开始之前,您需要具备如下基础背景知识,并理解相关的名词概念,点击可快速获取相关内容。
名词解释#
ModelScope平台是以模型为中心的模型开源社区,与模型的使用相关,您需要先了解如下概念。
| 基础概念 | 定义 | 了解更多 |
|---|---|---|
| 任务 | 任务(Task)指某一领域具体的应用,以用于完成特定场景的任务。例如图像分类、文本生成、语音识别等,您可根据任务的输入、输出找到适合您的应用场景的任务类型,通过任务的筛选来查找您所需的模型。 | 了解更多信息,请参阅任务的介绍 |
| 模型 | 模型(Model)是指一个具体的模型实例,包括模型网络结构和相应参数。ModelScope平台提供丰富的模型信息供用户体验与使用。 | |
| 模型库 | 模型库(Modelhub)是指对模型进行存储、版本管理和相关操作的模型服务,用户上传和共享的模型将存储至ModelScope的模型库中,同时用户也可在Model hub中创建属于自己的模型存储库,并沿用平台提供的模型库管理功能进行模型管理。 | 了解更多信息,请参阅模型库的介绍 |
| 数据集 | 数据集(Dataset)是方便共享及访问的数据集合,可用于算法训练、测试、验证,通常以表格形式出现。按照模态可划分为文本、图像、音频、视频、多模态等。 | 了解更多信息,请参阅数据集的介绍 |
| 数据集库 | 数据集库(Datasethub)用于集中管理数据,支持模型进行训练、预测等,使各类型数据具备易访问、易管理、易共享的特点。 | |
| ModelScope Library | ModelScope Library是ModelScope平台自研的一套Python Library框架,通过调用特定的方法,用户可以只写短短的几行代码,就可以完成模型的推理、训练和评估等任务,也可以在此基础上快速进行二次开发,实现自己的创新想法。 | 了解更多信息,请参阅ModelScope Library的介绍 |
