- 星火认知大模型服务说明">星火认知大模型服务说明
- WebSocket协议通用鉴权URL生成说明">WebSocket协议通用鉴权URL生成说明
- 星火认知大模型Web API文档-网页">星火认知大模型Web API文档-网页
- Spark Android SDK接入文档-手机">Spark Android SDK接入文档-手机
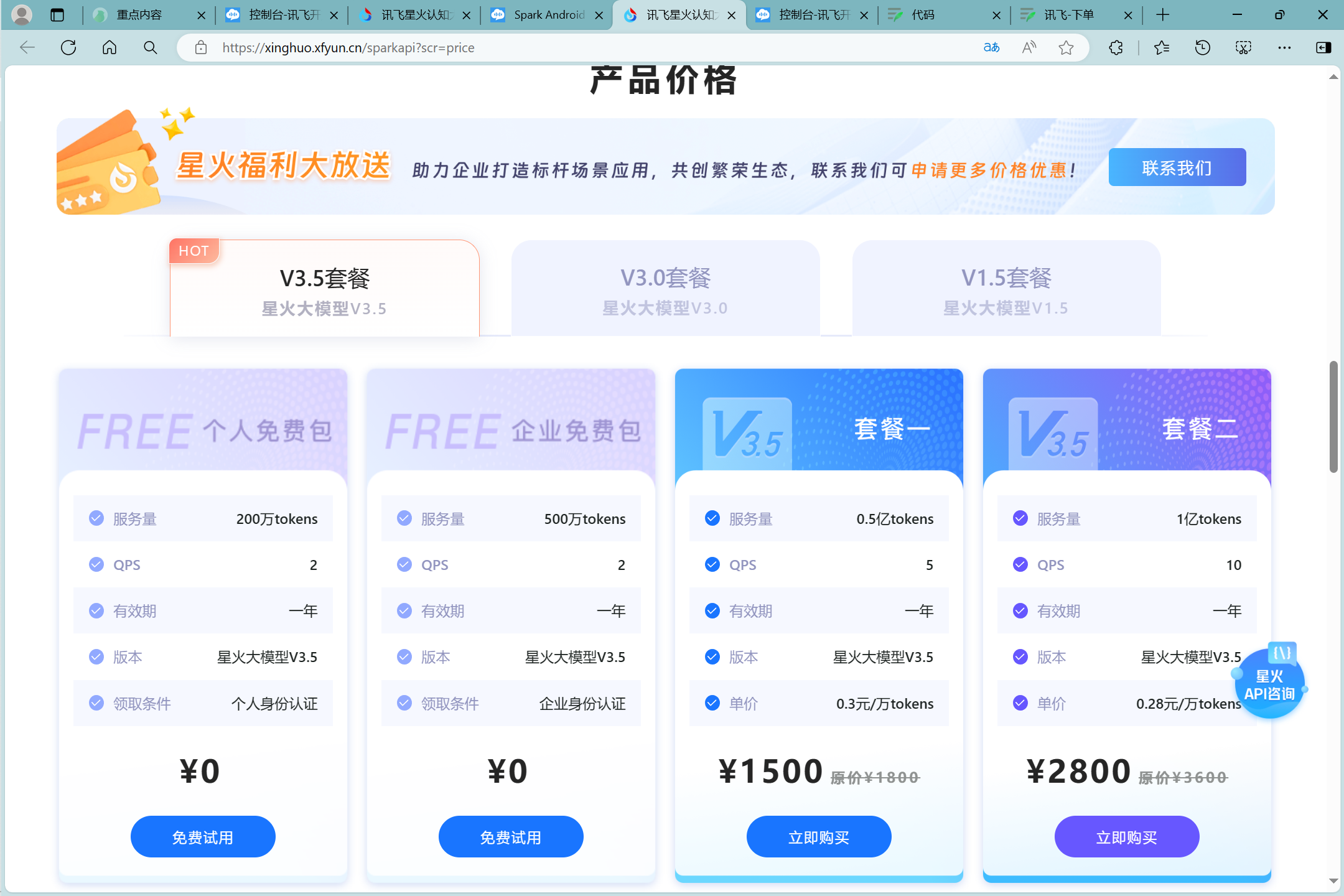
星火认知大模型服务说明
关于Web接口的说明:
- 必须符合 websocket 协议规范(rfc6455)。
- websocket握手成功后用户在60秒内没有发送请求数据,服务侧会主动断开。
- 本接口默认采用短链接的模式,即接口每次将结果完整返回给用户后会主动断开链接,用户在下次发送请求的时候需要重新握手链接。
关于SDK的说明:
- 高效接入:SDK统一封装鉴权模块,接口简单最快三步完成SDK集成接入
- 稳定可靠: 统一连接池保障连接时效性,httpDNS保障请求入口高可用性
- 配套完善:支持多路并发用户回调上下文绑定,交互历史管理及排障日志回传收集
- 多平台兼容:覆盖Windows,Linux,Android,iOS以及其他交叉编译平台
关于tokens的说明(重要):
- 接口采用tokens方式计费。
- tokens与词表、分词方案相关,没有精确的计算方式,但是接口会返回本次计费的tokens数(详见接口文档响应参数描述)。
- 接口计费会将请求text字段下所有的content内容均计费,开发者需要酌情考虑保留的历史对话信息数量,避免浪费tokens(最大的输入tokens见接口文档参数描述)。
关于文本审核说明(重要):
- 接口会对用户输入和AI输出内容进行文本审核,会对包括但不限于:(1) 涉及国家安全的信息;(2) 涉及政治与宗教类的信息;(3) 涉及暴力与恐怖主义的信息;(4) 涉及黄赌毒类的信息;(5) 涉及不文明的信息 的输入输出赋予错误码返回(详见错误码部分10013和10014说明)
关于错误码说明
服务错误码:
| 错误码 | 错误信息 |
|---|---|
| 0 | 成功 |
| 10000 | 升级为ws出现错误 |
| 10001 | 通过ws读取用户的消息出错 |
| 10002 | 通过ws向用户发送消息 错 |
| 10003 | 用户的消息格式有错误 |
| 10004 | 用户数据的schema错误 |
| 10005 | 用户参数值有错误 |
| 10006 | 用户并发错误:当前用户已连接,同一用户不能多处同时连接。 |
| 10007 | 用户流量受限:服务正在处理用户当前的问题,需等待处理完成后再发送新的请求。(必须要等大模型完全回复之后,才能发送下一个问题) |
| 10008 | 服务容量不足,联系工作人员 |
| 10009 | 和引擎建立连接失败 |
| 10010 | 接收引擎数据的错误 |
| 10011 | 发送数据给引擎的错误 |
| 10012 | 引擎内部错误 |
| 10013 | 输入内容审核不通过,涉嫌违规,请重新调整输入内容 |
| 10014 | 输出内容涉及敏感信息,审核不通过,后续结果无法展示给用户 |
| 10015 | appid在黑名单中 |
| 10016 | appid授权类的错误。比如:未开通此功能,未开通对应版本,token不足,并发超过授权 等等 |
| 10017 | 清除历史失败 |
| 10019 | 表示本次会话内容有涉及违规信息的倾向;建议开发者收到此错误码后给用户一个输入涉及违规的提示 |
| 10110 | 服务忙,请稍后再试 |
| 10163 | 请求引擎的参数异常 引擎的schema 检查不通过 |
| 10222 | 引擎网络异常 |
| 10907 | token数量超过上限。对话历史+问题的字数太多,需要精简输入 |
| 11200 | 授权错误:该appId没有相关功能的授权 或者 业务量超过限制 |
| 11201 | 授权错误:日流控超限。超过当日最大访问量的限制 |
| 11202 | 授权错误:秒级流控超限。秒级并发超过授权路数限制 |
| 11203 | 授权错误:并发流控超限。并发路数超过授权路数限制 |
| 错误码 | 错误信息 |
|---|---|
| 18300 | sdk不可用 |
| 18301 | sdk没有初始化 |
| 18302 | sdk初始化失败 |
| 18303 | sdk已经初始化 |
| 18304 | sdk不合法参数 |
| 18305 | sdk会话handle为空 |
| 18306 | sdk会话未找到 |
| 18307 | sdk会话重复终止 |
| 18308 | 超时错误 |
| 18309 | sdk正在初始化中 |
| 18310 | sdk会话重复开启 |
| 18400 | 工作目录无写权限 |
| 18402 | 文件打开失败 |
| 18403 | 内存分配失败 |
| 18500 | 未找到该参数key |
| 18501 | 参数范围溢出,不满足约束条件 |
| 18502 | sdk初始化参数为空 |
| 18503 | sdk初始化参数中appid为空 |
| 18504 | sdk初始化参数中apiKey为空 |
| 18505 | sdk初始化参数中apiSecret为空 |
| 18507 | input参数为空 |
| 18509 | 必填参数缺失 |
| 18700 | 通用网络错误 |
| 18701 | 网路不通 |
| 18702 | 网关检查不过 |
| 18712 | http 404错误 |
| 18801 | 连接建立出错 |
| 18802 | 结果等待超时 |
| 18311 | sdk同一能力并发路数超出 |
WebSocket协议通用鉴权URL生成说明
#1. 鉴权说明
