快速排序的特点就是快,而且效率高!它是处理大数据最快的排序算法之一。
动画
实现
思想
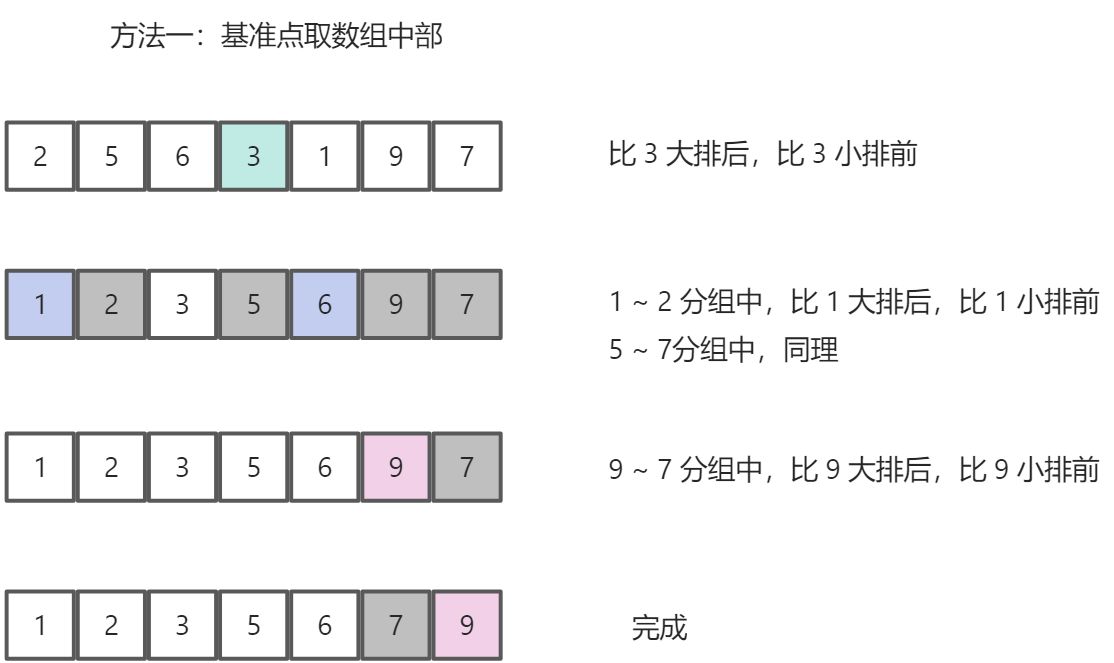
- 先找到一个基准点(一般指数组的中部),然后数组被该基准点分为两部分,依次与该基准点数据比较,如果比它小,放左边;反之,放右边。
- 左右分别用一个空数组去存储比较后的数据。
- 最后递归执行上述操作,直到数组长度 <= 1;
特点:快速,常用。
缺点:需要另外声明两个数组,浪费了内存空间资源。
真很常用,回想日常,体育课之类的,按身高排序,我们都会先找一个基准,再逐一比较,放左放右。 然后缩小区间,取基准,比较后,放左放右,直到完成。 只不过我们基准有时找的很随意,不固定,排着排着就不是快排了。
const array = [3, 44, 38, 5, 47, 15, 36, 26, 27, 46, 4, 19, 50, 48];const quickSort = (arr) => {if (arr.length < 2) return arr;// 取基准点const midIndex = Math.floor(arr.length / 2);const [midValue] = arr.splice(midIndex, 1);const left = []; // 存放比基准点小的数const right = [];// 存放比基准点大的数// 遍历数组,判断第 i 项与基准点的大小关系,进行分配for (let i = 0; i < arr.length; i++) {if (arr[i] < midValue) {left.push(arr[i]);} else {right.push(arr[i]);}}return [...quickSort(left), midValue, ...quickSort(right)];}const newArray = quickSort(array)console.log(newArray); // [3, 4, 5, 15, 19, 26, 27, 36, 38, 44, 46, 47, 48, 50]
方法一,需要创建新的数组,如果我们想要在原数组进行排序,我们可以采用方法二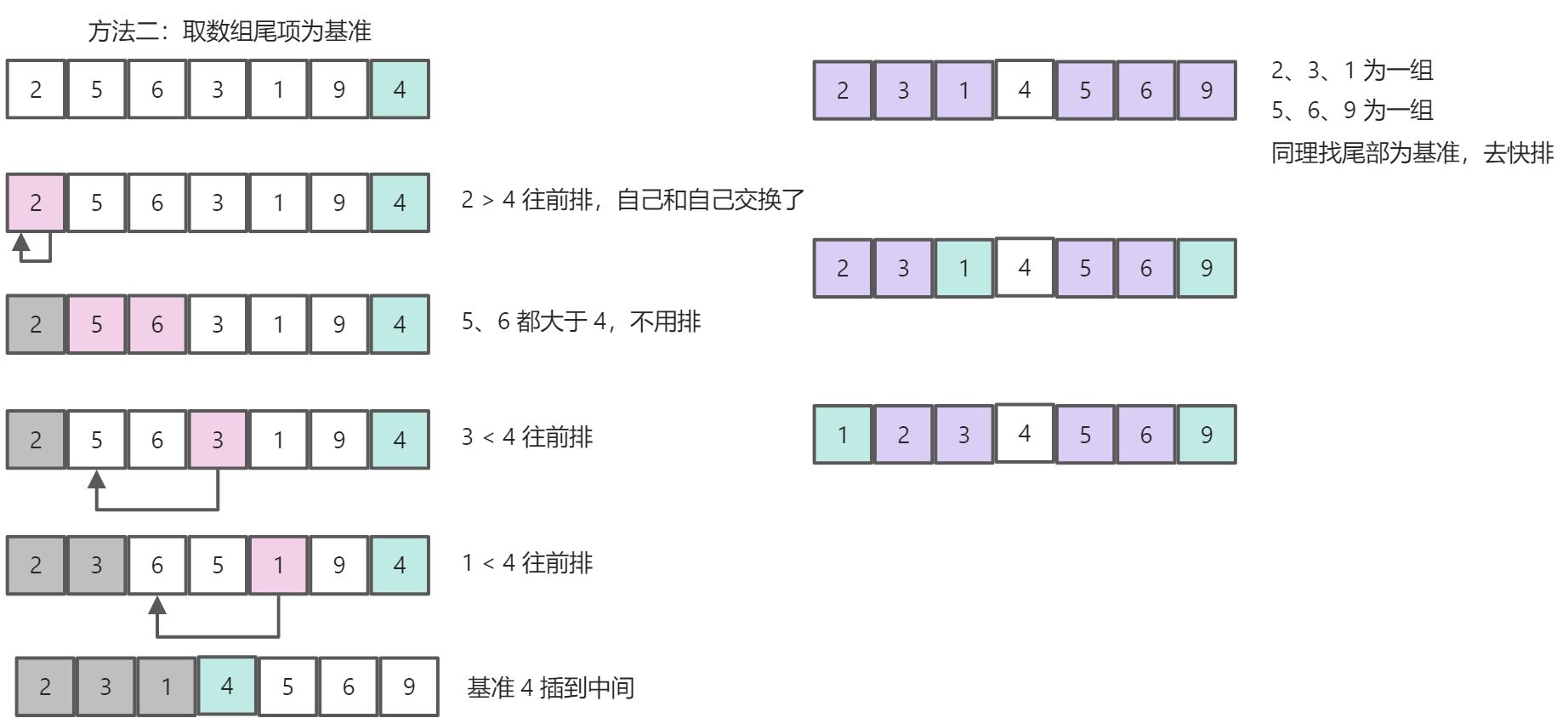
const array = [3, 44, 38, 5, 47, 15, 36, 26, 27, 46, 4, 19, 50, 48];// 交换数组的值const swap = (arr, i, j) => {const temp = arr[i];arr[i] = arr[j];arr[j] = temp;}// 分治:以尾部的基准,遍历排序,并返回基准的新位置const partition = (arr, left, right) => {const