此外,您还需要了解基础的python命令与用法。 如果您完全不懂也没关系,平台将提供简单的命令代码,复制即可使用! 至此,恭喜你,已经具备了初步的概念!你现在可以在平台上探索你感兴趣的模型,若需要查看模型效果,可在模型卡片页面进行在线体验(当前仅部分模型支持在线体验),如果您想更深度地体验模型,需要安装环境进行模型验证与使用。
一、模型探索#
首先访问平台网址https://www.modelscope.cn/models, 您将看见平台上已有的所有公开模型,根据任务筛选或者关键词搜索可查找您感兴趣的模型。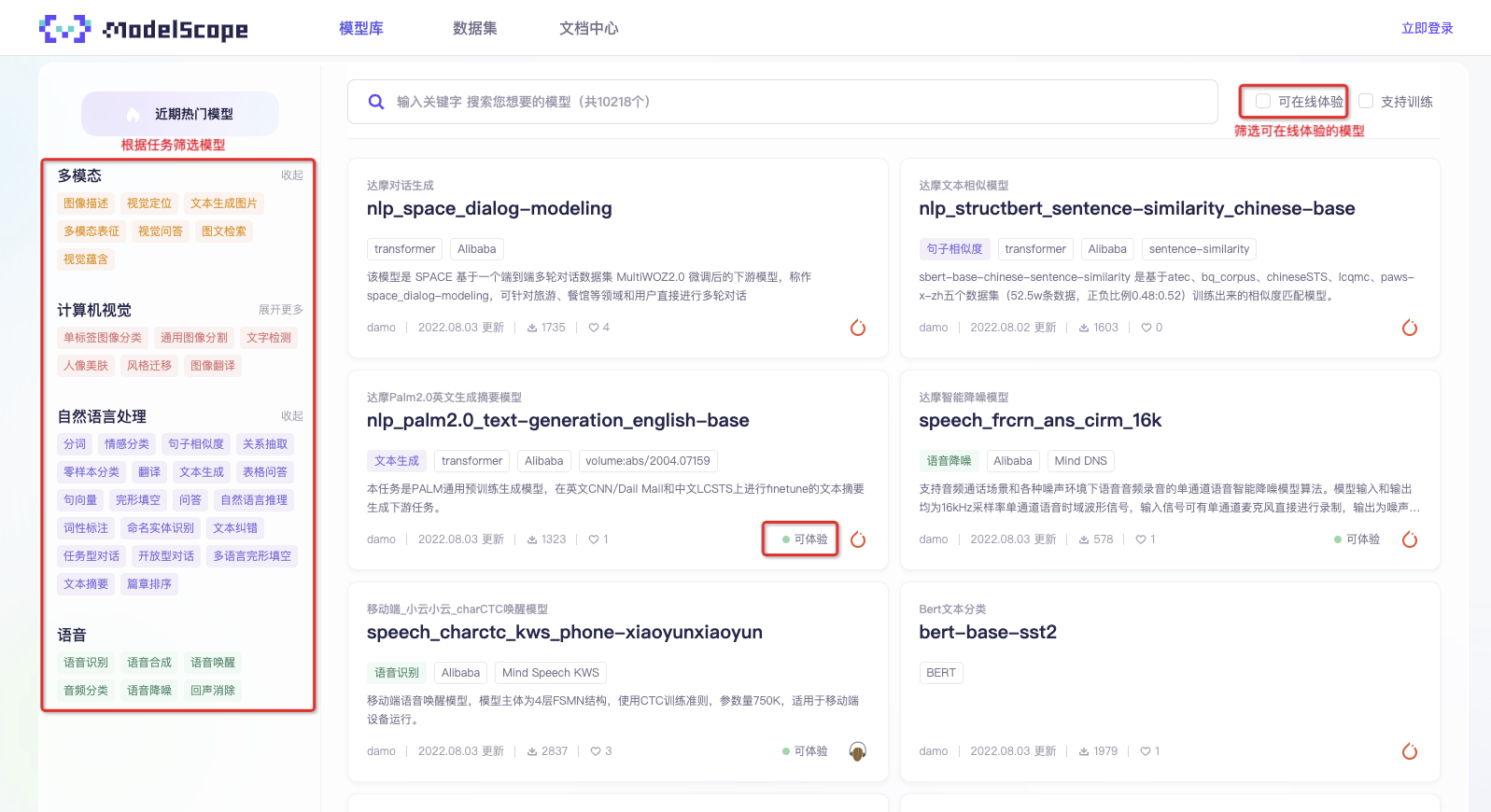
若需要查找可在线体验或者可支持训练调优的模型,可通过搜索框右侧筛选框进行筛选。可在线体验和可支持训练的模型将不断的丰富扩展,敬请期待。
此文以中文分词模型为例,带您探索ModelScope的模型体验使用之旅。
通过筛选“分词”的任务,或者搜索关键词“分词”您可以检索到对应的中文分词模型。在右侧模型卡片上,将展示该模型的基础信息包括中英文名称、任务类型标签和其他模型标签、模型使用的深度学习框架、模型提供者、下载数、点赞数和模型描述等信息,帮助您快速了解模型。

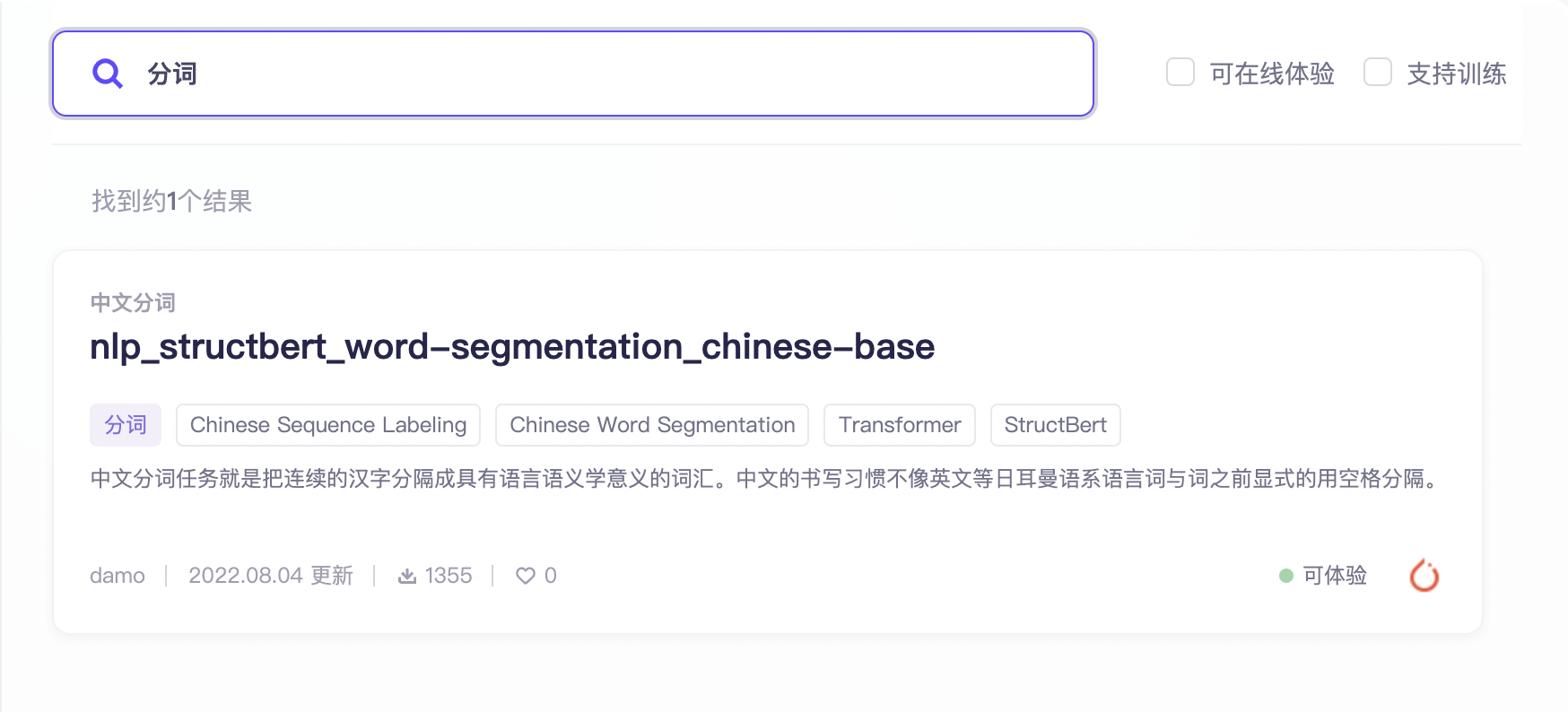
点击模型,进入模型详情页,您可以查看该模型具体的模型介绍。模型提供者将在此处介绍模型具体的应用场景、功能描述、技术方法、模型训练与使用还有效果评估,供您参考。 右侧有“在线体验”功能,您可以通过切换默认示例来查看模型效果,或输入适合该模型的测试信息进行模型的效果测试。

在执行在线体验前,请您仔细阅读并理解相关免责声明,并合法合规使用在线体验的模块功能。
除了模型体验外,还可查看关于该模型具体的模型文件并进行下载。(当前支持通过git、Python SDK方式下载,更多请参阅模型的下载)