开发者需要自行先在控制台创建应用,利用应用中提供的appid,APIKey, APISecret进行鉴权,生成最终请求的鉴权url。鉴权方法见下方1.2。#1.2 鉴权参数
| 参数 | 类型 | 必须 | 说明 | 示例 |
|---|---|---|---|---|
| host | string | 是 | 请求的主机 | aichat.xf-yun.com(使用时需替换为实际使用的接口地址) |
| date | string | 是 | 当前时间戳,采用RFC1123格式,时间偏差需控制在300s内 | Fri, 05 May 2023 10:43:39 GMT |
| GET | string | 是 | 请求方式 | /v1.1/chat HTTP/1.1 |
| authorization | string | 是 | base64编码的签名信息 | 参考下方生成方式 |
#1.2.1 date参数生成规则
星火认知大模型Web API文档-网页
#1. 接口说明
注意: 该接口可以正式使用。如您需要申请使用,请点击前往产品页面。
Tips:- 计费包含接口的输入和输出内容
- 1tokens 约等于1.5个中文汉字 或者 0.8个英文单词
- 星火V1.5支持[搜索]内置插件;星火V2.0、V3.0和V3.5支持[搜索]、[天气]、[日期]、[诗词]、[字词]、[股票]六个内置插件
- 星火V3.5 现已支持system、Function Call 功能。
#1.1 请求地址
Tips: 星火大模型API当前有V1.5、V2.0、V3.0和V3.5四个版本,四个版本独立计量tokens。
传输协议 :ws(s),为提高安全性,强烈推荐wss
星火大模型V3.5请求地址,对应的domain参数为generalv3.5:
wss://spark-api.xf-yun.com/v3.5/chat
星火大模型V3请求地址,对应的domain参数为generalv3:
wss://spark-api.xf-yun.com/v3.1/chat
星火大模型V2请求地址,对应的domain参数为generalv2:
wss://spark-api.xf-yun.com/v2.1/chat
星火大模型V1.5请求地址,对应的domain参数为general:
wss://spark-api.xf-yun.com/v1.1/chat
#1.2 接口鉴权
参考通用URL鉴权文档 ### #1.3 接口请求 #### #1.3.1 请求参数接口请求字段由三个部分组成:header,parameter, payload。 字段解释如下
# 参数构造示例如下{"header": {"app_id": "12345","uid": "12345"},"parameter": {"chat": {"domain": "generalv3.5","temperature": 0.5,"max_tokens": 1024,}},"payload": {"message": {# 如果想获取结合上下文的回答,需要开发者每次将历史问答信息一起传给服务端,如下示例# 注意:text里面的所有content内容加一起的tokens需要控制在8192以内,开发者如有较长对话需求,需要适当裁剪历史信息"text": [{"role":"system","content":"你现在扮演李白,你豪情万丈,狂放不羁;接下来请用李白的口吻和用户对话。"} #设置对话背景或者模型角色{"role": "user", "content": "你是谁"} # 用户的历史问题{"role": "assistant", "content": "....."} # AI的历史回答结果# ....... 省略的历史对话{"role": "user", "content": "你会做什么"} # 最新的一条问题,如无需上下文,可只传最新一条问题]}}}
header部分
| 参数名称 | 类型 | 必传 | 参数要求 | 参数说明 |
|---|---|---|---|---|
| app_id | string | 是 | 应用appid,从开放平台控制台创建的应用中获取 | |
| uid | string | 否 | 最大长度32 | 每个用户的id,用于区分不同用户 |
parameter.chat部分
| 参数名称 | 类型 | 必传 | 参数要求 | 参数说明 |
|---|---|---|---|---|
| domain | string | 是 | 取值为[general,generalv2,generalv3,generalv3.5] | 指定访问的领域: general指向V1.5版本; generalv2指向V2版本; generalv3指向V3版本; generalv3.5指向V3.5版本; 注意:不同的取值对应的url也不一样! |
| temperature | float | 否 | 取值范围 (0,1] ,默认值0.5 | 核采样阈值。用于决定结果随机性,取值越高随机性越强即相同的问题得到的不同答案的可能性越高 |
| max_tokens | int | 否 | V1.5取值为[1,4096] V2.0、V3.0和V3.5取值为[1,8192],默认为2048。 | 模型回答的tokens的最大长度 |
| top_k | int | 否 | 取值为[1,6],默认为4 | 从k个候选中随机选择⼀个(⾮等概率) |
| chat_id | string | 否 | 需要保障用户下的唯一性 | 用于关联用户会话 |
payload.message.text部分
注:text下所有content累计内容 tokens需要控制在8192内
| 参数名称 | 类型 | 必传 | 参数要求 | 参数说明 |
|---|---|---|---|---|
