引言
本章和下一章对程序执行(如何启动代码,以及 Python 如何运行它)进行快速了解。在本章中我们将大致学习 Python 解释器是如何执行代码的。第三章将向你展示如何把自己的程序启动并运行。 启动细节本质上是与平台相关的,并且在这两章当中的一些内容可能不适用于你正在使用的平台。一些高级的读者可以尽可能地略过跟他们预期用途不相关的部分。同样的,过去已经使用过类似工具和倾向于快速获得语言要点的读者可以把一些章节归档为 “未来参考”。对于剩下的读者,在我们学习如何编写它之前,让我们快速看一下 Python 运行我们代码的方式。介绍 Python 解释器
到目前为止,我几乎一直在将 Python 作为一门编程语言在讲,但是,如当前实现的那样,它也是一个叫做解释器的软件包。解释器是执行其他程序的一种程序。当你编写一个 Python 程序时, Python 解释器会解读你的程序,执行它包含的指令。事实上,这个解释器是在你的代码和机器硬件之间的软件逻辑层。 当 Python 包被安装到你的机器上时,它产生了许多组件 —— 最少也会有一个解释器和支持库。取决于你是如何使用它的,Python 解释器可能以一个可执行程序或链接入另一个程序的一组库的形式来存在。取决于你运行的是哪一种 Python,解释器本身可以被实现为一个 C 程序,一组 Java 类或其他。不管它采取的是什么形式,你编写的 Python 代码总是会被解释器运行。为了确保它被运行,你必须安装一个 Python 解释器在电脑上。 Python 安装的细节根据平台而异,并且在附录 A 当中有更详细地讲述。简而言之:- Windows 的用户获取并运行一个自安装的可执行文件,它将 Python 装到你的电脑上。简单地双击并在每一个提示窗口中选择 是 或者 下一步就可以了。
- Linux 和 Mac OS X 的用户很可能已经在他们的电脑上预装了可用的 Python—— 在今天,这是这些平台上的标准组件。
- 一些 Linux 和 Mac OS X 用户(和大多数的 Unix 用户)从 Python 的完整源码分发包中编译 Python。
- Linux 用户还可以找到 RPM(Red Hat Package Manager) 文件,Mac OS X 用户可以找到各种各样的 Mac 专用的安装包。
- 其他的平台也有跟这些平台相关的安装技术。比如,Python 在手机、平板、游戏控制台和 ipod 上可用。但是安装细节非常不同。
 我们将在下一章讨论这里显示的开始选项。在 Unix 和 Linux 上,Python 很可能就在你的 /usr 目录树下。
我们将在下一章讨论这里显示的开始选项。在 Unix 和 Linux 上,Python 很可能就在你的 /usr 目录树下。
程序执行
编写和运行一个 Python 脚本意味着什么取决于你看待这些任务的角度:从程序员的角度,还是从 Python 解释器的角度。这两种角度都提供了关于 Python 编程的重要视角。程序执行 —— 程序员的角度
Python 最简单的形式只是一个包含 Python 语句的文本文件。比如。下面的名为 script0.py 的文件,就是一个我可以编造的最简单的 Python 脚本,但是它似乎就是一个完全正常运行的 Python 程序:文件含有两行 Python print 语句,它简单地打印了一个字符串(文字在引号内)和一个数字表达式(2 的 100 次方)的结果到输出流。不要担心这个代码的语法 —— 在这一章中,我们只是对如何运行代码感兴趣。在本书的下面的部分,我将解释 print 语句和为什么你可以在 Python 里面得到 2 的 100 次方而不溢出。 可以在任何你喜欢的文本编辑器里面创建这样的语句文件。按照约定,Python 的程序文件以 .py 结尾。技术上讲,命名方案只是对那些 “导入的”(这是在下一章中将会澄清的术语)文件才是必须的。但为了一致性,大部分文件都有 .Py 名字。 在一个文本文件中输入这些语句后,必须让 Python 去执行这个文件 —— 这仅仅意味着从上到下逐句运行文件当中的所有语句。如将在下一章中看到的,可以通过 shell 命令行,通过点击 Python 文件的图标,从 IDE 中,以及用其他标准的技术来启动 Python 程序文件。如果一切顺利,当执行文件的时候,将看到这两个 print 语句的结果出现在你电脑的某个位置 —— 默认通常是当你运行程序的时候出现在所处的同一个窗口:
