layout: post # 使用的布局(不需要改)
title: SQLModel # 标题
subtitle: SQLModel
date: 2019-09-15 # 时间
author: NSX # 作者
header-img: img/post-bg-2015.jpg #这篇文章标题背景图片
catalog: true # 是否归档
tags: #标签
- SQLModel
- ORM
SQLModel – SQL Databases in FastAPI
SQLModel 是一个用于与 SQL DB 交互的库,基于 Python 类型提示。
由 Pydantic(数据校验库)和 SQLAlchemy(SQL 对象映射器)提供技术支持,并且都针对 FastAPI 进行了优化。
GitHub 在这里: https://github.com/tiangolo/sqlmodel
此 Twitter 线程中的更多信息: https://twitter.com/tiangolo/status/1430252646968004612
文档在这里: https://sqlmodel.tiangolo.com/
基于 SQLAlchemy¶
SQLModel也基于 SQLAlchemy 并将其用于一切。
在下面,✨一个SQLModel模型也是一个SQLAlchemy模型。✨
有很多研究和努力致力于使其成为这种方式。特别是,要使单个模型同时成为 SQLAlchemy 模型和 Pydantic模型,需要付出很多努力和实验。
这意味着您可以获得 SQLAlchemy(Python 中使用最广泛的数据库库)的所有功能、稳健性和确定性。
SQLModel提供了自己的实用程序来改善开发人员体验,但在底层,它使用了所有 SQLAlchemy。
您甚至可以将SQLModel 模型与 SQLAlchemy 模型结合起来。
SQLModel 旨在满足最常见的用例,并为这些用例尽可能简单方便,提供最佳的开发人员体验。
但是,当您有更多需要更复杂功能的奇特用例时,您仍然可以将 SQLAlchemy 直接插入 SQLModel 并在您的代码中使用其所有功能。
ORM介绍
面向对象编程把所有实体看成对象(object),关系型数据库则是采用实体之间的关系(relation)连接数据。很早就有人提出,关系也可以用对象表达,这样的话,就能使用面向对象编程,来操作关系型数据库。
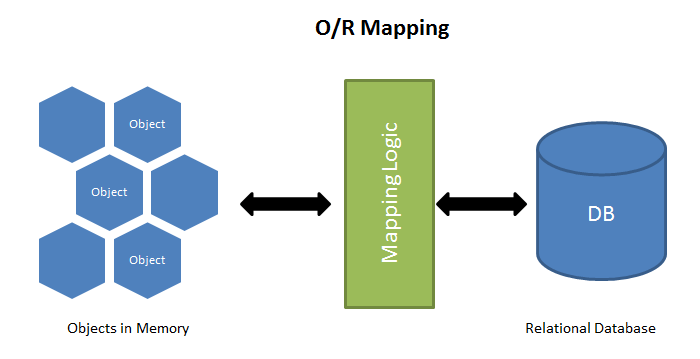
简单说,ORM 就是通过实例对象的语法,完成关系型数据库的操作的技术,是”对象-关系映射”(Object/Relational Mapping) 的缩写。
ORM 把数据库映射成对象。
- 数据库的表(table) —> 类(class)
- 记录(record,行数据)—> 对象(object)
- 字段(field)—> 对象的属性(attribute)

总结起来,ORM 有下面这些优点。
- 数据模型都在一个地方定义,更容易更新和维护,也利于重用代码。
- ORM 有现成的工具,很多功能都可以自动完成,比如数据消毒、预处理、事务等等。
- 它迫使你使用 MVC 架构,ORM 就是天然的 Model,最终使代码更清晰。
- 基于 ORM 的业务代码比较简单,代码量少,语义性好,容易理解。
- 你不必编写性能不佳的 SQL。
但是,ORM 也有很突出的缺点。
- ORM 库不是轻量级工具,需要花很多精力学习和设置。
- 对于复杂的查询,ORM 要么是无法表达,要么是性能不如原生的 SQL。
- ORM 抽象掉了数据库层,开发者无法了解底层的数据库操作,也无法定制一些特殊的 SQL。
Installation¶
pip install sqlmodel
CRUD operations with SQLModel using a single table
Create an SQLModel: models.py
from sqlmodel import SQLModel,Fieldfrom typing import Optionalclass Book(SQLModel,table=True):id:Optional[int]=Field(default=None,primary_key=True)title:strdescription:str
该id字段不能NULL在数据库中,因为它是主键,我们使用Field(primary_key=True). 但是在 Python 代码中id实际上可以有None相同的字段,所以我们用 声明类型Optional[int],并将默认值设置为Field(default=None):
Database setup: database.py
from sqlmodel import SQLModel,create_engineimport osBASE_DIR=os.path.dirname(os.path.realpath(__file__))conn_str='sqlite:///'+os.path.join(BASE_DIR,'books.db')print(conn_str)engine=create_engine(conn_str,echo=True)
在这个例子中,我们还使用了参数 echo=True。它将使引擎打印它执行的所有 SQL 语句,这可以帮助您了解正在发生的事情。
Creating the database create_db.py
from sqlmodel import SQLModelfrom models import Bookfrom database import engineprint("CREATING DATABASE.....")SQLModel.metadata.create_all(engine)
导入models的Book类,Python 执行所有代码,创建从 SQLModel 继承的类并将它们注册到 SQLModel.metadata 中。create_all通过engine来创建数据库和在此 MetaData 对象中注册的所有表。
Get all items main.py
from fastapi import FastAPIfrom fastapi import statusfrom fastapi.exceptions import HTTPExceptionfrom models import Bookfrom database import enginefrom sqlmodel import Session,selectfrom typing import Optional,Listapp=FastAPI()session=Session(bind=engine)@app.get('/books',response_model=List[Book],status_code=status.HTTP_200_OK)async def get_all_books():statement=select(Book)results=session.exec(statement).all()return results
