title: Lightgbm使用指南
subtitle: Lightgbm调参方法以及optuna超参数优化
date: 2020-08-24
author: NSX
catalog: true
tags:
- 技术
Lightgbm介绍
基于决策树算法,用于排名,分类和其他机器学习任务
LightGBM 是Light Gradient Boosted Machine的缩写,即梯度提升树算法,其在各方面继续延续了Xgboost那一套集成学习方法,Light是轻量级的意思,其关注的是模型训练速度,其也是LightGBM提出的初衷。LightGBM 框架支持不同的算法,包括GBT,GBDT,GBRT,GBM和MART。
本文简单对Lightgbm的源码进行分析并介绍它的使用和调参方法,最后给出一个实用超参数优化库optuna来帮助实现参数的随机搜索!
- LightGBM的介绍及优势
- LightGBM的使用(代码)
- LightGBM的调参指导
- LightGBM的API接口方法
- 附录:optuna超参数优化
LightGBM在哪些地方进行了优化 (区别XGBoost)?
参考《LightGBM——提升机器算法(图解+理论)》、《LightGBM源码阅读+理论分析(处理特征类别,缺省值的实现细节)》
- 基于Histogram的决策树算法(直方图优化)
- LightGBM的生长策略(基于最大深度的Leaf-wise)
- 直方图做差加速
- 支持类别特征
- Cache命中率优化
- 支持并行学习

1.1 直方图优化
直方图算法的基本思想是先把连续的浮点特征值离散化成k个整数(其实又是分桶的思想,而这些桶称为bin,比如[0,0.1)→0, [0.1,0.3)→1),同时构造一个宽度为k的直方图。
在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。

使用直方图算法有很多优点。首先,最明显就是内存消耗的降低,直方图算法不仅不需要额外存储预排序的结果,而且可以只保存特征离散化后的值,而这个值一般用8位整型存储就足够了,内存消耗可以降低为原来的1/8。然后在计算上的代价也大幅降低,预排序算法每遍历一个特征值就需要计算一次分裂的增益,而直方图算法只需要计算k次(k可以认为是常数),时间复杂度从O(#data#feature)优化到O(k#features)。
1.2 带深度限制的Leaf-wise的叶子生长策略
在XGBoost中,树是按层生长的,称为Level-wise tree growth,同一层的所有节点都做分裂,最后剪枝,如下图所示:

