双工流就是同时实现了 Readable 和 Writable 的流,即可以作为上游生产数据,又可以作为下游消费数据,这样可以处于数据流动管道的中间部分,即
rs.pipe(rws1).pipe(rws2).pipe(rws3).pipe(ws);
在 NodeJS 中双工流常用的有两种
- Duplex
-
Duplex
实现 Duplex
和 Readable、Writable 实现方法类似,实现 Duplex 流非常简单,但 Duplex 同时实现了 Readable 和 Writable, NodeJS 不支持多继承,所以我们需要继承 Duplex 类
继承 Duplex 类
- 实现 _read() 方法
- 实现 _write() 方法
相信看过前面章节后对 _read()、_write() 方法的实现不会陌生,和 Readable、Writable 完全一样
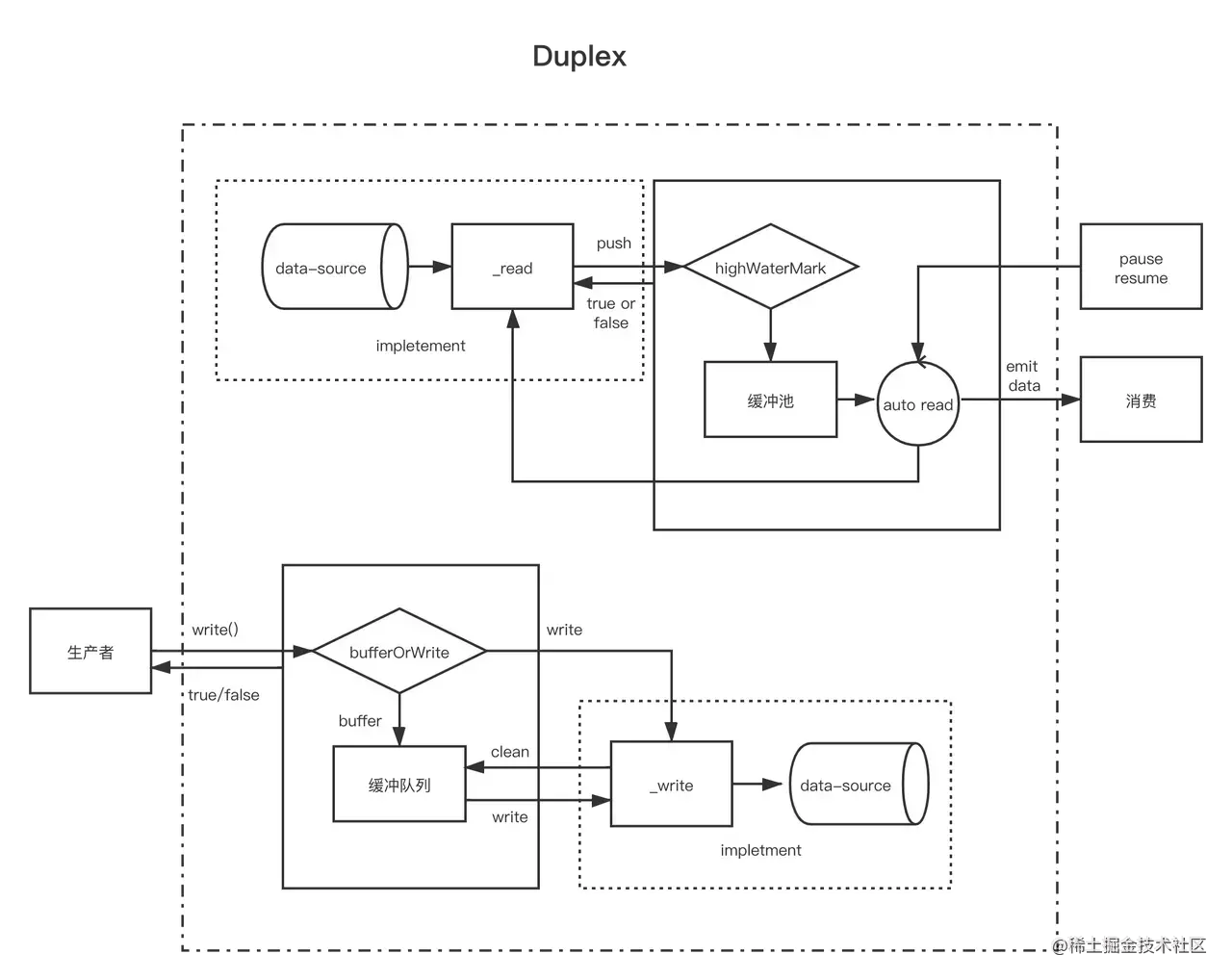
自定义 Duplex 有三种写法
const { Duplex } = require('stream');class MyDuplex extends Duplex {constructor(options) {super(options);// ...}}
const { Duplex } = require('stream');const util = require('util');function MyDuplex(options) {if (!(this instanceof MyDuplex)) return new MyDuplex(options)Duplex.call(this, options);}util.inherits(MyDuplex, Duplex);
const { Duplex } = require('stream')const myDuplex = new Duplex({read(size) {// ...},write(chunk, encoding, callback) {// ...}})
构造函数参数
Duplex 实例内同时包含可读流和可写流,在实例化 Duplex 类的时候可以传递几个参数
readableObjectMode <Boolean>: 可读流是否设置为 ObjectMode,默认 falsewritableObjectMode <Boolean>: 可写流是否设置为 ObjectMode,默认 falseallowHalfOpen <Boolean>: 默认 true, 设置成 false 的话,当写入端结束的时,流会自动的结束读取端
小例子
了解了 Readable 和 Writable 之后看 Duplex 非常简单,直接用一个官网的例子
当然这是不能执行的伪代码,但是 Duplex 的作用可见一斑,进可以生产数据,又可以消费数据,所以才可以处于数据流动管道的中间环节,Node.js 中常见的 Duplex 流有
- Tcp Scoket
- Zlib
- Crypto ```javascript const Duplex = require(‘stream’).Duplex; const kSource = Symbol(‘source’);
class MyDuplex extends Duplex { constructor(source, options) { super(options); this[kSource] = source; }
_write(chunk, encoding, callback) { // The underlying source only deals with strings if (Buffer.isBuffer(chunk)) chunk = chunk.toString(); this[kSource].writeSomeData(chunk); callback(); }
