在基于attention机制的seq2seq(Encoder-Decoder)框架中,可以进一步引入copy机制,使得解码输出更加流畅与准确。本文总结三篇关于copy机制的做法:
- Incorporating Copying Mechanism in Sequence-to-Sequence Learning的CopyNet
- Get To The Point: Summarization with Pointer-Generator Networks的指针网络
- 苏神的实体标注型的Copy机制
一、CopyNet中的Copy Mechanism
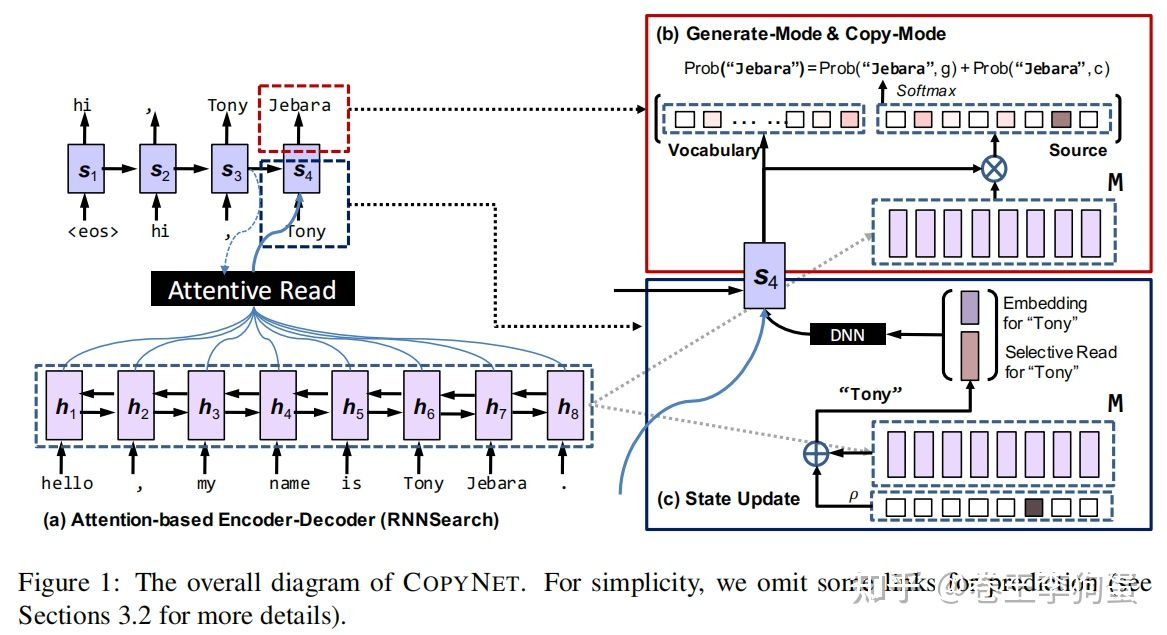
CopyNet是基于RNN的Seq2Seq结构搭建的,在解码时能自行决定预测的token是由生成模式还是复制模式而来。其网络结构主要是在Bahdanau attention的基础上进一步增加了copy机制。该机制对于摘要和对话系统来说,可有效提高基于端到端生成文本的流畅度和准确度,并改善了OOV问题(对于测试过程中可能Source和Target中同时出现的OOV词,过去的方法里,由于其不在词表中,故无法生成,现在只要其出现在Source序列中,便有概率Copy过来)。
与上述分析的基于attention的Encoder-Decoder相比,最大不同在于Decoder部分,Encoder部分不变。值得指出的是,作者将Encoder端生成的隐状态向量序列定义为copyNet的短期memory,用MM表示。在解码时MM将被多次使用。具体地,copyNet在预测某个token时是基于生成模式和copy模式两种混合概率进行建模的,即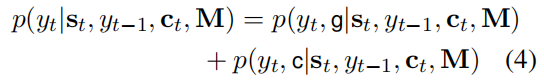
其中g表示Genertate-Mode,c表示Copy-Mode,  (Context vector)表示所有Encoder隐状态的汇总(Attention),M表示Source序列的隐状态矩阵,
(Context vector)表示所有Encoder隐状态的汇总(Attention),M表示Source序列的隐状态矩阵,  表示解码t-1时间步的预测token的向量表示,
表示解码t-1时间步的预测token的向量表示,  表示解码当前时刻的隐层输出。
表示解码当前时刻的隐层输出。 并非只根据预测token对应的Embedding得到,它的更新还加入了从M中Selective Read的信息,如上图右下部分。
并非只根据预测token对应的Embedding得到,它的更新还加入了从M中Selective Read的信息,如上图右下部分。
记词表为  ,Source序列中存在的单词记为
,Source序列中存在的单词记为  , 那么每个单词的生成概率和Copy概率按照如下方式计算:
, 那么每个单词的生成概率和Copy概率按照如下方式计算: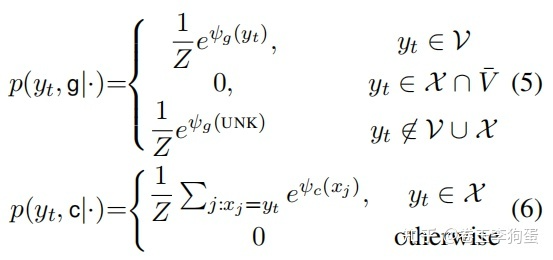
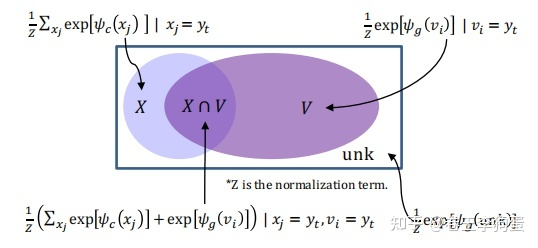
预测单词的生成概率容易计算,只需将t时刻的隐状态  通过一个全连接层计算每个单词对应的logits即可。
通过一个全连接层计算每个单词对应的logits即可。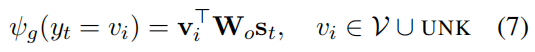
如果单词出现在 中,将该单词在Encoder中对应的状态
中,将该单词在Encoder中对应的状态  与参数
