- 向量脉络最近更新了什么 #6">向量脉络最近更新了什么 #6
- 向量脉络最近更新了什么 #6">向量脉络最近更新了什么 #6
向量脉络最近更新了什么 #6
毕by 毕老师
2024/4/26 02:28:57向量脉络最近更新了什么 #6
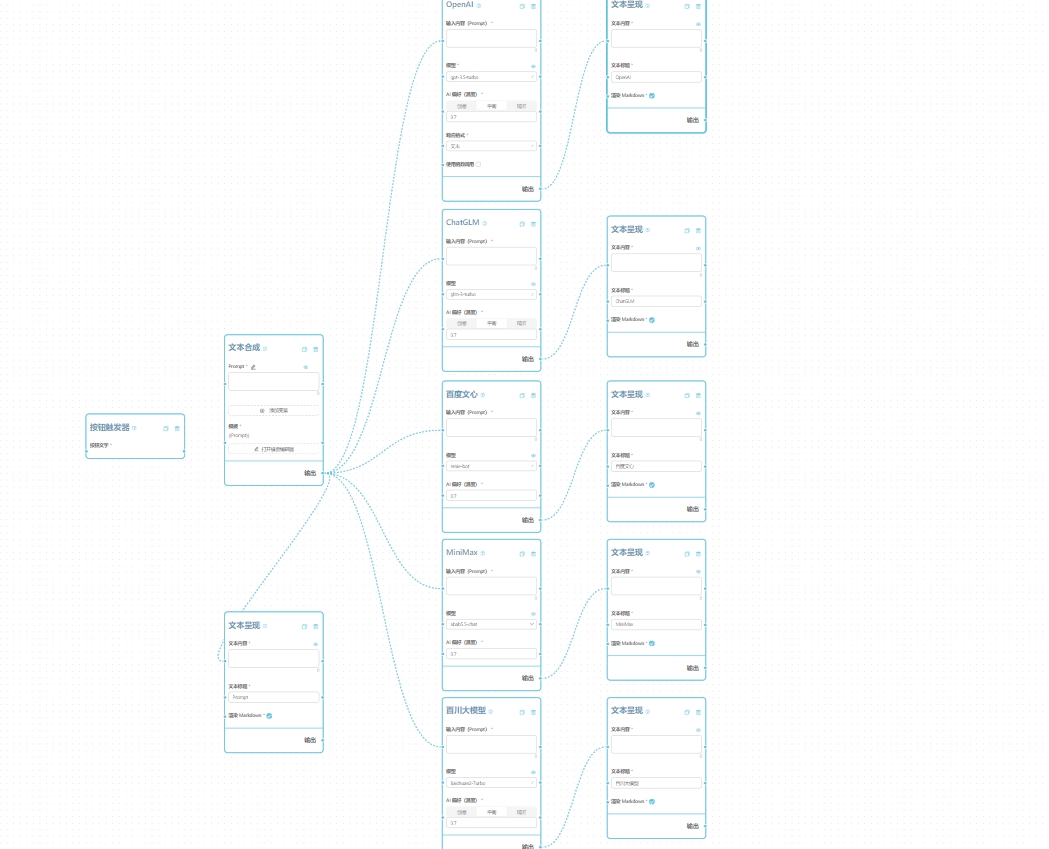
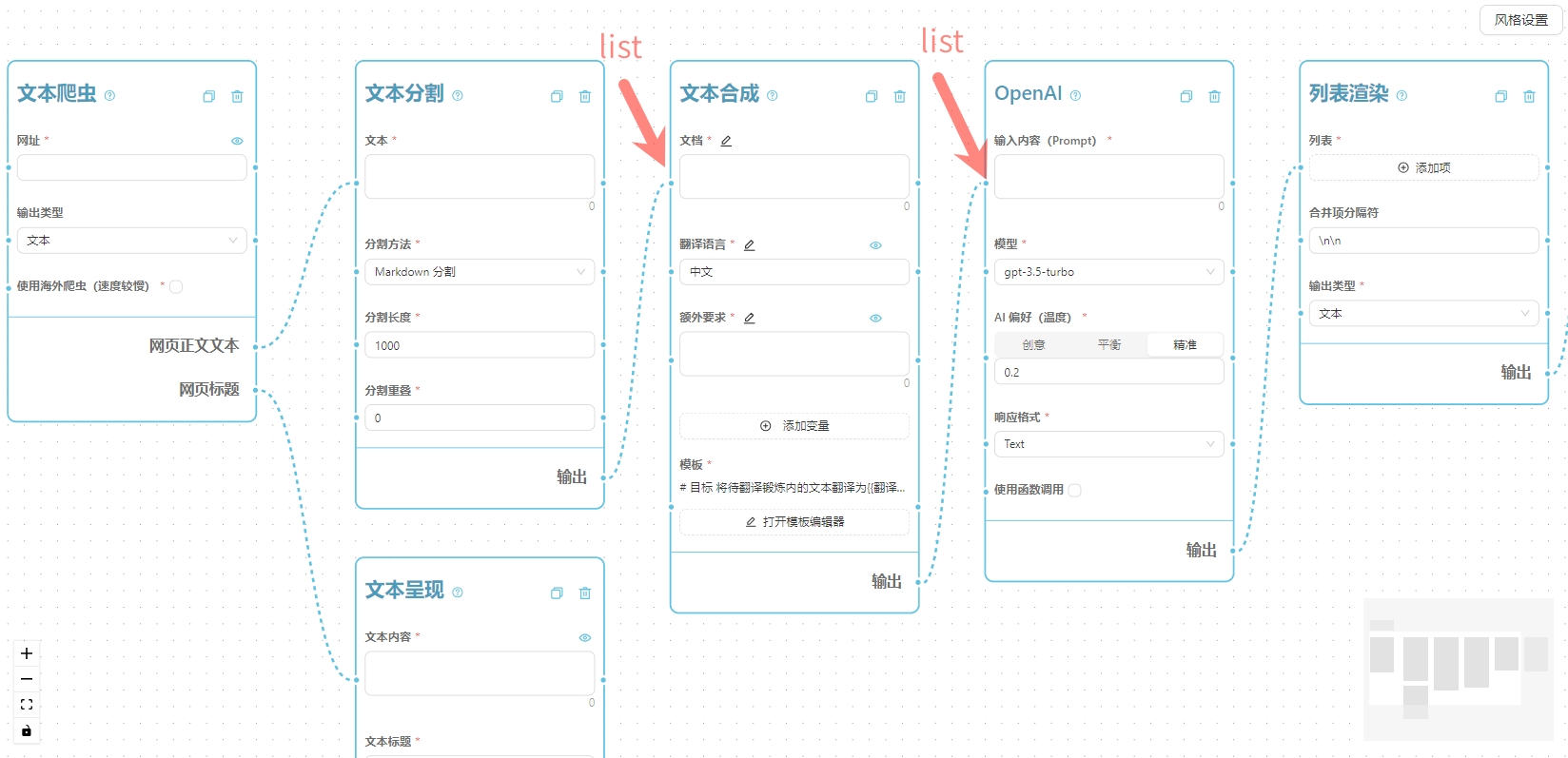
朋友们好!本次除了介绍新功能以外,我还给大家准备了一个 🎁** 重磅福利**,详情请看文末。 最大的更新也和福利一起放在最后了。🔀 工作流节点自动并发处理
大约三周前开始,我已经给工作流运行机制做了一个升级,对大家设计的工作流中存在的可以并行处理的节点,系统会自动进行并发处理,而不是像以前一样严格按照拓扑排序后的结果每个节点依次执行,这样可以大大提高工作流的执行效率。简单的原理可以看下面的示意动画。



⏩ 工作流节点数据提前返回
现在开始,工作流中已经完成的节点会提前返回数据,如果使用界面的输出部分有呈现,那么您将能够看到提前返回的结果。例如下图所示的界面,节点 1 已经完成,节点 2 还在运行中,但是我们可以提前看到节点 1 的结果。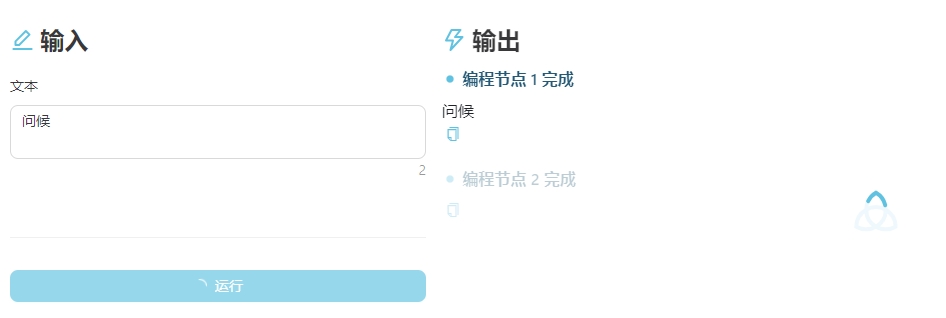