print('hello world')print(2 ** 100)
比如,这就是当我在 windows 的笔记本的 命令行提示窗口的命令行上运行脚本时出现的结果,来确保没有任何愚蠢的笔误:
hello world1267650600228229401496703205376

Python 的角度
对脚本语言来说,前一节中的简短描述是相当标准的,并且它通常是大多数 Python 程序员需要知道的所有知识。在文本文件中键入代码,然后通过解释器运行那些文件。然而,在底层,当你让 Python 运行时有更多的事情发生了。虽然 Python 内部机制的知识对 Python 编程不是严格必须的,但对 Python 运行时结构的基本理解能帮助你掌握程序执行的更宏观场景。 当你让 Python 运行脚本时,在代码真正开始全力运行前有几个 Python 执行的步骤。具体来说,它首先被编译为名为 “字节码” 的东西,然后被发送到一个名为 “虚拟机” 的东西。Python 的角度 —— 字节码编译
当执行一个程序时,Python 会在内部且对你是几乎透明的情况下编译源码(文件中的语句)为一种名为字节码的格式。编译仅仅是一个翻译步骤,字节码是源码的更底层展示,与平台无关。大致的讲,Python 通过将每一条源码语句分解为独立步骤,将它们翻译为一组字节码指令。执行这个字节码翻译是为了提高执行速度 —— 字节码能比在文本文件中的源码语句运行得快得多。 你将注意到:在前面的段落中说了这个过程是对你是几乎透明的。如果 Python 进程在你的机器上有写权限,它就会把程序的字节码存储到以 .pyc 的扩展名(”.pyc” 意味着编译的 “.py” 源)结尾的文件中。 在 Python 3.2 之前,会看到在已经运行了一些程序后,这些文件和对应的源代码文件一起出现在你的电脑上 —— 也就是,同样的目录中。比如,将注意到:在导入 script.py 后会有一个 script.pyc。 在 3.2 及之后,Python 将 其 .pyc 字节码文件保存在你的源码文件所处目录的一个名为<font style="color:rgb(133, 128, 128);background-color:rgb(249, 250, 250);">__pycache__</font> 的子目录中,并且在那些名称就可以识别出创建它们的 Python 版本的文件中(比如,script.cpython-33.pyc)。这个新的 <font style="color:rgb(133, 128, 128);background-color:rgb(249, 250, 250);">__pycache__</font>子目录是用来避免混乱的,并且字节码文件的新的命名约定避免了安装在同一个电脑上的不同 Python 版本覆盖其他版本保存的字节码。尽管这些字节码文件模型对于大多数 Python 程序来说是自动和无关的,而且在前面描述过的不同 Python 实现中都有很大不同,但我们还是会在第 22 章更深入研究它们。
在两种模型中,Python 都保存像这样的字节码来作为启动速度优化。只要自从字节码上一次保存起,你没有修改过源码且没有使用不同于创建字节码的 Python 运行源码,下一次运行程序时,Python 将加载 .pyc 文件且跳过编译步骤。它按如下工作:
- 源更改:Python 自动检查源和字节码文件的最后修改时间戳来知道什么时候必须重新编译 —— 如果你编辑并重新保存了源码,字节码在下一次运行程序时就会自动重新创建。
