据类别较少时建议选取定性色板中的对比色,数据类别多时可在定性色板基础上进行扩展。

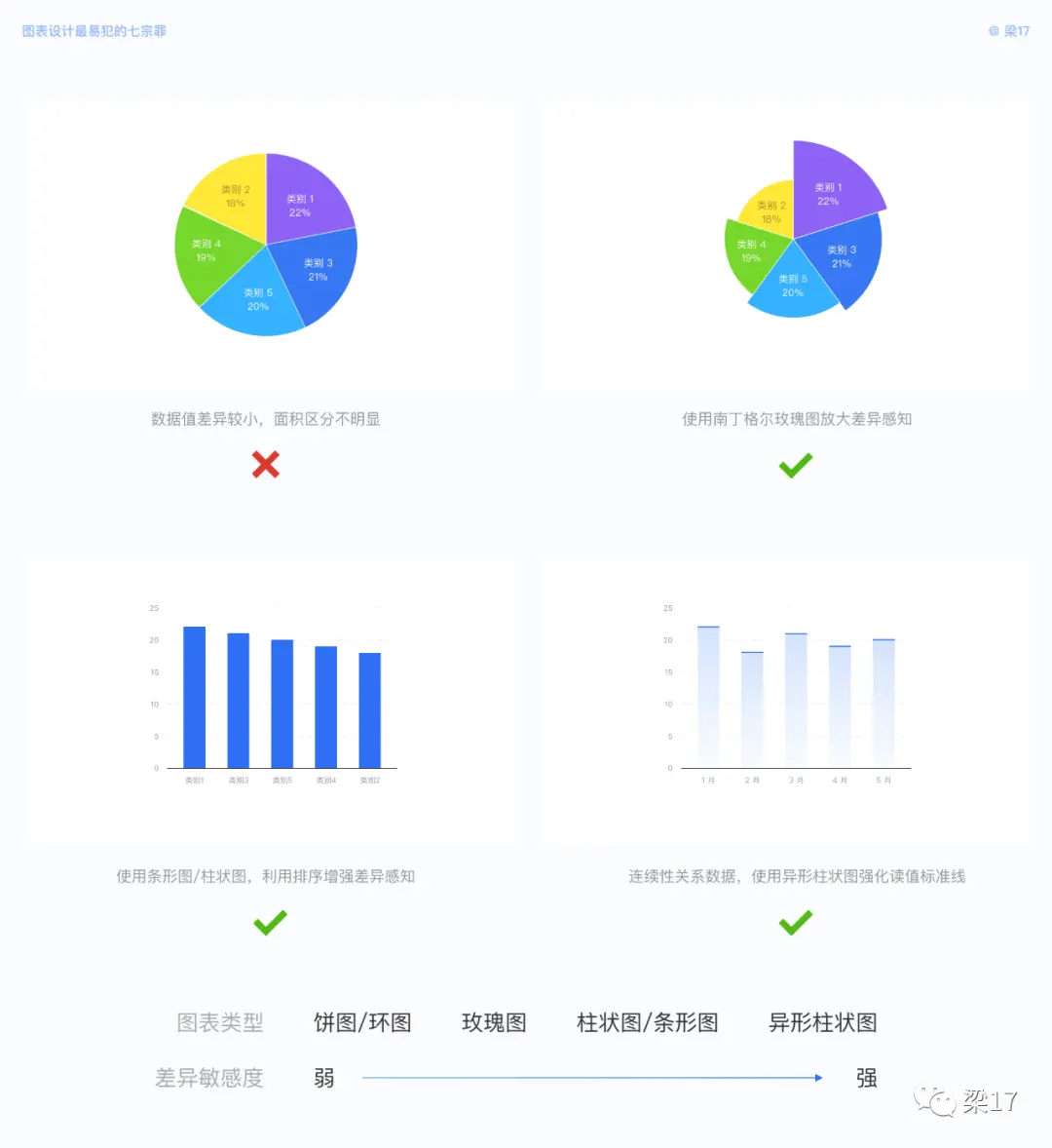
人眼对于面积的敏感度会低于高度 / 长度,数据值差异较小时,不建议使用面积图,可改用玫瑰图、条形图 / 柱状图、异形柱状图。
可能有朋友要好奇了,南丁格尔玫瑰图不是基于面积对比吗?玫瑰图是基于半径进行对比的,具体会在第七点中详细展开。如下图,从面积图至异形柱状图,用户认知敏感度逐渐递增。
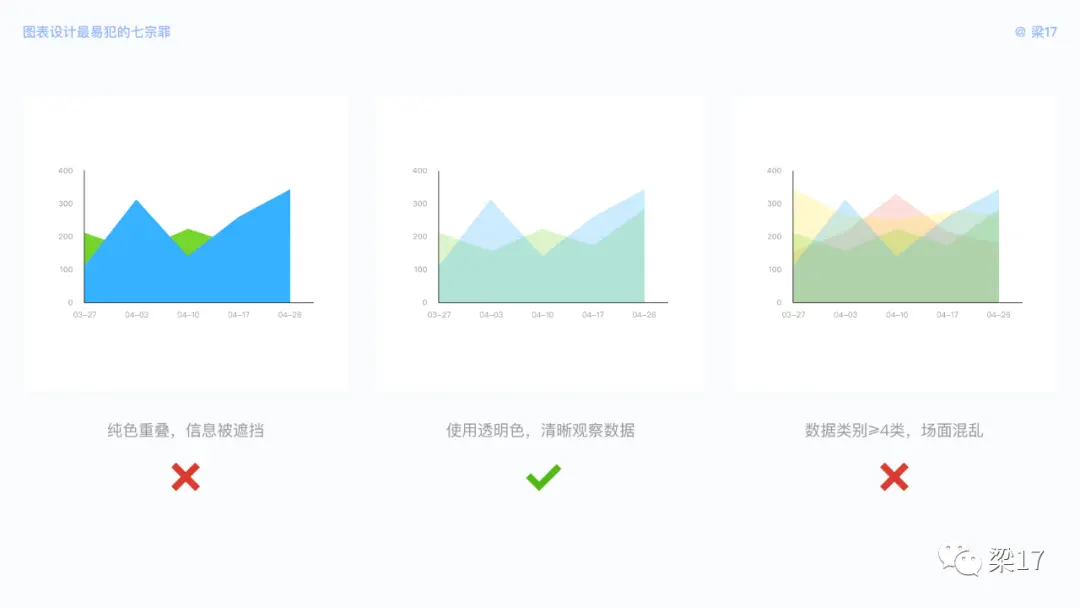
当我们使用面积图时,两类数据近距离重叠,建议使用透明色,确保信息不会被遮挡。
