模型中心
更新时间:2023-10-23 16:49:23概念解释
更新时间:2024-03-16 17:14:36 模型中心模块核心概念解释如下表所示:| 模块 | 概念 | 解释 |
|---|---|---|
| 模块 | 概念 | 解释 |
|---|---|---|
| 训练数据 | 训练集 | 调优所用的数据集,格式一般为Prompt+Completion的文本数据,可通过Excel进行编辑和上传,最小训练数据条数为20,最大训练数据条数为10000,一条训练数据Prompt+Completion总字符数不高于8000,高于8000的字符数系统将自动截断。 |
| 评测集 | 评测所用的数据集,格式一般为Prompt+Completion的文本数据,评测系统将自动基于Prompt数据预测模型结果,可通过参考评测集中的Completion数据对模型预测结果进行标识,判断模型效果,最小评测数据条数为1,最大条数为5000,Prompt总字符数不高于8000,以实际需要为准。 | |
| 模型调优 | 预置模型 | 预置模型为未经过任何训练的原始模型,您可以通过选择基础模型进行训练从而得到自创模型,不同的基础模型的参数和能力不同,我们将持续推出不同能力方向的模型。 |
| 自定义模型 | 自订阅模型是基于您训练过的模型进行再次训练,从而调优模型效果,请注意,由于大模型的训练原理,多次训练模型时,后序训练易丢失前序训练已习得的能力,建议后序训练数据需要采样或保持前序训练数据。 | |
| 循环次数 | 循环次数代表模型训练过程中模型学习数据集的次数,可理解为看几遍数据,一般建议的范围是1-3遍即可,可依据需求进行调整 。 | |