Level-wise过一次数据可以同时分裂同一层的叶子,容易进行多线程优化,也好控制模型复杂度,不容易过拟合。但实际上Level-wise是一种低效的算法,因为它不加区分的对待同一层的叶子,带来了很多没必要的开销,因为实际上很多叶子的分裂增益较低,没必要进行搜索和分裂。
在Histogram算法之上,LightGBM进行进一步的优化。首先它抛弃了大多数GBDT工具使用的按层生长 (level-wise)
的决策树生长策略,而使用了带有深度限制的按叶子生长 (leaf-wise)算法。

Leaf-wise则是一种更为高效的策略,每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。因此同Level-wise相比,在分裂次数相同的情况下,Leaf-wise可以降低更多的误差,得到更好的精度。Leaf-wise的缺点是可能会长出比较深的决策树,产生过拟合。因此LightGBM在Leaf-wise之上增加了一个最大深度的限制,在保证高效率的同时防止过拟合。
1.3 直方图做差优化
LightGBM另一个优化是Histogram(直方图)做差加速。一个容易观察到的现象:一个叶子的直方图可以由它的父亲节点的直方图与它兄弟的直方图做差得到。通常构造直方图,需要遍历该叶子上的所有数据,但直方图做差仅需遍历直方图的k个桶。
利用这个方法,LightGBM可以在构造一个叶子的直方图后,可以用非常微小的代价得到它兄弟叶子的直方图,在速度上可以提升一倍。

1.4 直接支持类别特征
实际上大多数机器学习工具都无法直接支持类别特征,一般需要把类别特征,转化到多维的0/1特征,降低了空间和时间的效率。而类别特征的使用是在实践中很常用的。
基于这个考虑,LightGBM优化了对类别特征的支持,可以直接输入类别特征,不需要额外的0/1展开。并在决策树算法上增加了类别特征的决策规则。在Expo数据集上的实验,相比0/1展开的方法,训练速度可以加速8倍,并且精度一致。LightGBM是第一个直接支持类别特征的GBDT工具。

1.5 Cache命中率优化
当我们用数据的bin描述数据特征的时候带来的变化:首先是不需要像预排序算法那样去存储每一个排序后数据的序列,也就是下图灰色的表,在LightGBM中,这部分的计算代价是0;第二个,一般bin会控制在一个比较小的范围,所以我们可以用更小的内存来存储
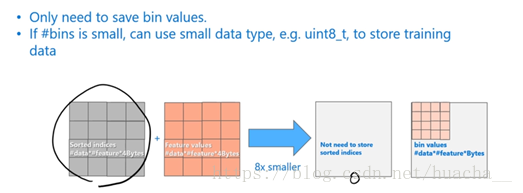
1.6 支持并行学习
LightGBM原生支持并行学习,目前支持特征并行(Featrue Parallelization)和数据并行(Data Parallelization)两种,还有一种是基于投票的数据并行(Voting Parallelization)
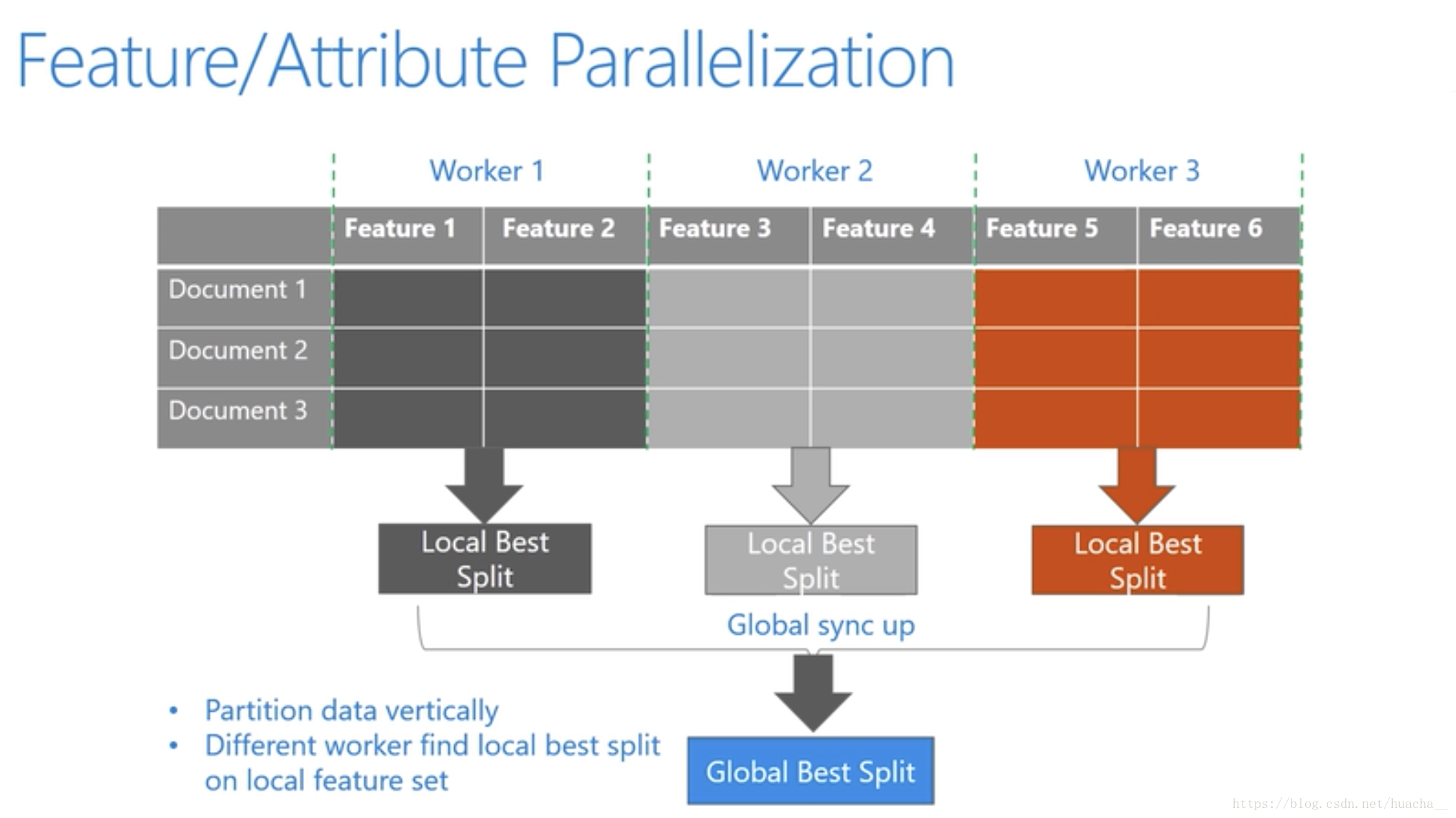
