title: Simplify the Usage of Lexicon in Chinese NER
subtitle: 论文笔记
date: 2020-09-04
author: NSX
catalog: true
tags:
- 论文笔记
NER论文:Simplify the Usage of Lexicon in Chinese NER
本篇论文为避免设计复杂的模型结构、同时为便于迁移到其他序列标注框架,提出了一种在embedding层简单利用词汇的方法。本文先后对比了三种不同的融合词汇的方式:
第一种:Softword
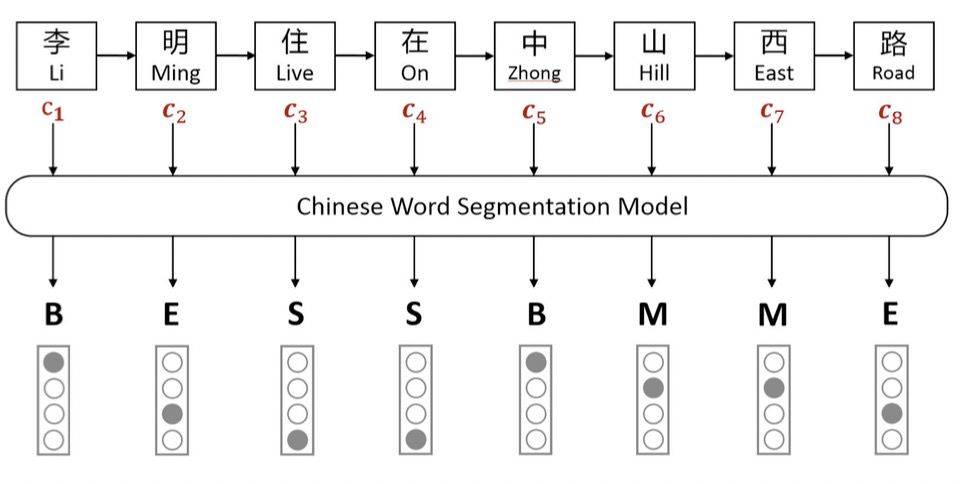 如上图所示,Softword通过中文分词模型后,对每一个字符进行BMESO的embedding嵌入。显而易见,这种Softword方式存在由分词造成的误差传播问题,同时也无法引入词汇对应word embedding。
如上图所示,Softword通过中文分词模型后,对每一个字符进行BMESO的embedding嵌入。显而易见,这种Softword方式存在由分词造成的误差传播问题,同时也无法引入词汇对应word embedding。
第二种:ExtendSoftword
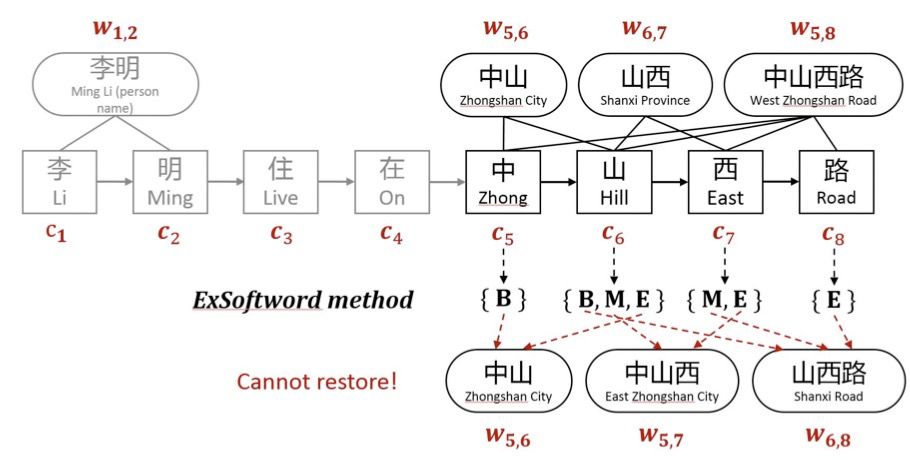 ExtendSoftword则将所有可能匹配到的词汇结果对字符进行编码表示。如上图中,对于字符「山」来说,其可匹配到的词汇有中山、中山西、山西路,「山」隶属 {B,M,E}。论文对于字符对应的词汇信息按照BMESO编码构建5维二元向量,如「山」表示为[1,1,1,0,0].
ExtendSoftword则将所有可能匹配到的词汇结果对字符进行编码表示。如上图中,对于字符「山」来说,其可匹配到的词汇有中山、中山西、山西路,「山」隶属 {B,M,E}。论文对于字符对应的词汇信息按照BMESO编码构建5维二元向量,如「山」表示为[1,1,1,0,0].
