1. Pointer Network(Ptr-Nets)
论文:Pointer Networks 博客:Pointer Network【文本生成】发展与应用、Pointer Networks简介及其应用 ⭐️李宏毅Pointer Network视频
传统的 Seq2Seq 模型中 Decoder 输出的目标数量是固定的,例如翻译时 Decoder 预测的目标数量等于字典的大小。这导致 Seq2Seq 不能用于一些组合优化的问题,例如凸包问题(Convex Hull ),三角剖分(Delaunay Triangulation ),旅行商问题 (TSP) 等。Pointer Network 可以解决输出字典大小可变的问题,Pointer Network 的输出字典大小等于 Encoder 输入序列的长度并修改了 Attention 的方法,根据 Attention 的值从 Encoder 的输入中选择一个作为 Decoder 的输出。
1.1 Why Pointer Network?
提出Pointer Network的动机是什么?
需要先回顾下Seq2Seq,顾名思义,它实现了把一个序列转换成另外一个序列的功能,并且不要求输入序列和输出序列等长。
后来,Attention Mechanism[6]的加入使得seq2seq模型的性能大幅提升,从而大放异彩。那么Attention Mechanism做了些什么事呢?一言以蔽之,Attention Mechanism的作用就是将encoder的隐状态按照一定权重加和之后拼接(或者直接加和)到decoder的隐状态上,以此作为额外信息。如下面的公式所示,其中 是Encoder的隐状态,
是Encoder的隐状态, 是Decoder的隐状态,
是Decoder的隐状态, 都是可学习的参数。
都是可学习的参数。
Attention 起到所谓“软对齐”的作用,并且提高了整个模型的预测准确度。简单举个例子,在机器翻译中一直存在对齐的问题,也就是说源语言的某个单词应该和目标语言的哪个单词对应,如“Who are you”对应“你是谁”,如果我们简单地按照顺序进行匹配的话会发现单词的语义并不对应,显然“who”不能被翻译为“你”。而Attention Mechanism非常好地解决了这个问题。如前所述,Attention Mechanism会给输入序列的每一个元素分配一个权重,如在预测“你”这个字的时候输入序列中的“you”这个词的权重最大,这样模型就知道“你”是和“you”对应的,从而实现了软对齐。
Attention机制三步骤:
- 编码器和解码器对每个单词的embedding,做权重和之后输入到tanh激活函数,来求编码器和解码器的单词embedding的相似性;
- 归一化;
- 求权重和 . 求得的值就是attention权重。每当Decoder生成一个单词的时候,都会考虑不同权重的Input。
通过Attention Mechanism将encoder的隐状态和decoder的隐状态结合成一个中间向量C,然后使用decoder解码并预测,最后经由softmax层得到了针对词汇表的概率分布,从中选取概率最高的作为当前预测结果。
传统的seq2seq模型是无法解决输出序列的词汇表随着输入序列序列长度的改变而改变的问题。
如寻找凸包(Convex Hull )等。因为对于这类问题,输出往往是输入集合的子集。基于这种特点,作者考虑能不能找到一种结构类似编程语言中的指针,每个指针对应输入序列的一个元素,从而我们可以直接操作输入序列而不需要特意设定输出词汇表。
1.2 Structure of Pointer Network
为啥叫pointer network呢?对于凸包的求解,就是从输入序列 中选点的过程。选点的方法就叫pointer,它不像attention mechanism将输入信息通过encoder整合成context vector,而是将attention转化为一个pointer,来选择原来输入序列中的元素。