还有,暧昧要两个人才是甜甜的,最多可以加一位僚机,当出现第四人,场面开始有点不受控制了。所以数据类别≥4 类时,建议使用折线图或柱状图。
潜在风险
颜色、图表选取不当,信息区分感模糊,容易造成用户困惑,价值体验降低。
如何避免
针对不同需求不同场景,选取合适的颜色与图表,帮助用户快速辨别。
4. 失焦
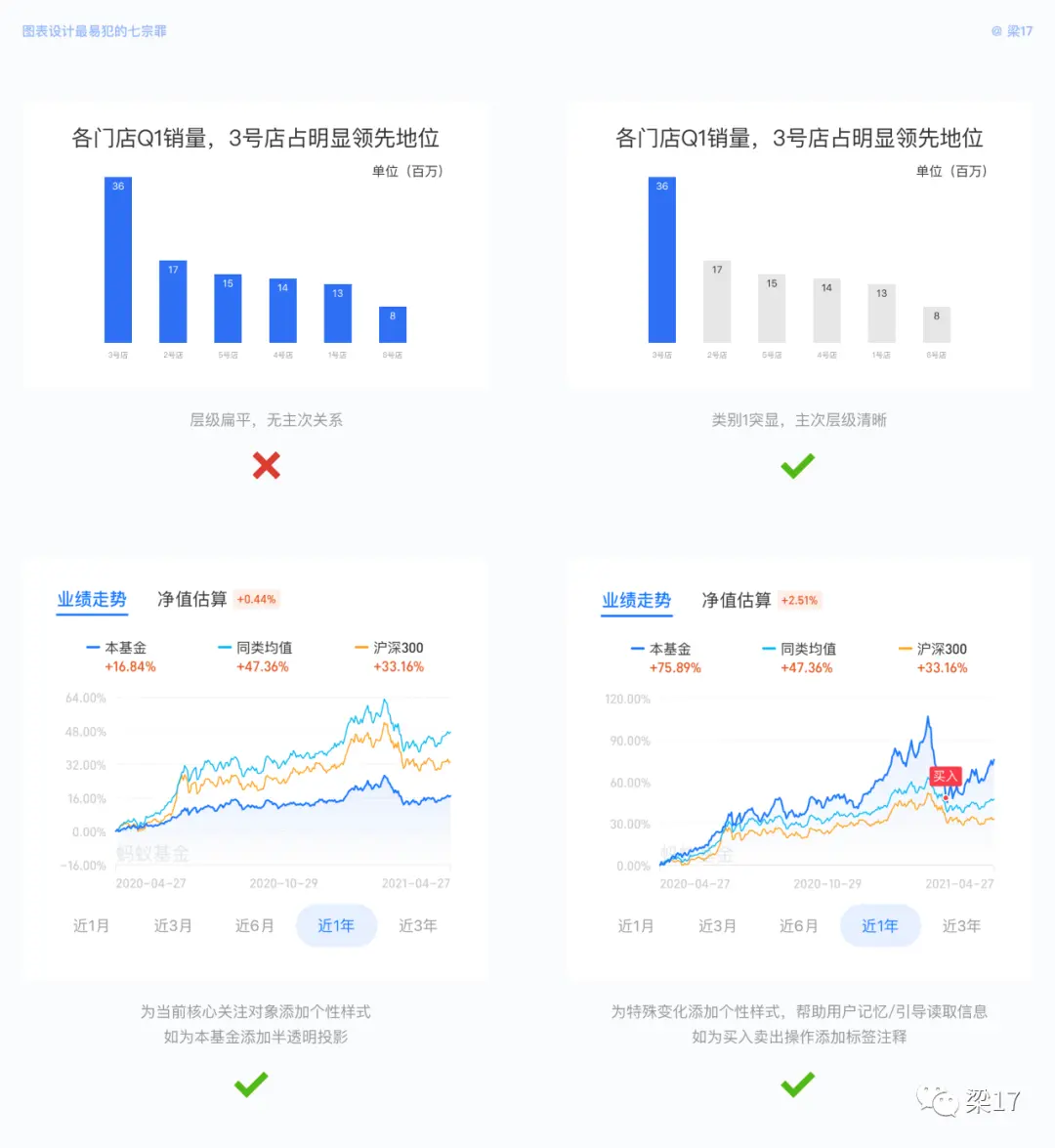
即层级模糊,无法对焦核心信息。
与刚才的暧昧不同,失焦指在传递某一个核心信息时层级模糊,数据之间是有层级关系的;而暧昧指在展示数据集时分辨边界模糊,数据之间是平级的。
例如在汇报提案场景,有想要着重传达的核心观点结论。