- 特征并行的主要思想是在不同机器、在不同的特征集合上分别寻找最优的分割点,然后在机器间同步最优的分割点。
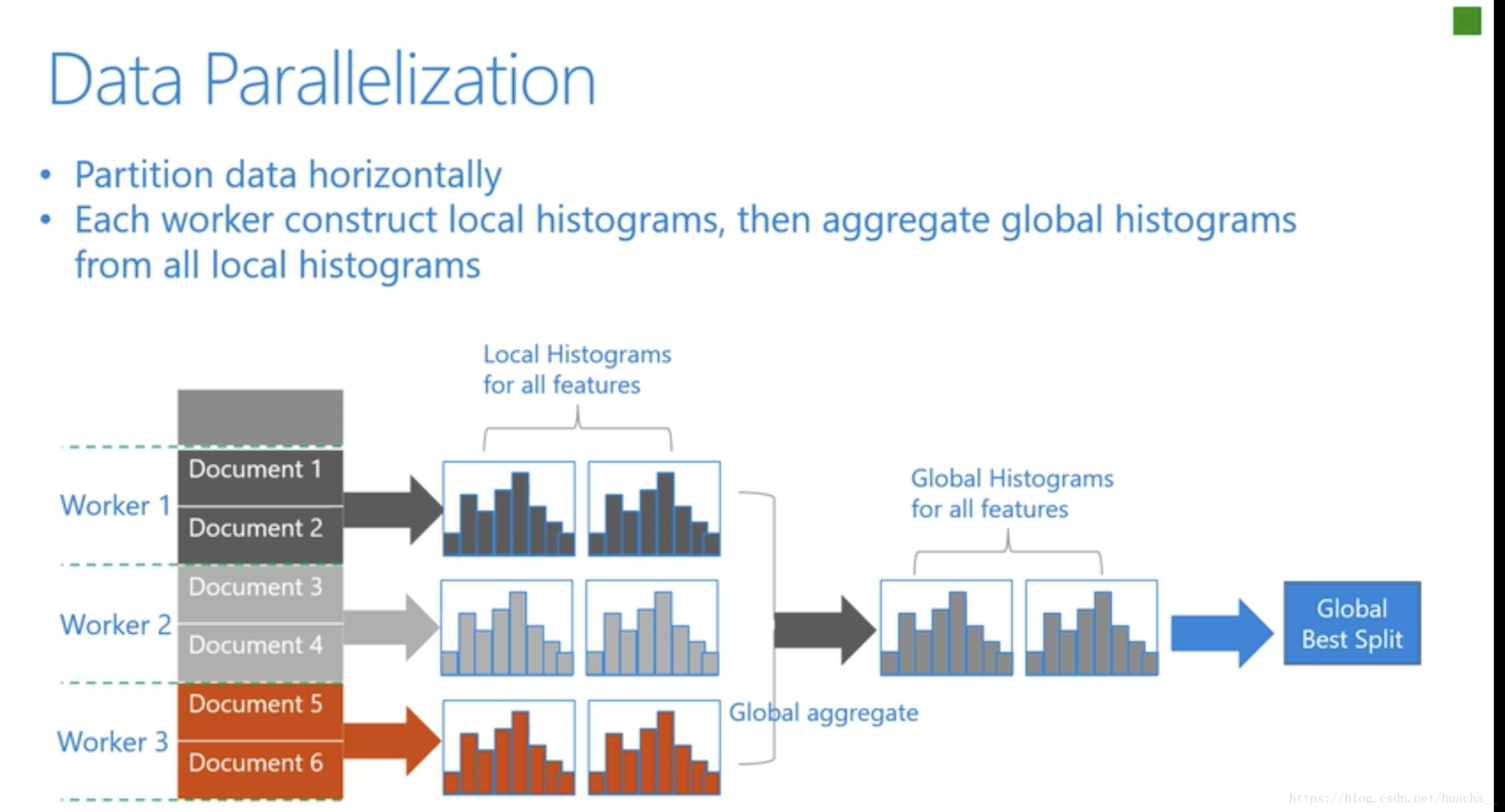
- 数据并行则是让不同的机器先在本地构造直方图,然后进行全局的合并,最后在合并的直方图上面寻找最优分割点。
LightGBM针对这两种并行方法都做了优化。
- 特征并行算法中,通过在本地保存全部数据避免对数据切分结果的通信。
- 数据并行中使用分散规约 (Reduce scatter) 把直方图合并的任务分摊到不同的机器,降低通信和计算,并利用直方图做差,进一步减少了一半的通信量。
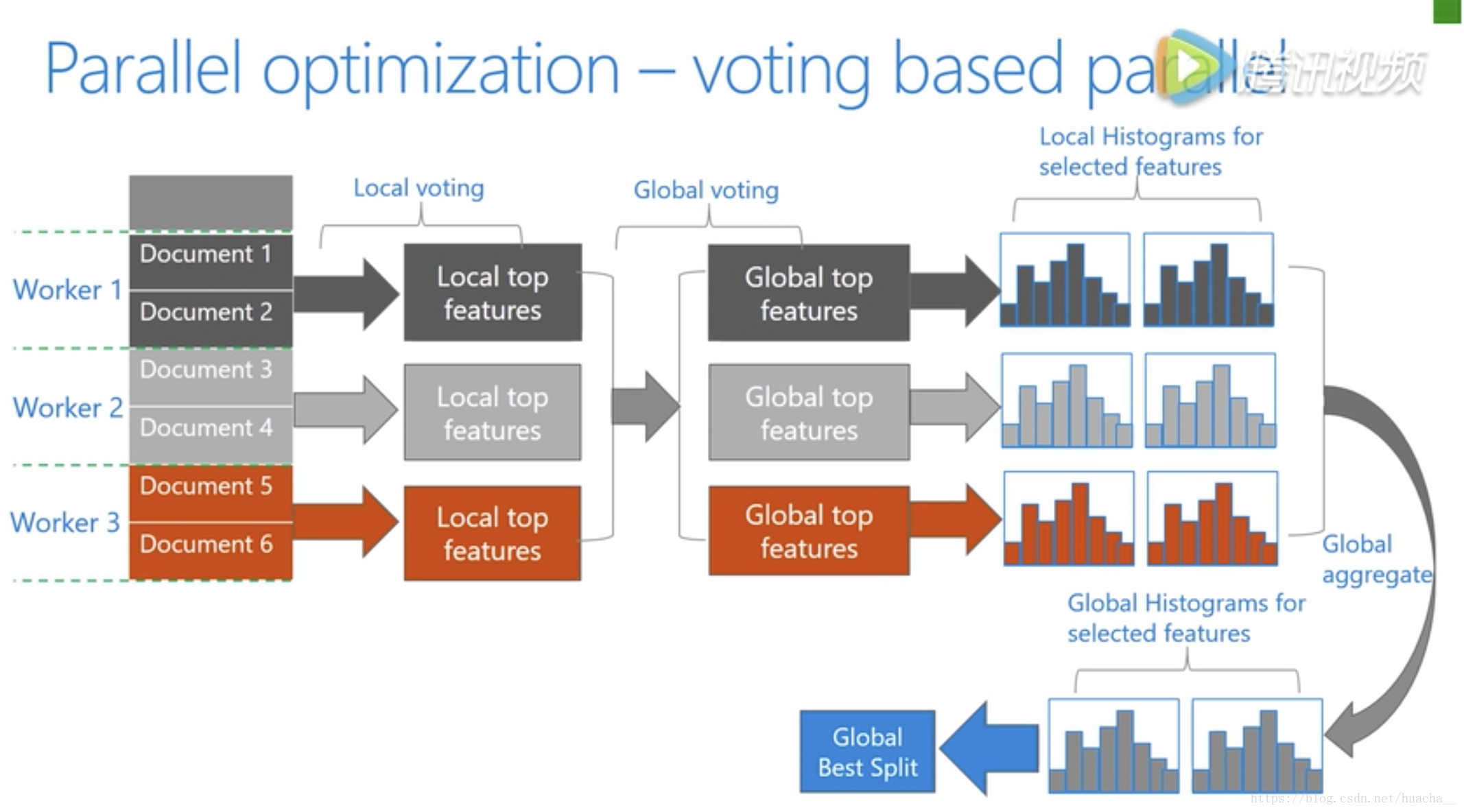
- 基于投票的数据并行(Voting Parallelization)则进一步优化数据并行中的通信代价,使通信代价变成常数级别。在数据量很大的时候,使用投票并行可以得到非常好的加速效果。
下图更好的说明了以上这三种并行学习的整体流程:
在直方图合并的时候,通信代价比较大,基于投票的数据并行能够很好的解决这一点。
1.7 LightGBM vs. XGBoost
下面这个表格给出了XGBoost和LightGBM (Light Gradient Boosting Machine)之间更加细致的性能对比,包括了树的生长方式,LightGBM是直接去选择获得最大收益的结点来展开,而XGBoost是通过按层增长的方式来做,这样呢LightGBM能够在更小的计算代价上建立我们需要的决策树。当然在这样的算法中我们也需要控制树的深度和每个叶子结点的最小数据量,从而减少过拟合。
| XGBoost | LightGBM | |
|---|---|---|
| 树木生长算法 | 按层生长的方式有利于工程优化,但对学习模型效率不高 | 直接选择最大收益的节点来展开,在更小的计算代价上去选择我们需要的决策树控制树的深度和每个叶子节点的数据量,能减少过拟合 |
| 划分点搜索算 法 | 对特征预排序的方法 | 直方图算法:将特征值分成许多小筒,进而在筒上搜索分裂点,减少了计算代价和存储代价,得到更好的性能。另外数据结构的变化使得在细节处的变化理上效率会不同 |
| 内存开销 | 8个字节 | 1个字节 |
| 划分的计算增益 | 数据特征 | 容器特征 |
| 高速缓存优化 | 无 | 在Higgs数据集上加速40% |
| 类别特征处理 | 无 | 在Expo数据集上速度快了8倍 |
Lightgbm的实战应用(代码)
参考:
1、用lightgbm算法实现鸢尾花种类的分类任务,GitHub:点击进入
lightgbm的使用起来也很简单。大致步骤可以分为下面几个