中选点的过程。选点的方法就叫pointer,它不像attention mechanism将输入信息通过encoder整合成context vector,而是将attention转化为一个pointer,来选择原来输入序列中的元素。
Pointer Network 对注意力模型的简单修改,用于解决输出序列的大小取决于输入序列中元素的数量这个问题。
Pointer Network 计算 Attention 值之后不会把 Encoder 的输出融合,而是将 Attention 作为输入序列 中每一个位置输出的概率。
中每一个位置输出的概率。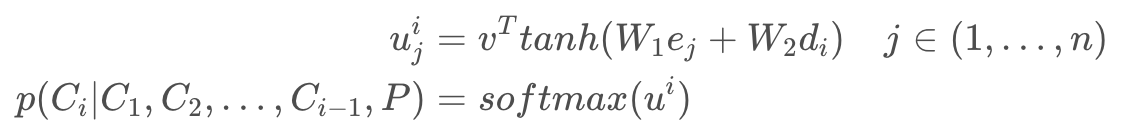
Pointer Network三步骤:
- 编码器和解码器对每个单词做embedding,求其权重和之后输入到tanh激活函数,来求编码器和解码器的单词的embedding相似性 ;
- 归一化;
- 将前
 个输出的单词和Attention权重作为条件概率,来生成第
个输出的单词和Attention权重作为条件概率,来生成第 个单词。
个单词。
这种方法专门针对输出离散且与输入位置相对应的问题。这种方法适用于可变大小的输入(产生可变大小的输出序列)。 本质上,input Sequence里对生成第i个单词的影响(相似性,相关性)越大,权重就越大。
Pointer Network 和 Seq2Seq 的区别:
- Seq2Seq 的 Decoder 会预测每一个位置的输出 (但是输出目标的数量是固定的);而 Pointer Network 的 Decoder 直接根据 Attention 得到输入序列中每一个位置的概率,取概率最大的输入位置作为当前输出。
- seq2seq需要遍历全局词表,可能出现OOV问题;而Pointer Network 无需遍历全局词表,只需遍历source text(input sequence),输出的也是input sequence中出现的单词,避免OOV。
1.3 Optimization
那么接下来如何训练pointer network?在这个地方使用(model-free和model-based) RL方法来优化pointer network的参数 ;我们的训练目标是,给定序列
;我们的训练目标是,给定序列 ,最小化期望路径长度:
,最小化期望路径长度:
在训练的过程中,为了能够具有泛化性,考虑序列点的图是服从分布 ,因此总的优化目标包含图的分布信息:
,因此总的优化目标包含图的分布信息:
我们借助策略梯度policy gradient方法和随机梯度stochastic gradient下降来优化参数;(3)式子的梯度使用REINFORCE algorithm (Williams, 1992) (这个不是很理解,后面补一下)表示为:
其中b(s)表示不依赖π的基线函数,并估计预期的行程长度以减小梯度的方差。通过对图进行sample,假设采样了B个图, ,则梯度(4)可以近似为:
,则梯度(4)可以近似为:
3.2 Baseline-critic
上面提到,找到一个合适baseline  可以提高训练学习的效果,这里采用critic 网络,参数为
可以提高训练学习的效果,这里采用critic 网络,参数为 ,来学习我们当前策略
,来学习我们当前策略 下的期望路径长度。评论家接受了随机梯度下降训练,其均方误差目标介于其预测值
下的期望路径长度。评论家接受了随机梯度下降训练,其均方误差目标介于其预测值 与最新策略采样出来的一个实际长度之间,(这个地方为什么是减
与最新策略采样出来的一个实际长度之间,(这个地方为什么是减 ,而不是