此时我们可弱化次要数据,强调主要数据,以突显关键信息;亦或者在查看基金业绩走势场景,用户更关注的是当前所选基金的走势详情,同类均值与沪深 300 只是参照物。
潜在风险
特殊情况下,信息层级模糊,用户需要主动获取信息,不利于核心业务信息的高效传达。
如何避免
通过颜色明度对比、特殊样式,按需强调主数据、淡化次要数据,帮助用户直接接收核心信息,提高传达效率与准确性。
5. 浮夸
即虚幻夸张,不切实际。
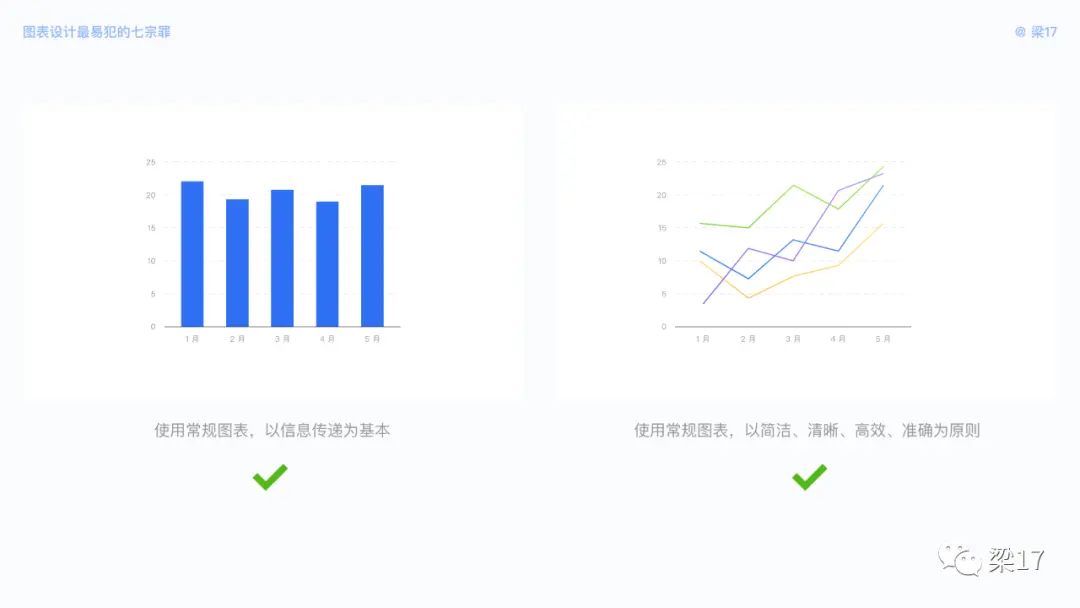
这是很多设计师常犯的错误,总是忍不住地添加视觉效果,影响了数据真实性却不自知。以下的柱状图,你能快速地告诉我 1 月、3 月、5 月哪个数据值更大吗?折线图中,你能快速地分辨分辨并读取信息吗?