| role | string | 是 | 取值为[system,user,assistant] | system用于设置对话背景,user表示是用户的问题,assistant表示AI的回复 |
| content | string | 是 | 所有content的累计tokens需控制8192以内 | 用户和AI的对话内容 |
#1.4 接口响应
接口返回字段分为两个部分,header,payload。字段解释如下
# 接口为流式返回,此示例为最后一次返回结果,开发者需要将接口多次返回的结果进行拼接展示{"header":{"code":0,"message":"Success","sid":"cht000cb087@dx18793cd421fb894542","status":2},"payload":{"choices":{"status":2,"seq":0,"text":[{"content":"我可以帮助你的吗?","role":"assistant","index":0}]},"usage":{"text":{"question_tokens":4,"prompt_tokens":5,"completion_tokens":9,"total_tokens":14}}}}
header部分
| 字段名 | 类型 | 字段说明 |
|---|---|---|
| code | int | 错误码,0表示正常,非0表示出错;详细释义可在接口说明文档最后的错误码说明了解 |
| message | string | 会话是否成功的描述信息 |
| sid | string | 会话的唯一id,用于讯飞技术人员查询服务端会话日志使用,出现调用错误时建议留存该字段 |
| status | int | 会话状态,取值为[0,1,2];0代表首次结果;1代表中间结果;2代表最后一个结果 |
payload.choices部分
| 字段名 | 类型 | 字段说明 |
|---|---|---|
| status | int | 文本响应状态,取值为[0,1,2]; 0代表首个文本结果;1代表中间文本结果;2代表最后一个文本结果 |
| seq | int | 返回的数据序号,取值为[0,9999999] |
| content | string | AI的回答内容 |
| role | string | 角色标识,固定为assistant,标识角色为AI |
| index | int | 结果序号,取值为[0,10]; 当前为保留字段,开发者可忽略 |
payload.usage部分(在最后一次结果返回)
| 字段名 | 类型 | 字段说明 |
|---|---|---|
| question_tokens | int | 保留字段,可忽略 |
| prompt_tokens | int | 包含历史问题的总tokens大小 |
| completion_tokens | int | 回答的tokens大小 |
| total_tokens | int | prompt_tokens和completion_tokens的和,也是本次交互计费的tokens大小 |
#2.Function Call说明
注:当前仅V3.0和V3.5(推荐)版本支持了该功能
#2.1接口请求
#2.1.1 请求示例
# 参数构造示例如下,仅在原本生成的基础上,增加了functions.text字段,用于方法的注册{"header": {"app_id": appid,"uid": "1234"},"parameter": {"chat": {"domain": domain,"random_threshold": 0.5,"max_tokens": 2048,"auditing": "default"}},"payload": {"message": {"text": [{"role": "user", "content": ""} # 用户的提问]},"functions": {"text": [{"name": "天气查询","description": "天气插件可以提供天气相关信息。你可以提供指定的地点信息、指定的时间点或者时间段信息,来检索诗词库,精准检索到天气信息。","parameters": {"type": "object","properties": {"location": {"type": "string","description": "地点,比如北京。"},"date": {"type": "string","description": "日期。"}},"required": ["location"]}},{"name": "税率查询","description": "税率查询可以查询某个地方的个人所得税率情况。你可以提供指定的地点信息、指定的时间点,精准检索到所得税率。","parameters": {"type": "object","properties": {"location": {"type": "string","description": "地点,比如北京。"},"date": {"type": "string","description": "日期。"}},"required": ["location"]}}]}}}
#2.1.2参数说明
接口请求payload.functions字段解释如下:| 参数名称 | 类型 | 必传 | 参数要求 | 参数说明 |
|---|---|---|---|---|
| text | array | 是 | 列表形式,列表中的元素是json格式 | 元素中包含name、description、parameters属性 |
| name | string | 是 | function名称 | 用户输入命中后,会返回该名称 |
| description | string | 是 | function功能描述 | 描述function功能即可,越详细越有助于大模型理解该function |
