

1 如何开启模型训练
更新时间:2024-03-16 00:56:00 本篇文章讲解如何训练新模型。视频介绍
定义
模型调优是通过Fine-tuning训练模式提高模型效果的功能模块,作为重要的大模型效果优化方式,用户可以通过构建符合业务场景任务的训练集,调整参数训练模型,训练模型学习业务数据和业务逻辑,最终提高在业务场景中的模型效果。优势
•推理加速:平台底层默认进行模型压缩和推理加速,屏蔽机器管理和推理加速的技术工作。 •全链路训练平台:丰富、完整的模型训练工具,支持SFT、LoRa等多种优化方式,训练之后支持一键部署。 •多维度评估:支持单模型、多模型对比等多维度评估方式。训练前的数据准备
训练集:训练所用的数据集,格式一般为Prompt+Completion的文本数据,可通过excel/json进行编辑和上传,最小训练数据条数为20,最大训练数据条数为10000,一条训练数据Prompt+Completion总字符数不高于8000,高于8000的字符数系统将自动截断。通过模型训练可增强模型能力,提升预测效果。
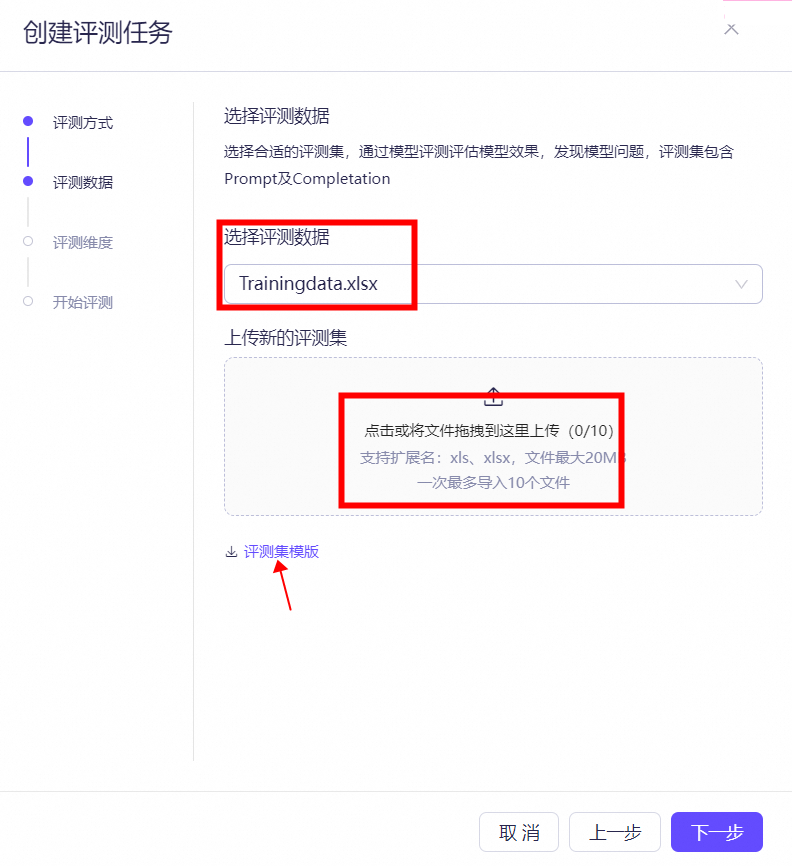
评测集:评测所用的数据集,格式一般为Prompt+Completion的文本数据,评测系统将自动基于Prompt数据预测模型结果,可通过参考评测集中的Completion数据对模型预测结果进行标识,判断模型效果,最小评测数据条数为1,最大条数为5000,Prompt总字符数不高于8000,以实际需要为准。通过模型评测评估模型效果,发现模型问题。