若您对模型效果满意,想进一步了解并对该模型进行代码验证,您可点击“快速使用”查看具体的代码示例方法。平台提供了两种方式的模型下载:
1)通过ModelScope Library安装下载
2)通过git拉取仓库。
这两种方式可以在本地运行模型。但需要先安装ModelScope Library才能运行代码,具体参见第二步【环境准备】-【本地开发环境安装】。 同时,我们也提供了在线Notebook,为您准备了模型所需的运行环境,无需用户自行安装依赖环境,使用更加流畅,推荐使用此种方式进行模型的深度体验!具体参见第二步【环境安装】-【在Notebook中开发】。

二、环境准备#
1、本地开发环境安装#
如果您需要在本地运行模型,需要进行相应的环境安装准备,包括:
- 安装python环境。支持python3,不支持python2,建议3.7版本及以上。我们推荐您使用Anaconda进行安装。
- 安装深度学习框架。ModelScope Library目前支持Tensorflow,Pytorch两大深度学习框架进行模型训练、推理。您可根据模型所需的框架选择适合的框架进行安装。
- 安装ModelScope Library。我们提供两种安装方式,您可选择适合的方式进行安装。
- pip安装。ModelScope提供了根据不同领域的安装包,您可根据对应的模型选择所需的安装包。
- 使用源码安装。
更完整的安装信息参考:环境安装指南。
2、在Notebook中开发#
若您觉得本地安装较为复杂, ModelScope 平台也提供在线的运行环境,您可直接在Notebook中运行,Notebook中提供官方镜像无需自主进行环境安装,更加方便快捷,推荐大家使用! 注意:该功能需要您登录后使用,新用户注册ModelScope账号并完成阿里云账号绑定后即可获得免费算力资源,详情请参阅免费额度说明 。