| parameters | json | 是 | function参数列表 | 包含type、properties、required字段 |
| parameters.type | string | 是 | 参数类型 | |
| parameters.properties | string | 是 | 参数信息描述 | 该内容由用户定义,命中该方法时需要返回哪些参数 |
| properties.x.type | string | 是 | 参数类型描述 | 该内容由用户定义,需要返回的参数是什么类型 |
| properties.x.description | string | 是 | 参数详细描述 | 该内容由用户定义,需要返回的参数的具体描述 |
| parameters.required | array | 是 | 必须返回的参数列表 | 该内容由用户定义,命中方法时必须返回的字段 |
#2.2接口响应
#2.2.1示例如下
// 触发了function_call的情况下,只会返回一帧结果,其中status 为2{"header":{"code":0,"message":"Success","sid":"cht000b41d5@dx18b851e6931b894550","status":2},"payload":{"choices":{"status":2,"seq":0,"text":[{"content":"","role":"assistant","content_type":"text","function_call":{"arguments":"{\"datetime\":\"今天\",\"location\":\"合肥\"}","name":"天气查询"},"index":0}]},"usage":{"text":{"question_tokens":3,"prompt_tokens":3,"completion_tokens":0,"total_tokens":3}}}}
#2.2.2返回字段说明
| 字段名 | 类型 | 字段说明 |
|---|---|---|
| function_call | json | function call 返回结果 |
| function_call.arguments | json | 客户在请求体中定义的参数及参数值 |
| function_call.name | string | 客户在请求体中定义的方法名称 |
#3. 调用示例
注: demo只是一个简单的调用示例,不适合直接放在复杂多变的生产环境使用
Spark Android SDK接入文档-手机
注意: 该接口可以正式使用。如您需要申请使用,请点击前往产品页面。
Tips:- 计费包含接口的输入和输出内容
- 1tokens 约等于1.5个中文汉字 或者 0.8个英文单词
- 星火V1.5支持[搜索]内置插件;星火V2.0和V3.0支持[搜索]、[天气]、[日期]、[诗词]、[字词]、[股票]六个内置插件
#1. SDK介绍
Spark SDK提供了一套快速集成星火大模型的工具,让开发者无需关注底层协议细节,提高开发效率。同时,它支持Android、Linux、iOS、Windows多个平台,方便开发者选择最适合自己的平台进行开发。Spark SDK可以帮助企业快速将星火大模型应用到业务场景中,提高效率和竞争力。本文档主要介绍Android平台集成过程。 ## #2. 兼容性说明 | 类别 | 兼容范围 | | :—- | :—- | | 系统 | 支持armv7和armv8架构,兼容android 5.0及以上版本 | | 开发环境 | 建议使用Android Studio 进行开发 | ## #3. 授权说明 星火认知大模型授权支持按照tokens授权和设备级授权两种方式。 tokens 授权:授权tokens总量,按照tokens 使用量计费,1 tokens 约等于1.5个中文汉字 或者 0.8个英文单词。 设备级授权:授权设备台数和有效期,按照设备指纹计量计费,此方式仅支持定制级客户,如有需要请与开放平台联系。#4. SDK集成包目录结构
将SDK zip包解压缩,得到如下文件: ├── Demo Spark的使用DEMO,DEMO中已经集成了SDK,您可以参考DEMO,集成SDK。集成前,请先测通DEMO,了解调用原理。├── ReleaseNotes.txt SDK版本日志
├── SDK Spark SDK
│ └── SparkChain.aar
└── SparkChain LLM Android SDK集成文档.pdf Spark集成指南
#5. 接口调用流程图
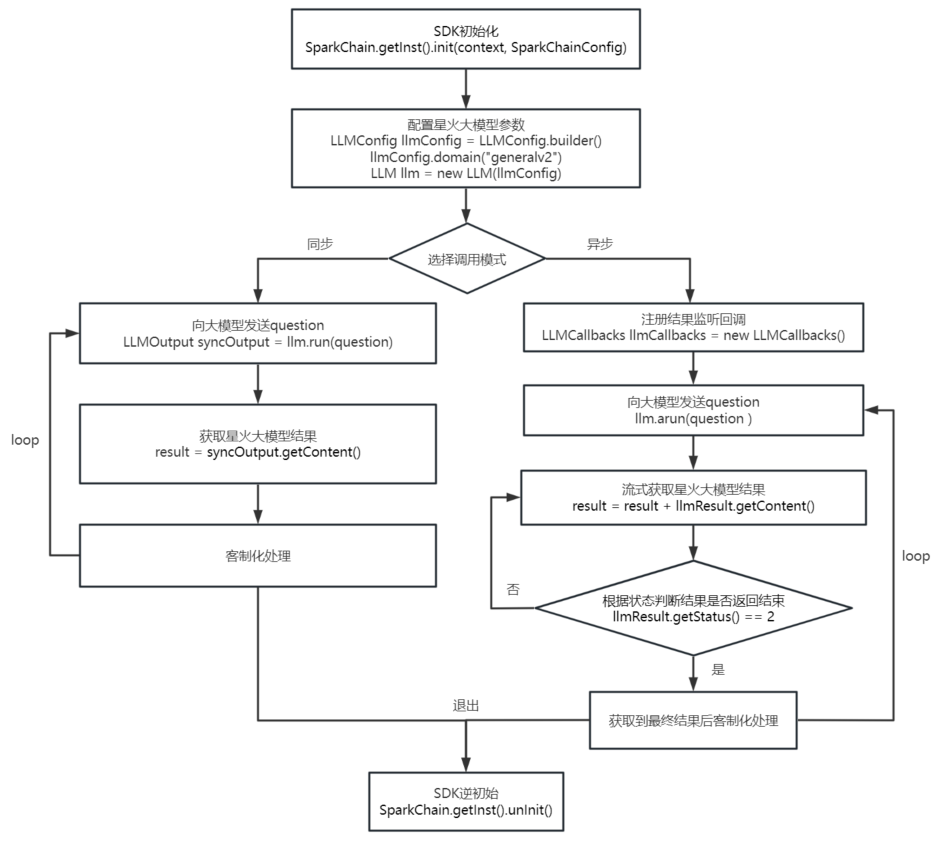
#6. SDK工程配置
#6.1 导入SDK库
复制SparkChain.aar到项目的libs目录下,然后在主Module的build.gradle文件中,增加如下配置:
implementation files('libs/SparkChain.aar')
#6.2 配置权限
Spark SDK中使用了如下权限:| 权限 | 使用说明 |
|---|---|
| INTERNET | 必须权限,SDK需要访问网络获取结果。 |
| READ_EXTERNAL_STORAGE | 必须权限,SDK需要判断日志路径是否存在。 |
| WRITE_EXTERNAL_STORAGE | 必须权限,SDK写本地日志需要用到该权限。 |
| MANAGE_EXTERNAL_STORAGE | 可选权限,安卓10以上设备用于动态授权弹出授权框需要用到该权限,安卓10以上设备必选。 |
| READ_PHONE_STATE | 可选权限,用于获取设备标识。 |