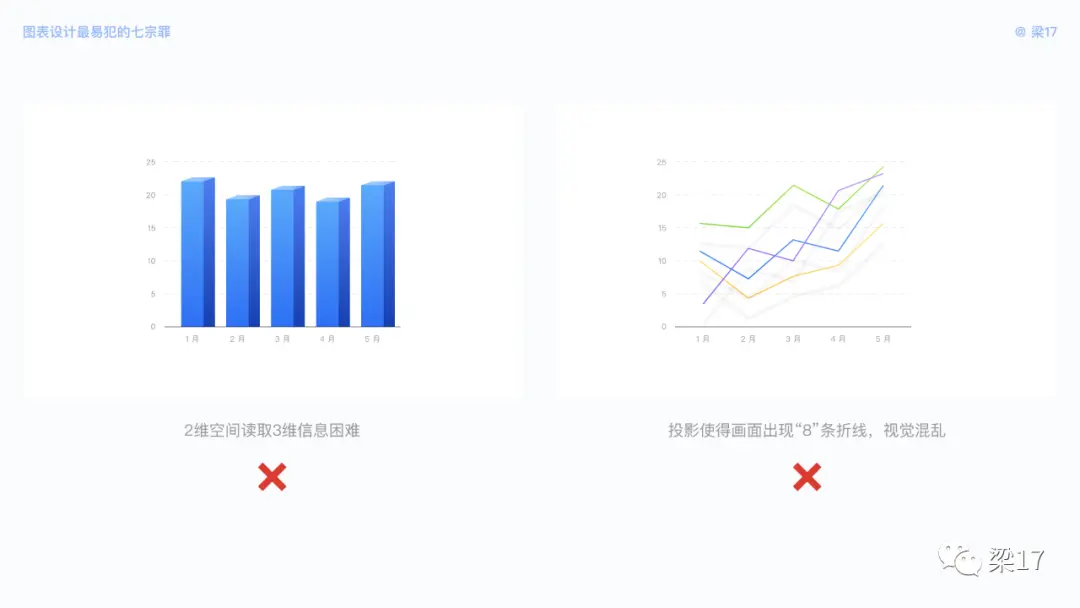
如果这些图表只做视觉点缀作用,不承载信息传递作用,那么是勉强可用的。但如果你需要传递信息,让用户读取,那么建议你放弃 3D、物理投影、拟物质感,除非你是在 VR 场景中使用它们。
还有很多设计师喜欢用的大圆角,圆头端点读取困难且不精准,是读端点还是圆心呢?
端点只此一个点,单凭一个小点如何精确读值?
在堆叠图中更会因为圆角之间的间隙丢失数值,请问图二的间隙应该计算在数值内吗?算在哪个属性之内呢?
如果你的数据集属于展示类,在常驻数据标签的存在下,你是可以使用大圆角的。在业务类数据集,还是建议大家使用平角或小圆角(1~5pt 即可)。

还有这种嵌套式的环状图,相关从业人员或许能清楚的判断 3 个数据值大小,但是普罗大众未必就能清楚判断了。
我们将其拆开,你能清楚地发现蓝色百分比最高,但是黄色的视觉重量明显最大。百分比值与视觉重量不符,容易影响用户判断,并且空间利用率低。

潜在风险
浮夸的 3D 效果、质感效果、大圆角效果、异形效果,在业务数据集的可视化中容易丢失数据、信息读取困难、浪费空间。
如何避免
去掉一切浮夸样式,回到可视化本质:清晰、高效、准确地传递信息,而不是让用户猜测、计算。
6. 失真
即失去本意或本来的面貌,信息传递错误。
我们常见的平滑曲线图,相较于折线图,多了一份柔美、自然与律动感。但是请注意,曲线在用户心智当中是一组连续的数据,是真实的趋势,曲线上任意一点都会对应一个真实的数据。而折线图在用户心智中是一组有限的数据进行连接,方便查看大致趋势。
例如当你只测量了整点时刻的温度,为了美观绘制了平滑曲线,用户可能会认为 12:30 时,温度为 20°。但这并非真实的,谁知道是 12 点后缓慢降温,还是突然降温呢?