,而不是 ,这个地方是从当前策略中sample出一个确定的路径)
,这个地方是从当前策略中sample出一个确定的路径)
Critic architecture:现在来解释critic的构造,主要包含有三个模块:一个LSTM encoder,一个LSTM process block,和一个2-layer ReLU网络decoder。LSTM encoder与pointer network类似结构,输入sequence ss并将其转为latent memory states以及一个隐藏状态hidden h。然后是处理模块process block,处理块对隐藏状态h执行P个计算步骤。 每个处理步骤都通过glimpsing memory states状态来更新此隐藏状态h,并将瞥见功能的输出作为输入提供给下一个处理步骤。process block结束后,获得的隐藏state被解码为一个baseline的预测结果。
3.2 Search strategy
由于评估游程长度的成本很低,我们的TSP代理可以很容易地在推理时通过考虑每个图形的多个候选方案并选择最佳方案来模拟搜索过程。推理过程类似于求解器如何在大量可行解的集合上进行搜索。在本文中,我们考虑两种搜索策略,详述如下,我们将其称为采样sample和主动搜索active search。
(1)sampling:从训练的随机策略 中随机采样几个,找到其中的最短路径。当从我们的非参数softmax中取样时,用温度超参数控制取样游的多样性。
中随机采样几个,找到其中的最短路径。当从我们的非参数softmax中取样时,用温度超参数控制取样游的多样性。
Softmax: 用于多分类中,它将多个神经元的输出,映射到(0,1)区间内,可以看成概率来理解,从而来进行多分类,假设我们有一个数组,V,Vi表示V中的第i个元素,那么这个元素的softmax值就是
(2)Active search:。。。
2. GlobalPointer
《GlobalPointer:用统一的方式处理嵌套和非嵌套NER》 《Efficient GlobalPointer:少点参数,多点效果》
GlobalPointer#
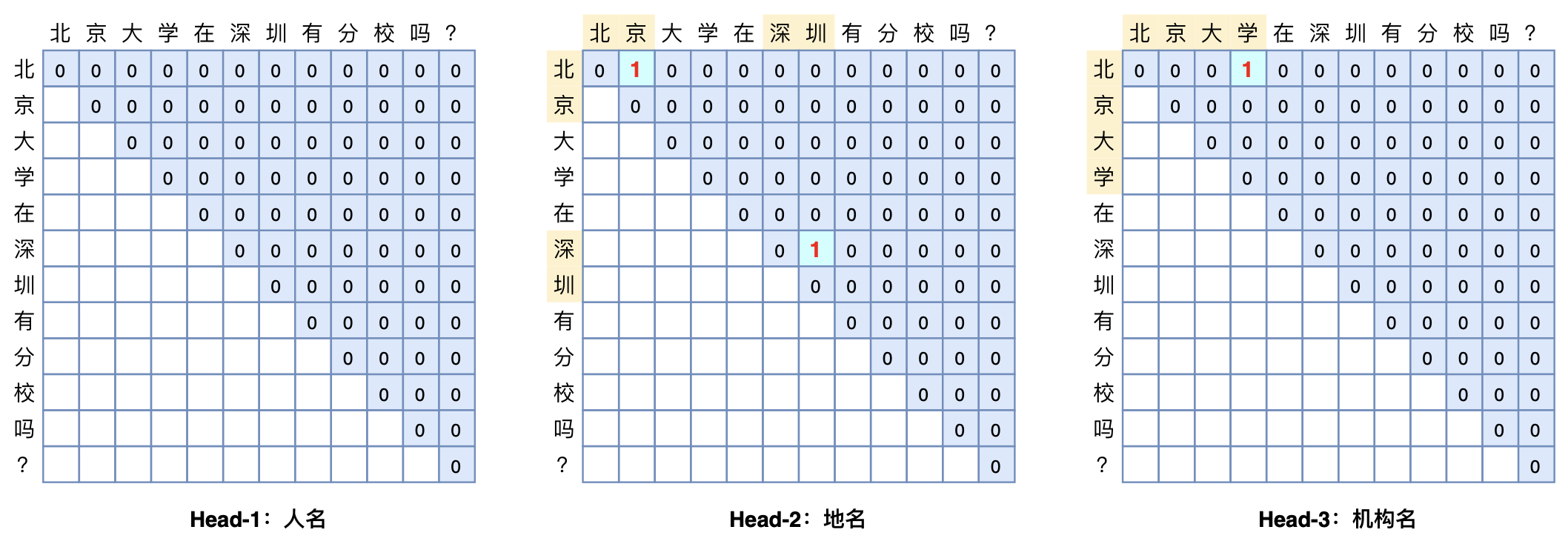
常规的Pointer Network的设计在做实体识别或者阅读理解时,一般是用两个模块分别识别实体的首和尾,这会带来训练和预测时的不一致。而GlobalPointer就是针对这个不一致而设计的,它将首尾视为一个整体去进行判别,所以它更有“全局观”(更Global)。
基本思路#
具体来说,假设要识别文本序列长度为 ,简单起见先假定只有一种实体要识别,并且假定每个待识别实体是该序列的一个连续片段,长度不限,并且可以相互嵌套(两个实体之间有交集),那么该序列有多少个“候选实体”呢?不难得出,答案是
,简单起见先假定只有一种实体要识别,并且假定每个待识别实体是该序列的一个连续片段,长度不限,并且可以相互嵌套(两个实体之间有交集),那么该序列有多少个“候选实体”呢?不难得出,答案是 个,即长度为n的序列有
个,即长度为n的序列有 个不同的连续子序列,这些子序列包含了所有可能的实体,而我们要做的就是从这
个不同的连续子序列,这些子序列包含了所有可能的实体,而我们要做的就是从这 个“候选实体”里边挑出真正的实体,其实就是一个“
个“候选实体”里边挑出真正的实体,其实就是一个“ 选 k”的多标签分类问题。如果有m种实体类型需要识别,那么就做成m个“
选 k”的多标签分类问题。如果有m种实体类型需要识别,那么就做成m个“ 选k”的多标签分类问题。这就是GlobalPointer的基本思想,以实体为基本单位进行判别,如本文开头的图片所示。
选k”的多标签分类问题。这就是GlobalPointer的基本思想,以实体为基本单位进行判别,如本文开头的图片所示。