成功登录后,您可直接在模型详情页中,点击“在Notebook中打开”,并选择需要运行的实例环境(CPU环境或GPU环境)。系统将预装ModelScope官方镜像,点击“启动”按钮即可在Notebook中使用。此时实例启动需要一些时间,请耐心等待,当环境启动后点击“查看Notebook”,则跳转notebook页面,即可在新环境中使用。

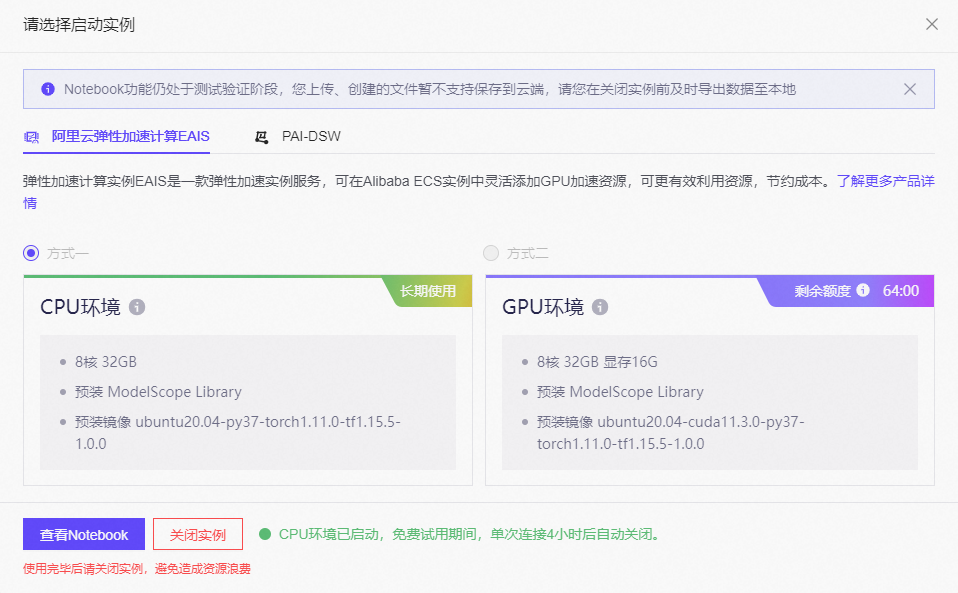
系统将新开一个页面,点击Python3,进入为您搭建好的Python3开发环境。

复制模型详情页面里快速使用的代码到该python环节中,点击运行按钮,即可跑出推理结果。(一些模型的使用方法,可参看具体的模型卡片的README信息中的代码要求)

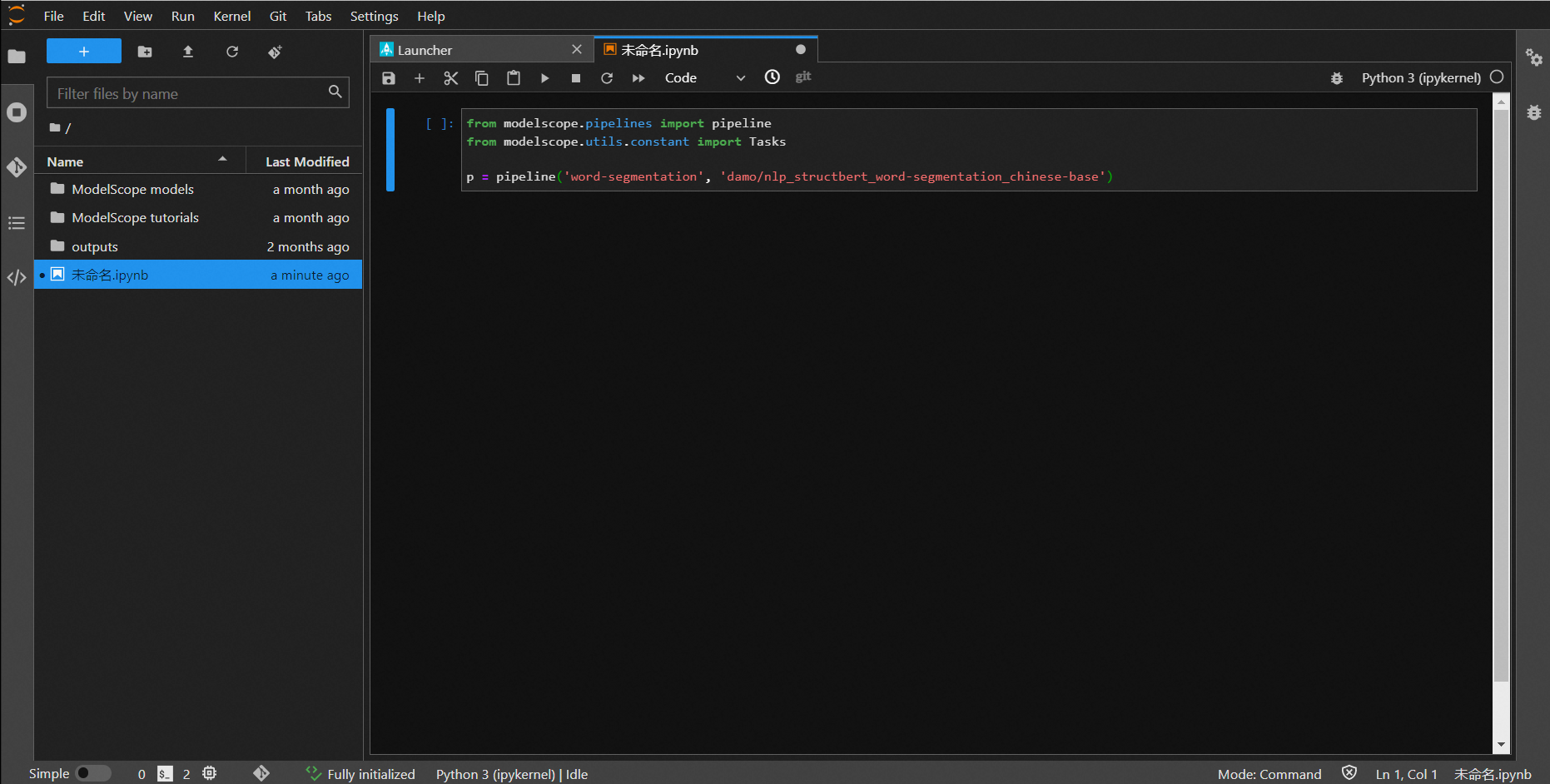
执行命令后,系统将进行模型的下载、推理等一系列操作日志,推理完毕后输入测试的内容即可得到输出结果。
您也可使用该环节实现您的代码编程。关于Notebook功能,更多详情参阅:Notebook功能概述 。
三、2分钟跑通模型推理#
若您准备好本地环境或者已经打开一个Notebook的预装环境实例,则根据下述代码可对该模型进行推理。 使用modelscope pipeline接口只需要两步,同样以上述中文分词模型(damo/nlp_structbert_word-segmentation_chinese-base)为例简单说明:
- 首先根据task实例化一个pipeline对象
from modelscope.pipelines import pipelineword_segmentation = pipeline('word-segmentation',model='damo/nlp_structbert_word-segmentation_chinese-base')
- 输入数据,拿到结果
input_str = '今天天气不错,适合出去游玩'print(word_segmentation(input_str)){'output': '今天 天气 不错 , 适合 出去 游玩'}