Android 10.0(API 29)及以上版本需要在application中做如下配置
<!-- 移除SDK非必须权限示例 --><uses-permission android:name="android.permission.READ_PHONE_STATE" tools:node="remove" />
<application android:requestLegacyExternalStorage="true"/>
#7. 快速集成
#7.1 SDK初始化
在使用Spark SDK 星火大模型交互功能前,需要首先开通星火大模型授权并获取已开通授权的应用信息**(appId、apiKey、apiSecret)。SDK全局只需要初始化一次。初始化示例如下:
初始化参数说明:
SparkChainConfig config = SparkChainConfig.builder().appID("$appId").apiKey("$apiKey").apiSecret("$apiSecret");//从平台获取的授权appid,apikey,apisecretyint ret = SparkChain.getInst().init(getApplicationContext(), config);Log.d(TAG,"sdk init:"+ret);
| 参数名 | 类型 | 说明 | 是否必填 |
|---|---|---|---|
| appID | String | 创建应用后,生成的应用ID | 是 |
| apiKey | String | 创建应用后,生成的唯一应用标识 | 是 |
| apiSecret | String | 创建应用后,生成的唯一应用秘钥 | 是 |
| logLevel | int | 0:VERBOSE,1:DEBUG,2:INFO,3:WARN,4:ERROR,5:FATAL,100:OFF | 否 |
| logPath | String | 日志存储路径,设置则会把日志存在该路径下,不设置则会把日志打印在终端上 | 否 |
| uid | String | 用户自定义标识 | 否 |
#7.2 配置星火大模型参数
首先需要配置星火大模型的相关参数,示例如下:参数说明:
LLMConfig llmConfig = LLMConfig.builder();llmConfig.domain("generalv2");llmConfig.url("wss://spark-api.xf-yun.com/v2.1/chat");//如果使用generalv2,domain和url都可缺省,SDK默认;如果使用general,url可缺省,SDK会自动补充;如果是其他,则需要设置domain和url。LLM llm = new LLM(llmConfig);
| 字段 | 含义 | 类型 | 限制 | 是否必传 |
|---|---|---|---|---|
| domain | 需要使用的领域 | String | 取值为[general,generalv2],默认generalv2 general:通用大模型V1.5版本 generalv2:通用大模型V2版本 general和generalv2对应的url不同,需要严格对应。url地址参见下文。 | 否 |
| url | 配置chat服务器域名地址 | String | general:wss: //spark-api.xf-yun.com/v1.1/chat generalv2:wss: //spark-api.xf-yun.com/v2.1/chat generalv3:wss: //spark-api.xf-yun.com/v3.1/chat domian 取值为 general或generalv2 时,SDK自动设置url,可缺省。 |
否 |
| maxToken | 回答的tokens的最大长度 | int | 取值范围1-4096,默认:2048 | 否 |
| temperature | 配置核采样阈值,改变结果的随机程度 | float | 取值范围 (0,1] ,默认:0.5 | 否 |
| auditing | 内容审核的场景策略 | String | 当前仅支持default | 否 |
| topK | 配置从k个候选中随机选择⼀个(⾮等概率) | int | 取值范围1-6,默认值:4 | 否 |
| chatID | 配置关联会话chat_id标识,需要保障用户下唯一 | String | 否 |
#7.3 星火请求调用
当前支持同步调用和异步调用两种方式。用户可以通过run方法或者arun方法向大模型发送问题请求,获取大模型返回结果。run方法、arun方法不支持并发调用。#7.3.1 同步调用
#7.3.1.1 请求调用
run方法参数说明:
//同步调用// 第一轮交互,如果不需要交互上下文,均可按照此方式调用String question1 = "上海有什么景点?";LLMOutput syncOutput = llm.run(question1);if(syncOutput.getErrCode() == 0) {Log.i(TAG, "同步调用:" + syncOutput.getRole() + ":" + syncOutput.getContent());results = syncOutput.getContent();}else {Log.e(TAG, "同步调用:" + "errCode" + syncOutput.getErrCode() + " errMsg:" + syncOutput.getErrMsg());}//第二轮交互 示例带历史上下文的交互String question2 = "那帮我安排一份旅游计划吧。";try{JSONArray array = new JSONArray();JSONObject item_1 = new JSONObject();item_1.put("role","user");item_1.put("content",question1);JSONObject item_2 = new JSONObject();item_2.put("role","assistant");item_2.put("content",results);JSONObject item_3 = new JSONObject();item_3.put("role","user");item_3.put("content",question2);array.put(item_1).put(item_2).put(item_3);syncOutput = llm.run(array.toString());if(syncOutput.getErrCode() == 0) {Log.i(TAG, "同步调用:" + syncOutput.getRole() + ":" + syncOutput.getContent());results = syncOutput.getContent();}else {Log.e(TAG, "同步调用:" + "errCode" + syncOutput.getErrCode() + " errMsg:" + syncOutput.getErrMsg());}}catch(Exception e){e.printStackTrace();}
| 参数名 | 类型 | 说明 | 限制 | 是否必填 |
|---|---|---|---|---|
| question | String | 输入信息文本,包含历史信息 | general:4096 tokens generalv2:8192 tokens | 是 |
| 参数 | 类型 | 获取方法 | 说明 |
|---|---|---|---|
| errCode | int | getErrCode() | 调用结果状态,0:调用成功,非0:调用失败,具体原因请根据返回值参考错误码 |
| errMsg | String | getErrMsg() | 调用失败时的错误信息 |
| role | String | getRole() | 星火大模型的角色,assistant::助手,user:用户 |
| content | String | getContent() | 调用结果 |
| completionTokens | int | getCompletionTokens() | 回答的Token大小 |
| promptTokens | int | getPromptTokens() | 包含历史问题的总Tokens大小 |
| totalTokens | int | getTotalTokens() | promptTokens和completionTokens的和,也是本次交互计费的Tokens大小 |
#7.3.2 异步调用
#7.3.2.1.注册结果监听回调
LLMCallbacks数据结构说明:
//异步调用LLMCallbacks llmCallbacks = new LLMCallbacks() {@Overridepublic void onLLMResult(LLMResult llmResult, Object usrContext) {Log.d(TAG,"异步调用:" + "onLLMResult:" + " " + llmResult.getRole() + " " + llmResult.getContent());}@Overridepublic void onLLMEvent(LLMEvent event, Object usrContext) {Log.w(TAG,"onLLMEvent:" + " " + event.getEventID() + " " + event.getEventMsg());}@Overridepublic void onLLMError(LLMError error, Object usrContext) {Log.e(TAG,"onLLMError:" + " " + error.getErrCode() + " " + error.getErrMsg());}};llm.registerLLMCallbacks(llmCallbacks);
| 方法 | 参数 | 类型 | 说明 |
|---|---|---|---|
| onLLMResult | result | LLMResult | 星火大模型结果实例 |
| usrContext | Object | 用户自定义标识 | |
| onLLMEvent | event | LLMEvent | 调用事件结果实例 |
| usrContext | Object | 用户自定义标识 | |
| onLLMError | error | LLMError | 错误信息结果实例 |
| usrContext | Object | 用户自定义标识 |
| 结构类 | 方法 | 说明 |
|---|---|---|
| LLMResult | getRole | 星火大模型角色,assistant::助手,user:用户 |
| getContent | 调用结果 | |
| getCompletionTokens() | 回答的Token大小 | |
| getPromptTokens() | 包含历史问题的总Tokens大小 | |
| getTotalTokens() | promptTokens和completionTokens的和,也是本次交互计费的Tokens大小 | |
| getStatus() | 返回结果状态,0:start,1:continue,2:end | |
| LLMEvent | getEventID | 事件ID,15:建立连接,19:连接断开 |