| 批次大小 | 批次大小代表模型训练过程中,模型更新模型参数的数据步长,可理解为模型每看多少数据即更新一次模型参数,一般建议的批次大小为16/32,表示模型每看16或32条数据即更新一次参数。 | |
| Learning Rate Multiplier | Learning Rate Multiplier-学习率代表每次更新数据的增量参数权重,学习率数值越大参数变化越大,对模型影响越大,一般范围为:2-5e至2-8e。 | |
| Prompt损失权重 | Prompt损失权重的配置将影响模型学习样本及预测目标的遮盖范围,损失权重的设置范围是0.1-1.0,参数配置1.0表示完整学习样本(Prompt和Completion均不遮挡),参数设置为0.5表示从Completion侧开始向Prompt进行遮挡50%样本长度,参数越小,模型学习越少,收敛越快,但泛化性会变差,训练容易过拟合,参数越大,模型学习越完整,同时收敛越慢,训练成本越高。 | |
| Training Loss | Trianing Loss 代表针对训练数据学习的拟合程度,曲线一般呈现下降趋势,Loss越小,表示训练数据拟合程度越高,过小的Loss易导致数据过拟合,需要根据实际训练过程进行判断。 | |
| Validation Loss | Validation Loss代表针对验证集学习的拟合程度,曲线一般呈现先下降后上升趋势,Loss越小,表示验证数据拟合程度越高,优秀的模型效果往往出现Validation Loss的最小值节点,此时拟合程度最佳,训练效果最好。 | |
