title: 平安人寿智能问答系统subtitle: 平安人寿智能问答系统
date: 2021-10-31
author: NSX
catalog: true
tags:
- 平安人寿
- 智能问答系统
平安在ROCLING 2019上发表了一篇有关智能问答系统的论文,比较全面的讨论了一套智能问答的方案,这篇文章的特点在于详细系统地讲解了FAQ任务的常规方法和体系,对我们构造单论检索式对话、智能问答等任务的建设有很大意义,加之平安本身有非常强的问答需求,文章对智能问答的理解深度也体现的非常明确。
知乎上平安官博给了文章的中文版解释:https://zhuanlan.zhihu.com/p/111380177
懒人目录:
首先介绍平安人寿智能问答引擎算法架构,如下图:
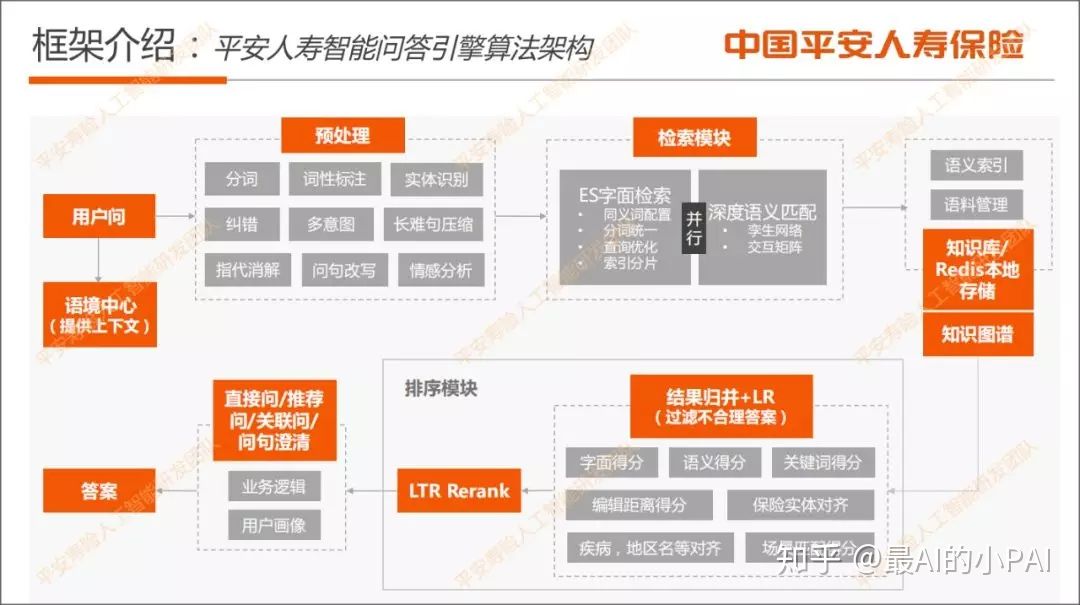
从问题输入开始,这里包括用户的问题以及语境中心提供上下文,其中包含用户的历史对话信息以及一些关于用户意图的结构化数据。
用户的问题输入后,首先进入预处理模块。在预处理模块里,分词、词性标注、实体识别都是比较成熟的技术,配合业务专用名词词典,我们采用Hanlp工具来做;多意图识别则用分类来做,主要处理用户一句话里有多个问题的意图,并给予不同的回答;问句改写主要是对保险名词的缩写和全称做改写;情感分析主要是通过句法分析去判断用户的话语是肯定意图或是否定意图。
预处理结束后,会进入检索模块。如果预处理经过纠错和问句改写,就会是多个query并行进入检索,触发ES字面检索和深度语义匹配。经过这两个检索模块得到的答案后,我们会从知识库以及Redis本地存储,把答案拿到后做多路结果归并。然后简单计算字面得分、语义得分、关键词得分,编辑距离作为LR的feature。
还有保险实体对齐,主要是重要名词、疾病、地区等的对齐。在排序模块里,比如用户问的问题是关于A保险,匹配的答案是B保险,处理的方式是在实体对齐的时候把答案去除,剩余的答案会做深度语义精排。
排序后,就进入输出模块。在输出模块里,有直接问输出、推荐问输出等,如果阈值比较低,还会做问句澄清。在输出模块,关联问可能会用到用户画像。
剩下的就慢慢开始展开讲吧。
一、问句预处理核心技术
但凡做过这个预处理模块,就知道Query预处理工作的繁杂,这里面列举的是非常常见的子模块了:
- 分词。NLP基操。
- POS。词性标注,一般使用的是序列标注的方法,也可能和实体抽取一起做。
- NER。实体识别使用的是加入了保险专用名词词典的NLP现成工具。
