关系数据库
关系数据库相关的节点。 这里我们给各位用户采用的底层数据库是轻量级的 SQLite 文件数据库。智能查询
参数详解
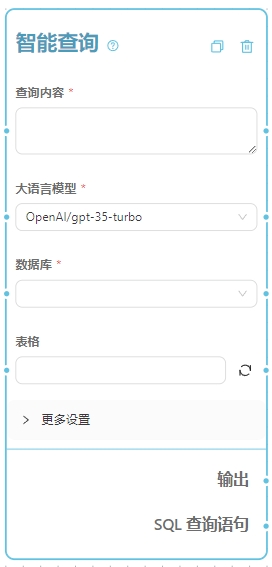
1. 查询内容
自然语言描述的查询内容。如:<font style="color:rgb(31, 35, 40);">查询2023年成绩表中90分以上的学生数量</font>。
支持列表输入
2. 大语言模型
目前内置支持的大语言模型有:- gpt-35-turbo
- gpt-4
- abab5.5-chat
- abab6-chat
- abab6.5s-chat
- glm-3-turbo
- glm-4
- qwen1.5-7b-chat
- qwen1.5-14b-chat
- qwen1.5-32b-chat
- qwen1.5-72b-chat
- qwen1.5-110b-chat
- moonshot-v1-8k
- moonshot-v1-32k
- moonshot-v1-128k
- claude-3-haiku-20240307
- claude-3-sonnet-20240229
- claude-3-opus-20240229
- mixtral-8x7b
- mistral-small
- mistral-medium
- mistral-large
- deepseek-chat
- deepseek-code
3. 数据库
需要查询的数据库。 注意:在使用这个工作流节点之前,请务必在数据集页面中创建一个数据库。4. 表格
您数据库中哪些表格将参与查询。如果不选择则默认为全部表格,建议只选择需要的表格以获得更准确的结果。5. 最大返回数量
查询语句最多返回多少数据量,建议根据实际情况修改该数值,避免查询结果过大时后续大语言模型节点的积分消耗过多。6. 输出类型
6.1 CSV 格式文本
示例:
csv姓名,性别,学号,班级张三,男,2024030115,三年一班马冬梅,女,2024030116,三年一班李四,女,2024030117,三年一班
6.2 Markdown 表格
Markdown 格式的表格,适合在文本呈现节点中直接展示。 示例:
markdown| 姓名 | 性别 | 学号 | 班级 || ------ | ---- | ---------- | -------- || 张三 | 男 | 2024030115 | 三年一班 || 马冬梅 | 女 | 2024030116 | 三年一班 || 李四 | 女 | 2024030117 | 三年一班 |
6.3 列表
以列表形式返回查询结果,适用于需要一条一条数据在后续节点中处理的情况。 当选择列表输出时,您回看到多出一个选项是<font style="color:rgb(31, 35, 40);">包含列名</font>,在默认勾选的情况下返回的数据格式如下:
如果不包含列名时输出的数据格式如下:
json[{"姓名": "张三","性别": "男","学号": "2024030115","班级": "三年一班"},{"姓名": "马冬梅","性别": "女","学号": "2024030116","班级": "三年一班"},{"姓名": "李四","性别": "女","学号": "2024030117","班级": "三年一班"}]
json[["张三", "男", "2024030115", "三年一班"],["马冬梅", "女", "2024030116", "三年一班"],["李四", "女", "2024030117", "三年一班"]]
输出类型
<font style="color:rgb(31, 35, 40);">字符串</font> | <font style="color:rgb(31, 35, 40);">列表</font>
积分消耗
取决于选择的大语言模型消耗的积分量。获取表信息

参数详解
1. 数据库
需要查询的数据库。 注意:在使用这个工作流节点之前,请务必在数据集页面中创建一个数据库。2. 表格
您数据库中哪些表格,如果不选择则默认为全部表格。输出类型
- SQL 输出
- 以 CREATE TABLE 语句的形式返回表格结构信息。
<font style="color:rgb(31, 35, 40);">字符串</font>
- JSON 输出
- 格式形如:
<font style="color:rgb(31, 35, 40);">[{"name": "<表格名>", "columns": [<列1>, ...]}]</font> <font style="color:rgb(31, 35, 40);">Python 字典</font>
- 格式形如:
积分消耗
本节点暂时不消耗积分。运行 SQL
参数详解
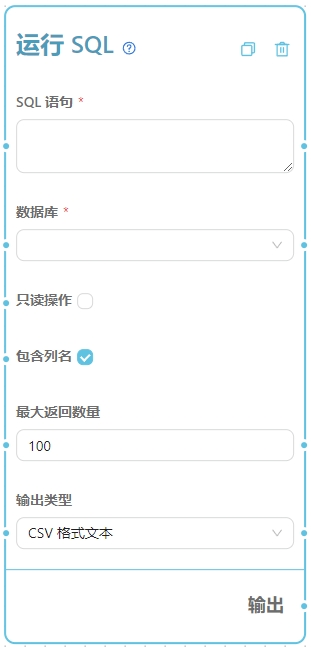
1. SQL 语句
需要运行的 SQL 语句。注意只支持单条 SQL 语句,不支持多条语句。如需运行多条 SQL 语句请使用列表格式输入。注意使用 SQLite 支持的 SQL 语法。
支持列表输入2. 数据库
需要查询的数据库。 注意:在使用这个工作流节点之前,请务必在数据集页面中创建一个数据库。3. 只读操作
如果勾选则只允许执行查询语句,不允许执行修改数据库的语句。即便输入的 SQL 语句是修改数据库的语句,也不会实际执行。4. 最大返回数量
查询语句最多返回多少数据量,建议根据实际情况修改该数值,避免查询结果过大时后续大语言模型节点的积分消耗过多。6. 输出类型
与 智能查询 节点相同。- CSV 格式文本
- Markdown 表格
- 列表
输出类型
<font style="color:rgb(31, 35, 40);">字符串</font> | <font style="color:rgb(31, 35, 40);">列表</font>
积分消耗
每次消耗2积分。
若有收获,就点个赞吧
0 人点赞