四、模型的训练与评估#
若您想更进一步使用自己的数据集进行模型训练,ModelScope提供了不同模态、场景下丰富的预训练模型,简单易用的调用接口,统一的配置文件设计,使得用户可以仅仅使用十几行python代码,就可以拉起一个finetune任务。 下面以一个简单的文本分类任务为例,演示如何通过十几行代码,就可以端到端拉起一个finetune任务。整体流程包含一下步骤:
- 载入数据集
- 数据预处理
- 训练
- 评估
1、载入数据集#
ModelScope提供了标准的MsDataset接口供用户进行基于ModelScope生态的数据源加载。下面以加载NLP领域的afqmc(Ant Financial Question Matching Corpus)数据集为例进行演示
from modelscope.msdatasets import MsDataset# 载入训练数据train_dataset = MsDataset.load('afqmc_small', split='train')# 载入评估数据eval_dataset = MsDataset.load('afqmc_small', split='validation')
数据集的使用,具体参看数据集的介绍。
2、数据预处理#
在ModelScope中,数据预处理与模型强相关,因此,在指定模型以后,ModelScope框架会自动从对应的modelcard中读取配置文件中的preprocessor关键字,自动完成预处理的实例化。
# 指定文本分类模型model_id = 'damo/nlp_structbert_sentence-similarity_chinese-tiny'
配置文件的相关字段:
..."preprocessor":{"type": "sen-cls-tokenizer",},...