说明
Prompt:即提示词,简单的理解为它是给大模型的指令。它可以是一个问题、一段文字描述,甚至可以是带有一堆参数的文字描述。大模型会基于 prompt 所提供的信息,生成对应的文本或者图片。 Completion:是指根据Prompt输出的对应的答案/内容。 Prompt+Completion类于FAQ的格式。及一问一答的数据内容。模型微调训练方式
数据准备
准备多少数据做SFT微调训练合适? SFT微调训练效果受大模型参数及训练数据集数量影响,数据量达到一定阈值后,效果不会再有明显上升。SFT不同训练任务的数据实验参考
文本分类任务-情感分析:
| 训练数据量 | 100 | 200 | 500 | 1000 |
|---|---|---|---|---|
| 准确率 | 0.9559 | 0.9719 | 0.9719 | 0.978 |
文本生成-阅读理解
| 训练数据量 | 100 | 200 | 500 | 1000 | 2000 |
|---|---|---|---|---|---|
| 准确率 | 0.5808 | 0.5992 | 0.6202 | 0.611 | 0.6235 |
序列标注-命名实体识别
| 训练数据量 | 200 | 500 | 1000 | 2000 | 3000 | 4000 |
|---|---|---|---|---|---|---|
| 准确率 | 0.4749 | 0.5251 | 0.5731 | 0.6164 | 0.6613 | 0.6593 |
句对关系任务-文本匹配
| 训练数据量 | 100 | 200 | 500 | 1000 |
|---|---|---|---|---|
| 准确率 | 0.7515 | 0.7758 | 0.7828 |
上传数据集
点击训练数据—上传训练集—上传文件—点击完成。说明
支持批量上传,最多同时上传10个训练集; 支持拓展名为xls、xlsx、jsonl;(已提供上传模板文件) 单个文件最大20M;

模型调优
点击【模型调优】模块,选择【训练新模型】按照提示进行创建。新增过程的专业名词可查看概念解释学习。

超参配置
企业可以通过参数配置来影响模型调优的过程,从而影响模型调优的效果,不同的参数配置训练的结果不同,一般建议使用默认配置。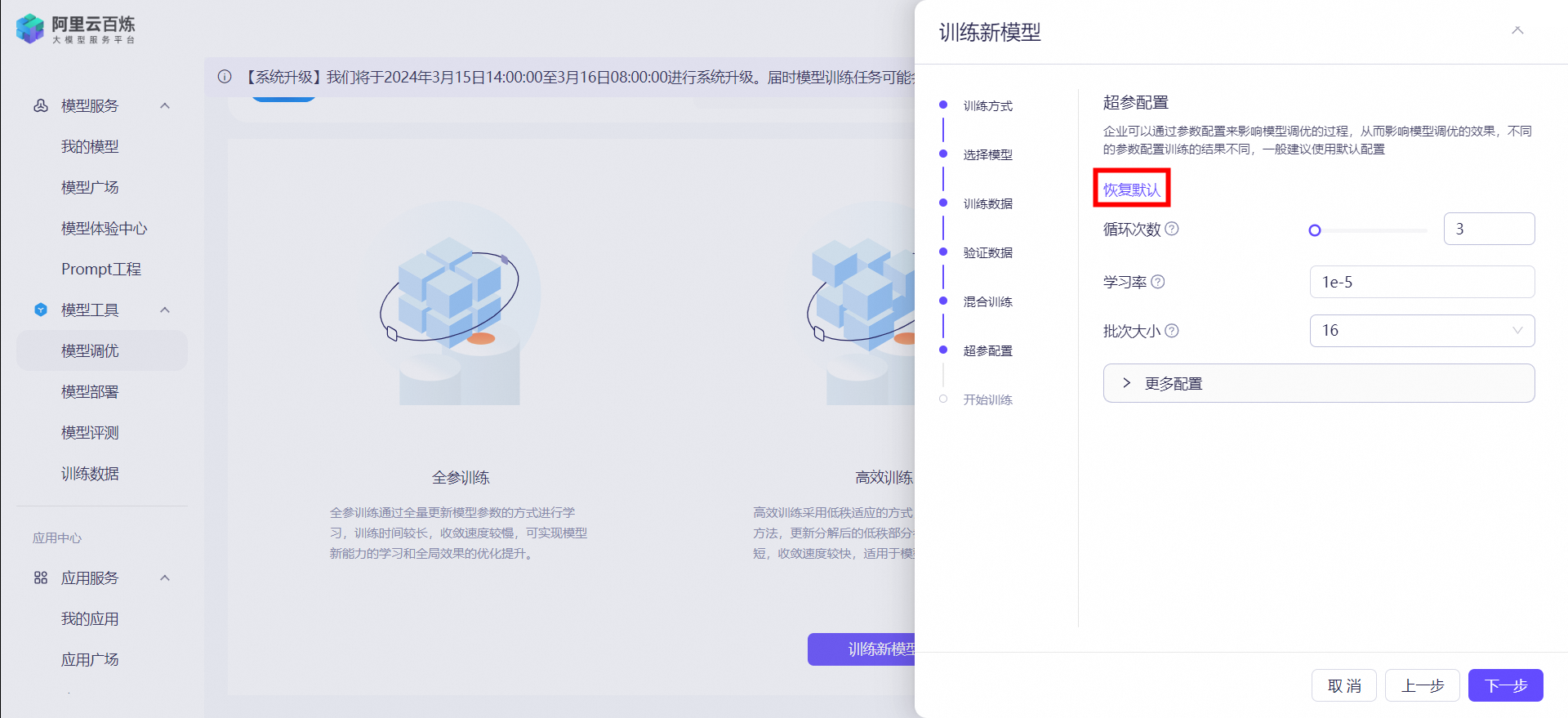
开始训练
预览你的训练配置,准备开始训练,开始训练将进入队列,可在模型管理列表刷新状态,同时,可查看训练过程中的相关指标,训练结束后将通过推送通知。重要
模型调优将产生训练费用,训练价格 0.1元/千tokens ,点击查看产品计费。
计算公式:
