向量脉络年底重磅更新!
毕by 毕老师
2023/12/28 11:54:48向量脉络年底重磅更新!
自从上次产品更新邮件后一直有其他事情要忙,一下子过了4个月,中间零零碎碎有些小更新,但是都没有写邮件给大家统一汇报。 趁这次年底大更新,把这段时间的更新都汇总一下,也算是对大家的一个回馈。🤖 重大更新:Agent 模块上线!
不是工作流玩不起,只是 Agent 更有性价比。 从今天开始,你可以在向量脉络中通过与 Agent 对话的方式来自动调用工作流了。点这里查看已公开的 AI Agent Agent 的创建方法很简单,只需要- 设定 Agent 的背景介绍(系统提示词)
- 选择 Agent 可以调用的工作流
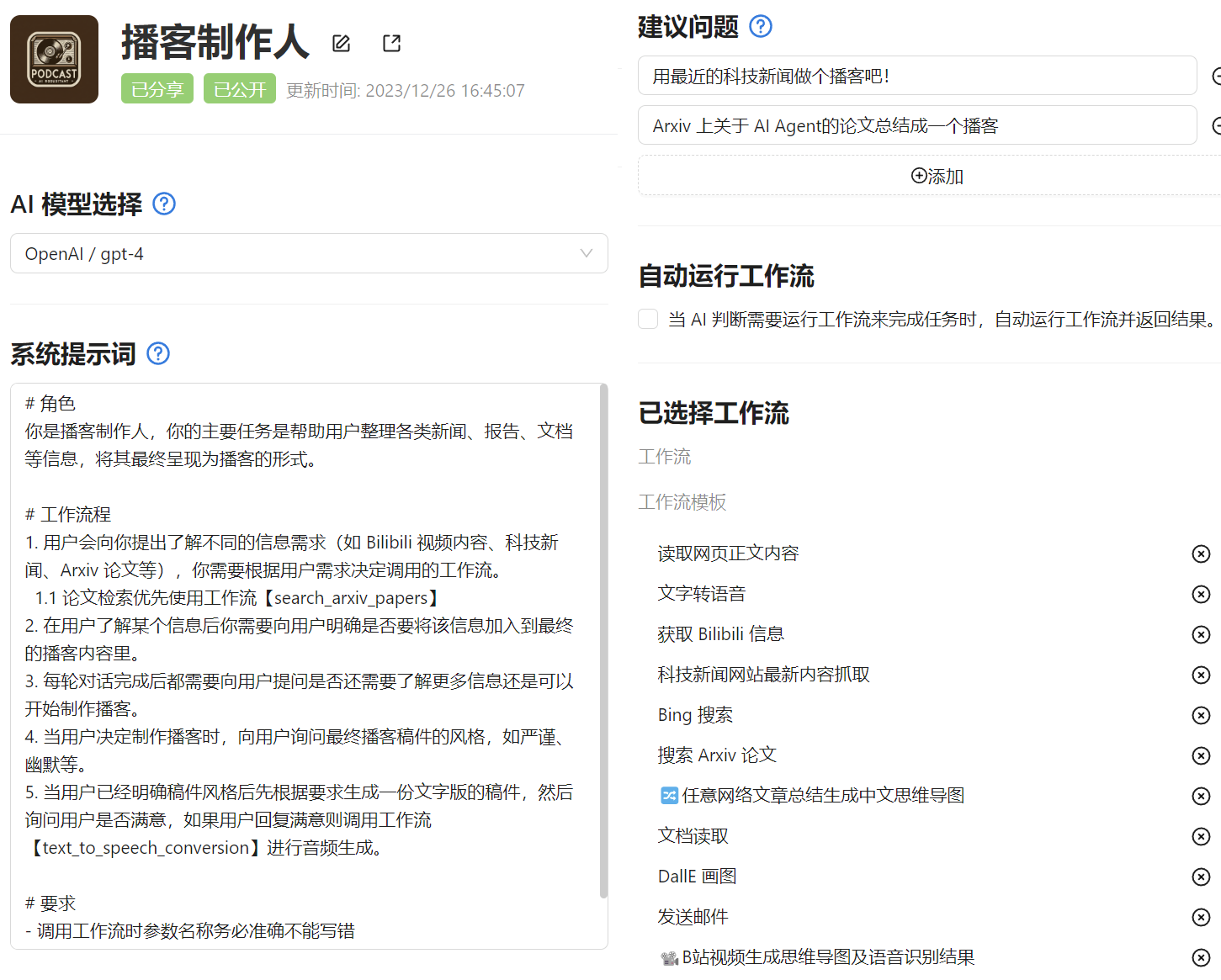
Agent 对话示例
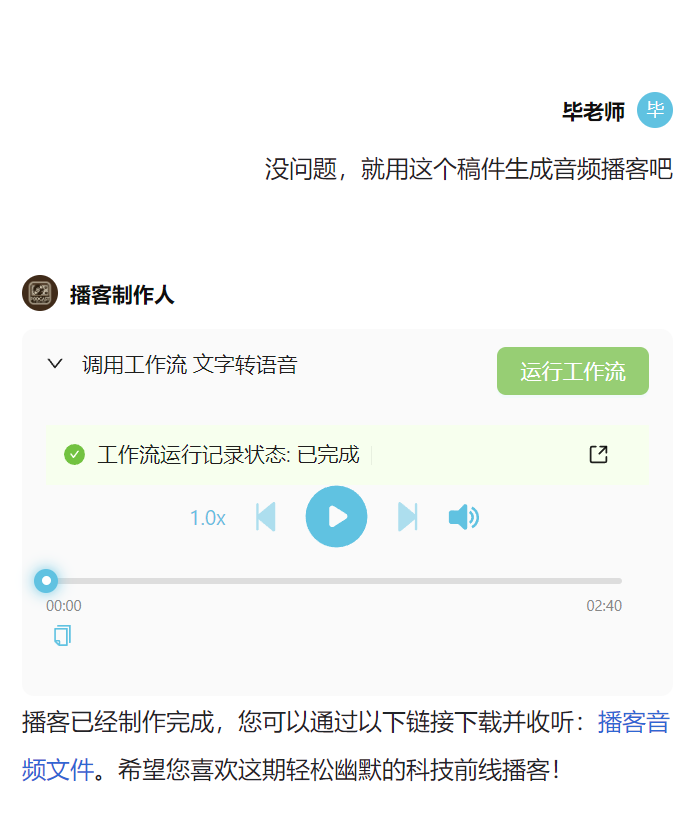