- 纠错。纠错模块主要是为了处理用户输入出现错别字的情况,因为错别字可能会对后面的模型识别造成影响,所以需要先进行纠错动作。比较直观的做法是基于字典和规则的纠错。
句子压缩。NLP对于长难句处理可能不能精准识别关键信息,有的时候还需要拆句,比较直观的一种方法是语法树分析+关键词典。
- 第一步,通过标点或空格分割长句成若干个短句,然后对短句分类,去掉口水语句。
- 第二步,基于概率和句法分析的句子压缩方案,只保留主谓宾等核心句子成分。配合保险关键词典,确保关键词被保留。
- 指代消解。NLP经典难题,分析“他她它”、“这个那个”之类所指代的内容。其实现思路是:分词→词性标注→依存句法分析→主谓宾提取→实体替换/指代消解
- 问句改写。有的时候用户的说法会比较多,会有自己的习惯说法,尤其是一些专名,例如英雄联盟里面用户不喜欢说“法外狂徒”、“格雷福斯”,而喜欢说“男枪”,那就需要我们进行改写。问句改写主要针对保险名。
- 情感分析。这块在小冰那里体现的非常丰富,在平安客服中也有体现,对生气的用户进行一定的安抚。
二、检索和深度语义匹配技术
平安的做法是将智能客服当做是经典的检索式对话来处理,真可谓是简单快捷。
1. ElasticSearch字面检索
目前字面检索用的是ElasticSearch,这是一个基于lucene的高可用分布式开源搜索引擎。
除了ElasticSearch外,其实还有Solr搜索引擎。选择前者的原因是,在处理实时的搜索应用时,ES的效率明显比Solr要高。线上的产品其实对运行时间有较高的要求,整个系统跑下来要求控制在100毫秒以内。
我们会根据知识库去建立所有数据的索引,同时支持一些分类和机构的查询。
其中ES的分词进行了统一配置的动作,里面配置了保险专用名词和同义词。ES默认为TFIDF的算法,但也支持BM25的算法。ES搜索结果的得分则会被零到一的归一化以及分片优化。
2. 孪生网络
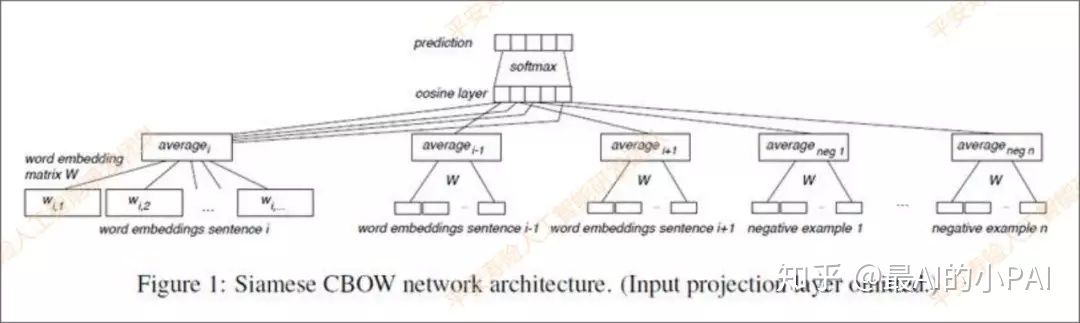
接下来介绍深度语义匹配模块,其中主要使用的是孪生网络Siamese CBOW。
词向量会经过预训练,然后用求和取平均的方式来表征句向量,对于每个query,使用标注的相似说法作为正样本,负样本使用随机采样的方式产生,且每次迭代都进行随机采样,大大增加训练数据的随机性,提升模型的泛化能力,损失函数为Contrastive Loss,让正样本之间的句向量表征尽量相似。预先算出语料的所有句向量表征,将用户问题通过模型转化成句向量,搜索语料里最相似的若干个句向量作为候选答案列表。
3. BERT for QA