- 首先用lgb包的DataSet类包装一下需要测试的数据;
- 将lightgbm的参数构成一个dict字典格式的变量
- 将参数字典,训练样本,测试样本,评价指标一股脑的塞进lgb.train()方法的参数中去
- 上一步的方法会自觉地得到最佳参数和最佳的模型,保存模型
- 使用模型进行测试集的预测
其中比较重要的是第二步也就是设置参数。有很多很重要的参数,在下面的第二部分(参数字典)中,我大概介绍一下使用的比较多的比较有意义的参数。
1. 安装
pip install lightgbmpip install --no-binary :all: lightgbm #从源码编译安装pip install lightgbm --install-option=--mpi #从源码编译安装 MPI 版本pip install lightgbm --install-option=--gpu #从源码编译安装 GPU 版本
2. 定义数据集
lightgbm的一些特点:
- LightGBM 支持 CSV, TSV 和 LibSVM 格式的输入数据文件。
- LightGBM 可以直接使用 categorical feature(类别特征)(不需要单独编码)。 Expo data 实验显示,与 one-hot 编码相比,其速度提高了 8 倍。可以在包装数据的时候指定哪些属性是类别特征(也可以使用pd.DataFrame存放特征X, 每一列表示1个特征, 将类别特征设置为X[cat_cols].astype(‘category’). 这样模型在fit时会自动识别类别特征 参考)
- LightGBM 也支持加权训练,可以在包装数据的时候指定每条记录的权重
LightGBM 中的 Dataset 对象由于只需要保存 discrete bins(离散的数据块), 因此它具有很好的内存效率. 然而, Numpy/Array/Pandas 对象的内存开销较大. 如果你关心你的内存消耗. 您可以根据以下方式来节省内存:
- 在构造 Dataset 时设置 free_raw_data=True (默认为 True)
- 在 Dataset 被构造完之后手动设置 raw_data=None
- 调用 gc
LightGBM Python 模块能够使用以下几种方式来加载数据:
- libsvm/tsv/csv txt format file(libsvm/tsv/csv 文本文件格式)
- Numpy 2D array, pandas object(Numpy 2维数组, pandas 对象)
- LightGBM binary file(LightGBM 二进制文件)
加载后的数据存在 Dataset 对象中.
