文件处理
文件处理节点类别。用于处理文件读取相关的任务。读取文件
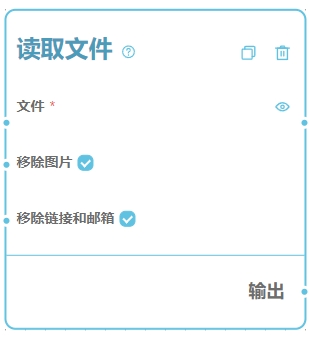
支持的文件类型
<font style="color:rgb(31, 35, 40);">.docx</font>- 读取Word文档为Markdown格式
<font style="color:rgb(31, 35, 40);">.pdf</font>- 读取PDF文档的文字内容
- 多页内容会被合并为一整段
- 暂无OCR识别文字的功能
<font style="color:rgb(31, 35, 40);">.pptx</font>- 读取PPT文档的文字内容
- 多页内容会被合并为一整段
<font style="color:rgb(31, 35, 40);">.xlsx</font>- 读取Excel表格并输出为CSV格式的字符串
- 其它格式 - 读取文件内容的原始文本输出为字符串
输出类型
<font style="color:rgb(31, 35, 40);">字符串</font>
积分消耗
1积分/次上传文件

输出类型
<font style="color:rgb(31, 35, 40);">字符串</font>
积分消耗
0 积分/次多模态处理
多媒体处理节点类别。用于处理图片、音频、视频等多媒体信息。语音识别
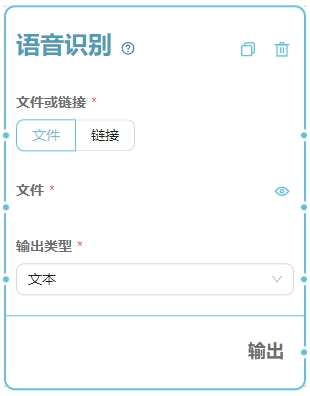
参数详解
1. 文件或链接
- 文件 - 通过在使用界面上传音频文件。
- 链接 - 输入一个音频文件的链接地址,可用于和其他节点连线结合。
2. 文件
通过在使用界面上传音频文件。3. 链接
支持列表输入 输入一个音频文件的链接地址,可用于和其他节点连线结合。4. 输出类型
- 文本 - 将识别结果合并为一个完整的文本字符串。
- 列表 - 将识别结果的每句话分别输出为一个字符串,以列表形式返回。 - 具体是如何分割的,取决于语音识别服务的结果。
- SRT字幕 - 输出位SRT字幕格式的文本字符串。
输出类型
<font style="color:rgb(31, 35, 40);">字符串</font> | <font style="color:rgb(31, 35, 40);">列表</font>
积分消耗
以音频时长计算,每分钟消耗约3.5积分。即1小时的音频消耗210积分。GPT-Vision
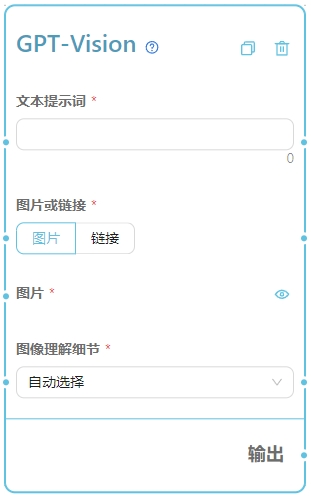
参数详解
1. 文本提示词
支持列表输入 指示 AI 语言模型生成内容的文本提示词。 根据官方的提示,带视觉的 GPT 模型最擅长回答关于图像中存在什么的一般问题。虽然它确实理解图像中对象之间的关系,它还没有被优化来回答关于图像中某些对象位置的详细问题。例如,你可以问它一辆车是什么颜色的,或者根据你冰箱里的东西,晚餐的一些想法可能是什么,但是如果你给它看一个房间的图像,问它椅子在哪里,它可能不会正确回答这个问题。2. 图片或链接
- 图片 - 通过在使用界面上传图片。
- 链接 - 输入一个图片的链接地址,可用于和其他节点连线结合。
3. 图片
通过在使用界面上传图片文件。4. 链接
支持列表输入 输入一个图片文件的链接地址,可用于和其他节点连线结合。5. 图像理解细节
- 自动
- 该设置将查看图像输入大小并决定是否应该使用
<font style="color:rgb(31, 35, 40);">低分辨率图像理解</font>设置或<font style="color:rgb(31, 35, 40);">高分辨率图像理解</font>设置。 - 低分辨率图像理解 - 将禁用”高分辨率”模式。 - 模型将接收低分辨率512px x 512px版本的图像,允许API返回更快的响应,并为不需要高细节的用例消耗更少的积分。
- 高分辨率图像理解 - 将启用”高分辨率”模式。 - 该模式首先允许模型看到低分辨率图像,然后根据输入图像大小将输入图像的详细作物创建为512px正方形。该模式下积分消耗比低分辨率模式高。
输出类型
<font style="color:rgb(31, 35, 40);">字符串</font> | <font style="color:rgb(31, 35, 40);">列表</font>