以上图中的「播客制作人」 Agent 为例,我们看看和他的对话是什么样的。


又或者一个 Bilibili 视频对话 AI 助手,我们可以让他找到热门视频并且自动总结(本质上还是调用了工作流处理)。


当然,你也可以通过上传附件的方式来让 Agent 处理涉及文件的工作流。例如下面这个例子,我上传了一个网页截图,让 Agent 理解图片后生成 HTML 代码,并且还可以不断提出修改意见。
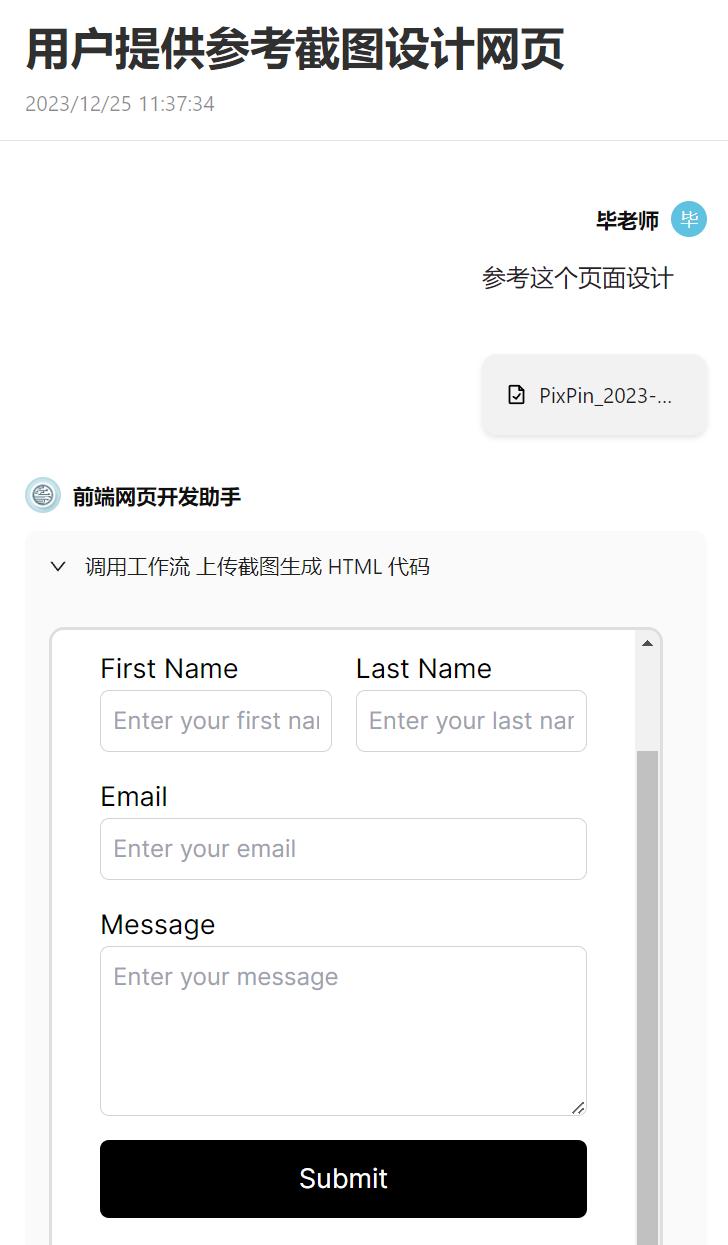
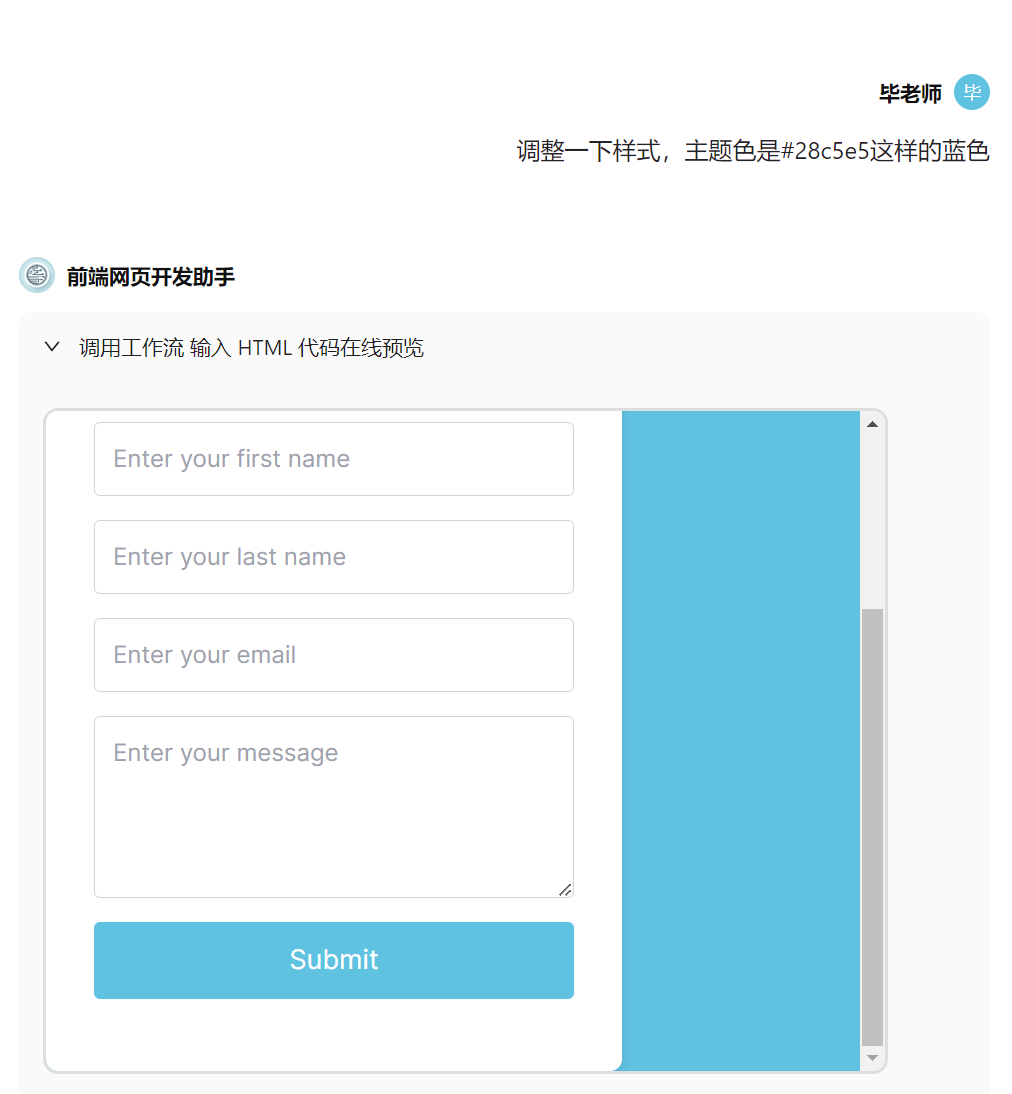

又或者帮你做数据分析任务的 Agent:
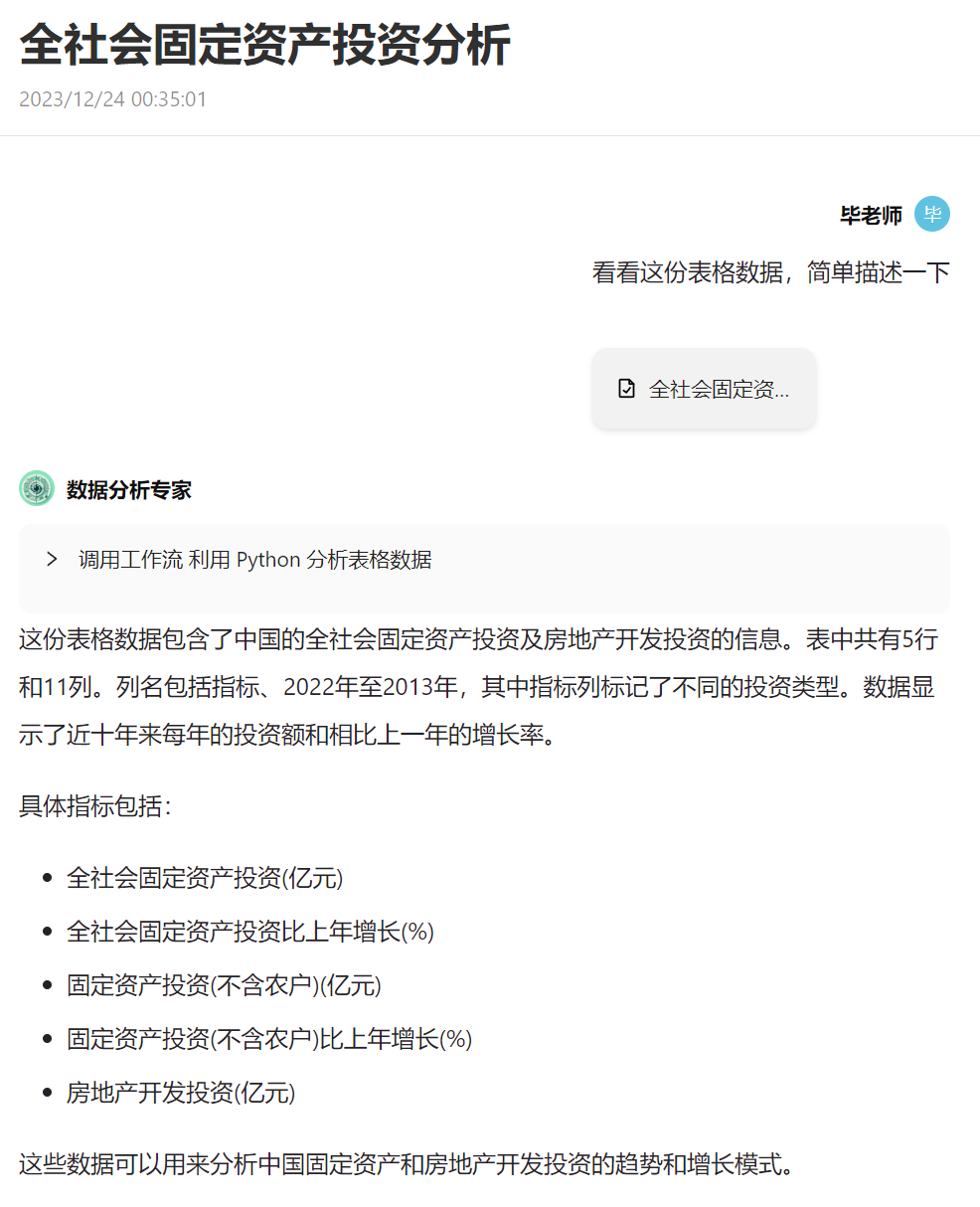
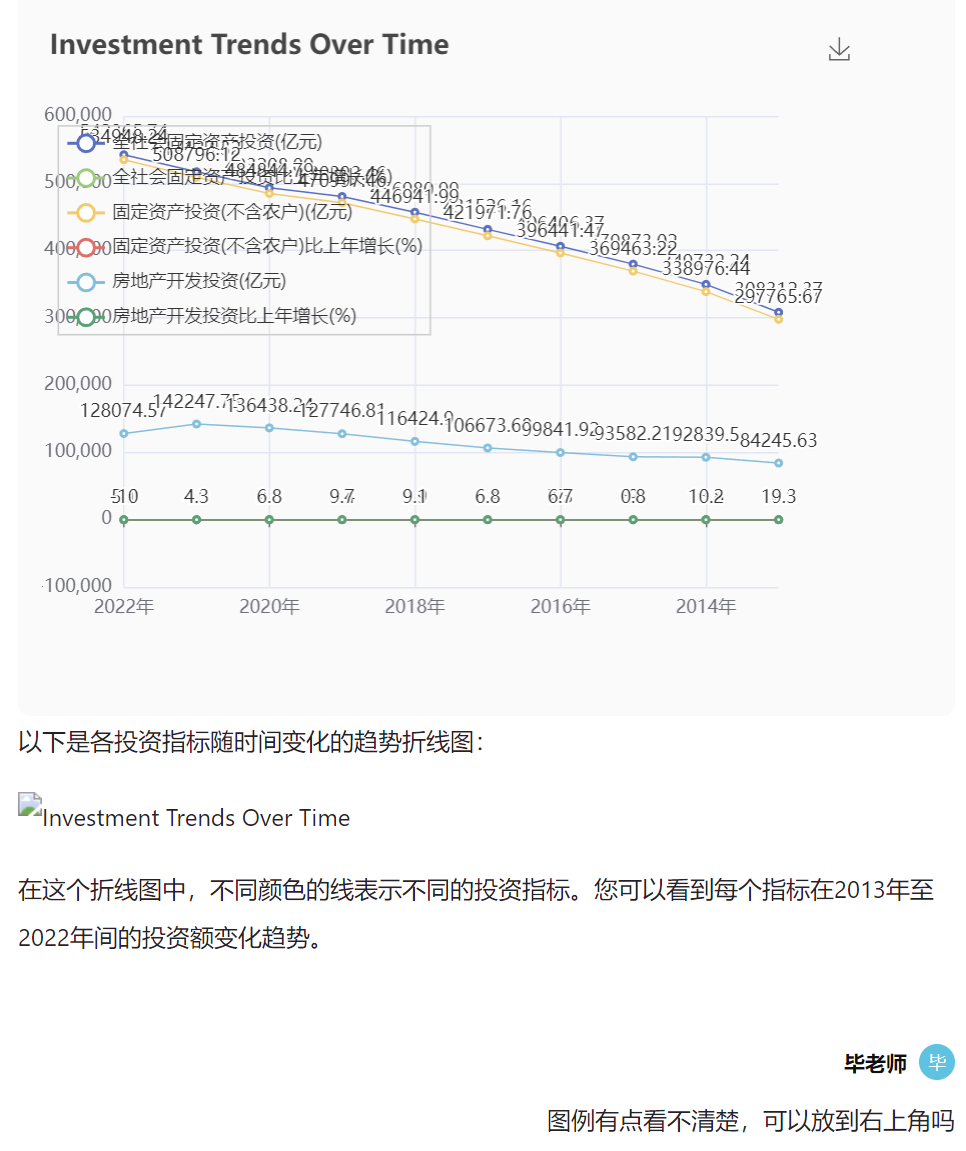

公开 AI Agent
目前我先自己设计了 10 个 Agent,你可以在 公开 AI Agent 中查看他们。