| Validation Token Accuracy | Validation Token Acc代表针对验证集学习的准确程度,曲线一般呈现上升趋势,训练过拟合后会呈现下降趋势,优秀的模型效果往往出现在Validation Token Acc的最大值节点,此时预测准确率最高,训练效果最好。 | |
| 模型部署 | 针对已经微调训练好的模型,如需评测此模型效果,或通过应用调用此模型,则需将模型部署为线上服务,平台为微调模型提供独占实例/按月计费的购买方式,注意,当部署模型成功后,此模型独占的实例服务即开始收费,具体收费模式见产品价格详情 部署成功的模型将显示为运行中状态,模型部署过程一般消耗十几分钟至半个小时不等。 |
|
| 超参配置 | 学习率调整策略 | 选择不同的学习率策略,动态地改变模型在训练过程中更新权重时所采用的学习率大小。 |
| 验证步数 | 训练阶段针模型的验证间隔步长,用于阶段性评估模型训练准确率、训练损失推荐范围:[1,2147483647]。 | |
| 序列长度 | 训练数据的序列长度,单个训练数据样本的最大长度,超出配置长度将自动截断。推荐范围:[500,2048] | |
| 学习率预热比例 | warmup占用总的训练steps的比例。推荐范围:(0,1) | |
| 权重衰减 | L2正则化,让权重衰减到更小的值,在一定程度上减少模型过拟合的问题。推荐范围:(0,0.2) | |
| 梯度存储 | 是否开启gradient checkpointing, 默认为True. 该参数可以用于节约显存, 虽然这会略微降低训练速度. 该参数在max_length较大, batch_size较大时作用显著。 |
模型体验介绍
