TaCL: Improving BERT Pre-training with Token-aware Contrastive Learning 2022
Paper: TaCL: Improve BERT Pre-training with Token-aware Contrastive Learning Authors: Yixuan Su, Fangyu Liu, Zaiqiao Meng, Lei Shu, Ehsan Shareghi, and Nigel Collier Paper Repo: [https://github.com/yxuansu/TaCL]
像BERT和RoBERTa这样的屏蔽语言模型(mlm)在过去的几年中彻底改变了自然语言理解领域。然而,现有的预训练mlm通常输出一个各向异性分布的token表示,分布在整个表示空间的一个狭窄子集。这样的token表示并不理想,特别是对于需要不同token的区别语义的任务。在这项工作中,我们提出了TaCL(Token-aware Contrastive Learning),首次尝试应用对比学习来改进Transformer模型的token表示,鼓励BERT学习各向同性和区分 token表示的分布。TaCL是完全无监督的,不需要额外的数据。我们以广泛的英语和中文基准测试我们的方法。结果表明,与原始BERT模型相比,TaCL模型带来了一致且显著的改进。 and away from the representations of other tokens in the same sequence (dashed arrows).")
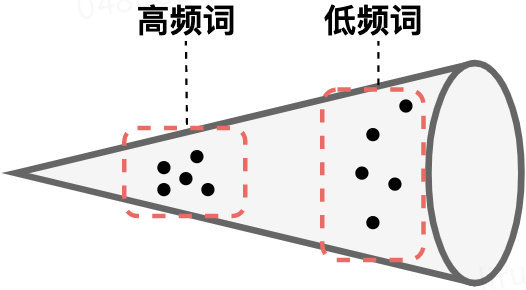
各向异性解释: 「各向异性」(即,用不同的方式去衡量它,他表现出不同的语义差别很大),高频词聚集到一起并且靠近坐标原点,而低频词则稀疏分散。当使用token embedding的平均作为句子表示时,高频词的就会起到主导地位,这就导致产生了对句子真实语义的偏置。也就是说,BERT句向量表示的坍缩和句子中的高频词有关。因此,在下游任务中直接应用BERT的原生句子表示是不合适的。
TaCL 训练方法介绍:
- 从相同的预训练BERT初始化两个模型(一个学生模型 S 和一个老师模型 T)
- 在训练阶段,我们冻结老师的参数,并不断优化的学生模型(利用 MLM Loss + NSP Loss + TaCL Loss)