| getEventMsg | 事件信息 | |
| LLMError | getErrCode | 错误码ID |
| getErrMsg | 错误信息 |
#7.3.2.2 请求调用
arun方法参数说明:
String myContext = "myContext";//异步调用// 第一轮交互,如果不需要交互上下文,均可按照此方式调用String question1 = "上海有什么景点?";int ret = llm.arun(question1,myContext);while (!isFinsh){try {Thread.sleep(100);}catch (Exception e){}}Log.d(TAG,"turn1:"+results);isFinsh = false;results = "";//第二轮交互 示例带历史上下文的交互String question2 = "那帮我安排一份旅游计划吧。";try{JSONArray array = new JSONArray();JSONObject item_1 = new JSONObject();item_1.put("role","user");item_1.put("content",question1);JSONObject item_2 = new JSONObject();item_2.put("role","assistant");item_2.put("content",results);JSONObject item_3 = new JSONObject();item_3.put("role","user");item_3.put("content",question2);array.put(item_1).put(item_2).put(item_3);ret = llm.arun(array.toString(),myContext);}catch(Exception e){e.printStackTrace();}while (!isFinsh){try {Thread.sleep(100);}catch (Exception e){}}Log.d(TAG,"turn2:"+results);
| 参数 | 类型 | 说明 | 限制 | 是否必填 |
|---|---|---|---|---|
| question | String | 输入信息文本 | general:4096 tokens generalv2:8192 tokens | 是 |
| usrTag | Object | 用户自定义标识 | 否 |
#7.4 响应协议说明
该协议为中间协议,星火大模型是按照此协议格式返回结果。SDK已完成对此协议的解析和封装,获取相应字段方法请查询7.3节LLMOutput和LLMResult的结构说明。协议结构说明
# 接口为流式返回,此示例为最后一次返回结果,开发者需要将接口多次返回的结果进行拼接展示{"header":{"code":0,"message":"Success","sid":"cht000b2d3c@dx18a980cc0beb894540","status":2},"payload":{"choices":{"status":2,"seq":9,"text":[{"content":"”","role":"assistant","index":0}]},"usage":{"text":{"question_tokens":15,"prompt_tokens":15,"completion_tokens":61,"total_tokens":76}}}}
| 字段 | 含义 | 类型 | 说明 |
|---|---|---|---|
| header | 协议头部 | Object | 协议头部,用于描述平台特性的参数 |
| payload | 响应数据块 | Object | 数据段,携带响应的数据。 |
| 字段 | 含义 | 类型 |
|---|---|---|
| sid | 本次会话的id | String |
| status | 数据状态 0:start,1:continue,2:end | int |
| seq | 数据序号,标明数据为第几块。最小值:0, 最大值:9999999 | int |
| content | 文本数据 | String |
| role | 星火大模型角色 | String |
| prompt_tokens | 包含历史问题的总Tokens大小 | int |
| completion_tokens | 回答的Token大小 | int |
| total_tokens | promptTokens和completionTokens的和,也是本次交互计费的Tokens大小 | int |
#7.5 SDK逆初始化
当SDK需要完整退出时,需调用逆初始化方法释放资源,示例代码如下:
SparkChain.getInst().unInit();
#8. 错误码
错误码包含SDK错误码和云端错误码,SDK错误码用来反馈SDK本地运行时遇到的错误;云端错误码用来反馈星火大模型交互时服务端错误。#8.1 SDK错误码
| 错误码 | 含义 | 自查指南 |
|---|---|---|
| 0 | 操作成功 | |
| 18007 | 授权应用不匹配(apiKey、apiSecret) | apiKey、apiSecret 配置有误,请核对项目中配置的 apiKey、apiSecret 。 |
| 18301 | SDK未初始化 | 在使用大模型前请先初始化 SDK,如果有调用 uninit 方法,再次使用大模型交互时需要重新初始化。 |
| 18302 | SDK初始化失败 | 请根据init接口回调中返回的错误码参考此文档做对应检查 |
