用Python在工作中“偷懒”
发布于 2019-11-14 00:16:43 8430 举报 文章被收录于专栏:数据森麟作者:吴小鹏
来源:数据札记馆
“偷懒还能干完活,才是本事。”
帅张发了一篇《工作要学会偷懒》,深感赞同。
有些事情既然定期都要处理,就没有更好的处理方式?能自动化么? 工作要学会偷懒,尤其对于一些大量重复的工作,第一感觉就要想到如何偷懒。 怎么偷懒呢? 做一点简单的编程工作就可以了。 我总结了一些在工作中非常常见的例子,将源码整理好供参考。 这类工作大部分是重复性工作,但占据了你比较多的时间,有时候用蛮力做的事情,可以有更省时省力的办法。 作为一名优秀的社会主义接班人,肯定都会有将工作任务自动化的意识,于是我去了解了一下身边不同岗位(HR、产品、运营、市场、数据分析师等)每天需要面对的重复性劳动(肯定会有不全,各位大佬不要喷我~) 今天我来分享一下在工作是实际会遇到的情况,其实我们不用吭哧吭哧地埋头干表格,也不用拼死平活地理数据,更不用机械式地点击各个启动和确认按钮,掌握一些自动化程序会让你的工作更加高效。那么如何将这些统统实现呢?
我将这些分为以下几类,大家可以自行评估,各取所需: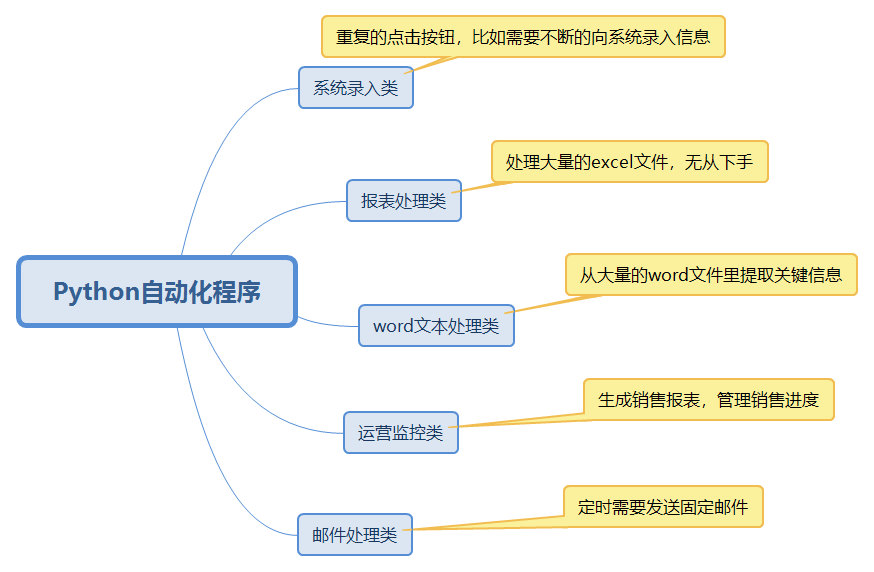
系统录入自动化
由于你经常需要不断的将一些信息录入系统,每一次录入的过程中你可能需要不断的点击一些按钮,面对这种情况,完全可以写一个自动脚本,每次代替你来执行这些点击的行为。
代码语言:javascript
复制
这里写了一个自动登录邮箱的脚本,可以实现文本输入和网页点击:
pip install splinter
代码语言:javascript
复制
同理可以写一个简单的游戏挂机脚本,游戏挂机脚本,无非就是自动移动鼠标,自动点击,进行重复操作,所以,第一步就是如何控制鼠标。
#coding=utf-8import timefrom splinter import Browserdef splinter(url):browser = Browser()#login 126 email websizebrowser.visit(url)#wait web element loadingtime.sleep(5)#fill in account and passwordbrowser.find_by_id('idInput').fill('xxxxxx')browser.find_by_id('pwdInput').fill('xxxxx')#click the button of loginbrowser.find_by_id('loginBtn').click()time.sleep(8)#close the window of browerbrowser.quit()if __name__ == '__main__':websize = 'https://mail.163.com/'splinter(websize)
代码语言:javascript
复制
值得注意的是,一定要在管理员权限下的cmd中运行,否则点击无效。 这个时候,你已经可以写个循环,不停地点击屏幕上不同的几个点,最基础的挂机脚本就实现了。 不是在犯罪的道路上越走越远,就是在成长的道路上越走越远 更高级的游戏外挂:
import win32apiimport timedef move_click(x, y, t=0): # 移动鼠标并点击左键win32api.SetCursorPos((x, y)) # 设置鼠标位置(x, y)win32api.mouse_event(win32con.MOUSEEVENTF_LEFTDOWN |win32con.MOUSEEVENTF_LEFTUP, x, y, 0, 0) # 点击鼠标左键if t == 0:time.sleep(random.random()*2+1) # sleep一下else:time.sleep(t)return 0# 测试move_click(30, 30)def resolution(): # 获取屏幕分辨率return win32api.GetSystemMetrics(0), win32api.GetSystemMetrics(1)
https://github.com/JamesRaynor67/jump
Excel自动化处理
Excel合并
在实际应用中可能会有不同月份的数据或者不同周的报告等等的Excel数据,都是单个独立的文件,如果想要整体使用的话就需要合并一下,那么如何利用python把指定目录下的所有Excel数据合并成一个文件呢?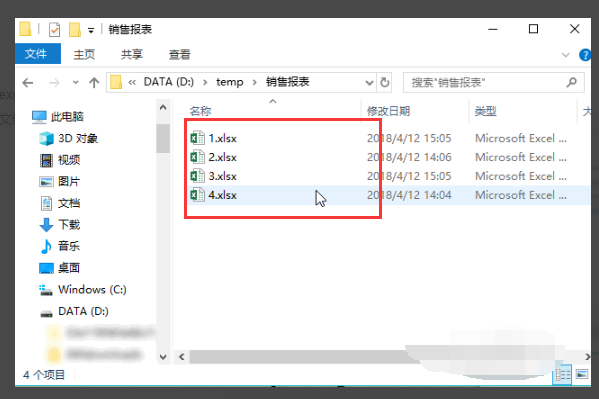
代码语言:javascript
复制
或者直接用concat+一个循环来实现:
# -*- coding: utf-8 -*-#将多个Excel文件合并成一个import xlrdimport xlsxwriter#获取excel中所有的sheet表def getsheet(fh):return fh.sheets()#获取sheet表的行数def getnrows(fh,sheet):table=fh.sheets()[sheet]return table.nrows#读取文件内容并返回行内容def getFilect(file,shnum):fh=open_xls(file)table=fh.sheets()[shnum]num=table.nrowsfor row in range(num):rdata=table.row_values(row)datavalue.append(rdata)return datavalue
代码语言:javascript
复制
for i in var_list:df_0 = data[['var_1','var_2','var_3','var_4',i]][data[i]=='信息']df_0['month'] = date_replace(i)df_0 = df_0[['var_1','var_2','var_3','var_4','var_5']]li.append(df_0)writer = pd.ExcelWriter(r'C:\Users\mapping.xlsx')df = pd.concat(li)df.to_excel(writer,'Sheet1',index=False,header = None)df
Excel中添加数据图表
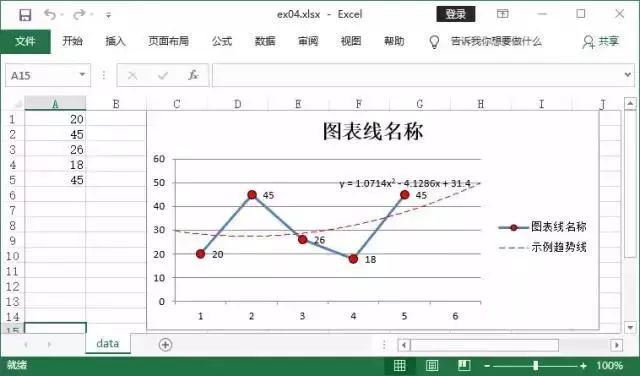
整理好excel文件后下一步需要做的是处理文件里的数据,根据数据来生成一些自己需要的图表:代码语言:javascript
复制
实现效果:
import xlsxwriter#设置一个例子data = [20, 45, 26, 18, 45]#创建表格workbook = xlsxwriter.Workbook("temp.xlsx")worksheet = workbook.add_worksheet("data")#添加数据worksheet.write_column('A1', data)#创建图表chart = workbook.add_chart({'type': 'line'})#图表添加数据chart.add_series({'values': '=data!$A1:$A6','name': '图表名称','marker': {'type': 'circle','size': 8,'border': {'color': 'black'},'fill': {'color': 'red'}} ,'data_labels': {'values': True},'trendline': {'type': 'polynomial','order': 2,'name': '趋势线','forward': 0.5,'backward': 0.5,'display_equation':True,'line': {'color': 'red', 'width':1, 'dash_type': 'long_dash'}}})worksheet.insert_chart('c1', chart)workbook.close()
word关键信息提取
假设你收到1万份简历,你想先根据学校做一些筛选,这时候利用python将大量的简历进行信息汇总,只提取关键信息用excel查看起来更加方便。
代码语言:javascript
复制
后台回复简历获取完整代码,参考资料:
import redef get_field_value(text):value_list = []m = re.findall(r"姓 名(.*?)性 别", table)value_list.append(m)m = re.findall(r"性 别(.*?)学 历", table)value_list.append(m)m = re.findall(r"民 族(.*?)健康状况", table)value_list.append(m)'''此处省略其他字段匹配'''return value_list
https://blog.csdn.net/geoker/article/details/80149463
自动化运营监控
在平时的工作中,一定会有对运营情况的监控,假设你管理一家店铺,那么一些关键指标肯定是你需要每天查看到的,比如店铺访问数,商品浏览数,下单数等等,这个时候不用每天重复地去统计这些数据,这需要写一个自动化程序,每天将数据保存在固定的文件夹下就可以实现报表的实时监控。
代码语言:javascript
复制
如果你的数据来源是线上文件(存在数据库) 那可以直接利用python链接数据库进行一些列的操作 然后导出你所需要的结果