与参数  以及Decoder的t时刻的隐状态
以及Decoder的t时刻的隐状态  融合计算得分。
融合计算得分。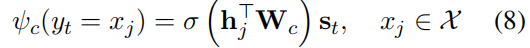
二、指针网络
1.1 Why Pointer Network?
提出Pointer Network的动机是什么?
需要先回顾下Seq2Seq,顾名思义,它实现了把一个序列转换成另外一个序列的功能,并且不要求输入序列和输出序列等长。
后来,Attention Mechanism[6]的加入使得seq2seq模型的性能大幅提升,从而大放异彩。那么Attention Mechanism做了些什么事呢?一言以蔽之,Attention Mechanism的作用就是将encoder的隐状态按照一定权重加和之后拼接(或者直接加和)到decoder的隐状态上,以此作为额外信息。如下面的公式所示,其中 是Encoder的隐状态,
是Encoder的隐状态, 是Decoder的隐状态,
是Decoder的隐状态, 都是可学习的参数。
都是可学习的参数。
Attention 起到所谓“软对齐”的作用,并且提高了整个模型的预测准确度。简单举个例子,在机器翻译中一直存在对齐的问题,也就是说源语言的某个单词应该和目标语言的哪个单词对应,如“Who are you”对应“你是谁”,如果我们简单地按照顺序进行匹配的话会发现单词的语义并不对应,显然“who”不能被翻译为“你”。而Attention Mechanism非常好地解决了这个问题。如前所述,Attention Mechanism会给输入序列的每一个元素分配一个权重,如在预测“你”这个字的时候输入序列中的“you”这个词的权重最大,这样模型就知道“你”是和“you”对应的,从而实现了软对齐。
Attention机制三步骤:
- 编码器和解码器对每个单词的embedding,做权重和之后输入到tanh激活函数,来求编码器和解码器的单词embedding的相似性;
- 归一化;
- 求权重和 . 求得的值就是attention权重。每当Decoder生成一个单词的时候,都会考虑不同权重的Input。
通过Attention Mechanism将encoder的隐状态和decoder的隐状态结合成一个中间向量C,然后使用decoder解码并预测,最后经由softmax层得到了针对词汇表的概率分布,从中选取概率最高的作为当前预测结果。
传统的seq2seq模型是无法解决输出序列的词汇表随着输入序列序列长度的改变而改变的问题。
如寻找凸包(Convex Hull )等。因为对于这类问题,输出往往是输入集合的子集。基于这种特点,作者考虑能不能找到一种结构类似编程语言中的指针,每个指针对应输入序列的一个元素,从而我们可以直接操作输入序列而不需要特意设定输出词汇表。
1.2 Structure of Pointer Network
为啥叫pointer network呢?对于凸包的求解,就是从输入序列 中选点的过程。选点的方法就叫pointer,它不像attention mechanism将输入信息通过encoder整合成context vector,而是将attention转化为一个pointer,来选择原来输入序列中的元素。
中选点的过程。选点的方法就叫pointer,它不像attention mechanism将输入信息通过encoder整合成context vector,而是将attention转化为一个pointer,来选择原来输入序列中的元素。