| 18303 | SDK 已经初始化 | 重复初始化导致,使用能力时,SDK 只需要初始化一次,请检查 SDK 初始化逻辑是否存在多次初始化。 |
| 18304 | 不合法参数 | 请参考demo及集成文档仔细检查所传参数是否正确。 |
| 18311 | sdk同一能力并发路数超出最大限制 | |
| 18312 | 此实例已处在运行态,禁止单实例并发运行 | |
| 18400 | 工作目录无写权限 | 在设置 workDir 时,请确保该工作路径有读写权限。若无法设置读写权限,请修改为有读写权限的工作路径。 |
| 18402 | 文件打开失败 | 请检查 日志中所打印的文件是否存在,以及对应路径下是否有读权限。 |
| 18500 | 未找到该参数 key | 请参照demo或集成文档仔细检查参数名拼写 |
| 18501 | 参数范围溢出,不满足约束条件 | 请根据文档检查调用 SDK 方法时所传参数范围,需要确保所传参数符合协议约束要求 |
| 18502 | SDK 初始化参数为空 | 请根据 SDK 集成文档检查 SDK 初始化代码,确保必填参数有值且合法 |
| 18503 | SDK 初始化参数中 appId 为空 | appId 为空值,请在 SDK 初始化时传入正确的 appId 值 |
| 18504 | SDK 初始化参数中 apiKey为空 | apiKey为空值,请在 SDK 初始化时传入正确的 apiKey值 |
| 18505 | SDK 初始化参数中 apiSecret 为空 | apiSecret 为空值,请在 SDK 初始化时传入正确的 apapiSecret 值 |
| 18509 | 必填参数缺失 | 请参考demo或者文档检查是否漏传必填参数 |
| 18700 | 通用网络错误 | 请检查网络连接是否正常 |
| 18701 | 网络不通 | 请检查网络连接是否正常 |
| 18702 | 网关检查不过 | 检查设备时间是否正确; 请检查 SDK 初始化时所传 apiKey、apiScrect 是否正确; |
| 18703 | 云端响应格式不对 | 请检查网络是否可以正常访问外网 |
| 18705 | 应用 ApiKey & ApiSecret 校验失败 | 请检查 apiKey、apiSecret 是否正确 |
| 18707 | 授权已过期 | 请检查授权期限 |
| 18708 | 无可用授权 | 没有授权或者授权已满 |
| 18712 | 网络请求 404 错误 | 请检查网络是否通畅 |
| 18713 | 设备指纹安全等级不匹配 | 设备指纹安全等级不符合要求 |
| 18714 | 应用信息有误 | 服务端无法查询到api_key,请检查api_key和api_secret信息是否填写正确 |
| 18717 | SDK授权不足 | 授权数量已满 |
| 18801 | 连接建立出错 | 请检查网络是否通畅 |
| 18802 | 结果等待超时 | 请检查网络是否通畅 |
| 18803 | 连接状态异常 | 请检查网络是否通畅 |
| 18902 | 并发超过路数限制 | 不支持并发 |
| 18903 | 大模型规划步骤为空 | 请检查请求数据的意图是否明确 |
| 18904 | 插件未找到 | 请检查是否使用了未存在的插件 |
| 18906 | 与大模型交互次数超限制 | |
| 18907 | 运行超限制时长 | |
| 18908 | 大模型返回结果格式异常 | |
| 18951 | 同一流式大模型会话,禁止并发交互请求 | |
| 18952 | 输入文本格式或内容非法 |
#8.2 服务端错误码
| 错误码 | 错误信息 |
|---|---|
| 错误码 | 错误信息 |
| 0 | 成功 |
| 10000 | 升级为ws出现错误 |
| 10001 | 通过ws读取用户的消息出错 |
| 10002 | 通过ws向用户发送消息 错 |
| 10003 | 用户的消息格式有错误 |
| 10004 | 用户数据的schema错误 |
| 10005 | 用户参数值有错误 |
| 10006 | 用户并发错误:当前用户已连接,同一用户不能多处同时连接。 |
| 10007 | 用户流量受限:服务正在处理用户当前的问题,需等待处理完成后再发送新的请求。(必须要等大模型完全回复之后,才能发送下一个问题) |
| 10008 | 服务容量不足,联系工作人员 |
| 10009 | 和引擎建立连接失败 |
| 10010 | 接收引擎数据的错误 |
| 10011 | 发送数据给引擎的错误 |
| 10012 | 引擎内部错误 |
| 10013 | 输入内容审核不通过,涉嫌违规,请重新调整输入内容 |
| 10014 | 输出内容涉及敏感信息,审核不通过,后续结果无法展示给用户 |
| 10015 | appid在黑名单中 |
| 10016 | appid授权类的错误。比如:未开通此功能,未开通对应版本,token不足,并发超过授权 等等 |
| 10017 | 清除历史失败 |
| 10019 | 表示本次会话内容有涉及违规信息的倾向;建议开发者收到此错误码后给用户一个输入涉及违规的提示 |
| 10110 | 服务忙,请稍后再试 |
| 10163 | 请求引擎的参数异常 引擎的schema 检查不通过 |
| 10222 | 引擎网络异常 |
| 10907 | token数量超过上限。对话历史+问题的字数太多,需要精简输入 |
| 11200 | 授权错误:该appId没有相关功能的授权 或者 业务量超过限制 |
| 11201 | 授权错误:日流控超限。超过当日最大访问量的限制 |
| 11202 | 授权错误:秒级流控超限。秒级并发超过授权路数限制 |
| 11203 | 授权错误:并发流控超限。并发路数超过授权路数限制 |
详见服务说明

若有收获,就点个赞吧
0 人点赞