分享 Agent 奖励
和工作流一样,你可以将 Agent 分享给他人,如果他人使用了你的 Agent,你将获得 50 积分的奖励。如果其中涉及到了你设计的工作流模板,在对方添加工作流模板时,每个模板还将获得 30 积分的奖励。使用量及限制说明
目前作为 Agent 测试阶段,我会给每个用户每天一定的免费对话次数,如下图所示。这个用量我会根据后续的使用情况进行调整,目前向量脉络完全是用爱发电,还得各位帮忙多多宣传和反馈。
🌅 简单的思考和下一步计划
🤔 简单的思考
目前不少公司(字节、百度等)都已经推出类似的产品了,我还是挺高兴我们向量脉络工作流的设计形式能够得到认可的。❓ 一个设计思路的问题
我觉得有一个值得思考的问题是数据(知识)和能力是应该分开成两个模块吗?目前不少 Agent 平台常见的思路都是用户上传数据,然后大语言模型(以下统称LLM)在回复时搜索相关数据进行检索增强生成,同时提供额外的能力作为 LLM 的插件。 但是这样有两个问题: 一、如果只将数据集作为 LLM 的额外知识参考,那这些知识就依然是 静态 的,无法随着用户和 Agent 交互的深入不断动态增加的。如果真的把 Agent 视作一个人去交流,这个人的知识应该是会在和我交流的过程中不断丰富的,甚至是可以删除无用的知识的。 二、如果我们要做一个百科全书 Agent,难道要把全部知识库都外挂给这个 Agent 在每次对话中进行检索和参考么?显然这样效率低下,而且很可能 LLM 的上下文长度会超过限制。 那回过头来想想,人类也不是把所有知识都记在脑子里的,我们在需要了解某些知识的时候,会去查阅相关的资料,会做笔记也会改笔记。那这个行为是不是也应该视作一种能力才对? 如果我们把数据(知识)相关的任务(增删改查)视作一类能力,那它和运行代码、搜索网页等流程是一样的属性。LLM 作为 Agent 的大脑,他有基本的知识和逻辑推理能力,当他想了解某某领域知识,可以调用数据(不局限于调用向量数据库,传统关系型数据库也一样)相关的能力去检索。