计费token数= 训练集token数 * 循环次数。
模型调优开始后,就会产生费用(训练失败除外)。


说明
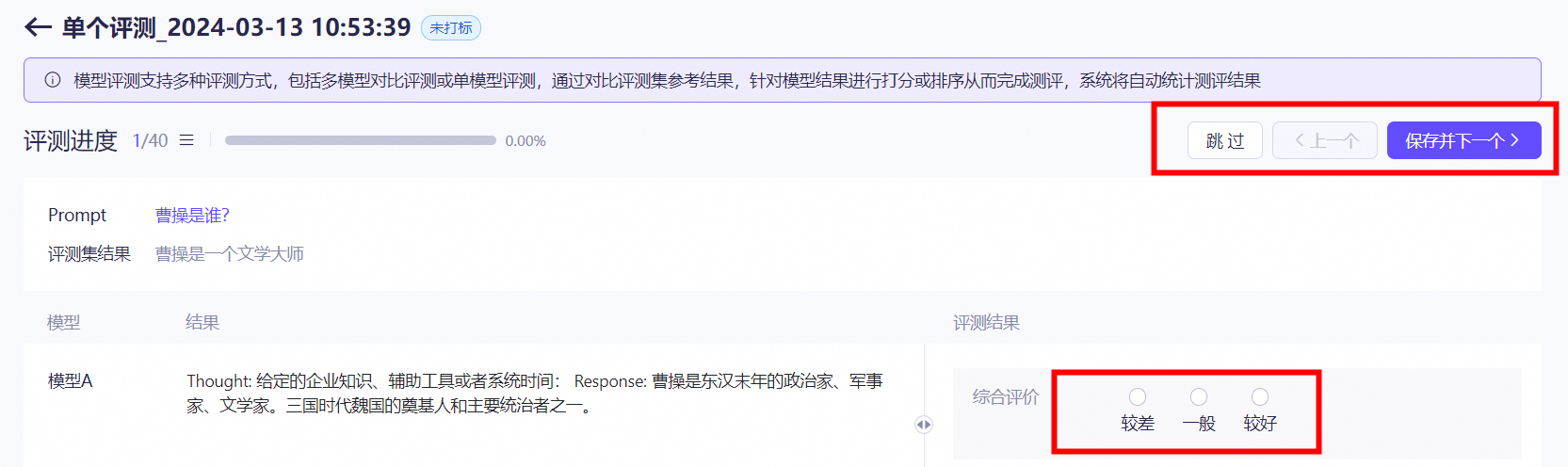
点击查看预估,可以查看本次训练的预估费用。 在训练中的模型可以点击查看了解进度,也可以点击终止训练停止。模型评测
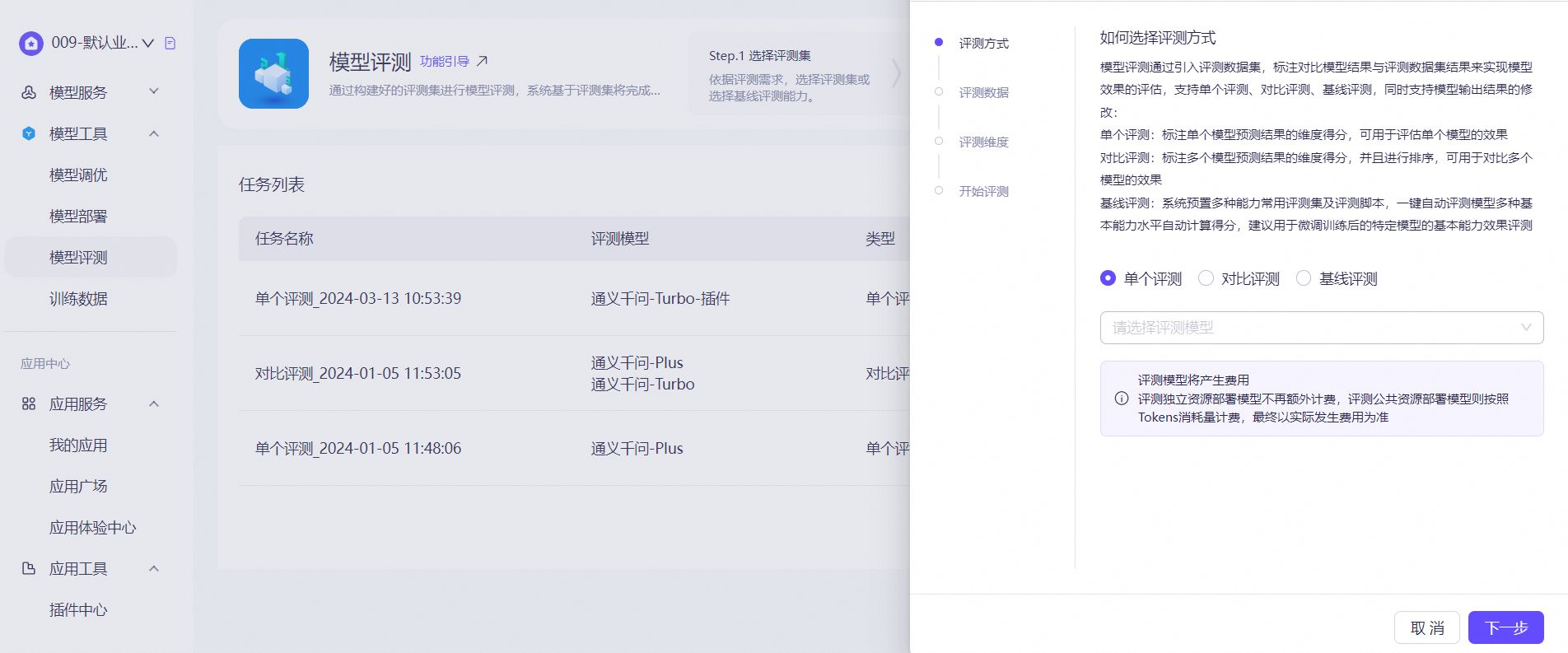
上传模型数据
路径:模型工具—模型评测—创建评测任务。



2 如何使用流程编排处理复杂业务场景
更新时间:2024-04-07 18:20:05 本篇文档主要介绍流程编排中各流程变量的含义及操作方法。定义
支持通过画布的方式,编排复杂业务流程对接大模型。完成流程编排后,可以直接创建关联新建应用或关联已有应用。提升接入大模型的效率,同时提供应用流程的全生命周期管理,包括流程编排、试验、部署等。通过配置流程编排实现让天猫精灵随机播放一首歌曲
由于随机播放,我们可以根据您所处区域的天气来推荐一首歌曲,所以我们会用【API调用节点】调用天气接口,然后将天气结果传入【大模型节点】的Prompt中,最终大模型推荐了一首歌曲,我们再利用脚本节点将大模型推荐的歌曲进行最终结果拼接。配置展示
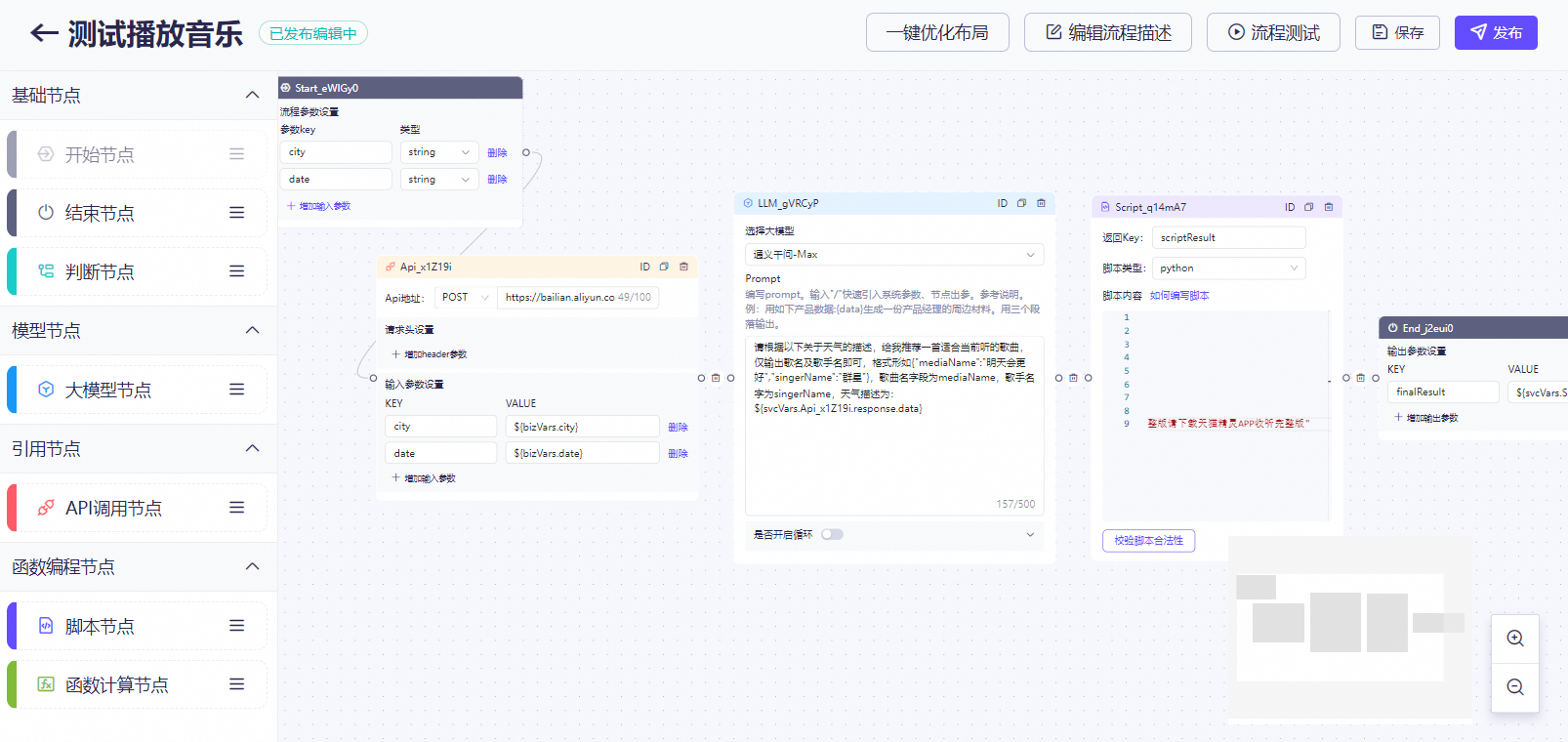
配置方式
开始节点