更新时间:2024-04-17 14:52:22 本篇内容介绍模型体验和模型调试。模型体验
支持选择多个模型同时体验,快速对比不同模型的效果,最多同时选择3个模型,支持差异化模型配置及重复模型选择。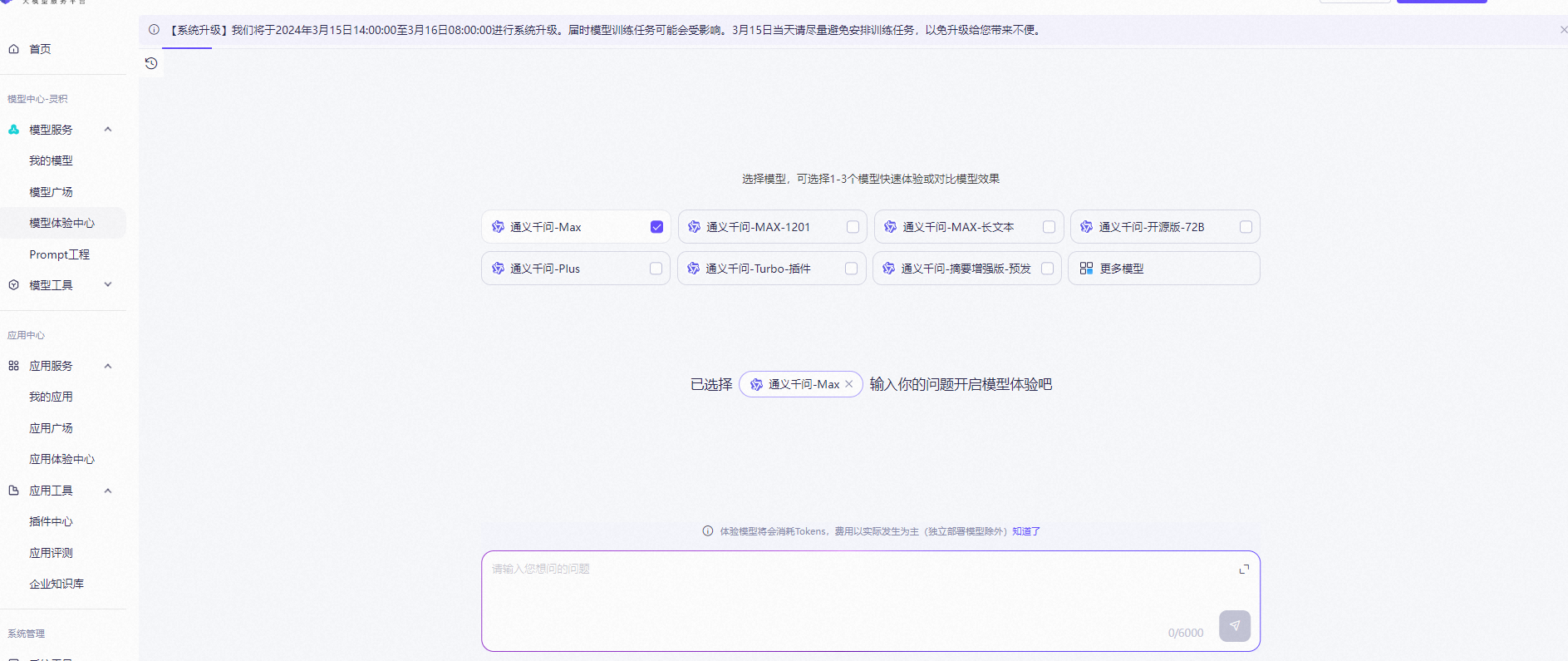
说明
- 体验模型将会消耗Tokens,费用以实际发生为主(独立部署模型除外)。
- 各大模型收费标准请查看模型广场介绍,部分模型限时免费调用。
示例内容:
问法:阿里云百炼大模型是什么 下方图片展示选择的不同大模型回复的内容。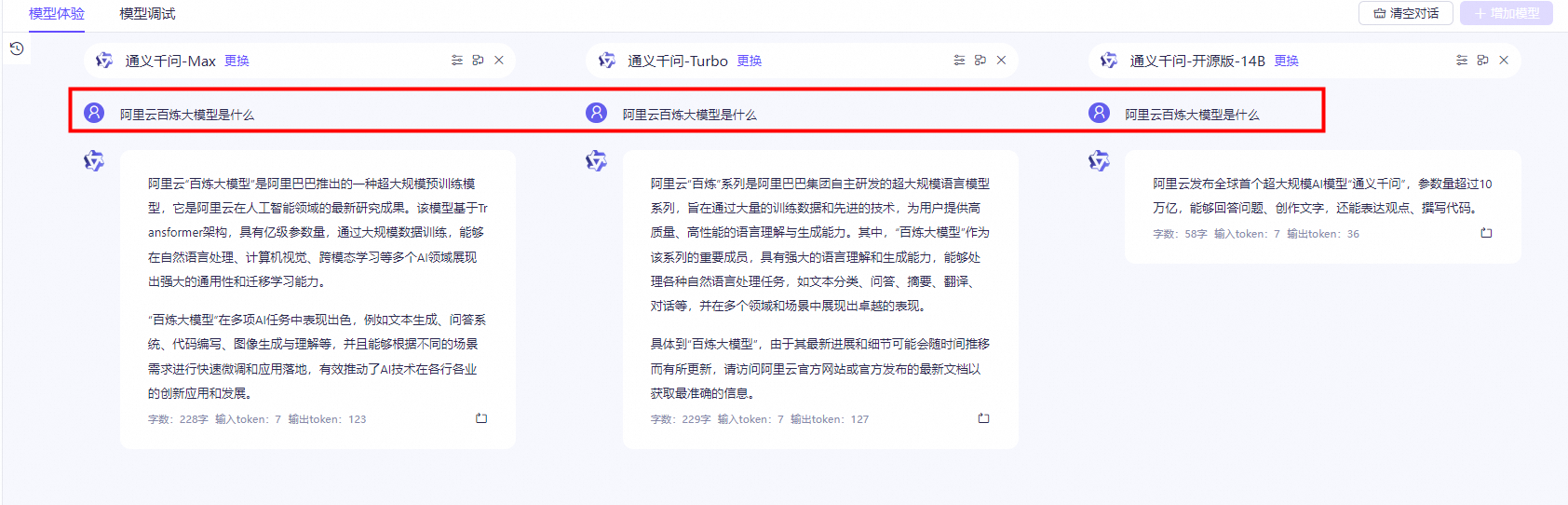
模型调试
支持调试模式,透明化查看模型输出结果,支持Prompt模式及Message模式,便于开发者调试模型效果。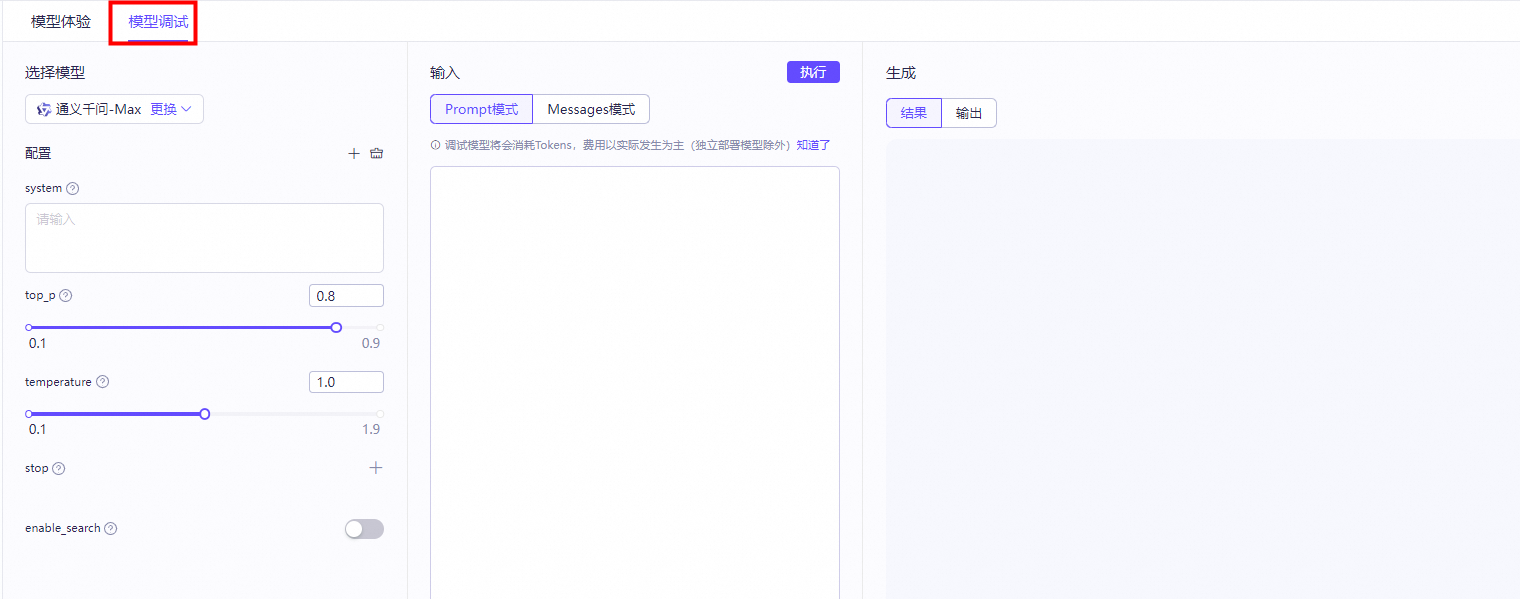
说明
system:系统人设,例如“你是一个AI助手”。 top_p:控制核采样方法的概率阈值,取值越大,生成的随机性越高。 temperature:控制生成随机性和多样性,范围(0,2)。建议该参数和top_p只设置1个。 stop:用于控制生成时遇到某些内容则停止。您可以传入多个字符串。 enable_search:是否参考搜索的结果,默认为false。示例内容:
使大模型检测Prompt中是否存在错别字,并进行纠正。详细内容参数值参考下方图片。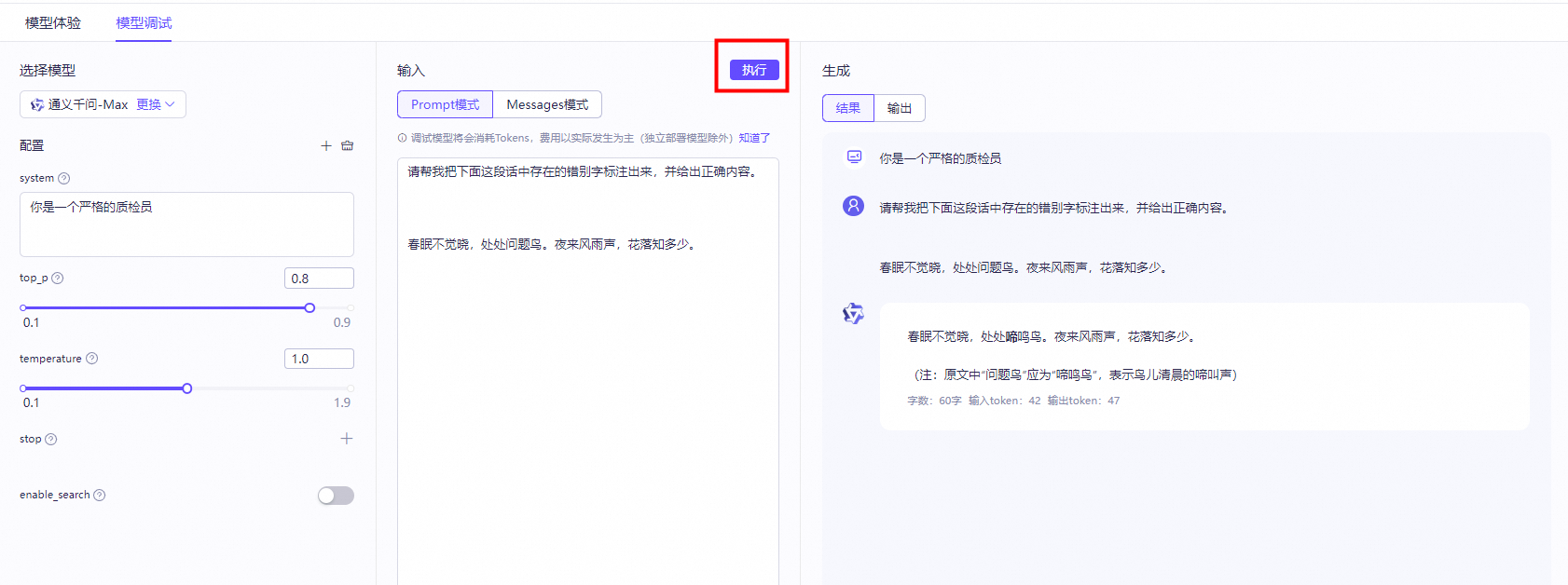
历史对话一键继承
新增对比模型时,一键继承已有模型历史对话,保持History消息不变的情况下,查看后续对话效果对比。

若有收获,就点个赞吧
0 人点赞