Pointer Network 对注意力模型的简单修改,用于解决输出序列的大小取决于输入序列中元素的数量这个问题。
Pointer Network 计算 Attention 值之后不会把 Encoder 的输出融合,而是将 Attention 作为输入序列 中每一个位置输出的概率。
中每一个位置输出的概率。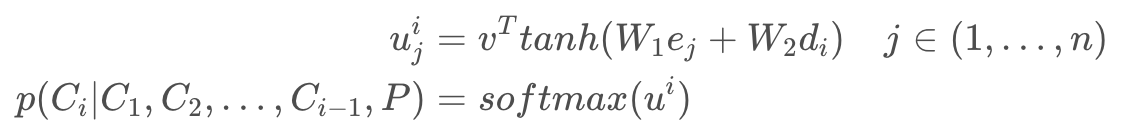
Pointer Network三步骤:
- 编码器和解码器对每个单词做embedding,求其权重和之后输入到tanh激活函数,来求编码器和解码器的单词的embedding相似性 ;
- 归一化;
- 将前
 个输出的单词和Attention权重作为条件概率,来生成第
个输出的单词和Attention权重作为条件概率,来生成第 个单词。
个单词。
这种方法专门针对输出离散且与输入位置相对应的问题。这种方法适用于可变大小的输入(产生可变大小的输出序列)。 本质上,input Sequence里对生成第i个单词的影响(相似性,相关性)越大,权重就越大。
Pointer Network 和 Seq2Seq 的区别:
- Seq2Seq 的 Decoder 会预测每一个位置的输出 (但是输出目标的数量是固定的);而 Pointer Network 的 Decoder 直接根据 Attention 得到输入序列中每一个位置的概率,取概率最大的输入位置作为当前输出。
- seq2seq需要遍历全局词表,可能出现OOV问题;而Pointer Network 无需遍历全局词表,只需遍历source text(input sequence),输出的也是input sequence中出现的单词,避免OOV。
1.3 Optimization
那么接下来如何训练pointer network?在这个地方使用(model-free和model-based) RL方法来优化pointer network的参数 ;我们的训练目标是,给定序列
;我们的训练目标是,给定序列 ,最小化期望路径长度:
,最小化期望路径长度:
在训练的过程中,为了能够具有泛化性,考虑序列点的图是服从分布 ,因此总的优化目标包含图的分布信息:
,因此总的优化目标包含图的分布信息:
我们借助策略梯度policy gradient方法和随机梯度stochastic gradient下降来优化参数;(3)式子的梯度使用REINFORCE algorithm (Williams, 1992) (这个不是很理解,后面补一下)表示为:
其中b(s)表示不依赖π的基线函数,并估计预期的行程长度以减小梯度的方差。通过对图进行sample,假设采样了B个图, ,则梯度(4)可以近似为:
,则梯度(4)可以近似为:
3.2 Baseline-critic
上面提到,找到一个合适baseline  可以提高训练学习的效果,这里采用critic 网络,参数为
可以提高训练学习的效果,这里采用critic 网络,参数为 ,来学习我们当前策略
,来学习我们当前策略 下的期望路径长度。评论家接受了随机梯度下降训练,其均方误差目标介于其预测值
下的期望路径长度。评论家接受了随机梯度下降训练,其均方误差目标介于其预测值 与最新策略采样出来的一个实际长度之间,(这个地方为什么是减
与最新策略采样出来的一个实际长度之间,(这个地方为什么是减 ,而不是
,而不是 ,这个地方是从当前策略中sample出一个确定的路径)
,这个地方是从当前策略中sample出一个确定的路径)