可能有读者会问:这种设计的复杂度明明就是 呀,不会特别慢吗?如果现在还是RNN/CNN的时代,那么它可能就显得很慢了,但如今是Transformer遍布NLP的时代,Transformer的每一层都是
呀,不会特别慢吗?如果现在还是RNN/CNN的时代,那么它可能就显得很慢了,但如今是Transformer遍布NLP的时代,Transformer的每一层都是 的复杂度,多GlobalPointer一层不多,少GlobalPointer一层也不少,关键是
的复杂度,多GlobalPointer一层不多,少GlobalPointer一层也不少,关键是 的复杂度仅仅是空间复杂度,如果并行性能好的话,时间复杂度甚至可以降到
的复杂度仅仅是空间复杂度,如果并行性能好的话,时间复杂度甚至可以降到 ,所以不会有明显感知。
,所以不会有明显感知。
数学形式#
设长度为n的输入t经过编码后得到向量序列 ,通过变换
,通过变换 和
和 我们可以得到序列向量序列
我们可以得到序列向量序列 和
和 ,它们是识别第α种类型实体所用的向量序列。此时我们可以定义
,它们是识别第α种类型实体所用的向量序列。此时我们可以定义
作为从i到j的连续片段是一个类型为α的实体的打分。也就是说,用 与
与 的内积,作为片段
的内积,作为片段 是类型为α的实体的打分(logits),这里的
是类型为α的实体的打分(logits),这里的 指的是序列t的第i个到第j个元素组成的连续子串。在这样的设计下,GlobalPointer事实上就是Multi-Head Attention的一个简化版而已,有多少种实体就对应多少个head,相比Multi-Head Attention去掉了VV相关的运算。
指的是序列t的第i个到第j个元素组成的连续子串。在这样的设计下,GlobalPointer事实上就是Multi-Head Attention的一个简化版而已,有多少种实体就对应多少个head,相比Multi-Head Attention去掉了VV相关的运算。
优化细节#
在这部分内容中,我们会讨论关于GlobalPointer在训练过程中的一些细节问题,包括损失函数的选择以及评价指标的计算和优化等,从中我们可以看到,GlobalPointer以实体为单位的设计有着诸多优雅和便利之处。
损失函数#
到目前为止,我们已经设计好了打分 ,识别特定的类α的实体,则变成了共有
,识别特定的类α的实体,则变成了共有 类的多标签分类问题。接下来的关键是损失函数的设计。最朴素的思路是变成
类的多标签分类问题。接下来的关键是损失函数的设计。最朴素的思路是变成 个二分类,然而实际使用时n往往并不小,那么
个二分类,然而实际使用时n往往并不小,那么 更大,而每个句子的实体数不会很多(每一类的实体数目往往只是个位数),所以如果是
更大,而每个句子的实体数不会很多(每一类的实体数目往往只是个位数),所以如果是 个二分类的话,会带来极其严重的类别不均衡问题。
个二分类的话,会带来极其严重的类别不均衡问题。
这时候我们之前研究的《将“softmax+交叉熵”推广到多标签分类问题》就可以派上用场了。简单来说,这是一个用于多标签分类的损失函数,它是单目标多分类交叉熵的推广,特别适合总类别数很大、目标类别数较小的多标签分类问题。其形式也不复杂,在GlobalPointer的场景,它为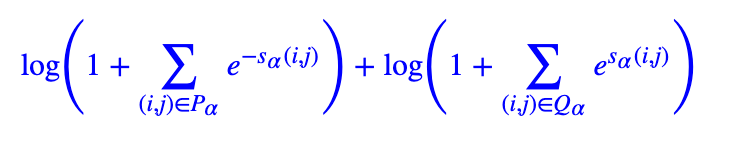
其中Pα是该样本的所有类型为α的实体的首尾集合,Qα是该样本的所有非实体或者类型非α的实体的首尾集合,注意我们只需要考虑i≤j的组合,即
而在解码阶段,所有满足 的片段
的片段 都被视为类型为α的实体输出。可见,解码过程是及其简单的,并且在充分并行下解码效率就是
都被视为类型为α的实体输出。可见,解码过程是及其简单的,并且在充分并行下解码效率就是 !
!