- Python 版本:导入也会通过一些方法来检查来看是否文件必须被重新编译 —— 因为它由一个不同的 Python 版本创建,在 3.2 和更早版本中,使用的是用字节码文件中的 “魔术” 版本号,或在 3.2 和之后版本中,使用的是字节码文件名中的信息。
Python 的角度 —— Python 虚拟机(PVM)
一旦程序被编译为字节码(或字节码从现有的 .py 文件中加载),它就被发送到名为 Python 虚拟机(就是你们常说的首字母缩写 PVM)的东东中被执行。PVM 其实言过其实了;真的,它不是一个独立的程序,并且它不需要独立安装。实际上,PVM 只是一个大的代码循环,它迭代字节码指令,逐句执行指令的操作。PVM 是 Python 的运行时引擎;它总是作为 Python 系统的一部分出现,而且它是真正运行脚本的组件。技术上讲,它只是被称作”Python 解释器 “的最后一步。 图 2-2 显示了这里描述的运行时结构。记住,所有这些复杂性都已经故意对程序员隐藏了。字节码编译是自动的,且 PVM 只是你已经安装到机器上的 Python 系统的一部分。就是这样,程序员仅仅编码和运行含有语句的文件,Python 处理运行它们的组织工作。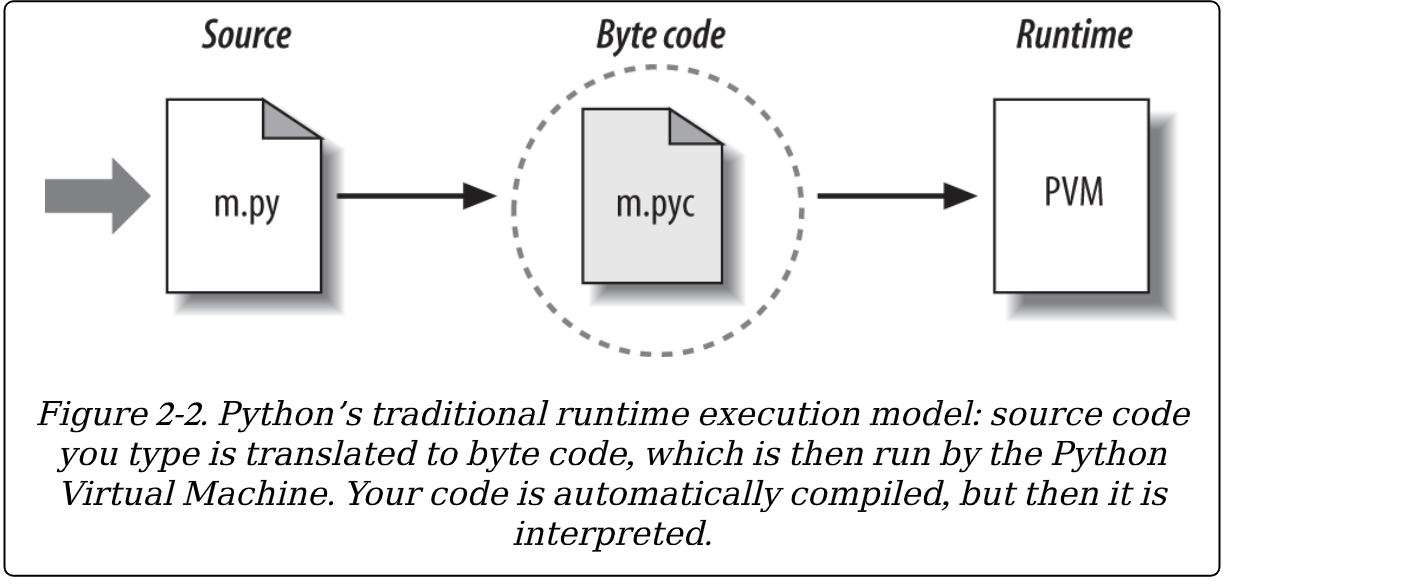
Python 的角度 —— 性能影响
有完全编译型语言如 C 和 C++ 背景的读者可能注意到在 Python 模型中的一些不同点。首先,在 Python 的工作中通常没有 build 或 “make” 步骤:代码在编写后就立即被运行。第二,Python 字节码不是二进制机器码(比如,Intel 或 ARM 芯片的指令)。字节码是 Python 特有的表现形式。 这就是为什么像第一章中描述的,有些 Python 代码可能不如 C 或 C++ 代码运行的那么快 ——PVM 循环,不是 CPU 芯片,仍然必须解释字节码,且字节码指令需要比 CPU 指令工作得更多。另一方面,不像在经典的解释器中,它仍然有一个内部的编译步骤 ——Python 不需要重复地重新分析和重新解析每一个源语句文本。最终效果就是纯 Python 代码运行的速度在传统编译性语言和传统解释性语言之间。要了解 Python 在性能妥协上的细节,请参见第一章。Python 的角度 —— 开发影响
Python 的执行模型的另一个影响是在开发环境和执行环境之间真的没有区别了。也就是说,编译和执行源码的系统真的是同一个。这个相似性对有传统编译型语言的读者意义更为重大,但在 Python 中,编译器总是在运行时出现而且是运行程序的系统的一部分(因为 Python 的解释器已经包含了编译器) 这导致开发周期更加快速。在执行开始前没有必要预编译和链接了;只需要键入和运行代码。这也向语言添加了更动态的特点 —— 对 Python 程序来说,在运行时构建和执行其他 Python 程序时是可能且通常非常方便的。比如,<font style="color:rgb(133, 128, 128);background-color:rgb(249, 250, 250);">eval</font> 和 <font style="color:rgb(133, 128, 128);background-color:rgb(249, 250, 250);">exec</font> 内置函数,接受和运行包含 Python 程序代码的字符串。这个结构也是为什么 Python 适合产品自定义 —— 因为 Python 代码能在系统运行时修改,用户可以在线修改系统的 Python 部分而无需拥有或编译整个系统的代码。
在更基本的层面上,记住在 Python 中所有我们真正的拥有的只是运行时 —— 根本就没有初始的编译时阶段,且所有事情发生在程序正在运行的时候。这甚至包含了如函数和类的创建以及模块的链接等操作。在更静态的语言中,这些事件发生在执行之前,但在 Python 中却和程序执行一起发生。如将看到的,这导致了比一些读者已经适应的语言更加动态的编程体验。

若有收获,就点个赞吧
0 人点赞