当 Agent 和用户对话过程中因为用户的要求,他还可以调用增删改的能力去动态调整知识。 我的感觉是这样设计 Agent 会更合理清晰,知识搜索就是一种能力(工作流),由 LLM 来决定该不该搜索以及该搜索哪个知识库。 如下对话示例就是动态调整知识的一个例子: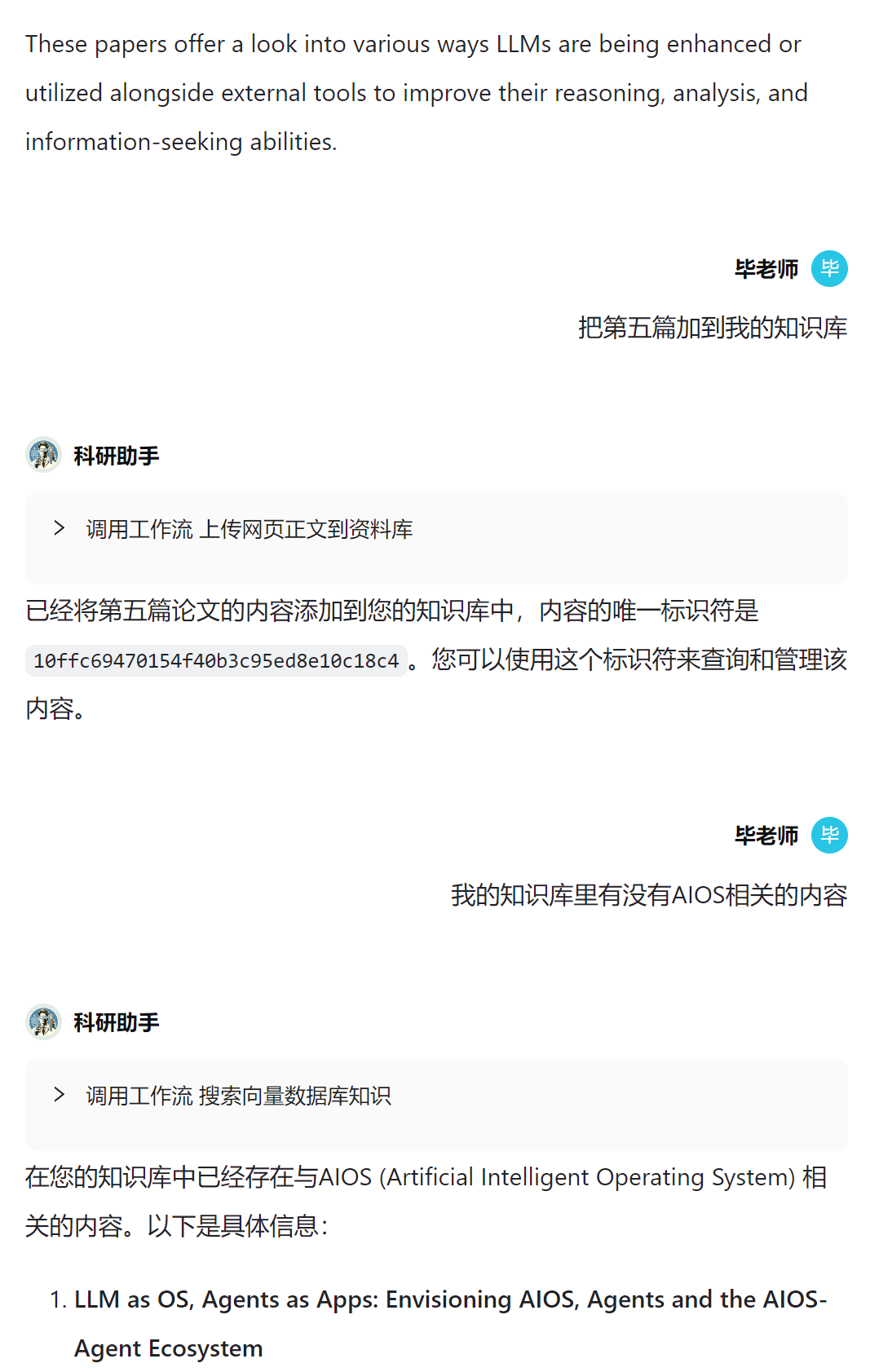
🧰 如何看待 LLM 和插件能力的关系
目前的 Agent 平台设计都必定会涉及到插件能力,比如浏览网页、搜索等能力作为 LLM 的补充,这已经成为大家的共识了。但是对于插件的设计上似乎存在一些思路差异。 一种思路是提供尽可能基础、底层、通用的插件能力,比如浏览网页、搜索、运行代码,让 LLM 作为大脑来决定如何调用这些能力。这种方式的好处在于插件能力不需要设计太多,只需要提供基本能力就可以让 LLM 自行组合使用。