想要查询天气情况,需要城市和日期,这两个变量需要外部服务传入,所以开始节点需要添加这两个参数,city、date。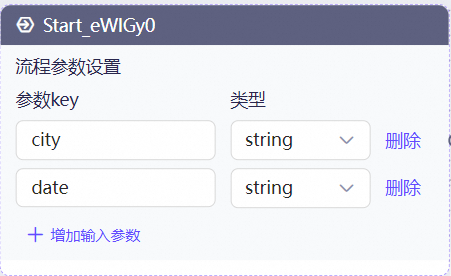 ### API调用节点
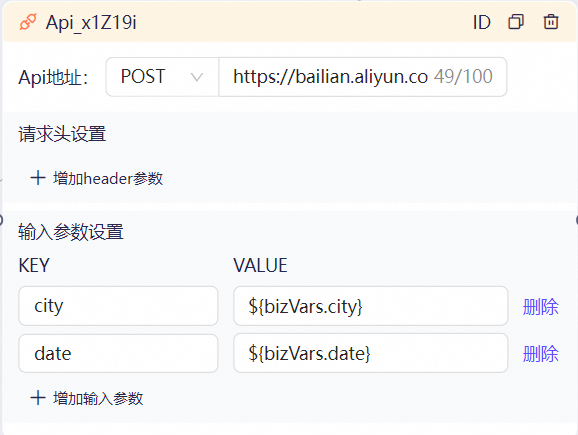
注册查询天气的接口:https://bailian.aliyun.com/sample/weather/queryV2。
### API调用节点
注册查询天气的接口:https://bailian.aliyun.com/sample/weather/queryV2。
说明
当前平台提供的是一个mock接口只为调试使用,不是真实数据,返回结构为:点击增加输入参数,将API的入参和当前传入的city、date参数进行映射,获取变量的方式请参考流程变量含义及取值方式说明。
{"status": "success","errorInfo": "","data": "小到中雨,气温15~27℃"}
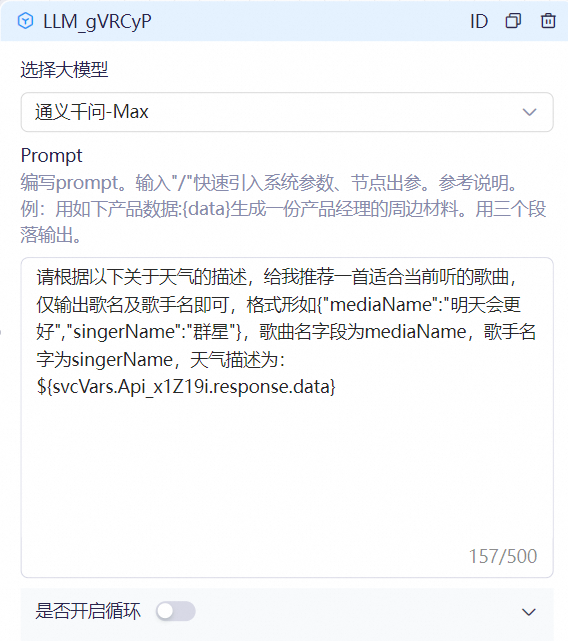
大模型节点
示例Prompt:请根据以下关于天气的描述,给我推荐一首适合当前听的歌曲,仅输出歌名及歌手名即可,格式形如{“mediaName”:”明天会更好”,”singerName”:”群星”},歌曲名字段为mediaName,歌手名字为singerName,天气描述为:${svcVars.Api_XWndOx.response.data}