_read(size) { this[kSource].fetchSomeData(size, (data, encoding) => { this.push(Buffer.from(data, encoding)); }); } }
<a name="zwqZG"></a># TransformTransform 同样是双工流,看起来和 Duplex 重复了,但两者有一个重要的区别:1. Duplex 虽然同时具备可读流和可写流,但两者是相对独立的;2. Transform 的可读流的数据会经过一定的处理过程自动进入可写流虽然会从可读流进入可写流,但并不意味这两者的数据量相同,上面说的一定的处理逻辑会决定如果 tranform 可读流,然后放入可写流,transform 原义即为转变,很贴切的描述了 Transform 流作用最常见的压缩、解压缩用的 zlib 即为 Transform 流,压缩、解压前后的数据量明显不同,而流的作用就是输入一个 zip 包,输出一个解压文件或反过来。我们平时用的大部分双工流都是 Transform。<br />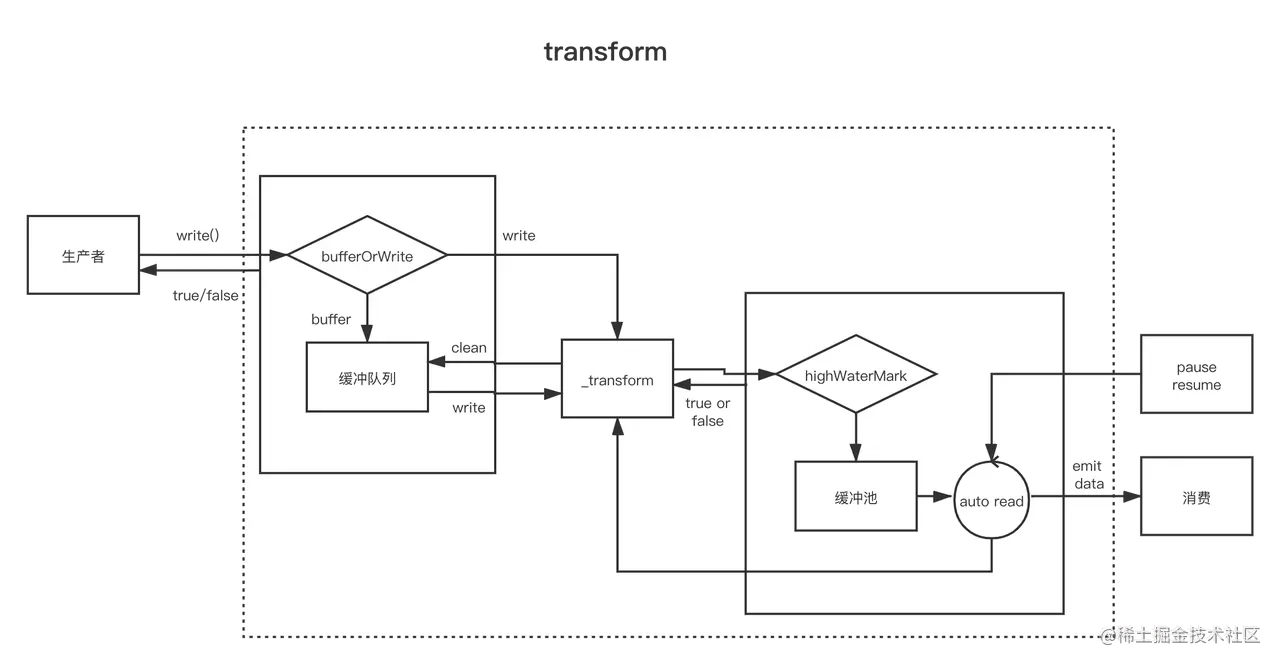<a name="TdgGc"></a>## 实现 TransformTranform 类内部继承了 Duplex 并实现了 `writable.write()` 和 `readable._read()` 方法,自定义一个 Transform 流,只需要三个步骤1. 继承 Transform 类2. 实现 _transform() 方法3. 实现 _flush() 方法(可以不实现):::warning`_transform(chunk, encoding, callback)` 方法用来接收数据,并产生输出,参数我们已经很熟悉了,和 Writable 一样, chunk 默认是 Buffer,除非 decodeStrings 被设置为 false在 `_transform()` 方法内部可以调用 `this.push(data)` 生产数据,交给可写流,也可以不调用,意味着输入不会产生输出当数据处理完了必须调用 `callback(err, data)`,第一个参数用于传递错误信息,第二个参数可以省略,如果被传入了,效果和 `this.push(data)` 一样:::```haskelltransform.prototype._transform = function (data, encoding, callback) {this.push(data);callback();};transform.prototype._transform = function (data, encoding, callback) {callback(null, data);};
有些时候,transform 操作可能需要在流的最后多写入可写流一些数据。例如, Zlib流会存储一些内部状态,以便优化压缩输出。在这种情况下,可以使用 _flush() 方法,它会在所有写入数据被消费、触发 end之前被调用
自定义 Duplex 有三种写法
const { Transform } = require('stream');class MyTransform extends Transform {constructor(options) {super(options);// ...}}
const { Transform } = require('stream');const util = require('util');function MyTransform(options) {if (!(this instanceof MyTransform)) return new MyTransform(options)Transform.call(this, options);}util.inherits(MyTransform, Transform);