ExtendSoftword也会存在一些问题:1)仍然无法引入词汇对应的word embedding;2)也会造成信息损失,无法恢复词汇匹配结果,例如,假设有两个词汇列表[中山,山西,中山西路]和[中山,中山西,山西路],按照ExtendSoftword方式,两个词汇列表对应字符匹配结果是一致的;换句话说,当前ExtendSoftword匹配结果无法复原原始的词汇信息是怎样的,从而导致信息损失。
第三种:Soft-lexicon
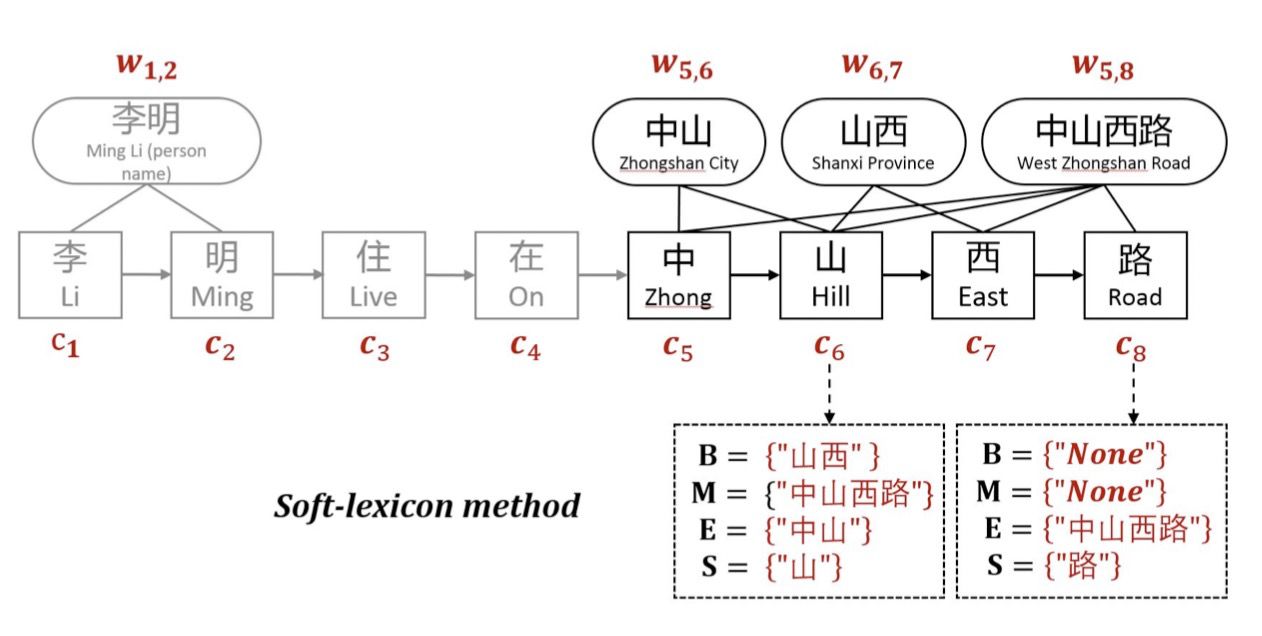 为了解决Softword和ExtendSoftword存在的问题,Soft-lexicon对当前字符,依次获取BMES对应所有词汇集合,然后再进行编码表示。
为了解决Softword和ExtendSoftword存在的问题,Soft-lexicon对当前字符,依次获取BMES对应所有词汇集合,然后再进行编码表示。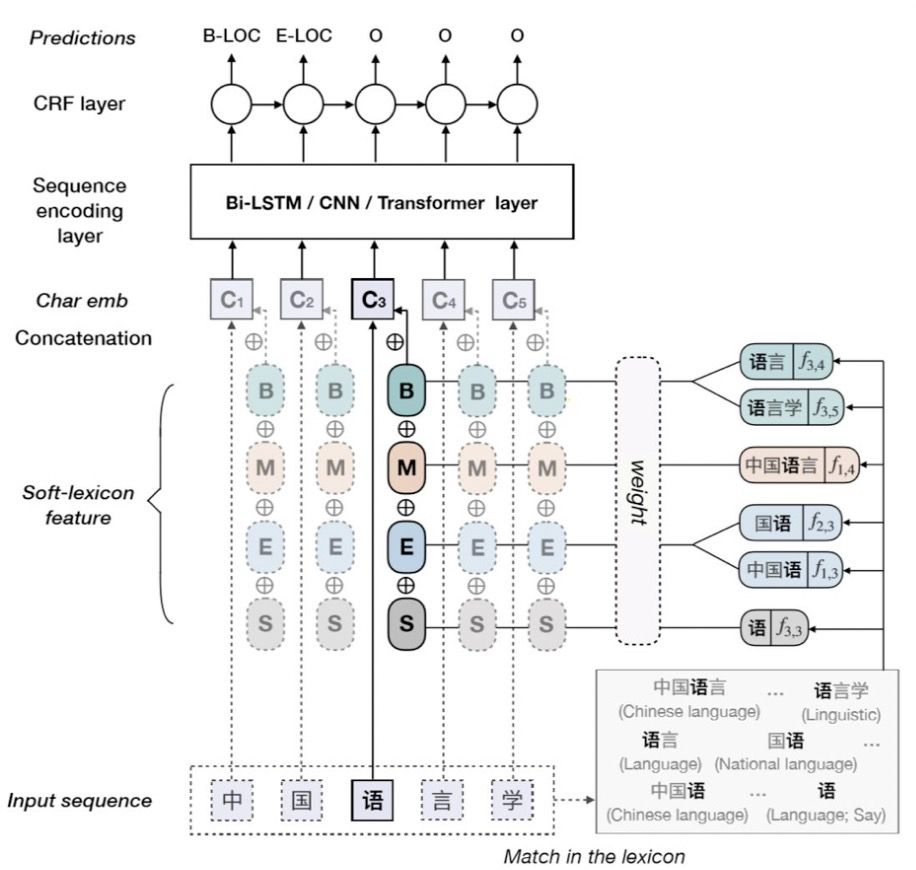
由上图可以看出,对于字符[语],其标签B对应的词汇集合涵盖[语言,语言学];标签M对应[中国语言];标签E对应[国语、中国语];标签S对应[语]。当前字符引入词汇信息后的特征表示为:
%3D%5Cleft%5B%5Cboldsymbol%7Bv%7D%5E%7Bs%7D(%5Cmathrm%7BB%7D)%20%5Coplus%20%5Cmathrm%7Bv%7D%5E%7B%5Cmathrm%7Bs%7D%7D(%5Cmathrm%7BM%7D)%20%5Coplus%20%5Cmathrm%7Bv%7D%5E%7B%5Cmathrm%7Bs%7D%7D(%5Cmathrm%7BE%7D)%20%5Coplus%20%5Cmathrm%7Bv%7D%5E%7B%5Cmathrm%7Bs%7D%7D(%5Cmathrm%7BS%7D)%5Cright%5D%2C%20%5C%5C%0A%5Cmathbf%7Bx%7D%