可读流是生产数据用来供程序消费的流。
常见的数据生产方式有读取磁盘文件、读取网络请求内容等,看一下前面介绍什么是流用的例子:
const rs = fs.createReadStream(filePath);
rs 就是一个可读流,其生产数据的方式是读取磁盘的文件,控制台 process.stdin 也是一个可读流:
process.stdin.pipe(process.stdout);
通过简单的一句话可以把控制台的输入打印出来,process.stdin 生产数据的方式是读取用户在控制台的输入。
回头再看一下对可读流的定义:可读流是生产数据用来供程序消费的流。
自定义可读流
如果希望自己以某种特定的方式生产数据,交给程序消费,那么改如何开始呢?
简单两步即可
- 继承 stream 模块的 Readable 类
- 重写 _read 方法,调用 this.push 将生产的数据放入待读取队列
Readable 类已经把可读流要做的大部分工作完成,只需要继承它,然后把生产数据的方式写在 _read 方法里就可以实现一个自定义的可读流。
举个例子:实现一个每 100 毫秒生产一个随机数的流(没什么用处)
const { Readable } = require('stream')class RandomNumberStream extends Readable {constructor(max) {super()}_read() {const ctx = thisconst timer = setTimeout(() => {const randomNumber = parseInt(Math.random() * 10000)ctx.push(randomNumber + '\n')clearTimeout(timer)}, 100)}}module.exports = RandomNumberStream
类继承部分代码很简单,主要看一下 _read 方法的实现,有几个值得注意的地方
- Readable 类中默认有 _read 方法的实现,不过什么都没有做,我们做的是覆盖重写
- _read 方法有一个参数 size,用来向 read 方法指定应该读取多少数据返回,不过只是一个参考数据,很多实现忽略此参数,我们这里也忽略了,后面会详细提到
- 通过 this.push 向缓冲区推送数据,缓冲区概念后面会提到,暂时理解为数据挤到了水管中,可消费了
- push 的内容只能是字符串或者 Buffer,不能是数字
- push 方法有第二个参数 encoding,用于第一个参数是字符串时指定 encoding
这样可以看到数字源源不断的显示到了控制台上,实现了一个产生随机数的可读流,还有几个小问题待解决const RandomNumberStream = require('./RandomNumberStream')const rns = new RandomNumberStream()rns.pipe(process.stdout)
如何停下来
每隔 100 毫秒向缓冲区推送一个数字,但就像读取一个本地文件总有读完的时候,如何标识数据读取完毕?
答:向缓冲区 push 一个 null 就可以,修改一下代码,允许消费者定义需要多少个随机数字: ```javascript const { Readable } = require(‘stream’)
