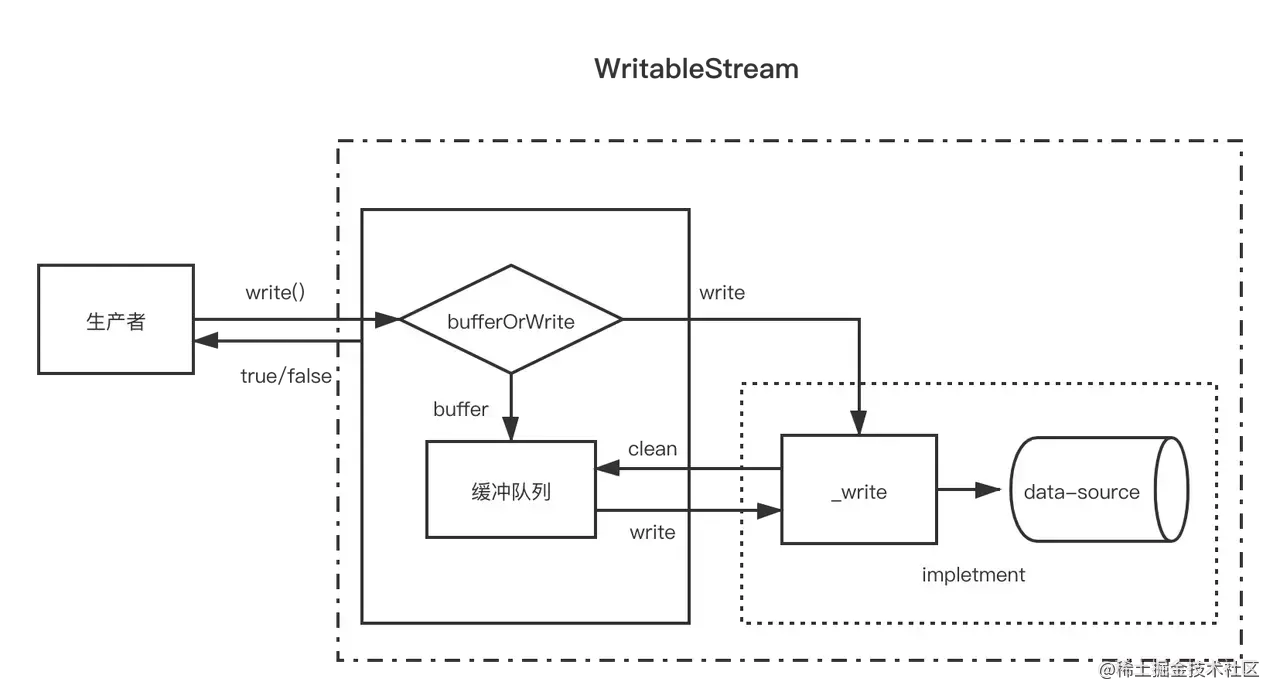
什么是可写流
可写流是对数据流向设备的抽象,用来消费上游流过来的数据,通过可写流程序可以把数据写入设备,常见的是本地磁盘文件或者 TCP、HTTP 等网络响应。看一个之前用过的例子
process.stdin.pipe(process.stdout)
process.stdout 是一个可写流,程序把可读流 process.stdin 传过来的数据写入的标准输出设备。在了解了可读流的基础上理解可写流非常简单,流就是有方向的数据,其中可读流是数据源,可写流是目的地,中间的管道环节是双向流。
可写流的使用
之前我们学过 fs 模块的一个 API fs.createWriteStream,它就是基于 Node 可写流进行文件写入的封装类。
- path(
string | buffer | url):数据来源 options(
string | object)- flags(
string)读取还是写入。默认值w - fd(
integer | fileHadnle):默认值null - mode(
integer):默认值0o666 - autoClose(
boolean):默认值true - emitClose(
boolean) :默认值true - start(
integer):从文件的第几个字符开始写入,默认值 0 - fs(
object | null):默认值null - highWaterMark(
Number):水平线,默认值:16384(16kb)或16表示objectMode流
可写流实例的const ws = fs.createWriteStream(path[, options]) // 该方法将返回一个可写流的实例
write()方法,可以用来把数据写入流
- flags(
**write()**方法有三个参数- chunk {String| Buffer},表示要写入的数据
- encoding 当写入的数据是字符串的时候可以设置编码,默认
utf-8 - callback 数据被写入之后的回调函数
**write()**方法的返回值,是布尔值- 当接受要写入的数据后,内部缓冲区 < 创建流时分配的 highWaterMark,则返回 true
- 当接受要写入的数据后,内部缓冲区 >= 创建流时分配的 highWaterMark,则返回 false,且不再将数据写入流,直到触发可写流的
drain事件
const fs = require('fs')const writeStream = fs.createWriteStream('./test.txt')let flag = writeStream.write('1234567890好\n', () => console.log('第一次数据流入'))flag = writeStream.write('abcdefghijklmnopqrstuvwxyz好\n', 'utf-8', () => console.log('第二次数据流入'))flag = writeStream.write('ABCDEFGHIJKLMNOPQRSTUVWXYZ好\n', 'ASCII', () => console.log('第三次数据流入'))
上述代码创建了可写流,每一次写入的数据,就像一部分水流,流入test.txt文件中。
上述代码执行后,test.txt会变成下面这样。
1234567890好abcdefghijklmnopqrstuvwxyz好ABCDEFGHIJKLMNOPQRSTUVWXYZ}
上文说到的 highWater,我们写个 demo 感受一下。下面代码把 0123456789写入 test.txt 文件中。
while 循环中,writeStream.write() 是同步调用的,而文件 I/O 是异步的,Node 怎么保证写入的数据的有序的呢?—— Node 使用了链表来作为缓冲区
第一次
writeStream.write()时,直接写入,writeStream内部的状态writing设置为 trueNode 源码中,为 WriteStream 创建的实例,维护一些状态
state,其中writing表示正在写入第二次