⛔ 支持强制停止工作流
现在对于正在运行中的工作流,您可以在运行记录中对其进行强制停止,工作流会在下一个节点开始前终止。
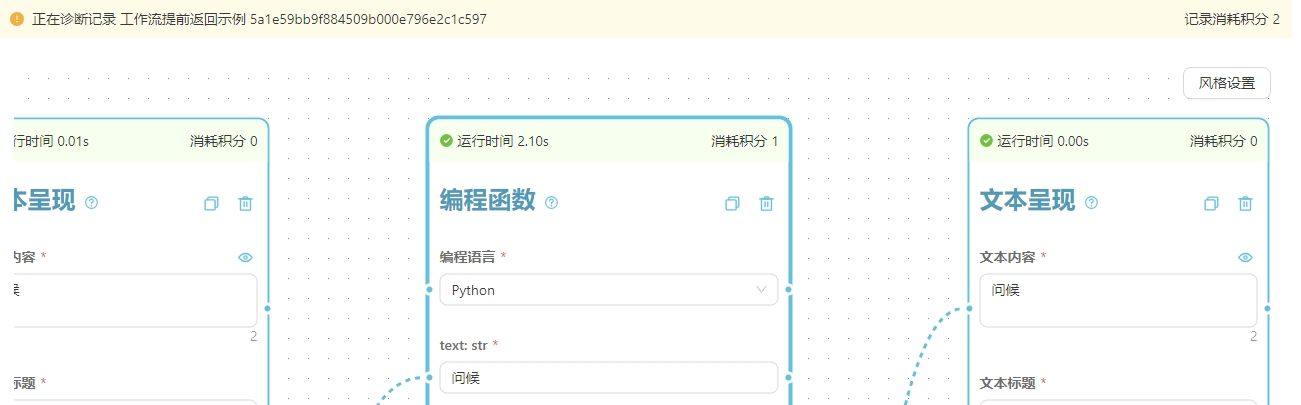
🔎 增加对工作流运行记录的诊断功能
现在可以对已经完成的工作流进行诊断,不管是成功运行还是运行失败的记录都可以点进去查看具体运行情况。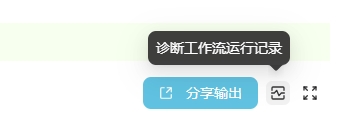
📦 增加 .zip 文件的读取
现在除了普通文档以外,您可以上传 .zip 文件,系统会自动解压并读取其中的文件,例如下图中上传了一个 .zip 文件,系统解压后读取了包含子文件夹的所有文本类文件。 文件夹结构:- doc1.md
- doc2.md
- sub-path - doc3.md
- doc1.md
- doc2.md
- sub-path/doc3.md
🤖 增加 gemini-1.5-pro 模型,支持 100万 token 输入
现在 Gemini 模型节点里可以选择 gemini-1.5-pro 模型,支持 100 万 token 输入,这样您可以输入更长的文本进行处理。 说实话我个人是比较看重超长文输入的,因为代码项目很容易就超过 10 万字长度,而且有时候需要对整个项目进行分析,这时候就需要一个支持超长文本输入的模型。 