class RandomNumberStream extends Readable { constructor(max) { super() this.max = max || 10 } _read() { const ctx = this const timer = setTimeout(() => { if (ctx.max) { const randomNumber = parseInt(Math.random() * 10000) ctx.push(randomNumber + ‘\n’) ctx.max -= 1 } else { ctx.push(null) } clearTimeout(timer) }, 100) } } module.exports = RandomNumberStream
<a name="YUGRD"></a># 为什么是 setTimeout 不是 setInterval细心的同学可能注意到,每隔 100 毫秒生产一个随机数并不是调用的 setInterval,而是使用的 setTimeout,为什么仅仅是延时了一下并没有重复生产,结果却是正确的呢?<br />这就需要了解流的两种工作方式1. 流动模式:数据由底层系统读出,并尽可能快地提供给应用程序2. 暂停模式:必须显示地调用 read() 方法来读取若干数据块流在默认状态下是处于暂停模式的,也就是需要程序显式的调用 read() 方法,可上面例子中并没有调用就可以得到数据,因为流通过 pipe() 方法切换成了流动模式,这样 _read() 方法会自动被反复调用,直到数据读取完毕,所以每次 _read() 方法里面只需要读取一次数据即可<a name="TMl2E"></a># 流动模式和暂停模式的切换流从默认的暂停模式切换到流动模式可以使用以下几种方式:1. 通过添加 data 事件监听器来启动数据监听2. 调用 resume() 方法启动数据流3. 调用 pipe() 方法将数据转接到另一个可写流从流动模式切换为暂停模式又两种方法:1. 在流没有 pipe() 时,调用 pause() 方法可以将流暂停2. pipe() 时移除所有 data 事件的监听,再调用 unpipe() 方法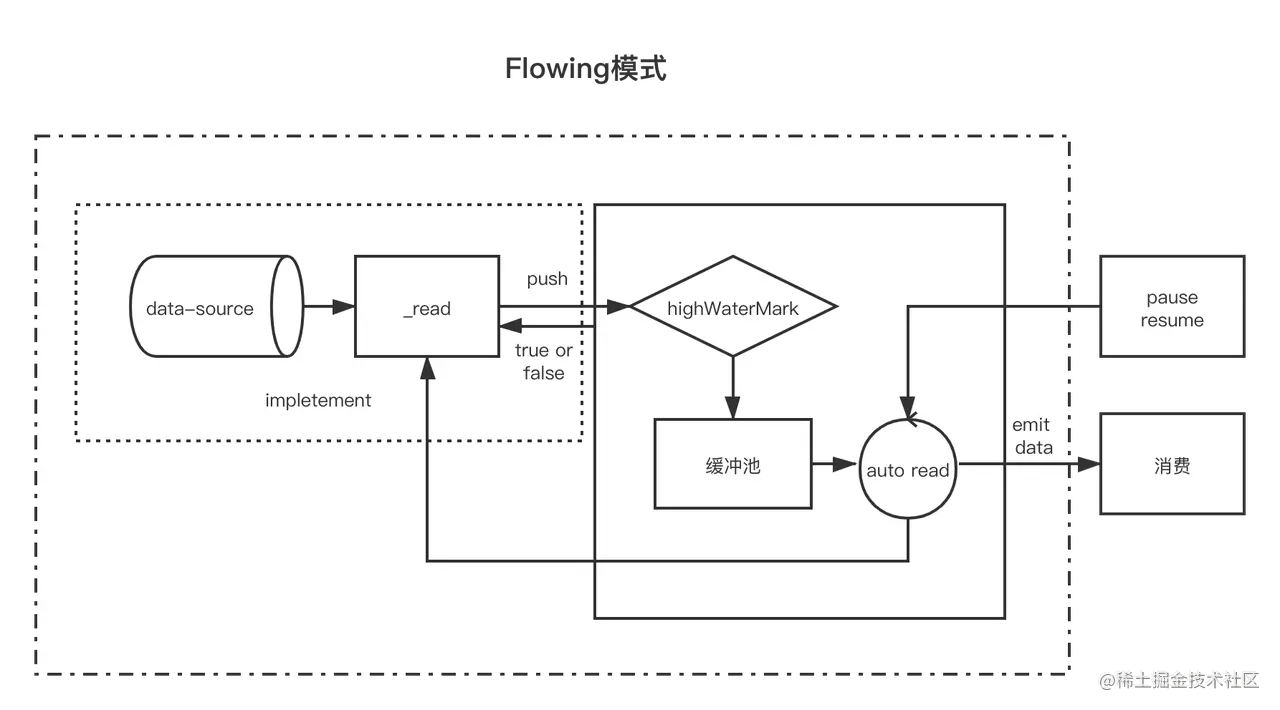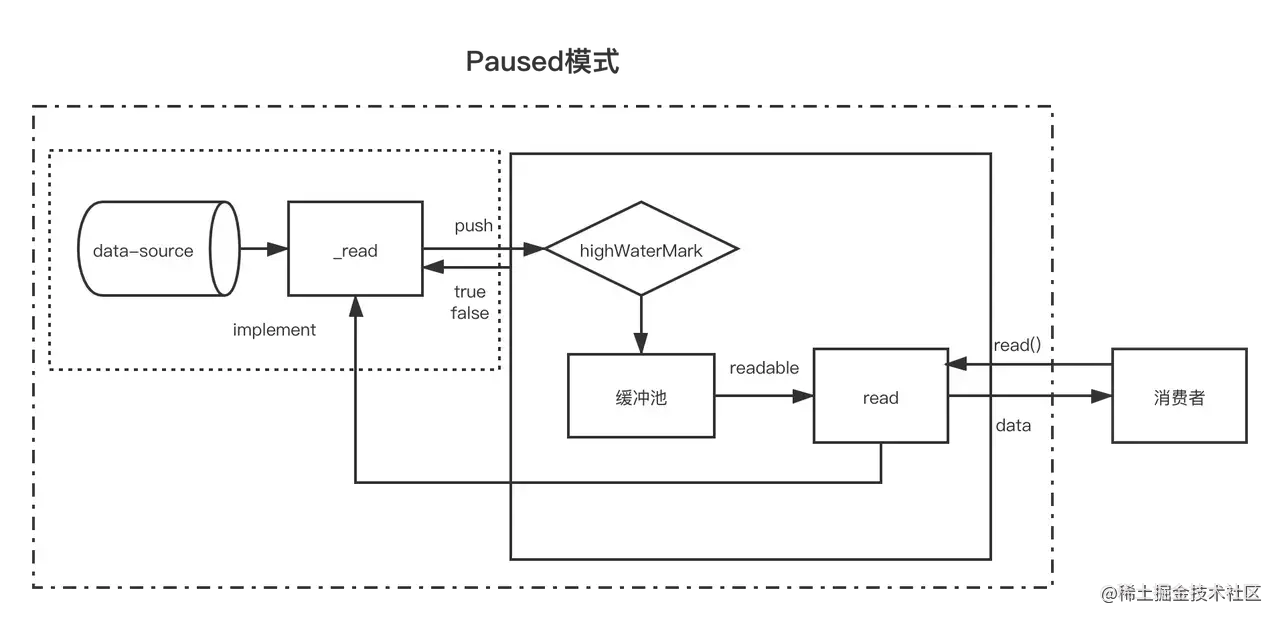<a name="ii6aJ"></a>## data 事件使用了 pipe() 方法后数据就从可读流进入了可写流,但对用户好像是个黑盒,数据究竟是怎么流向的呢?切换流动模式和暂停模式的时候有两个重要的名词1. 流动模式对应的 data 事件2. 暂停模式对应的 read() 方法这两个机制是程序能够驱动数据流动的原因,先来看一下流动模式 data 事件,一旦监听了可读流的 data 事件,流就进入了流动模式,可以改写一下上面调用流的代码```javascriptconst RandomNumberStream = require('./RandomNumberStream');const rns = new RandomNumberStream(5);rns.on('data', chunk => {console.log(chunk);});
<Buffer 39 31 32 38 0a><Buffer 32 31 38 39 0a><Buffer 37 32 34 33 0a><Buffer 38 32 31 36 0a><Buffer 35 33 33 38 0a><Buffer 31 39 38 37 0a><Buffer 32 33 36 0a><Buffer 31 30 34 39 0a><Buffer 36 34 37 36 0a><Buffer 33 39 37 30 0a>