writeStream.write()时,由于writing为 true,将写入的值压入缓冲区- 第三、四、五次,都会压入缓冲区,此时缓冲区长度为 4
- 缓冲区长度,即 buffer 的总长度。即使传入字符串,Node 内部也会转成 buffer
- 第六次,如果再将数据压入缓冲区,那么就等于 highWaterMark 了。所以不会压入缓冲区
- Node 源码是要求 buffer 总长度小于 highWaterMark
- 第七八九十次,也不会把数据压入缓冲区。
- 当缓冲区的数据一个一个的被写入
test.txt完成后,会触发drain事件 - 我们在
drain事件中重新调用 handle,写入56789```javascript const fs = require(‘fs’) const writeStream = fs.createWriteStream(‘./test.txt’, { highWaterMark: 5 } ) let i = 0; const handle = () => { let flag = true while (i < 10 && flag) { flag = writeStream.write(‘’ + i++) } } handle()
// 抽干事件 writeStream.on(‘drain’, () => { handle() console.log(‘ok’) })
<a name="hvbdp"></a># 自定义可写流> Node 提供的 Stream 模块,可以让我们自定义可读流、可写流、双工流。和自定义可读流类似,简单的自定义可写流只需要两步1. 继承 stream 模块的 **Writable** 类2. 实现 **_write()** 方法用个简单例子演示可写流实现,把传入可写流的数据转成大写之后输出到标准输出设备 stdout```javascriptconst { Writable } = require('stream')class OutputStream extends Writable {_write(chunk, encoding, done) {// 转大写之后写入标准输出设备process.stdout.write(chunk.toString().toUpperCase());// 此处不严谨,应该是监听写完之后才调用 doneprocess.nextTick(done);}}module.exports = OutputStream
和最终可写流暴露出来的 write() 方法一样, _write() 方法有三个参数,作用类似
- chunk 写入的数据,大部分时候是 buffer,除非 decodeStrings 被设置为 false
- encoding 如果数据是字符串,可以设置编码,buffer 或者 object 模式会忽略
- callback 数据写入后的回调函数,可以通知流传入下一个数据;当出现错误的时候也可以设置一个 error 参数
除了在流实现中的 _write() 之外,还可以实现 _writev() 方法,一次处理多个数据块,这个方法用于被滞留的数据写入队列调用,可以不实现
实例化可写流
有了可写流的类之后可以实例化使用了,实例化可写流的时候有几个 option 可选,了解一下接下来要用到的三个核心 options
**objectMode** <Boolean>默认是 false- 设置成 true 后 writable.write() 方法除了写入 string 和 buffer 外,还可以写入任意 JavaScript 对象。
- 很有用的一个选项,后面介绍 transform 流的时候详细介绍
**highWaterMark** <Number>每次最多写入的数据量,- Buffer 的时候默认值 16kb
- objectMode 时默认值 16
**decodeStrings** <Boolean>是否把传入的数据转成 Buffer,默认是 true
这样就更清楚的知道 _write() 方法传入的参数的含义了,而且对后面介绍 back pressure 机制的理解很有帮助
事件
和可读流一样,可写流也有几个常用的事件,有了可读流的基础,理解起来比较简单