要加载 numpy 数组到 Dataset 中:
# data = np.arange(0, 5000).reshape((500, 10))data = np.random.rand(500, 10) # 500 个样本, 每一个包含 10 个特征label = np.random.randint(2, size=500) # 二元目标变量, 0 和 1train_data = lgb.Dataset(data, label=label)
在现实情况下,我们可能之前使用的是pandas的dataFrame格式在训练数据,那也没有关系,可以先使用sklearn包对训练集和测试集进行划分,然后再使用DataSet类包装。DataSet第一个参数是训练特征,第二个参数是标签
from sklearn.model_selection import train_test_splitX_train,X_val,y_train,y_val = train_test_split(X,Y,test_size=0.2)xgtrain = lgb.Dataset(X_train, y_train)xgvalid = lgb.Dataset(X_val, y_val, reference=xgtrain)
在 LightGBM 中, 验证数据应该与训练数据一致(格式一致).
保存 Dataset 到 LightGBM 二进制文件将会使得加载更快速:
train_data = lgb.Dataset('train.svm.txt')train_data.save_binary('train.bin')
指定 feature names(特征名称)和 categorical features(分类特征),注意在你构造 Dataset 之前, 你应该将分类特征转换为 int 类型的非负整数。还可以指定每条数据的权重(比如在样本规模不均衡的时候希望少样本的标签对应的记录可以拥有较大的权重)
w = np.random.rand(500, )train_data = lgb.Dataset(data, label=label, feature_name=['c1', 'c2', 'c3'], categorical_feature=['c3'],weight=w)
或者
train_data = lgb.Dataset(data, label=label, group=group_x)w = np.random.rand(500, )train_data.set_weight(w)
3. 设置参数
- 参数字典
每个参数的含义后面介绍(使用max_position设置NDCG优化的位置)
# 将参数写成字典下形式lgb_params = {"task": "train", # task type, support train and predict"objective": "lambdarank", # 排序任务(目标函数)"boosting_type": "gbdt", # 基学习器 gbrt dart"metric": {'ndcg', 'map'}, # 评估函数# "ndcg_at": [1, 3, 5],# "max_position": 5, # @NDCG 位置优化 5"train_metric": True, # 训练时就输出度量结果 True"tree_learner": "serial", # 用于并行学习"num_threads": 1, # 线程数,可以限制模型训练时CPU的占用率!!!"verbose": -1, # <0 显示致命的, =0 显示错误 (警告), >0 显示信息'learning_rate': 0.05, # 学习速率'max_depth': -1,'num_leaves': 31, # 叶子节点数,一般设为少于2^(max_depth)'max_bin': 256, # 设置连续特征或大量类型的离散特征的bins的数量'feature_fraction': 0.8, # 特征采样'bagging_fraction': 0.8, # 数据采样'bagging_freq': 5, # k 意味着每 k 次迭代执行bagging'lambda_l1': 0.1,'lambda_l2': 0.1,'min_split_gain': 0.8,'is_unbalance': 'true', #当训练数据是不平衡的,正负样本相差悬殊的时候,可以将这个属性设为true,此时会自动给少的样本赋予更高的权重}
- 自定义评价函数
评价函数可以是自定义的,也可以是sklearn中使用的。这里是一个自定义的评价函数写法:
def feval_spec(preds, train_data):from sklearn.metrics import roc_curvefpr, tpr, threshold = roc_curve(train_data.get_label(), preds)tpr0001 = tpr[fpr <= 0.0005].max()tpr001 = tpr[fpr <= 0.001].max()tpr005 = tpr[fpr <= 0.005].max()#tpr01 = tpr[fpr.values <= 0.01].max()tprcal = 0.4 * tpr0001 + 0.3 * tpr001 + 0.3 * tpr005return 'spec_cal',tprcal,Truelgb.train(feval=feval_spec)
如果是自定义的评价函数,那么需要函数的输入是预测值、输入数据。返回参数有三个,第一个是评价指标名称、第二个是评价值、第三个是True表示成功。
4. 模型训练
4.1基础版
训练一个模型时, 需要一个 parameter list(参数列表、字典)和 data set(数据集)这里使用上面定义的param参数字典和上面提到的训练数据:
num_round = 10bst = lgb.train(param, train_data, num_round, valid_sets=[test_data])
4.2 交叉验证
时间充足的时候,应该使用交叉验证来选择最好的训练模型,使用 5-折 方式的交叉验证来进行训练(4 个训练集, 1 个测试集):
num_round = 10lgb.cv(param, train_data, num_round, nfold=5)
4.3 提前停止
如果您有一个验证集, 你可以使用提前停止找到最佳数量的 boosting rounds(梯度次数). 提前停止需要在 valid_sets 中至少有一个集合. 如果有多个,它们都会被使用:
bst = lgb.train(param, train_data, num_round, valid_sets=valid_sets,early_stopping_rounds=10)bst.save_model('model.txt', num_iteration=bst.best_iteration)
该模型将开始训练, 直到验证得分停止提高为止. 验证错误需要至少每个 early_stopping_rounds 减少以继续训练.
