关于【工作流调用】节点的设计
毕
by 毕老师
2023/8/25 00:44:53
最近这段时间一直在设计【工作流调用】节点,这个节点是非常特殊的工作流节点,它本身没有专门的处理功能,但是可以调用别的工作流作为自己的功能。有点像动漫中常见的 能力复制 角色,直接复制使用别人的能力。

利姆露·坦派斯特————《关于我转生变成史莱姆这档事》 能力概述:不止能够复制能力,还能够变化为被吞入对象的模样。因为被吞入者并不一定会死亡,而且相关能力也不会消失所以是复制。 来自萌娘百科
通过【工作流调用】节点我们可以把一个复杂的任务通过拆分重组,设计出非常复杂的系统。我认为这是一个非常有价值也非常有潜力的节点,会在未来发挥非常重要的作用。
最开始的设计是将【工作流调用】节点视作常规节点,在后端服务器的程序里,它会被当做一个常规节点,由一个函数进行处理,可以类比 backend/worker/tasks/tools.py 中的 <font style="color:rgb(31, 35, 40);">programming_function</font> 函数:
python@taskdef programming_function( workflow_data: dict, node_id: str,): workflow = Workflow(workflow_data) ... return workflow.data
由于【工作流调用】节点就是用来调用工作流的,因此最直接的想法就是利用现有的 API 调用工作流机制,在一个函数里通过 API 的方式由后端服务器调用工作流并获取结果。
这样的设计最简单,也不需要对现有工作流运行机制和后端工作流服务程序做太多改变,实际上还是一个普通的节点设计形式,只是它的功能是调用工作流而已。
当我们的后端工作流服务不需要处理特别复杂的工作流也不需要处理大量并发的工作流时,这样的设计是没有问题的。但是这样的设计有个非常大的隐患,就是一旦工作流设计比较复杂比如有多层嵌套调用,或者同时需要处理多个带有工作流调用节点的工作流时,后端服务就会完全被卡死,无法处理任何请求,而且这个死锁通过增加后端处理进程(或节点)的数量仅仅可以缓解,无法完全解决,因为这是从根本的逻辑设计上存在的问题。
这个问题的原因其实不复杂,首先需要解释一下我们后端工作流服务程序处理工作流的逻辑,这个处理逻辑在开源版和我们 SaaS 版都是一样的。在我们的后端工作流服务程序中,每个节点在前端体现为一个模块,而在后端就体现为一个函数。