当然,对于进阶的使用者,配置文件也支持用户自定义并从任意本地路径读取,具体参考文档:Configuration详解
3、模型的训练#
我们支持单卡训练和分布式训练,请根据您的机器规格从下列方式中选择一种即可。如果您是新手,推荐您优先选择单卡的方式。
单卡#
首先,配置训练所需参数:
from modelscope.trainers import build_trainer# 指定工作目录tmp_dir = "/tmp"# 配置参数kwargs = dict(model=model_id,train_dataset=train_dataset,eval_dataset=eval_dataset,work_dir=tmp_dir)
其次,根据参数实例化trainer对象
trainer = build_trainer(default_args=kwargs)
最后,调用train接口进行训练
trainer.train()
恭喜,你完成了一次模型训练!😀
分布式#
首先,准备训练脚本,并将下列代码保存到例如./train.py脚本中:
import argparseimport osfrom modelscope.trainers import build_trainerparser = argparse.ArgumentParser(description='Train a model')parser.add_argument('--local_rank', type=int, default=0)args = parser.parse_args()if 'LOCAL_RANK' not in os.environ:os.environ['LOCAL_RANK'] = str(args.local_rank)# 指定工作目录tmp_dir = "/tmp"# 配置参数kwargs = dict(model=model_id,train_dataset=train_dataset,eval_dataset=eval_dataset,work_dir=tmp_dir,launcher='pytorch' # 分布式启动方式)# 实例化trainer对象trainer = build_trainer(default_args=kwargs)# 调用train接口进行训练trainer.train()
然后启动分布式训练:
PyTorch:
单机多卡:
$ python -m torch.distributed.launch --nproc_per_node=${NUMBER_GPUS} --master_port=${MASTER_PORT} ./train.py
- nproc_per_node:当前主机创建的进程数(使用的GPU个数), 例如—nproc_per_node=8。
- master_port:主节点的端口号,例如—master_port=29527。
多机多卡:
以两个节点为例。
节点1:
python -m torch.distributed.launch --nproc_per_node=${NUMBER_GPUS} --nnodes=2 --node_rank=0 --master_addr=${YOUR_MASTER_IP_ADDRESS} --master_port=${MASTER_PORT} ./train.py
节点2:
python -m torch.distributed.launch --nproc_per_node=${NUMBER_GPUS} --nnodes=2 --node_rank=1 --master_addr=${YOUR_MASTER_IP_ADDRESS} --master_port=${MASTER_PORT} ./train.py
- nproc_per_node:当前主机创建的进程数(使用的GPU个数), 例如—nproc_per_node=8。
- nnodes:节点的个数。
- node_rank:当前节点的索引值。
- master_addr:主节点的ip地址,例如—master_addr=104.171.200.62。
- master_port:主节点的端口号,例如—master_port=29527。
恭喜,你完成了一次模型分布式训练!😀
4、模型的评估#
训练完成以后,配置评估数据集,直接调用trainer对象的evaluate函数,即可完成模型的评估,
# 直接调用trainer.evaluate,可以传入train阶段生成的ckpt# 也可以不传入参数,直接验证modelmetrics = trainer.evaluate(checkpoint_path=None)print(metrics)
modelscope也支持在训练时同步进行交叉验证,需要配置config文件中的 train.hooks的 EvaluationHook,具体配置如下:
{..."train": {..."hooks": [..., {"type": "EvaluationHook","by_epoch": false,"interval": 100}]},}
用户可以根据自己实际情况进行调整配置文件,也可自行注册相应hook,并通过type字段注册在配置文件中进行调用。关于hook的详细说明请参考文档:回调函数机制详解。
使用教程#
恭喜你!至此你已经成功学习完一个模型的完整使用。若你对平台功能想要更多地了解可具体参考对应的功能模块,同时平台提供了相应的教程来帮助您更好地理解模型的应用!我们也欢迎你加入到我们的社区贡献你的模型与想法,共同构建绿色开源社区! 详细教程请参阅:(更多丰富教程与课程内容开发中,敬请期待!)
- 模型的推理
- 数据的预处理
- 模型的训练

若有收获,就点个赞吧
0 人点赞