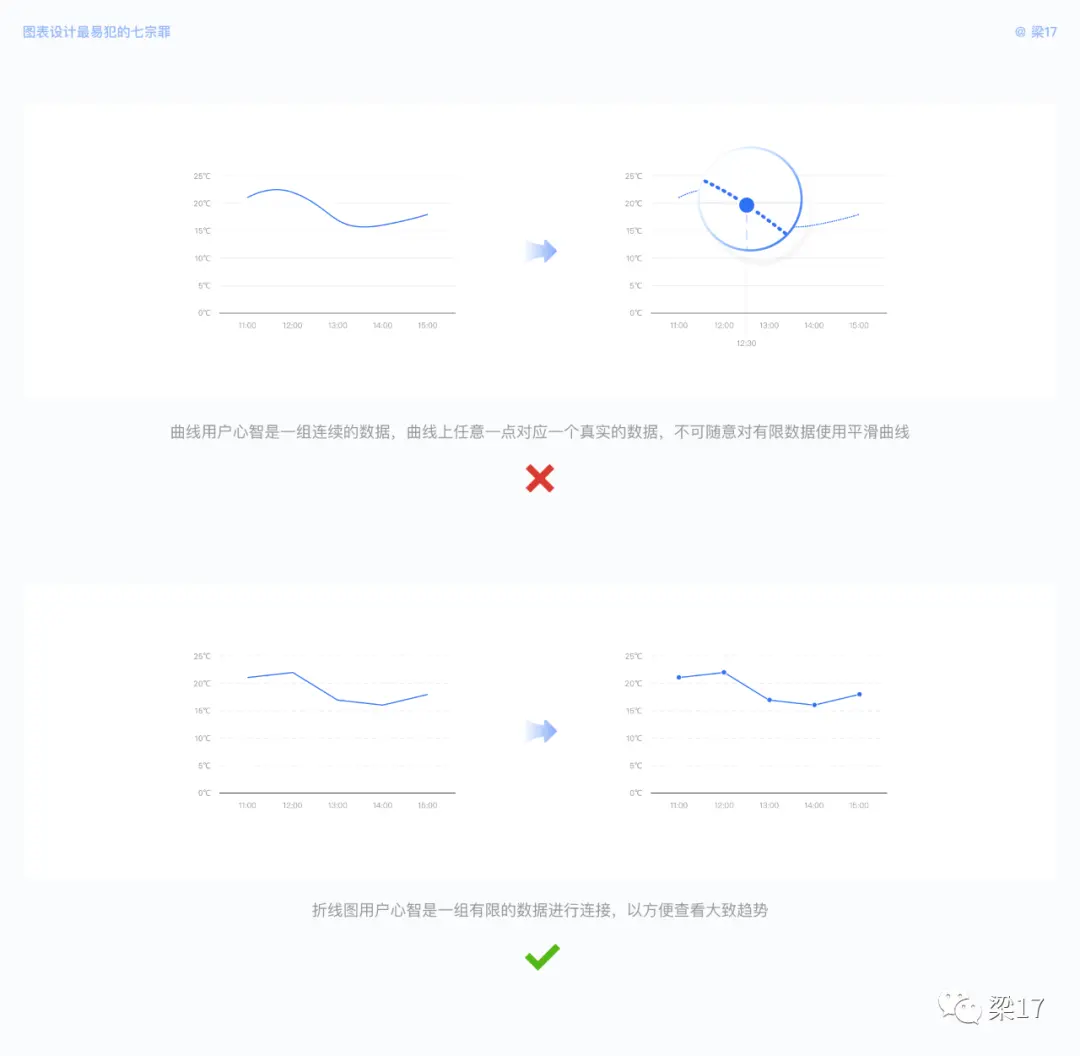
如果我们用钢笔工具在相同的几个点当中绘制平滑曲线,我们可以获得无数种可能性,这就是平滑曲线的失真原因。

在业务数据集中,我们需要考虑更多可能会发生的情况,例如出现了缺失的数据点。“空”与 “0” 是完全不同的概念,我们不能擅自为该数据点添加 “0” 值,而是真实的反应存在数据缺失。
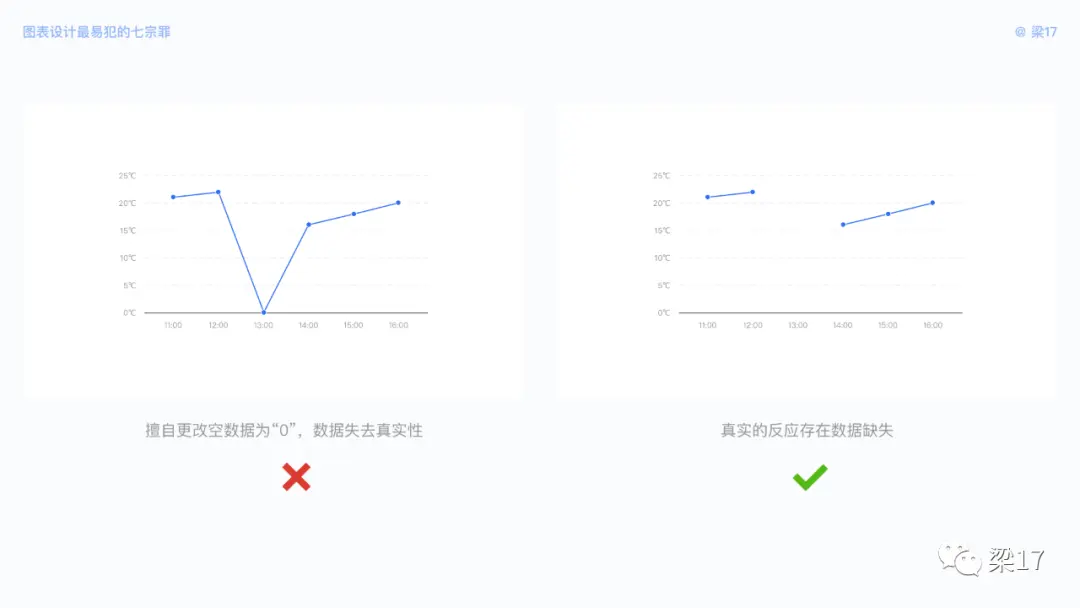
潜在风险
设计偏离用户心智与擅自定义数据,造成数据不真实,使用户接收到错误的信息。
如何避免
尽可能考虑更多的场景,与用户心智保持一致性,杜绝擅自修改数据,真实反映数据情况。
7. 误导
即错误的引导,让用户接收到错误的信息。
误导是 7 宗罪当中最严重的,前面几条多是基于无心之失,而误导却是刻意而为的。