当后端工作流服务程序接收到一个工作流的请求时,它会根据工作流的节点连接情况,按照图论中的拓扑排序算法* 对工作流节点进行排序,然后按照排序后的顺序依次处理工作流节点,每个节点的处理都是一个独立的进程,这样的设计可以保证工作流节点的并发处理,提高工作流的处理效率。
关于拓扑排序的简单理解:比如当你在学校选课时,你必须先修完某些课程才能修其他课程,这些课程之间的互相有先后的依赖关系,那么找到一个合理的选课顺序就是拓扑排序的过程。
比如课程 A 需要先修完课程 B 和 C 才能修,而课程 C 又需要先修完课程 D 才能修,那么一个合理的选课顺序就是 D -> C -> B -> A 或者 D -> B -> C -> A 等等,这就是拓扑排序的结果。
对应到我们的工作流节点中,比如节点 A 的 A1 参数是 B 节点的输出得来的,那么我们就必须先处理 B 节点,然后才能处理 A 节点。所以为了得到一个合理的工作流处理顺序,我们需要对工作流节点进行拓扑排序。
向量脉络中有向无环图拓扑排序部分代码
假设我们有一个进程来负责处理所有的工作流,现在同时来了两个工作流请求,工作流 A 需要处理 A1 -> A2 -> A3,工作流 B 需要处理 B1 -> B2 -> B3,那么这个进程可以按照 A1 -> A2 -> A3 -> B1 -> B2 -> B3 的顺序处理工作流节点,也可以按照 A1 -> B1 -> A2 -> B2 -> A3 -> B3 的顺序处理工作流节点,只要节点的拓扑排序结果是正确的,那么这个进程就可以处理这两个工作流。
在没有【工作流调用】节点时,我们不需要担心进程会在某个时间点卡死,因为所有节点都是一个函数,不存在嵌套依赖的关系。反正在一个有限的时间内这个函数要么执行完成,进程开始处理下一个节点,要么处理失败,进程处理别的工作流节点任务。
很容易可以想到,当我们增加进程数量时,后端服务处理工作流的效率会提升,反正不用非得在同一个节点处理一个工作流的所有任务,只要有空闲的进程,那么工作流节点的任务就可以被处理。这样我们始终可以保证不会出现某些进程一直忙于处理某个工作流的多个节点任务,而其他进程却一直处于空闲状态的情况。
这个设计可以使得我们能够非常轻松地横向扩展后端服务的能力,甚至同一个工作流的各个节点处理可以不在一台服务器完成。
然而当节点中有【工作流调用】节点时,情况就变得麻烦起来。极端情况考虑,假设现在我们只有一个进程用于处理工作流。工作流 A 的节点调用是 A1 -> A2 -> A3,其中 A2 节点是【工作流调用】节点,调用的是工作流 B,B 的节点调用是 B1 -> B2。我们会发现按照先前的设计,这个进程处理到 A2 节点时会发出一个新的工作流处理请求 B,等待 B 的处理结果,然后继续处理。但是由于我们只有一个进程,这个新的工作流处理请求没有进程可以处理!这个进程就会一直等待 B 的处理结果,而 B 的处理又需要等待工作流 A 完成,这样就形成了一个死锁,整个进程就会卡死,无法处理任何请求。
增加一个进程可以缓解这个局面,然而一旦同时有多个工作流调用节点,那么这个问题就会再次出现。
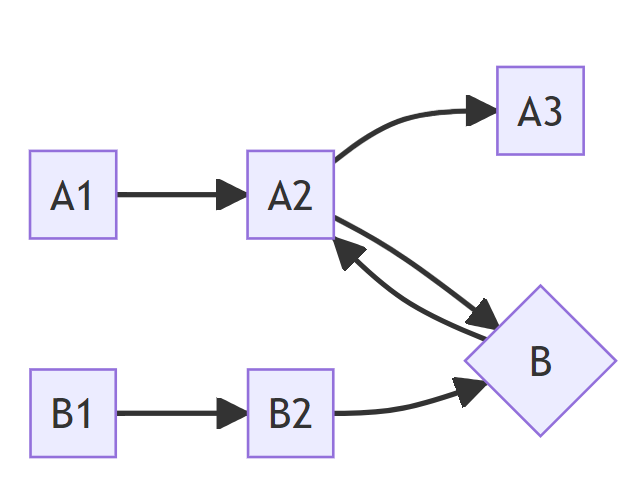
我把上面那段话给到流程图生成工作流里,AI 给我画出来的流程图示意。
因此你可以看到,如果还是将【工作流调用】节点当做一个普通节点,以 API 调用的方式处理它,这样会存在根本的设计逻辑问题。我们必须重新设计【工作流调用】节点的处理方式。
一种方案是当遇到工作流调用节点的处理任务时,进程不要等待直接释放,然后定时查询子工作流的处理结果。这样虽然可行,但是需要对整个结构设计做比较多的改动,个人感觉会变得不太清晰简洁。
另一个方案是在收到工作流处理请求的时候,针对【工作流调用】节点进行特殊的 展开 处理。比如上面的例子中 A2 节点实际上是调用 B1 -> B2,那我们直接把 A2 节点的连线替换为 B1 -> B2,此时工作流 A 就变成了 A1 -> B1 -> B2 -> A3,这样就可以直接处理了。

那么即使 B1 节点也是一个【工作流调用】节点,我们也可以继续递归展开,直到所有的【工作流调用】节点都被展开为止。这样的设计可以保证我们的工作流处理进程不会因为【工作流调用】节点而卡死,而且也不需要对整个工作流处理逻辑做太多改动。对应的代码实现:https://github.com/AndersonBY/vector-vein/blob/943cdb88be41e84ecd35eb933abd309edb13abce/backend/utilities/workflow.py#L146
当工作流处理完成以后我们再重新按照原始的工作流节点找到展开后的节点对应的计算结果并更新即可。
这样的设计实际上对原始的工作流处理系统没有什么大改动,只在接收到工作流时需要先做 展开 处理,在工作流任务完成后做 折叠 处理即可。
一个小问题是这样调整后子工作流的调用记录不会体现在子工作流的工作流运行记录中,不过这个不是大问题,如果非要记录也可以特殊处理一下。
好了,这就是对【工作流调用】节点的简单设计思考,目前看来应该没有什么大问题,后续再观察一下。
PS: 如果你切换语言会发现博客还有英文版本,当然这个都是用的 Markdown 保留格式翻译 工作流完成的。