如果提前停止, 模型将有 1 个额外的字段: bst.best_iteration. 请注意 train() 将从最后一次迭代中返回一个模型, 而不是最好的一个.. 请注意, 如果您指定多个评估指标, 则它们都会用于提前停止.
提前停止可以节约训练的时间。
4.4 查看特征重要性
# feature namesprint('Feature names:', gbm.feature_name())# feature importancesprint('Feature importances:', list(gbm.feature_importance()))
4.5 动态调整模型超参数
# decay learning rates# learning_rates accepts:# 1. list/tuple with length = num_boost_round# 2. function(curr_iter)gbm = lgb.train(params,lgb_train,num_boost_round=10,init_model=gbm,learning_rates=lambda iter: 0.05 * (0.99 ** iter),valid_sets=lgb_eval)print('Finished 20 - 30 rounds with decay learning rates...')# change other parameters during traininggbm = lgb.train(params,lgb_train,num_boost_round=10,init_model=gbm,valid_sets=lgb_eval,callbacks=[lgb.reset_parameter(bagging_fraction=[0.7] * 5 + [0.6] * 5)])print('Finished 30 - 40 rounds with changing bagging_fraction...')
5. 模型保存&加载
在训练完成后, 可以使用如下方式来存储模型:
bst.save_model('model.txt')# with open(model_path, "wb") as f:# pkl.dump(bst, f)# with open('model.json', 'w+') as f:# json.dump(bst, f, indent=4)
模型的重新载入:
bst = lgb.Booster(model_file='model.txt')# with open(model_path, "rb") as fin:# bst = pkl.load(fin)
已经训练或加载的模型都可以对数据集进行预测:
6. 预测
7 个样本, 每一个包含 10 个特征
data = np.random.rand(7, 10)ypred = bst.predict(data)
如果在训练过程中启用了提前停止, 可以用 bst.best_iteration 从最佳迭代中获得预测结果:
ypred = bst.predict(data, num_iteration=bst.best_iteration)
7. 自定义损失函数
# 类似在xgboost中的形式# 自定义损失函数def loglikelood(preds, train_data):labels = train_data.get_label()preds = 1. / (1. + np.exp(-preds))grad = preds - labelshess = preds * (1. - preds)return grad, hesslgb.train(fobj=loglikelood)
Lightgbm调参指导★
- 针对
leaf-wise树的参数优化:num_leaves:控制了叶节点的数目。它是控制树模型复杂度的主要参数。
如果是level-wise, 则该参数为 ,其中
,其中  为树的深度。
为树的深度。
但是当叶子数量相同时,leaf-wise的树要远远深过level-wise树,非常容易导致过拟合。因此应该让num_leaves小于
在
leaf-wise树中,并不存在depth的概念。因为不存在一个从leaves到depth的合理映射
min_data_in_leaf: 每个叶节点的最少样本数量。它是处理leaf-wise树的过拟合的重要参数。
将它设为较大的值,可以避免生成一个过深的树。但是也可能导致欠拟合。max_depth: 控制了树的最大深度。
该参数可以显式的限制树的深度。- 针对更快的训练速度:
- 通过设置
bagging_fraction和bagging_freq参数来使用 bagging 方法 - 通过设置
feature_fraction参数来使用特征的子抽样 - 使用较小的
max_bin - 使用
save_binary在未来的学习过程对数据加载进行加速- 获取更好的准确率:
- 使用较大的
max_bin(学习速度可能变慢) - 使用较小的
learning_rate和较大的num_iterations - 使用较大的
num_leaves(可能导致过拟合) - 使用更大的训练数据
- 尝试
dart- 缓解过拟合:
- 使用较小的
max_bin - 使用较小的
num_leaves - 使用
min_data_in_leaf和min_sum_hessian_in_leaf - 通过设置
bagging_fraction和bagging_freq来使用bagging - 通过设置
feature_fraction来使用特征子抽样 - 使用更大的训练数据
- 使用
lambda_l1,lambda_l2和min_gain_to_split来使用正则 - 尝试
max_depth来避免生成过深的树
核心参数
| 核心参数 | 含义 | 设置 |
|---|---|---|
| task | 要执行的任务 | train/predict/convert_model |
| application 或者objective 或者 app | 任务类型 | default = regression, options: regression, binary, multiclass, cross_entropy, cross_entropy_lambda, lambdarank, rank_xendcg, … |
| boosting或者boost或者boosting_type | 基学习器模型算法 | gbdt/rf/dart/goss |
| num_iteration或者num_tree或者 num_round或者 num_boost_round | 迭代次数 | 默认100 |
| learning_rate | 学习率 | 默认为 0.1 |
| num_leaves或者num_leaf | 一棵树上的叶子数 | 默认为 31 |
学习控制参数
| 学习控制参数 | 含义 | 设置 |
|---|---|---|
| max_depth | 树模型的最大深度 | 默认值为-1 |
| min_data_in_leaf | 一个叶子节点上包含的最少样本数量。 | 默认值为 20。将其设置的较大可以避免生成一个过深的树, 但有可能导致欠拟合 |
| feature_fraction | 如0.8 表示:在每棵树训练之前选择80% 的特征来训练 | 取值范围为[0.0,1.0], 默认值为1.0。降低过拟合 |