思考拓展#
在本节中,我们将进一步对CRF和GlobalPointer做一个理论上的对比,并且介绍一些与GlobalPointer相关的工作,以方便读者更好地理解和定位GlobalPointer。
相比CRF#
CRF(条件随机场,Conditional Random Field)是序列标注的经典设计,由于大多数NER也能转化为序列标注问题,所以CRF也算是NER的经典方法,笔者也曾撰写过《简明条件随机场CRF介绍(附带纯Keras实现)》和《你的CRF层的学习率可能不够大》等文章来介绍CRF。在之前的介绍中,我们介绍过,如果序列标注的标签数为kk,那么逐帧softmax和CRF的区别在于:
前者将序列标注看成是n个k分类问题,后者将序列标注看成是1个
分类问题。
这句话事实上也说明了逐帧softmax和CRF用于NER时的理论上的缺点。怎么理解呢?逐帧softmax将序列标注看成是n个k分类问题,那是过于宽松了,因为某个位置上的标注标签预测对了,不代表实体就能正确抽取出来了,起码有一个片段的标签都对了才算对;相反,CRF将序列标注看成是1个 分类问题,则又过于严格了,因为这意味着它要求所有实体都预测正确才算对,只对部分实体也不给分。虽然实际使用中我们用CRF也能出现部分正确的预测结果,但那只能说明模型本身的泛化能力好,CRF本身的设计确实包含了“全对才给分”的意思。
分类问题,则又过于严格了,因为这意味着它要求所有实体都预测正确才算对,只对部分实体也不给分。虽然实际使用中我们用CRF也能出现部分正确的预测结果,但那只能说明模型本身的泛化能力好,CRF本身的设计确实包含了“全对才给分”的意思。
所以,CRF在理论上确实都存在不大合理的地方,而相比之下,GlobalPointer则更加贴近使用和评测场景:它本身就是以实体为单位的,并且它设计为一个“多标签分类”问题,这样它的损失函数和评价指标都是实体颗粒度的,哪怕只对一部分也得到了合理的打分。因此,哪怕在非嵌套NER场景,GlobalPointer能取得比CRF好也是“情理之中”的。
相关工作#
如果读者比较关注实体识别、信息抽取的进展,那么应该可以发现,GlobalPointer与前段时间的关系抽取新设计TPLinker很相似。但事实上,这种全局归一化的思想,还可以追溯到更远。
对于笔者来说,第一次了解到这种思想,是在百度2017年发表的一篇《Globally Normalized Reader》,里边提出了一种用于阅读理解的全局归一化设计(GNR),里边不单单将(首, 尾)视为一个整体了,而是(句子, 首, 尾)视为一个整体(它是按照先选句子,然后在句子中选首尾的流程,所以多了一个句子维度),这样一来组合数就非常多了,因此它还用了《Sequence-to-Sequence Learning as Beam-Search Optimization》里边的思路来降低计算量。
有了GNR作铺垫,其实GlobalPointer就很容易可以想到的,事实上早在前年笔者在做LIC2019的关系抽取赛道的时候,类似的想法就已经有了,但是当时还有几个问题没有解决。
第一,当时Transformer还没有流行起来,总觉得 的复杂度很可怕;第二,当时《将“softmax+交叉熵”推广到多标签分类问题》也还没想出来,所以多标签分类的不均衡问题没有很好的解决方案;第三,当时笔者对NLP各方面的理解也还浅,bert4keras也没开发,一旦实验起来束手束脚的,出现问题也不知道往哪里调(比如开始没加上RoPE,降低了30个点以上,如果是两年前,我肯定没啥调优方案了)。
的复杂度很可怕;第二,当时《将“softmax+交叉熵”推广到多标签分类问题》也还没想出来,所以多标签分类的不均衡问题没有很好的解决方案;第三,当时笔者对NLP各方面的理解也还浅,bert4keras也没开发,一旦实验起来束手束脚的,出现问题也不知道往哪里调(比如开始没加上RoPE,降低了30个点以上,如果是两年前,我肯定没啥调优方案了)。
所以,GlobalPointer算是这两年来笔者经过各方面积累后的一个有点“巧合”但又有点“水到渠成”的工作。至于TPLinker,它还真跟GlobalPointer起源没什么直接联系。当然,在形式上GlobalPointer确实跟TPLinker很相似,事实上TPLinker还可以追溯到更早的《Joint entity recognition and relation extraction as a multi-head selection problem》,只不过这系列文章都主要是把这种Global的思想用于关系抽取了,没有专门针对NER优化。

若有收获,就点个赞吧
0 人点赞