积分消耗
与 gpt-4o 模型的积分消耗相同,只不过图像输入也会根据实际情况算作输入。 一张图片加两句话提问,并输出两三句话的回答,大约消耗 15 积分。Gemini-Vision
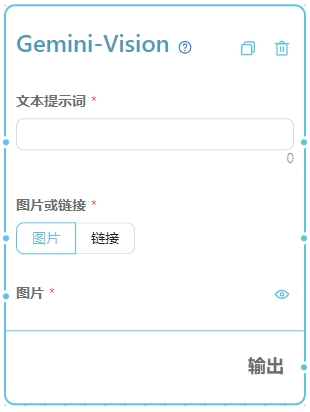
参数详解
1. 文本提示词
支持列表输入 指示 AI 语言模型生成内容的文本提示词。 根据官方的提示,带视觉的 GPT 模型最擅长回答关于图像中存在什么的一般问题。虽然它确实理解图像中对象之间的关系,它还没有被优化来回答关于图像中某些对象位置的详细问题。例如,你可以问它一辆车是什么颜色的,或者根据你冰箱里的东西,晚餐的一些想法可能是什么,但是如果你给它看一个房间的图像,问它椅子在哪里,它可能不会正确回答这个问题。2. 图片或链接
- 图片 - 通过在使用界面上传图片。
- 链接 - 输入一个图片的链接地址,可用于和其他节点连线结合。
3. 图片
通过在使用界面上传图片文件。4. 链接
支持列表输入 输入一个图片文件的链接地址,可用于和其他节点连线结合。输出类型
<font style="color:rgb(31, 35, 40);">字符串</font> | <font style="color:rgb(31, 35, 40);">列表</font>
积分消耗
按 Tokens 计算,1 积分 / 1000 Tokens。GLM-Vision
参数详解
1. 文本提示词
支持列表输入 指示 AI 语言模型生成内容的文本提示词。2. 图片或链接
- 图片 - 通过在使用界面上传图片。
- 链接 - 输入一个图片的链接地址,可用于和其他节点连线结合。
3. 图片
通过在使用界面上传图片文件。4. 链接
支持列表输入 输入一个图片文件的链接地址,可用于和其他节点连线结合。输出类型
<font style="color:rgb(31, 35, 40);">字符串</font> | <font style="color:rgb(31, 35, 40);">列表</font>
积分消耗
按 Tokens 计算,70 积分 / 1000 Tokens。Claude-Vision
参数详解
1. 文本提示词
支持列表输入 指示 AI 语言模型生成内容的文本提示词。2. 模型
- claude-3-opus - 新模型,质量最佳,价格最高 - 可接受 200K 输入,最大 4K 输出
- claude-3-sonnet - 新模型,速度、质量、价格最均衡 - 可接受 200K 输入,最大 4K 输出
- claude-3-haiku - 新模型,速度最快,价格最低 - 可接受 200K 输入,最大 4K 输出
3. 图片或链接
- 图片 - 通过在使用界面上传图片。
- 链接 - 输入一个图片的链接地址,可用于和其他节点连线结合。
4. 图片
通过在使用界面上传图片文件。5. 链接
支持列表输入 输入一个图片文件的链接地址,可用于和其他节点连线结合。输出类型
<font style="color:rgb(31, 35, 40);">字符串</font> | <font style="color:rgb(31, 35, 40);">列表</font>
积分消耗
| Model | Prompt | Completion |
|---|---|---|
| claude-3-opus | 75 积分 | 375 积分 |
| claude-3-sonnet | 15 积分 | 75 积分 |
| claude-3-haiku | 1.25 积分 | 6.25 积分 |
OCR

参数详解
1. 图片或链接
- 图片 - 通过在使用界面上传图片。
- 链接 - 输入一个图片的链接地址,可用于和其他节点连线结合。
2. 图片
通过在使用界面上传图片文件。3. 链接
支持列表输入 输入一个图片文件的链接地址,可用于和其他节点连线结合。输出类型
<font style="color:rgb(31, 35, 40);">字符串</font> | <font style="color:rgb(31, 35, 40);">列表</font>
积分消耗
每张图片识别消耗 30 积分。
若有收获,就点个赞吧
0 人点赞