pivot = arr[right];let j = left;for (let i = left; i < right; i++) {if (arr[i] <= pivot) {swap(arr, i, j);j++}}swap(arr, j, right);return j;}const quickSort = (arr, left, right) => {const len = arr.length;left = typeof left === 'number' ? left : 0;right = typeof right === 'number' ? right : len - 1;// 递归退出的条件if (right - left < 1) return arr;const pivotIndex = partition(arr, left, right);quickSort(arr, left, pivotIndex - 1);quickSort(arr, pivotIndex + 1, right)}quickSort(array)console.log(array); // [3, 4, 5, 15, 19, 26, 27, 36, 38, 44, 46, 47, 48, 50]
分析
- 第一,快速排序是原地排序算法吗 ?
因为partition()函数进行分区时,不需要很多额外的内存空间,所以快排是原地排序算法。 - 第二,快速排序是稳定的排序算法吗 ?
和选择排序相似,快速排序每次交换的元素都有可能不是相邻的,因此它有可能打破原来值为相同的元素之间的顺序。因此,快速排序并不稳定。 第三,快速排序的时间复杂度是多少 ?
极端的例子:如果数组中的数据原来已经是有序的了,比如 1,3,5,6,8。如果我们每次选择最后一个元素作为 pivot,那每次分区得到的两个区间都是不均等的。我们需要进行大约 n 次分区操作,才能完成快排的整个过程。每次分区我们平均要扫描大约 n / 2 个元素,这种情况下,快排的时间复杂度就从 O(nlogn) 退化成了 O(n^2)。
最佳情况:T(n) = O(nlogn)。
最差情况:T(n) = O(n^2)。
平均情况:T(n) = O(nlogn)。快速排序与归并排序的区别
快排和归并用的都是分治思想,递推公式和递归代码也非常相似,那它们的区别在哪里呢 ?
可以发现:归并排序的处理过程是由下而上的,先处理子问题,然后再合并。
- 而快排正好相反,它的处理过程是由上而下的,先分区,然后再处理子问题。
- 归并排序虽然是稳定的、时间复杂度为 O(nlogn) 的排序算法,但是它是非原地排序算法。
- 归并之所以是非原地排序算法,主要原因是合并函数无法在原地执行。
- 快速排序通过设计巧妙的原地分区函数,可以实现原地排序,解决了归并排序占用太多内存的问题。

若有收获,就点个赞吧
0 人点赞