商业活动中,所有项目都是围绕着商业价值的,我们不能否认设计是带着商业考量展开的。所以为了商业目的,或多或少会存在一些 “美化” 作用,为的是数据更好看或者更能为商业目标服务。我们作为 B 端设计师,甚至是 C 端设计,都应该真实地反映数据,而不是欺骗我们的用户。
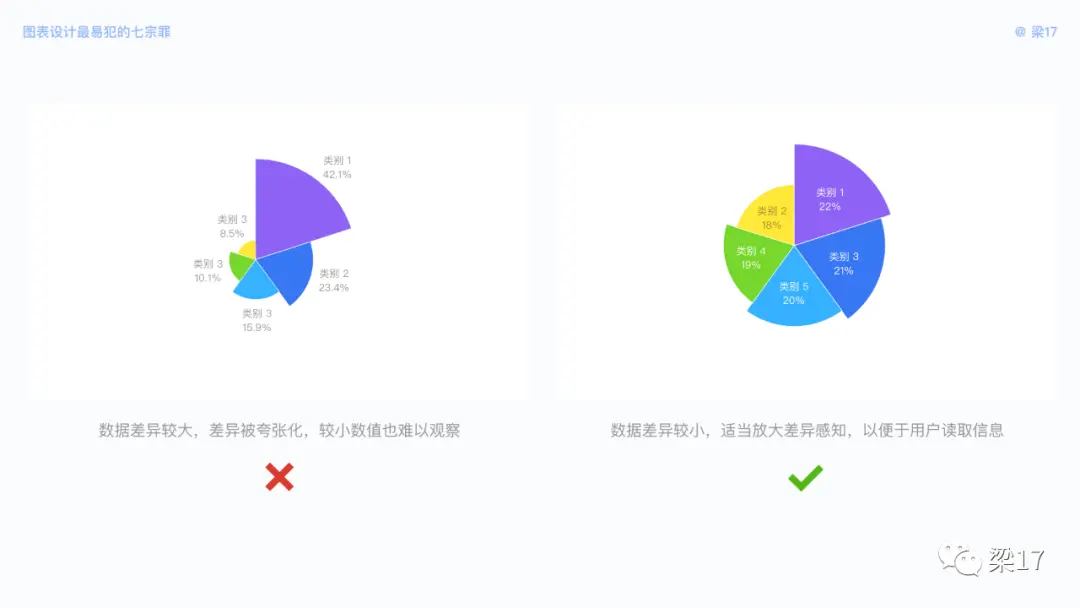
我们在第三点暧昧中提到,建议数据值差异较小时使用玫瑰图。仔细看会发现玫瑰图每个扇形角度是一致的,但半径不同。由扇形面积 S=nπr²/360 可得,数据类别的面积对比由 r² 决定,也就是半径的平方,它放大了数据之间的差异。
这一解释,似乎玫瑰图存在失真情况,但玫瑰图的真实对比不是基于面积,而是基于半径,面积只是在视觉上放大了不易观察的较小差异。
你可以理解玫瑰图是一种扇形的、旋转排布的柱状图。毕竟事物都具有双面性,我们可以用玫瑰图放大较小的差异感知,但是不可以用于夸大差异、传递某种美好的假象。其他 “美化” 手段也是如此。