BERT这一块的主要工作是,在BERT之后做一层微调。我们会自定义Fine-tune这块的Processor,然后把BERT表征之后的句向量再接一个孪生网络进行训练。
实验结果显示,加入BERT表征会比之前存的词向量准确率提升3个点左右。
4. 交互矩阵
前文提到的孪生网络Siamese CBOW其实是一个表示模型。深度语义匹配除了表示模型以外,还有一类是交互模型。从论文看,前面一种叫做representation model,后面这种交互模型主要是叫interaction model。
具体可查阅博客《2021-05-26-语义相似度&对比学习》
5. 检索&语义匹配小结
这里要详细说的是语义召回,在对话系统里面主要是两个方案:
- 第一种是将用户query向量化(例如word2vector,当然含有更复杂的方法),然后召回历史出现过的相似问题,相似问题对应的回答就可以是答案。也就是Q->Q->A的模式。
- 第二种就是Q->A的方式。直接召回结果。
无论是第一种还是第二种,实质上就是要对句子进行语义表征,然后通过向量召回的方式召回结果,于是解决问题的关键就落在了两个关键点上:
- 平行数据的构建。
- 语义相似度建模。
前者是数据集构建的问题,常规方式就是直接从历史对话里面获取,然后根据效果整理、拓展、增强,这就是算法工程师的内功了。后者则是一个学术界已经被很经常谈到的问题了,以DSSM为基础,辅以多种特征抽取层进行处理,平安对LSTM、CNN、Attention、Bert都进行了尝试,虽然BERT不出意外的得到了最好的效果,但是由于耗时的原因最终选择的是cbow(呃呃呃),而在切词粒度上,使用的是词组粒度效果最好,优于简单的字和词语,语义更为丰富,大家可以参考。
这里给大家推荐一个优秀的开源工具:MatchZoo,这是一个开源的Python环境下基于TensorFlow开发的文本匹配工具,实现了主流的20多种深度语义匹配算法。其主要用Keras实现,代码结构非常好。
三、基于深度学习的问答排序算法
通过多路召回,检索返回与用户问最匹配的问句列表,去重归并,通过实体对齐去掉一些不合理匹配问,再经过深度学习排序打分,输出最终的相关问列表,最后以业务格式根据匹配问查找答案返回给用户。
1. Deeprank
通过索引可以得到若干个答案,将这若干个答案合并去除重复的答案之后,就进入排序模块。接下来将详细介绍我们采用的深度学习排序算法:
- 构造格式为<用户query,候选答案>的pair对输入样本;
- 语义向量获取,这个可以来自于各种预训练语言模型;
- 构造打分器