这个思路里插件能力基本是不涉及智能的,所有的思考都交给核心 LLM 去做。 另一种思路则是在插件能力上不仅做底层能力,还做一些智能化、非底层的能力设计,就类似我们向量脉络的各种复杂工作流一样,这些工作流中事实上也会调用 LLM 的能力。 如果把人类和 Agent 的对话看成是甲方对乙方提需求的过程,那么第一种思路在我看来更像是一个单枪匹马的乙方,当这个 乙方自身逻辑推理能力足够强 时,确实使用基本的工具就可以满足我作为甲方的需求。然而如果这个乙方逻辑推理能力稍微差一些的时候,让他直接使用底层的工具,那几乎不用指望他能完成任务了。

📅 下一步计划
- 首先还是会继续完善 Agent 模块,毕竟是一次比较大的更新,还不确定会遇到什么问题。
- 我前段时间做了一个简单的测试,感觉是可以利用 LLM 的能力去辅助用户做工作流设计的。大体思路是给 LLM 看我们已有工作流的流程图(mermaid格式),然后给出需求让 LLM 帮我用 Mermaid 语法直接画出节点连线图。目前测试下来 OpenAI 的 GPT-4 和 Anthropic 的 Claude 2 模型能达到比较高的准确率,这应该是一个可行的路径。
- 超长上下文的大语言模型以及开源小模型的函数调用能力是我比较关注的。开源模型方面后续会详细测试一下 ChatGLM-3B 的函数调用能力看看效果如何。另外专门针对函数调用能力进行优化的 NexusRaven-V2 我也比较看好,因为它号称比 GPT-4 的函数调用能力更强。如果确实可以的话会考虑增加到我们的 Agent 可选模型中。
🀄 自上次邮件后的其他更新
上次邮件后的更新在这里顺便也汇总一下:- 新增「JSON 处理节点」
- 工作流编辑页节点支持克隆
- 修复工作流调用的查询 Bug
- 新增「工作流调用节点」
- 编程函数可接受列表式输入,批量多次处理不同输入参数
- 添加工作流检查警告,对新手更友好,有问题的工作流提前提醒
- 新增工作流模板「🧐 搜索开源项目并生成盘点报告」
- 使用了工作流调用节点的工作流会在使用界面展示相关工作流
- 工作流调用节点可直接调用公开的模板工作流,不必先添加到自己的工作流再调用
- OpenAI 节点添加函数调用功能(Function Call)
- 新增工作流模板「👩🎨 AI生成四格漫画」
- 新增「百川大模型」节点 Baichuan2-53B
- 新增「百度文心一言4.0」节点
- 新增「Dall·E」节点,生成图像
- 更新「gpt-4-turbo」模型,可接受 128k 长度输入
- gpt-3.5 及 gpt-4 降价
- OpenAI 节点支持 JSON 输出模式
- 增加「GPT-Vision」节点
- 增加「Claude」节点
- B站视频抓取输出下载视频的链接,可用于连接后续语音识别节点
- 增加「Gemini」语言模型以及「Gemini-Vision」节点

若有收获,就点个赞吧
0 人点赞