TaCL(Token-aware Contrastive Learning)
Token 级别的对比学习损失函数: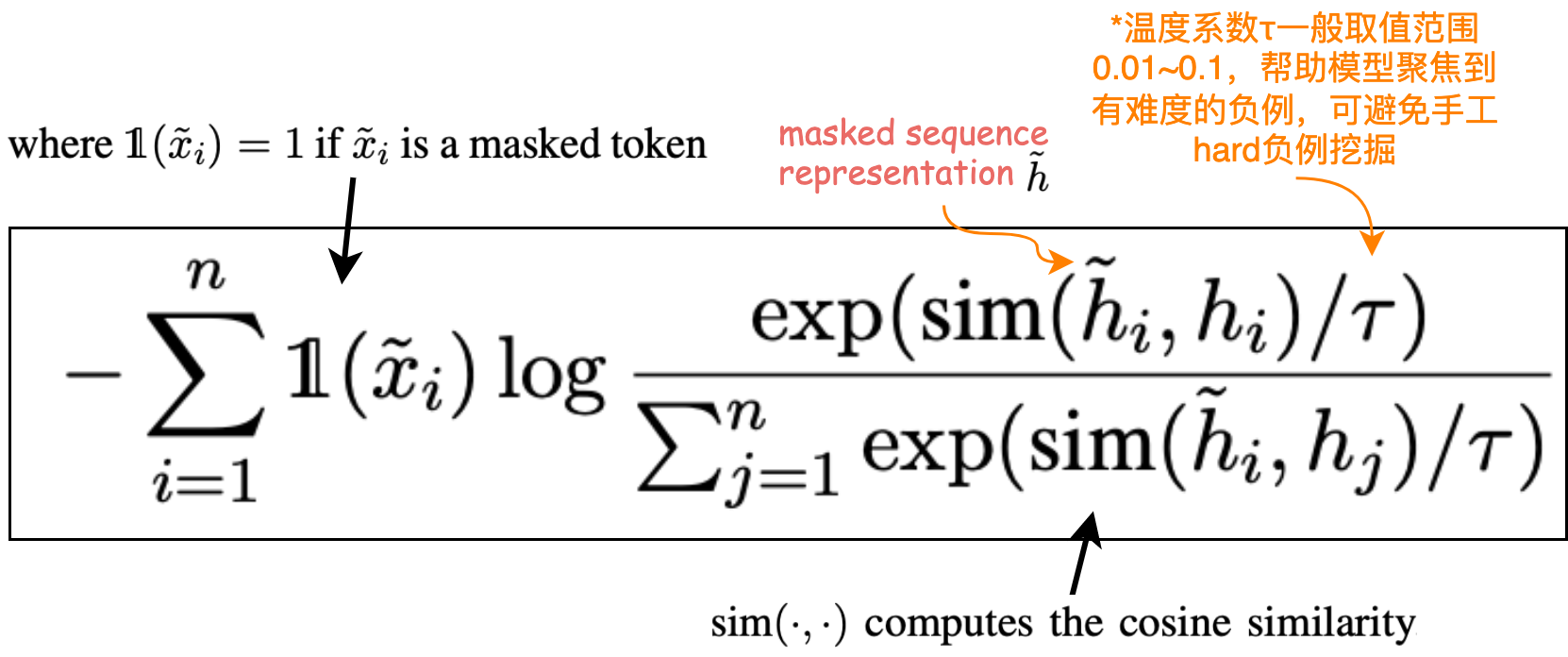
TACO not TACo
Paper: Contextual Representation Learning beyond Masked Language Modeling(掩码语言建模之上的语境表征学习) (ACL2022) Authors: Zhiyi Fu, Wangchunshu Zhou, Jingjing Xu,等 Paper Repo: https://github.com/FUZHIYI/TACO blog:https://zhuanlan.zhihu.com/p/503257104
本文研究以建模全局语义的方法通过BERT等预训练模型的限制。像BERT 这样的掩码语言模型(MLM)是如何学习上下文表示的?在这项工作中,通过聚焦分析MLM上下文表示学习的动态信息,作者发现:MLM采用采样嵌入作为锚来估计并向表示注入上下文语义,这限制了MLM的效率和有效性。为了解决这些问题,作者提出了一种简单而有效的表示学习方法TACO(Token-Alignment Contrastive Objective),来直接建模全局语义。TACO提取并对齐隐藏在上下文化表示中的上下文语义,以鼓励模型在生成上下文化表示时关注全局语义。在GLUE基准上的实验表明,与现有MLM相比,TACO实现了高达5倍的加速,平均提高了1.2个点。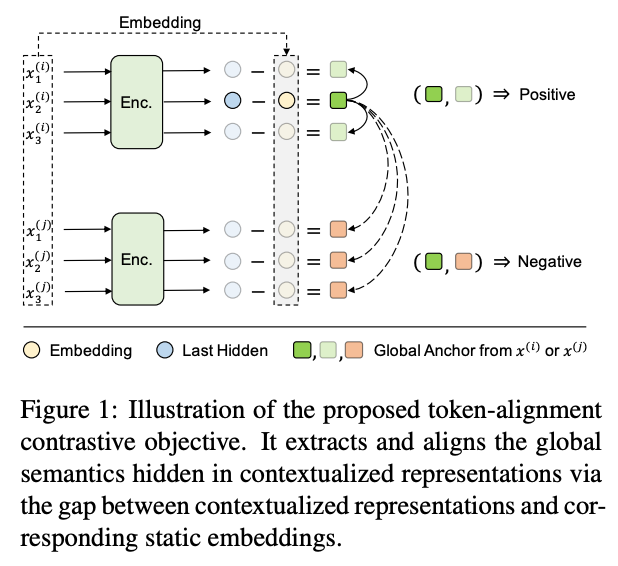
MLM目标可以表述为:周围标记的上下文化表示与目标标记的上下文无关嵌入之间的对齐,(2)表示空间中表示的一致性。")
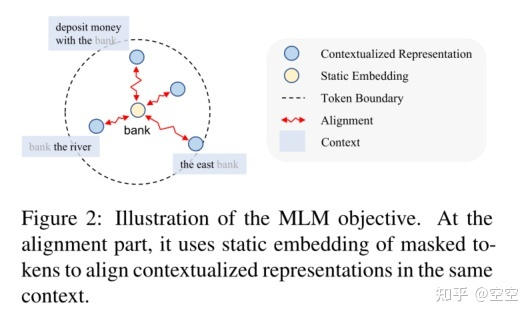
在对齐部分,MLM依赖于采样的与上下文无关的屏蔽令牌嵌入作为锚
嵌入锚在训练后期的语境化表征中减少了全局上下文信息。由于MLM采用局部锚点,这些局部嵌入将语境化表示推入不同的集群。语境分数也开始下降。这一现象证明了嵌入偏差问题,即语境化表征的学习取决于所选择的嵌入,而全局上下文语义被忽略。
Method:TACO