Y 轴标签的起始值选取,是提案、汇报中较为常见的一种美化手段。当取值非 0 时,数据差异被直接拉大。
如左图 5 月销量看似是 1 月的 25 倍,但实际情况是它们只相差将近 2 倍。我们秉承真实反映的原则,Y 轴起始值应从 0 开始。当数据存在负值时,可根据实际情况选择负值起始值。
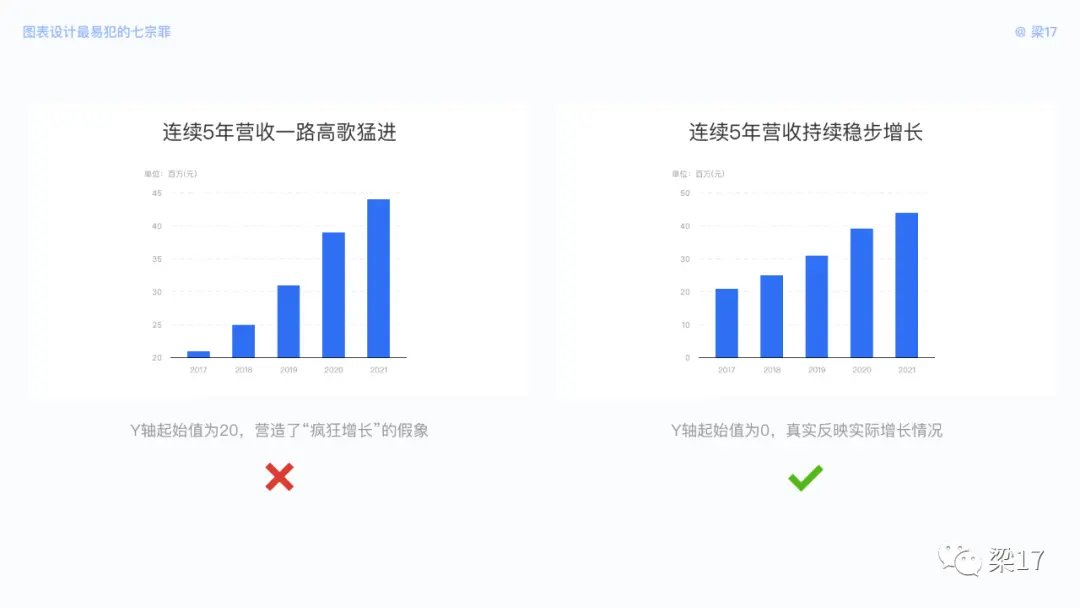
潜在风险
用户被刻意引导,接收了错误的信息,容易造成信任危机,且违反了真实原则。
如何避免
真实反映数据,放弃 “美化” 手段,真实引导用户读取真实信息,不要欺骗用户。
三、图标设计走查表
我特意整理了一份图表设计走查表,在此分享出来,希望它能帮助到大家,如果你在使用过程中有任何问题请务必向我反馈,作为体验设计师我很注重用户反馈的,嘿嘿~让我们一起持续迭代这个走查表。