当可读流生产出可供消费的数据后就会触发 data 事件,data 事件监听器绑定后,数据会被尽可能地传递。data 事件的监听器可以在第一个参数收到可读流传递过来的 Buffer 数据,这也就是控制台打印的 chunk,如果想显示为数字,可以调用 Buffer 的 toString() 方法
当数据处理完成后还会触发一个 end 事件,因为流的处理不是同步调用,所以如果希望完事后做一些事情就需要监听这个事件,在代码最后追加一句:
rns.on('end', () => {console.log('done');});
当然数据处理过程中出现了错误会触发 error 事件,可以监听做异常处理:
rns.on('error', (err) => {console.log(err);});
read(size)
流在暂停模式下需要程序显式调用 read() 方法才能得到数据,read() 方法会从内部缓冲区中拉取并返回若干数据,当没有更多可用数据时,会返回 null
使用 read() 方法读取数据时,
- 如果传入了 size 参数,那么它会返回指定字节的数据
- 当指定的 size 字节不可用时,则返回 null
- 如果没有指定 size 参数,那么会返回内部缓冲区中的所有数据
现在有一个问题:
在流动模式下流生产出了数据,然后触发 data 事件通知给程序,这样很方便,没问题。
在暂停模式下需要程序去读取,那么就有一种可能是读取的时候还没生产好,如果使用轮询的方式效率有些低
NodeJS 提供了一个 readable 的事件,事件在可读流准备好数据的时候触发,也就是先监听这个事件,收到通知有数据了再去读取就好了:
const rns = new RandomNumberStream(5);rns.on('readable', () => {let chunk;while((chunk = rns.read()) !== null){console.log(chunk);}})
这样可以读取到数据,值得注意的一点是并不是每次调用 read() 方法都可以返回数据,前面提到了如果可用的数据没有达到 size 那么返回 null,所以在程序中加了个判断
数据会不会漏掉
const stream = fs.createReadStream('/dev/input/event0');stream.on('readable', callback);
在流动模式会不会有这样的问题:可读流在创建好的时候就生产数据了,如果在绑定 readable 事件之前就生产了某些数据,触发了 readable 事件,在极端情况下会造成数据丢失吗?
事实并不会,按照 NodeJS event loop 程序创建流和调用事件监听在一个事件队列里面,生产数据和事件监听都是异步操作,而 on 监听事件使用了 process.nextTick 会保证在数据生产之前被绑定好,相关知识可以看定时器章节中对 event loop 的解读
到这里可能对 data事件、readable 事件触发时机, read() 方法每次读多少数据,什么时候返回 null 还有一定的疑问,在后续可写流章节会在 back pressure 部分结合源码介绍相关机制

若有收获,就点个赞吧
0 人点赞