重要
prompt中用到了api节点产生的结果,关联表达式为${svcVars.Api_XWndOx.response.data},注意这个Api_XWndOx为API调用节点的id,使用例子内的示例时,Api_XWndOx需要替换成自己API调用节点的节点id,具体取值方式请参考流程变量含义及取值方式说明。 可以使用提示功能,在Prompt录入区域输入”/“,api节点的输出前缀会出现在提示下拉当中,由于接口的结果为json,要获取的字段为data,所以最终的表达式为${svcVars.Api_XWndOx.response.data}。
脚本节点
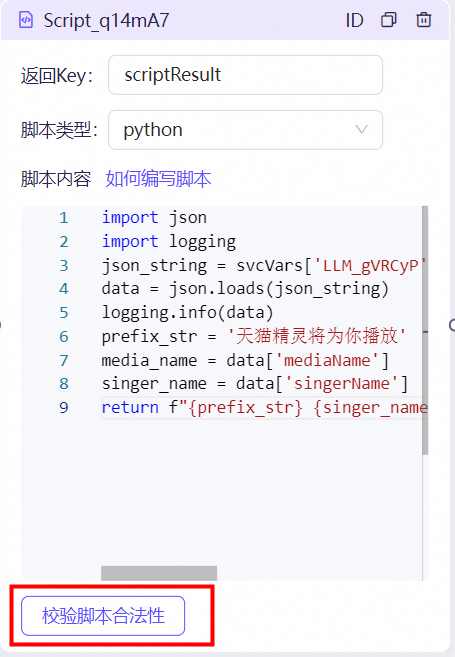
脚本详情:
说明
json_string = svcVars[‘LLM_RiKvop’][‘response’][‘text’] 是获取大模型的结果,因为大模型结果存储结构是svcVars.LLM_RiKvop.response.text,所以要按照上面的写法获取,注意这个LLM_RiKvop为大模型节点的id,使用例子内的示例时,LLM_RiKvop需要替换成自己大模型节点的节点id,这个可以通过右上角的ID复制功能,如下图。 ### 结束节点
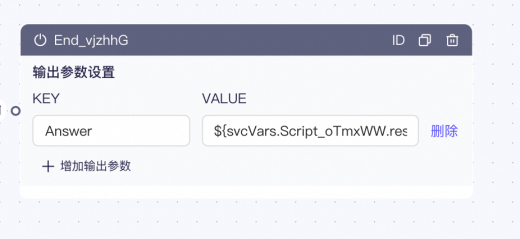
可以定制最终的结果KEY(示例中为Answer),映射的值填写表达式(示例中为${svcVars.Script_oTmxWW.response.scriptResult}),获取的是脚本节点执行的结果。
### 结束节点
可以定制最终的结果KEY(示例中为Answer),映射的值填写表达式(示例中为${svcVars.Script_oTmxWW.response.scriptResult}),获取的是脚本节点执行的结果。
最终结果展示
点击流程 按钮,输入参数值,开始测试。
按钮,输入参数值,开始测试。


import jsonimport loggingjson_string = svcVars['LLM_RiKvop']['response']['text']data = json.loads(json_string)logging.info(data)prefix_str = '天猫精灵将为你播放'media_name = data['mediaName']singer_name = data['singerName']return f"{prefix_str} {singer_name} 的 {media_name},收听完整版请下载天猫精灵APP收听完整版"
反馈
{"Answer": "天猫精灵将为你播放 周杰伦 的 晴天,收听完整版请下载天猫精灵APP收听完整版"}

若有收获,就点个赞吧
0 人点赞