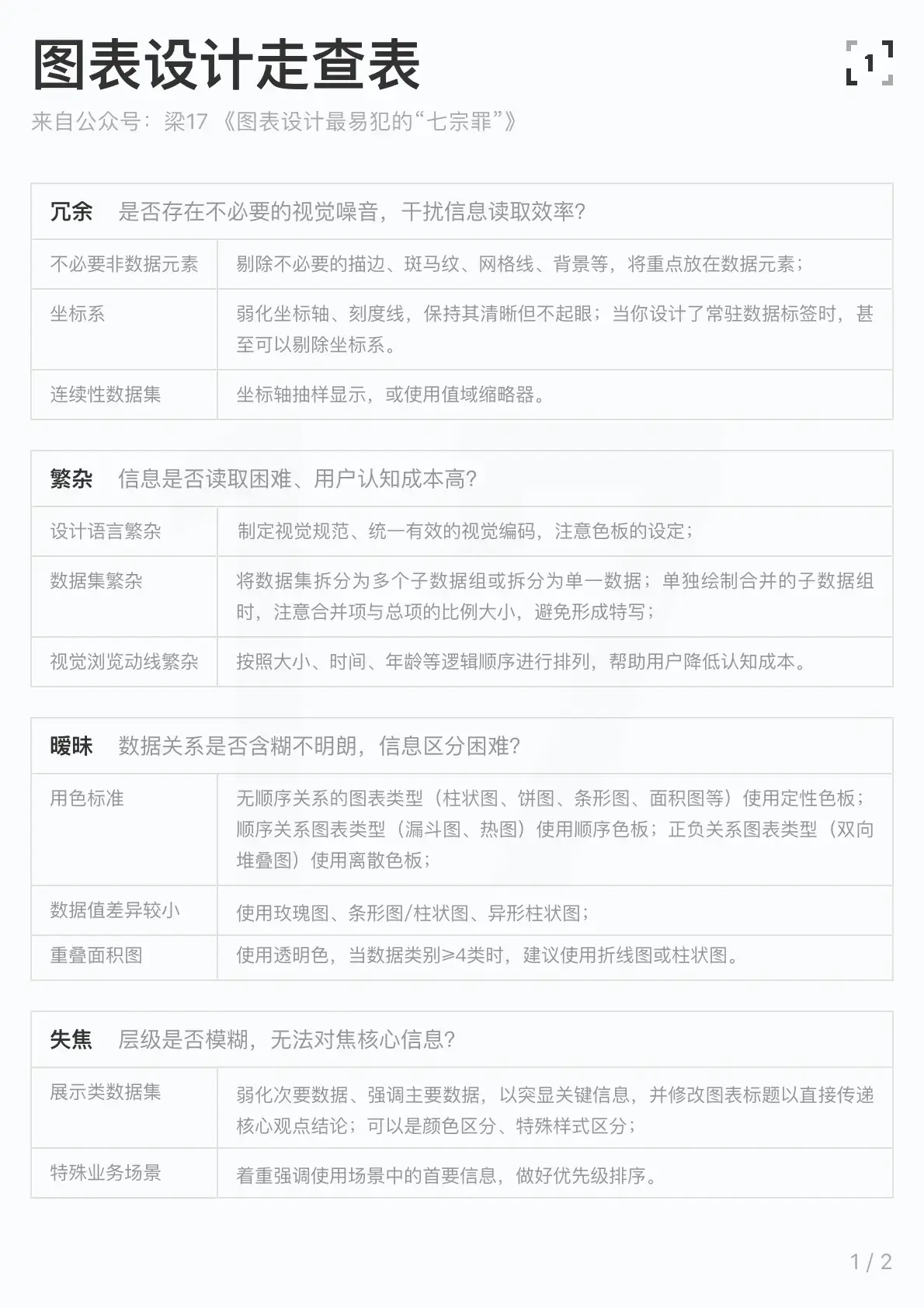
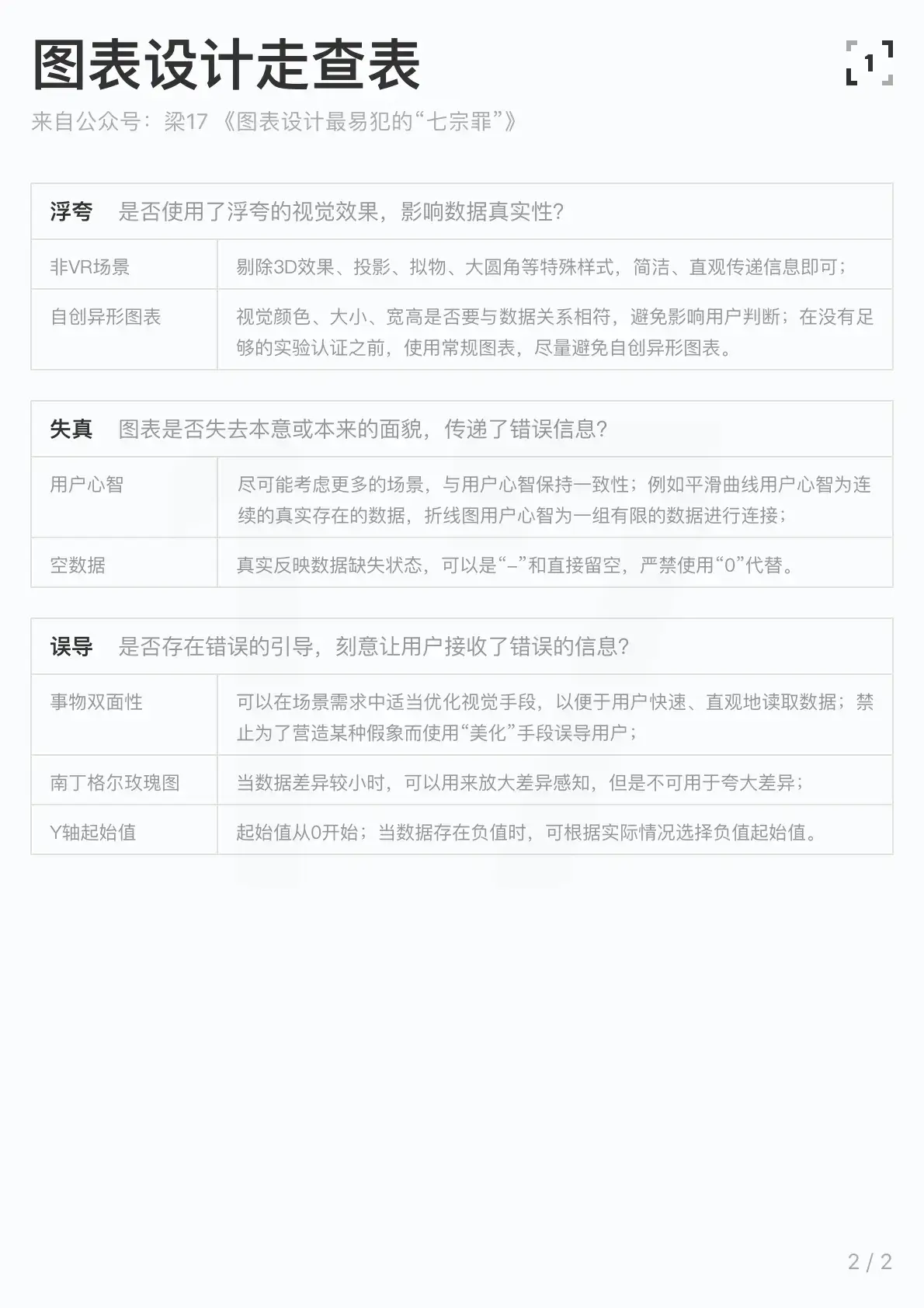
最后
以上就是本文的所有内容啦,如果你有什么 B 端相关问题,欢迎和我一起交流。在此也感谢有赞设计师 @美芳的指导,一群人才能跑得更快一点。
参考资料
http://www.woshipm.com/data-analysis/4197825.html
https://www.yuque.com/books/share/0cec1b86-5c3d-4a31-8a2e-a2dd00ab917f?#
https://www.zhihu.com/question/20855952
作者:梁 17,微信公众号:梁 17
本文 @梁 17 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议。

若有收获,就点个赞吧
0 人点赞