实践中我已经用 Gemini-1.5-Pro 模型处理了好几个项目分析甚至是代码生成的需求了,整体来说效果不错,能够相对全面地针对某一项功能找到不同文件中的关键代码,然后再根据需求进行修改。示例1 分析有道 QAnything 项目
这个示例中我们要求 Gemini 分析有道的 QAnything 并回答问题:我要修改哪些文件的代码才能把项目的 MySQL 数据库调整为 SQLite 数据库?务必列出所有相关文件路径以及需要修改的位置的完整代码。 运行结果:Gemini 分析 QAnything ### 示例2 分析向量脉络开源项目增加一个节点 这个示例中我们让 Gemini 增加了 Mistral AI 的大语言模型节点,Gemini 完整地找到了前后端对应的文件代码并提出了新增方法。 运行结果:Gemini 读项目代码并新增 —- 需要注意的是,即便能够接受 100 万输入,很多时候代码项目中存在一些非代码逻辑性的文件,比如 token 词表、node_modules、svg 图片、压缩后的 CSS 样式表等等,这些文件一般来说对我们的分析起不到什么帮助还会轻松占用大量输入(甚至一不小心就让整个项目超过 100 万长度了),所以强烈建议在使用前先检查一下项目代码的总长度。我在这里做了一个简单的工作流帮你计算 .zip 文件中的文档内容长度。 有的朋友可能担心积分消耗问题,目前 Gemini-1.5-Pro 模型的消耗我设定是 0.5 积分/1000 token,非常非常低的价格,主要为了让大家尝试一下。而与之对应的是我针对每个用户做了 Gemini-1.5-Pro 的模型请求量限制,避免大家滥用这个模型。但是由于 Google 那边的限制,也很难保证每次都能一定能正常运行。✨ 其它功能更新和调整
- Email 节点支持附件(网址类型)
- Agent 聊天积分调整
🎊 重磅更新:会员体系上线
向量脉络会员体系正式上线!根据日常使用场景我设计了三种会员: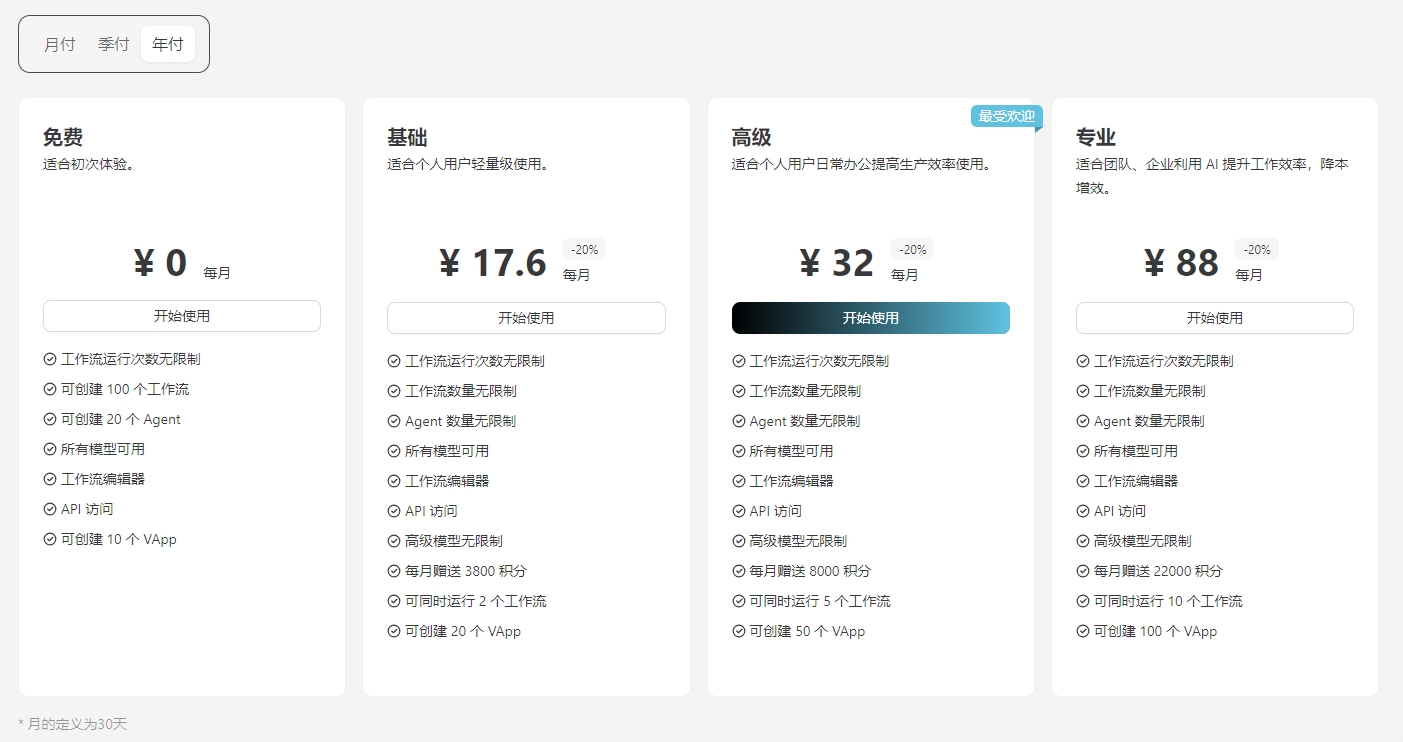
各版本详情查看戳这里 **👉** 会员体系详情介绍
这是初步的会员方案,后续可能会根据运行情况进行一定的调整。 为了感谢各位早期支持者一直以来的支持和信任,只要你收到了本邮件,你都可以打开链接 👉 点这里兑换福利 👈 点击礼物按钮直接兑换一个月的会员。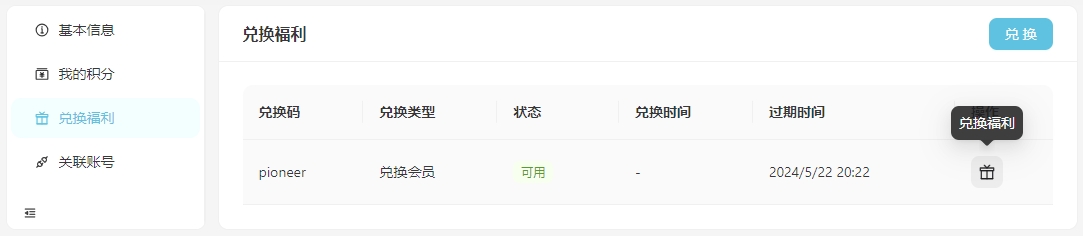
感谢你的支持!有兴趣的朋友可以加到内测群里来一起玩,添加我的企业微信二维码:

若有收获,就点个赞吧
0 人点赞