Critic architecture:现在来解释critic的构造,主要包含有三个模块:一个LSTM encoder,一个LSTM process block,和一个2-layer ReLU网络decoder。LSTM encoder与pointer network类似结构,输入sequence ss并将其转为latent memory states以及一个隐藏状态hidden h。然后是处理模块process block,处理块对隐藏状态h执行P个计算步骤。 每个处理步骤都通过glimpsing memory states状态来更新此隐藏状态h,并将瞥见功能的输出作为输入提供给下一个处理步骤。process block结束后,获得的隐藏state被解码为一个baseline的预测结果。
3.2 Search strategy
由于评估游程长度的成本很低,我们的TSP代理可以很容易地在推理时通过考虑每个图形的多个候选方案并选择最佳方案来模拟搜索过程。推理过程类似于求解器如何在大量可行解的集合上进行搜索。在本文中,我们考虑两种搜索策略,详述如下,我们将其称为采样sample和主动搜索active search。
(1)sampling:从训练的随机策略 中随机采样几个,找到其中的最短路径。当从我们的非参数softmax中取样时,用温度超参数控制取样游的多样性。
中随机采样几个,找到其中的最短路径。当从我们的非参数softmax中取样时,用温度超参数控制取样游的多样性。
Softmax: 用于多分类中,它将多个神经元的输出,映射到(0,1)区间内,可以看成概率来理解,从而来进行多分类,假设我们有一个数组,V,Vi表示V中的第i个元素,那么这个元素的softmax值就是
(2)Active search:。。。
三、BIO Copy Mechanism
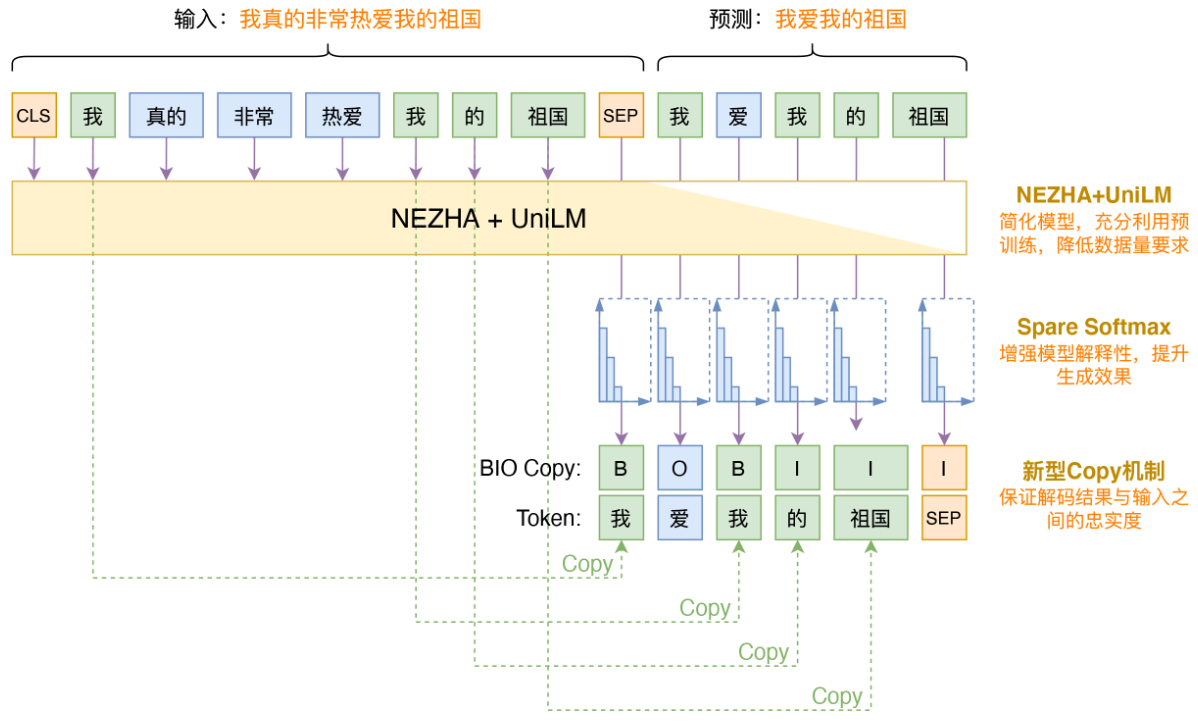
引自:https://spaces.ac.cn/archives/8046
先找Source和Target的最长公共子序列,并按照BIO标注方法对该子序列进行标注,标签如下:
- B:表示该token复制而来;
- I:表示该token复制而来且跟前面Token组成连续片段;
- O:表示该token不是复制而来的。
在训练阶段,在预测target序列的基础上,在每个token位置处将上述实体标注的预测损失也结合进优化目标即可(其实就是进一步保证了生成的摘要序列与Source中连续序列的一致性,因为Source与Target的最长公共子序列往往包含着专业性知识,这样可以尽量避免出现专业性错误,可以保证摘要与原始文本的忠实程度,这在实际使用中是相当必要的)。
在预测(解码)阶段,对于每一步,我们先预测该位置的标签,如果是O,则说明不涉及Copy部分,直接采用模型预测token即可。如果是B,那么在token的分布中mask掉所有不在原文中的token,如果是I,那么在token的分布中mask掉所有不能组成原文中对应的n-gram的token。也就是说,解码的时候还是一步步解码,并不是一次性生成一个片段,但可以通过mask的方式,保证BI部分位置对应的token是原文中的一个片段。
参考
Incorporating Copying Mechanism in Sequence-to-Sequence Learning
SPACES:“抽取-生成”式长文本摘要(法研杯总结) - 科学空间|Scientific Spaces

若有收获,就点个赞吧
0 人点赞