5E%7Bc%7D%20%5Cleftarrow%5Cleft%5B%5Cmathbf%7Bx%7D%5E%7Bc%7D%20%3B%20%5Cboldsymbol%7Be%7D%5E%7Bs%7D(%5Cmathrm%7BB%7D%2C%20%5Cmathrm%7BM%7D%2C%20%5Cmathrm%7BE%7D%2C%20%5Cmathrm%7BS%7D)%5Cright%5D%0A%5Cend%7Barray%7D%0A#card=math&code=%5Cbegin%7Barray%7D%7Br%7D%0Ae%5E%7Bs%7D%28%5Cmathrm%7BB%7D%2C%20%5Cmathrm%7BM%7D%2C%20%5Cmathrm%7BE%7D%2C%20%5Cmathrm%7BS%7D%29%3D%5Cleft%5B%5Cboldsymbol%7Bv%7D%5E%7Bs%7D%28%5Cmathrm%7BB%7D%29%20%5Coplus%20%5Cmathrm%7Bv%7D%5E%7B%5Cmathrm%7Bs%7D%7D%28%5Cmathrm%7BM%7D%29%20%5Coplus%20%5Cmathrm%7Bv%7D%5E%7B%5Cmathrm%7Bs%7D%7D%28%5Cmathrm%7BE%7D%29%20%5Coplus%20%5Cmathrm%7Bv%7D%5E%7B%5Cmathrm%7Bs%7D%7D%28%5Cmathrm%7BS%7D%29%5Cright%5D%2C%20%5C%5C%0A%5Cmathbf%7Bx%7D%5E%7Bc%7D%20%5Cleftarrow%5Cleft%5B%5Cmathbf%7Bx%7D%5E%7Bc%7D%20%3B%20%5Cboldsymbol%7Be%7D%5E%7Bs%7D%28%5Cmathrm%7BB%7D%2C%20%5Cmathrm%7BM%7D%2C%20%5Cmathrm%7BE%7D%2C%20%5Cmathrm%7BS%7D%29%5Cright%5D%0A%5Cend%7Barray%7D%0A)