Get one item
@app.get("/book/{book_id}", response_model=Book)async def get_a_book(book_id: int):statement = select(Book).where(Book.id == book_id)# statement = select(Hero).where(Hero.age >= 35, Hero.age < 40)# statement = select(Hero).where(or_(Hero.age <= 35, Hero.age > 90))result = session.exec(statement).first()if result == None:raise HTTPException(status_code=status.HTTP_404_NOT_FOUND)return result
Create an item
@app.post("/books", response_model=Book, status_code=status.HTTP_201_CREATED)async def create_a_book(book: Book):new_book = Book(title=book.title, description=book.description)session.add(new_book)print("After adding to the session")print("new_book:", new_book)session.commit()print("After committing the session")print("new_book:", new_book.id)print("new_book:", new_book.title)session.refresh(new_book) # 显式刷新对象,保证获取的是最新数据print("After refreshing the heroes")print("new_book:", new_book)return new_book
id默认设置为None,在与数据库交互之前,值实际上可能一直是None.
Update a book
@app.put("/book/{book_id}", response_model=Book)async def update_a_book(book_id: int, book: Book):statement = select(Book).where(Book.id == book_id)result = session.exec(statement).first()result.title = book.titleresult.description = book.descriptionsession.commit()session.refresh(result)return result
Delete a book
@app.delete("/book/{book_id}", status_code=status.HTTP_204_NO_CONTENT)async def delete_a_book(book_id: int):statement = select(Book).where(Book.id == book_id)result = session.exec(statement).one_or_none()if result == None:raise HTTPException(status_code=status.HTTP_404_NOT_FOUND, detail="Resource Not Found")session.delete(result)return result
Connect Tables - JOIN
联合查询的另一种方式,使用关键字JOIN而不是WHERE.
使用WHERE:
SELECT hero.id, hero.name, team.nameFROM hero, teamWHERE hero.team_id = team.id
这是使用的替代版本JOIN:
SELECT hero.id, hero.name, team.nameFROM heroJOIN teamON hero.team_id = team.id
两者是等价的。
@app.get("/books_join", response_model=List[Book], status_code=status.HTTP_200_OK)async def select_heroes():statement = select(Book, Team).where(Book.id==Team.id)results = session.exec(statement)print(results.all())statement = select(Book, Team).join(Team)results2 = session.exec(statement)for hero, team in results2:print("Hero:", hero, "Team:", team)
当使用 时.join(),因为我们foreign_key在创建模型时已经声明了什么,所以我们不必传递ON部分,它会自动推断
.join()有一个参数,我们可以isouter=True用来使JOINa LEFT OUTER JOIN:
# Code above omitted 👆def select_heroes():with Session(engine) as session:statement = select(Hero, Team).join(Team, isouter=True)results = session.exec(statement)for hero, team in results:print("Hero:", hero, "Team:", team)# Code below omitted 👇
参考
SQLModel 官方文档 https://sqlmodel.tiangolo.com/
SQLAlchemy ORM 官方文档 https://www.tutorialspoint.com/sqlalchemy/sqlalchemy_orm_filter_operators.htm

若有收获,就点个赞吧
0 人点赞