const { Transform } = require('stream');const myTransform = new Transform({transform(chunk, encoding, callback) {// ...}});
Transform 的事件
Transform 流有两个常用的事件
- 来自 Writable 的 finish
- 来自 Readable 的 end
当调用 transform.end() 并且数据被 _transform() 处理完后会触发 finish,调用_flush后,所有的数据输出完毕,触发 end 事件
回顾初始 Stream 的例子
如果有个需求,把本地一个 package.json 文件中的所有字母都改为大写,并保存到同目录下的 package-upper.json 文件下
这时候就需要用到双向的流了,假定有一个专门处理字符转大写的流 toUppercase
const fs = require('fs')const rs = fs.createReadStream('./package.json')const ws = fs.createWriteStream('./package-upper.json')const { Transform } = require('stream');// 所有转换流也是双工流。const toUpperCase = new Transform({writableObjectMode: true,transform(chunk, encoding, callback) {const str = cahunk.toString()const source = JSON.parse(str)const data = {}for (let key of Object.keys(source)) {const val = source[key]key = key[0].toUpperCase() + key.substring(1)data[key] = val}// 将数据推送到可读队列中。callback(null, JSON.stringify(data));}});rs.pipe(toUpperCase).pipe(ws)
const fs = require('fs')const rs = fs.createReadStream('./package.json')const ws = fs.createWriteStream('./package-upper.json')const { Duplex } = require('stream');class ToUpperCase extends Duplex {constructor(options) {super(options)this.source = Buffer.alloc(0)}_read(size) {}_write(chunk, encoding, callback) {this.source = Buffer.concat([this.source, chunk])const str = this.source.toString()const source = JSON.parse(str)const data = {}for (let key of Object.keys(source)) {const val = source[key]key = key[0].toUpperCase() + key.substring(1)data[key] = val}this.push(JSON.stringify(data))callback()}}const toUpperCase = new ToUpperCase()rs.pipe(toUpperCase).pipe(ws)

若有收获,就点个赞吧
0 人点赞