很容易理解,上述公式则将BMES对应的词汇编码 与字符编码
进行拼接。
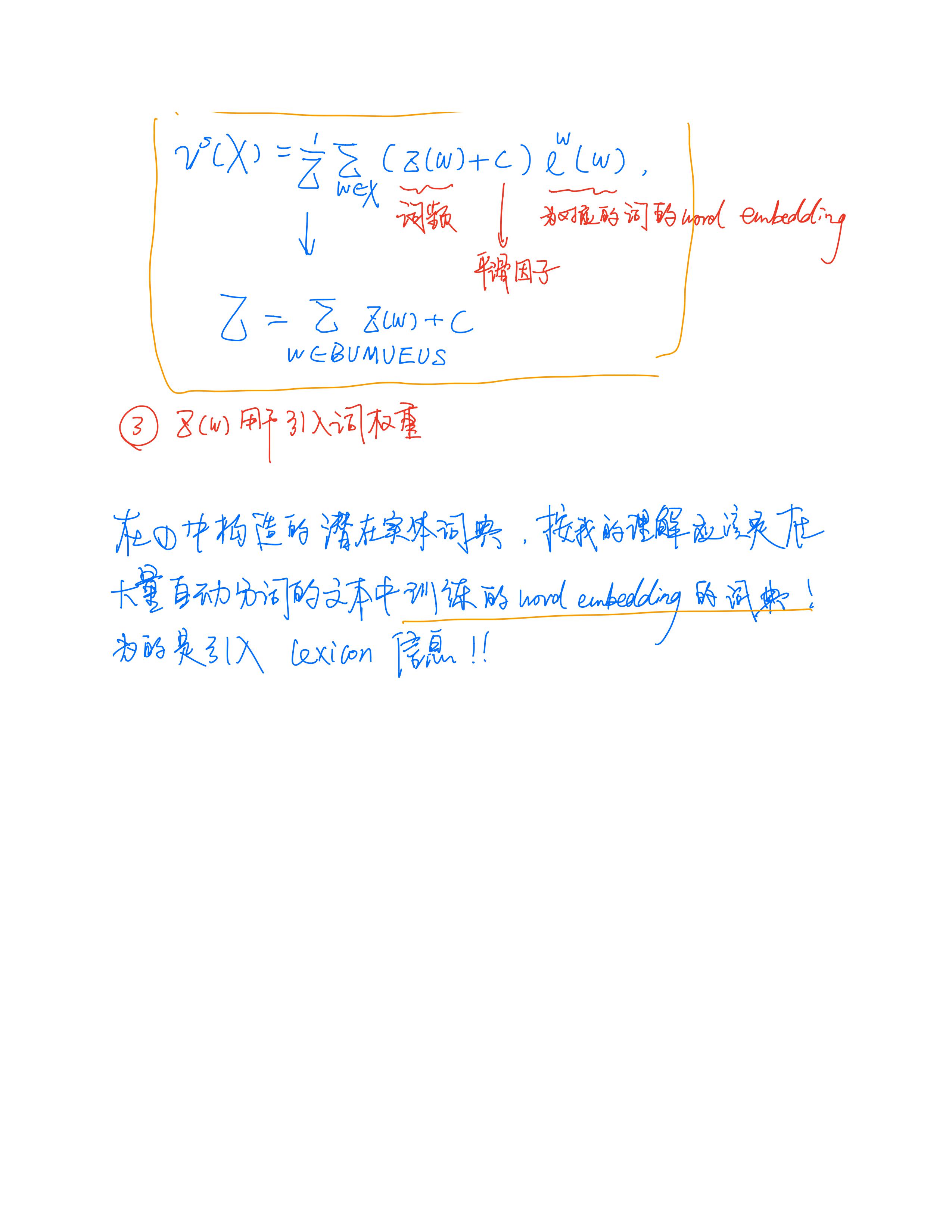
表示当前标签(BMES)下对应的词汇集合编码,其计算方式为:
%3D%5Cfrac%7B1%7D%7BZ%7D%20%5Csum%7Bw%20%5Cin%20S%7D%20z(w)%20%5Cboldsymbol%7Be%7D%5E%7Bw%7D(w)%0A#card=math&code=%5Cboldsymbol%7Bv%7D%5E%7Bs%7D%28S%29%3D%5Cfrac%7B1%7D%7BZ%7D%20%5Csum%7Bw%20%5Cin%20S%7D%20z%28w%29%20%5Cboldsymbol%7Be%7D%5E%7Bw%7D%28w%29%0A)
S 为词汇集合, Z(w) 代表词频。考虑计算复杂度,本文没有采取动态加权方法,而采取如同上式的静态加权方法,即:对词汇集合中的词汇对应的word embedding通过其词频大小进行加权。词频根据训练集和测试集可离线统计。
综上可见,Soft-lexicon这种方法没有造成信息损失,同时又可以引入word embedding,此外,本方法的一个特点就是模型无关,可以适配于其他序列标注框架。
总结与对比:关键结果分析
基于如何更好的融入词汇信息为出发点,无外于两点:
如何更充分的利用词汇信息、最大程度避免词汇信息损失;
如何设计更为兼容词汇的Architecture,加快推断速度。
笔记

参考资料
https://blog.csdn.net/Wangpeiyi9979/article/details/102782954
Simple-Lexicon:Simplify the Usage of Lexicon in Chinese NER(ACL2020)

若有收获,就点个赞吧
0 人点赞