CNN+Pooling+相似度矩阵&&拼接tfidf/词共现特征+MLP+Softmax进行 learning to rank,使得正确匹配的样本打分尽量高(归一化后趋近于1),错误匹配的样本打分尽量低(归一化后趋近于0) - 可以在 learng2rank 模型的输入向量中方便地融入外部特征
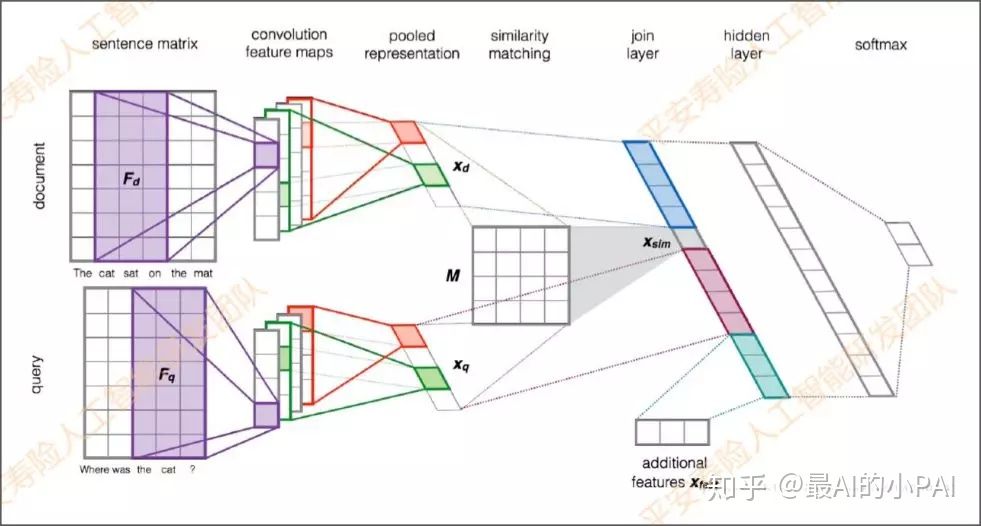
首先做分词,每一个词向量的维度矩阵就是sentence matrix这个矩阵高度。sentence matrix出来之后,会经过好几个过滤器去提取特征,例如下图是用tri-gram来提取。
把这些特征提取之后拼接在一起,有多个Filter的话就会生成多个Feature maps。多个卷积Feature maps提取好之后,会经过pooling层,把每个Feature maps做Pooling后,再把Pooling拼接到一起。
中间看到的Similarity Matching有个矩阵M。矩阵M是在模型里是通过参数训练得到的;Xd是用户匹配的问题;Xq是用户问题经过Pooing后提取的特征。
通过XdMXq得到Xsim,得到Join Layer。除了Xsim向量以外,Join Layer还会有额外Feature,包括问答对的共现词情况(交集个数、重要度、占比等),如TF-IDF、BM25、编辑距离,属于文本层面的匹配;抽取关键词和实体后的关键词匹配打分、实体匹配打分;意图和标签的匹配等。
实验发现,共现词特征其实影响比较大,加上这个特征之后大概会有2-3个点的提升。
过了join Layer之后,最后是一个MLP多层感知机接softmax,主要分5级打分S、A、B、C、D:S=完全匹配,A=非常相关,B=相关,C、D基本上不怎么相关。
该排序打分模型支持对pointwise和pairwise方法进行训练。假设只是pointwise,就看用户的问题跟匹配的问句是否相关;pairwise的话,就看用户匹配的两个问题,针对用户的query到底哪个更加相关。
小结
平安虽然并非所谓的大厂,但是其结构化的一些思路,尤其是本篇文章,依旧给我们提供了很多具体方案上的建议,让我们在方案设计时有更多扎实可靠的参考,通读本文下来,我们能够获得的应该是一套完整的智能问答系统方案,非常稳妥可靠。划几个重点吧:
- 智能团队对话系统的具体框架和流程。尤其是以检索和语义召回为中心的两条线的上下游处理。
- 预处理模块可能需要涉及的工作,有必要的,也有升级的,可以根据项目进展迭代进程逐步增加新功能。
- 排序上列举了不少可以使用的特征,让我们在优化效果的时候有更多明确的方向。
参考

若有收获,就点个赞吧
0 人点赞