为了解决MLM面临的挑战,我们提出了一种新的方法TACO,将全局锚和局部锚结合起来。为了对全局语义进行建模,目标是能够显式地捕获相同上下文中标记的上下文化表示之间共享的信息。我们首先引入TC Loss显式建模全局语义的token对齐对比损失,用于最大化相同上下文语境化表征中隐藏的上下文信息的互信息。token -alignment contrast (TC)损失如下: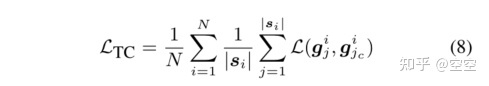
gi是隐藏在标记si的语境化表示中的全局语义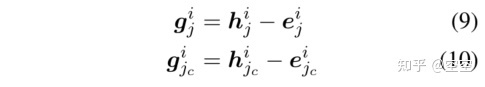
h为语境化表示,e为静态嵌入,jc为采样的正样本
如前所述,令牌对齐对比损失  设计用于对全局依赖关系建模,而MLM能够捕获局部依赖关系。因此,我们可以通过结合令牌对齐对比损失
设计用于对全局依赖关系建模,而MLM能够捕获局部依赖关系。因此,我们可以通过结合令牌对齐对比损失  和MLM损失来更好地建模上下文化的表示,以得到我们的总体目标
和MLM损失来更好地建模上下文化的表示,以得到我们的总体目标  :
: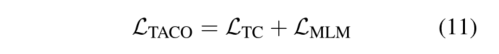
我们以多任务学习方式实现它。
TACO vs. MLM
为了更好地理解TACO的工作原理,我们对BERT和TACO的学习动态进行了定量比较。我们在图6中绘制了相同上下文(上下文内)和不同上下文(上下文间)中标记的上下文化表示之间的余弦相似性。我们发现TACO的学习动态与MLM有显著差异。具体来说,对于TACO,在训练后期,上下文内表示相似度仍然很高,上下文内相似度和上下文间相似度之间的差距仍然很大。这证实了TACO可以更好地实现全局语义,这可能有助于提高下游性能。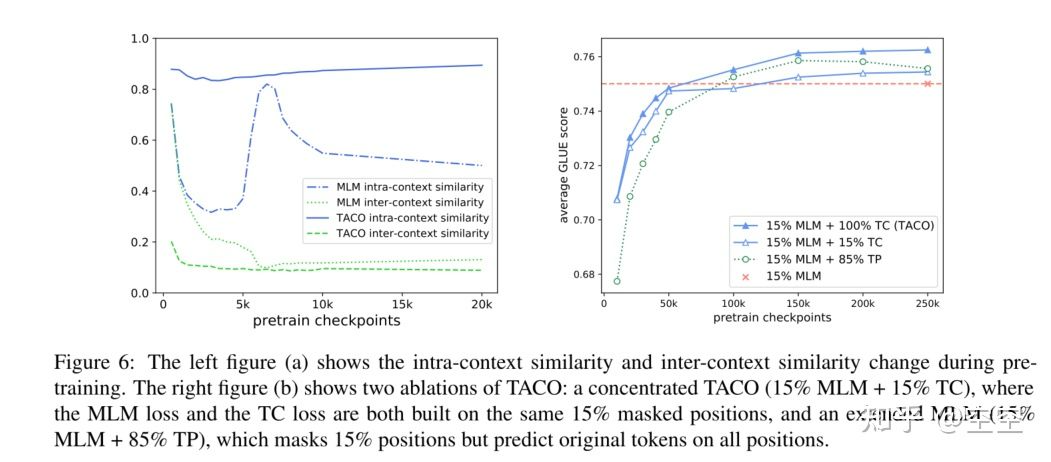
结论
- 在本文中,我们提出了一个简单而有效的学习情境化表示的目标。
- 本文以MLM为例,探讨当前的语言模型训练前目标是否以及如何学习情境化表征。我们发现,传销目标主要集中在本地锚对齐上下文化的表示,这损害了全局依赖建模由于“嵌入偏差”问题。
- 基于这些问题,我们提出TACO来直接建模全局语义。它可以很容易地与现有的MLM目标相结合。通过结合全局锚和局部锚,实验说明了TACO作为一种即插即用的方法来改善情境化表示学习的潜力。

若有收获,就点个赞吧
0 人点赞