**pipe**当可读流调用 pipe() 方法向可写流传输数据的时候会触发可写流的 pipe 事件**unpipe**当可读流调用 unpipe() 方法移除数据传递的时候会触发可写流的 unpipe 事件这两个事件用于通知可写流数据将要到来和将要被切断,在通常情况下使用的很少
:::info
writeable.write() 方法是有一个 boolean 的返回值的,前面提到了 highWaterMark,当要求写入的数据大于可写流的 highWaterMark 的时候,数据不会被一次写入,有一部分数据被滞留,这时候 writeable.write() 就会返回 false,如果可以处理完就会返回 true
:::
**drain**当之前存在滞留数据,也就是writeable.write()返回过 false,经过一段时间的消化,处理完了积压数据,可以继续写入新数据的时候触发(drain 的本意即为排水、枯竭,挺形象的) :::info 除了 write() 方法可写流还有一个常用的方法 end(),参数和 write() 方法相同,但也可以不传入参数,表示没有其它数据需要写入,可写流可以关闭了 :::**finish**当调用writable.end()方法,并且所有数据都被写入底层后会触发 finish 事件,**error**出现错误后会触发
back pressure
了解了这些事件,结合上之前提到的可读流的一些知识,就能探讨一些有意思的话题了。
前面章节提到过用流相对于直接操作文件的好处之一是不会把内存压爆,那么流是怎么做到的呢?
很容易联想到流不是一次性把所有数据载入内存处理,而是一边读一边写。
但一般数据读取的速度会远远快于写入的速度,那么 pipe() 方法是怎么做到供需平衡的呢?主要靠以下三个要点
- 可读流有流动和暂停两种模式,可以通过 pause() 和 resume() 方法切换
- 可写流的 write() 方法会返回是否能处理当前的数据,每次可以处理多少是 highWatermark 决定的
- 当可写流处理完了积压数据会触发 drain 事件
可以利用这三点来做到数据读取和写入的同步,还是使用之前的例子,但为了使消费速度降下来,刻意隔一秒再通知完成
const { Writable } = require('stream')class OutputStream extends Writable {_write(chunk, enc, done) {// 转大写之后写入标准输出设备process.stdout.write(chunk.toString().toUpperCase())// 故意延缓通知继续传递数据的时间,造成写入速度慢的现象setTimeout(done, 1000)}}module.exports = OutputStream
使用一下自定义的两个类,每 100 ms 生产出一个随机数,通过 OutputStream 将随机数输出到控制台。
const RandomNumberStream = require('./RandomNumberStream');const OutputStream = require('./OutputStream');const rns = new RandomNumberStream(100);const os = new OutputStream({highWaterMark: 8 // 把水平线降低,默认 16k 还是挺大的});rns.on('data', chunk => {// 当待处理队列大于 highWaterMark 时返回 falseif (os.write(chunk) === false) {console.log('pause');rns.pause(); // 暂停数据读取}});// 当待处理队列小于 highWaterMark 时触发 drain 事件os.on('drain', () => {console.log('drain')rns.resume(); // 恢复数据读取});
结合前面的三点和注释很容易看懂上面代码,这就是 pipe() 方法起作用的核心原理,官方教程中也有对 back presure 机制的详细讲解
对数据的来源的去向有了大概了解,就可以学习使用双向流对数据进行加工了
- duplex
- transform

若有收获,就点个赞吧
0 人点赞