from impala.dbapi import connectfrom impala.util import as_pandasimport datetimeconn = connect(host='host',port=21050,auth_mechanism='PLAIN',user='user',password='password')#host:数据库域名#user:数据库用户名#password:数据库密码df_data = pd.read_excel('temp.xlsx')rows =[]for index, row in df_data.iterrows():rows.append('('+'"'+str(row['case_id']).replace('nan','null')+'"'+','+'"'+str(row['birth_date'])+'"'+')'+',')a= '''INSERT into table(case_id, birth_date)values '''for i in rows:a += ia = a[:-1]cursor1 = conn.cursor()cursor1.execute(a)cursor1.close()conn.close()print('成功导入数据至数据库...')del adel rows
代码语言:javascript
复制
python连接数据库: https://blog.csdn.net/weixin_42213622/article/details/86523400
import sql #sql是封装的sql文件sql_end = sql.sql_endcursor1 = conn.cursor()for i in sql_end.split(';'):print(i)cursor1.execute(i)cursor1.close()conn.close()print('程序运行结束,请执行下一步。')
自动发送邮件
使用Python实现自动化邮件发送,可以让你摆脱繁琐的重复性业务,节省非常多的时间。 数据分析师经常会遇到一些取数需求,有些数据需求是每天都需要的,有些数据需求是每周一次的。对于这些周期性的数据需求,每次都重复性地手动导出这些数据,并回传给需求方,是很繁琐且浪费时间的。所以完全可以设置自动邮件来解决。“Talk is cheap, show you the code”
常见的邮件肯定有三部分: 1、正文 2、图片 3、附件 OK 导入我们需要用到的包代码语言:javascript
复制
在邮件中插入正文:
from email.mime.text import MIMETextfrom email.mime.multipart import MIMEMultipartfrom email.mime.image import MIMEImageimport smtplibmsg = MIMEMultipart()
代码语言:javascript
复制
如果你需要插入图片,利用同样的方法,在邮件中插入图片:
##在邮件中插入文本信息df_text='''<html><body><p> Hi all ,</p><p> 这是一个测试邮件,详情请参考附件 </p><p> 情况如下图: </p></body></html>'''msgtext = MIMEText(df_text, 'html', 'utf-8')msg.attach(msgtext)
代码语言:javascript
复制
在邮件中插入附件:
##在邮件中插入图片信息image = open('temp.jpg','rb')msgimage = MIMEImage(image.read())msg.attach(msgimage)
代码语言:javascript
复制
剩下的就是设置一些邮件参数来发送邮件:
##在邮件添加附件msgfile = MIMEText(open('temp.xlsx', 'rb').read(), 'base64', 'utf-8')msgfile["Content-Disposition"] = 'attachment; filename="temp.xlsx"'msg.attach(msgfile)
代码语言:javascript
复制
发送邮件:
#设置邮件信息常量email_host= '' # 服务器地址sender = '' # 发件人password ='' # 密码,如果是授权码就填授权码receiver = '' # 收件人
代码语言:javascript
复制
然后将你的任务设置定时执行就可以轻松实现啦
try:smtp = smtplib.SMTP(host=email_host)smtp.connect(email_host)smtp.starttls()smtp.login(sender, password)smtp.sendmail(sender, receiver.split(',') , msg.as_string())smtp.quit()print('发送成功')except Exception:print('发送失败')
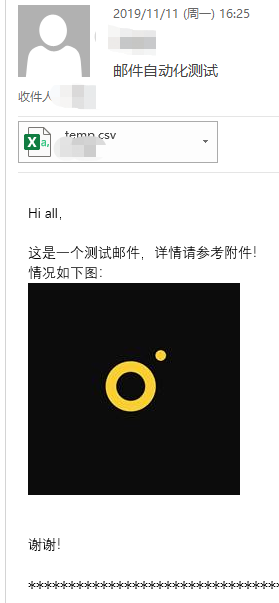
实现效果:
留言打卡第二季 DAY 50
今日的留言话题是聊聊你在工作或者学习中一些“偷懒”的技巧,关于留言打卡的规则可以参考数据森麟公众号留言打卡第二季开启!,请按照昵称+天数(请以自己实际打卡的天数为准,如day1 or day2 or day3)+ 留言内容(不少于15字)的方式留言,超过50天的朋友可以坐等奖品了,不够的后面还会有几次机会哈本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。

若有收获,就点个赞吧
0 人点赞