| bagging_fraction 或者 subsample | 如0.8 表示:在每棵树训练之前选择80% 的样本(非重复采样)来训练 | 取值范围为[0.0,1.0], 默认值为1.0。降低过拟合 |
| early_stopping_round或者early_stopping | 如果一个验证集的度量在early_stopping_round 循环中没有提升,则停止训练 | - |
| lambda_l1 或者reg_alpha | 表示L1正则化系数。 | 默认为0。降低过拟合 |
| lambda_l2 或者reg_lambda | 表示L2正则化系数。 | 默认为0。降低过拟合 |
| min_split_gain 或者min_gain_to_split | 一个浮点数,表示执行切分的最小增益 | 默认为0 |
| min_data_per_group | 表示每个分类组的最小数据量 用于排序任务 | 默认值为100 |
| cat_smooth | 用于category 特征的概率平滑,降低噪声在category 特征中的影响,尤其是对于数据很少的类。 | 默认值为 10 |
度量参数
| 度量参数 | 含义 | 设置 |
|---|---|---|
| metric | 度量的指标 | 对于回归问题,使用l2 ; 对于二分类问题,使用binary_logloss;对于lambdarank 问题,使用ndcg |
| metric_freq或者’output_freq | 一个正式,表示每隔多少次输出一次度量结果 | 默认为1 |
| train_metric 或者training_metric | 如果为True,则在训练时就输出度量结果 | 默认值为 False |
| ndcg_at 或者 ndcg_eval_at 或者eval_at | 指定了NDCG 评估点的位置。 | 默认为1,2,3,4,5 |
并行学习
lightgbm已经提供了以下并行学习算法:
| 并行算法 | 开启方式 | | —- | —- | | 数据并行 | tree_learner=’data’ | | 特征并行 | tree_learner=’feature’ | | 投票并行 | tree_learner=’voting’ |
tree_learner默认为'serial'。 表示串行学习。
调参示例
- 第一步:学习率和迭代次数我们先把学习率先定一个较高的值,这里取 learning_rate = 0.1,其次确定估计器boosting/boost/boosting_type的类型,不过默认都会选gbdt。
迭代的次数,也可以说是残差树的数目,参数名为n_estimators/num_iterations/num_round/num_boost_round。我们可以先将该参数设成一个较大的数 - 第二步:确定max_depth和num_leaves这是提高精确度的最重要的参数。这里我们引入sklearn里的GridSearchCV()函数进行搜索
- 第三步:确定min_data_in_leaf和max_bin
- 第四步:确定feature_fraction、bagging_fraction、bagging_freq
- 第五步:确定lambda_l1和lambda_l2
- 第六步:确定 min_split_gain
- 第七步:降低学习率,增加迭代次数,验证模型
Lightgbm API接口方法
数据接口 Dataset
Dataset: 由lightgbm内部使用的数据结构,它存储了数据集。class lightgbm.Dataset(data, label=None, max_bin=None, reference=None, weight=None, group=None, init_score=None, silent=False, feature_name='auto', categorical_feature='auto', params=None, free_raw_data=True)
- 参数:
data: 一个字符串、numpy array或者scipy.parse, 它指定了数据源。
如果是字符串,则表示数据源文件的文件名。label: 一个列表、1维的numpy array或者None, 它指定了样本标记。默认为None。max_bin: 一个整数或者None, 指定每个特征的最大分桶数量。默认为None。
如果为None,则从配置文件中读取。reference: 一个Dataset或者None。 默认为None。
如果当前构建的数据集用于验证集,则reference必须传入训练集。否则会报告has different bin mappers。weight: 一个列表、1维的numpy array或者None, 它指定了样本的权重。默认为None。group: 一个列表、1维的numpy array或者None, 它指定了数据集的group/query size。默认为None。init_score: 一个列表、1维的numpy array或者None, 它指定了Booster的初始score。默认为None。silent: 一个布尔值,指示是否在构建过程中输出信息。默认为Falsefeature_name: 一个字符串列表或者'auto',它指定了特征的名字。默认为'auto'- 如果数据源为
pandas DataFrame并且feature_name='auto',则使用DataFrame的column names
- 如果数据源为
categorical_feature: 一个字符串列表、整数列表、或者'auto'。它指定了categorical特征。默认为'auto'- 如果是整数列表,则给定了
categorical特征的下标 - 如果是字符串列表,在给定了
categorical特征的名字。此时必须设定feature_name参数。 - 如果是
'auto'并且数据源为pandas DataFrame,则DataFrame的categorical列将作为categorical特征
- 如果是整数列表,则给定了
params: 一个字典或者None,指定了其它的参数。默认为Nonefree_raw_data: 一个布尔值,指定是否在创建完Dataset之后释放原始的数据。默认为True
调用Dataset()之后,并没有构建完Dataset。 构建完需要等到构造一个Booster的时候。
- 方法:
.get_group(): 获取当前Dataset的groupget_xxx()等方法,都是调用的get_field()方法来实现的
- 返回值:一个`numpy array`,表示每个分组的`size` 。
.set_group(group): 设置当前Dataset的group- 参数:
group: 一个列表、numpy array或者None,表示每个分组的size。
- 参数:
.num_data(): 返回Dataset中的样本数量.num_feature(): 返回Dataset中的特征数量- 示例:
import lightgbm as lgbimport numpy as npclass DatasetTest:def __init__(self):self._matrix1 = lgb.Dataset('data/train.svm.txt')self._matrix2 = lgb.Dataset(data=np.arange(0, 12).reshape((4, 3)),label=[1, 2, 3, 4], weight=[0.5, 0.4, 0.3, 0.2],silent=False, feature_name=['a', 'b', 'c'])def print(self,matrix):'''Matrix 构建尚未完成时的属性:param matrix::return:'''print('data: %s' % matrix.data)print('label: %s' % matrix.label)print('weight: %s' % matrix.weight)print('init_score: %s' % matrix.init_score)print('group: %s' % matrix.group)def run_method(self,matrix):'''测试一些 方法:param matrix::return:'''print('get_ref_chain():', matrix.get_ref_chain(ref_limit=10))# get_ref_chain(): {<lightgbm.basic.Dataset object at 0x7f29cd762f28>}print('subset():', matrix.subset(used_indices=[0,1]))# subset(): <lightgbm.basic.Dataset object at 0x7f29a4aeb518>def test(self):self.print(self._matrix1)# data: data/train.svm.txt# label: None# weight: None# init_score: None# group: Noneself.print(self._matrix2)# data: [[ 0 1 2]# [ 3 4 5]# [ 6 7 8]# [ 9 10 11]]# label: [1, 2, 3, 4]# weight: [0.5, 0.4, 0.3, 0.2]# init_score: Noself.run_method(self._matrix2)
模型接口 lightgbm.train
lightgbm.train()函数执行直接训练。lightgbm.train(params, train_set, num_boost_round=100, valid_sets=None,valid_names=None, fobj=None, feval=None, init_model=None, feature_name='auto',categorical_feature='auto', early_stopping_rounds=None, evals_result=None,verbose_eval=True, learning_rates=None, keep_training_booster=False, callbacks=None)
参数:params: 一个字典,给出了训练参数train_set: 一个Dataset对象,给出了训练集num_boost_round: 一个整数,给出了boosting iteration的次数。默认为100valid_sets:一个Dataset的列表或者None,给出了训练期间用于evaluate的数据集。默认为Nonevalid_names:一个字符串列表或者None, 给出了valid_sets中每个数据集的名字。默认为Nonefobj:一个可调用对象或者None,表示自定义的目标函数。默认为Nonefeval:一个可调用对象或者None, 它表示自定义的evaluation函数。默认为None。它的输入为(y_true, y_pred)、或者( y_true, y_pred, weight)、或者(y_true, y_pred, weight, group), 返回一个元组:(eval_name,eval_result,is_higher_better)。或者返回该元组的列表。init_model:一个字符串或者None,它给出了lightgbm model保存的文件名,或者Booster实例的名字。后续的训练在该model或者Booster实例的基础上继续训练。默认为Nonefeature_name: 一个字符串列表或者'auto',它指定了特征的名字。默认为'auto'- 如果数据源为
pandas DataFrame并且feature_name='auto',则使用DataFrame的column names
- 如果数据源为
categorical_feature:一个字符串列表、整数列表、或者'auto'。它指定了categorical特征。默认为'auto'- 如果是整数列表,则给定了
categorical特征的下标 - 如果是字符串列表,在给定了
categorical特征的名字。此时必须设定feature_name参数。 - 如果是
'auto'并且数据源为pandas DataFrame,则DataFrame的categorical列将作为categorical特征
- 如果是整数列表,则给定了
early_stopping_rounds:一个整数或者None,表示验证集的score在连续多少轮未改善之后就早停。默认为None
该参数要求至少有一个验证集以及一个metric。
如果由多个验证集或者多个metric,则对所有的验证集和所有的metric执行。
如果发生了早停,则模型会添加一个best_iteration字段。该字段持有了最佳的迭代步。evals_result:一个字典或者None,这个字典用于存储在valid_sets中指定的所有验证集的所有验证结果。默认为Noneverbose_eval:一个布尔值或者整数。默认为True- 如果是
True,则在验证集上每个boosting stage打印对验证集评估的metric。 - 如果是整数,则每隔
verbose_eval个boosting stage打印对验证集评估的metric。 - 否则,不打印这些
- 如果是
该参数要求至少由一个验证集。
learning_rates:一个列表、None、 可调用对象。它指定了学习率。默认为None- 如果为列表,则它给出了每一个
boosting步的学习率 - 如果为一个可调用对象,则在每个
boosting步都调用它,从而生成一个学习率 - 如果为一个数值,则学习率在学习期间都固定为它。
- 如果为列表,则它给出了每一个
你可以使用学习率衰减从而生成一个更好的学习率序列。
keep_training_booster:一个布尔值,指示训练得到的Booster对象是否还会继续训练。默认为False- 如果为
False,则返回的booster对象在返回之前将被转换为_InnerPredictor。
当然你也可以将_InnerPredictor传递给init_model参数从而继续训练。
- 如果为
callbacks:一个可调用对象的列表,或者None。 它给出了在每个迭代步之后需要执行的函数。默认为None
返回:一个Booster 实例
lightgbm.cv()函数执行交叉验证训练。
绘图接口
https://www.bookstack.cn/read/huaxiaozhuan-ai/spilt.3.spilt.4.8d95f7184b045e7a.md
lightgbm.plot_importance(): 绘制特征的重要性。lightgbm.plot_metric(): 在训练过程中绘制一个metriclightgbm.plot_tree():绘制指定的树模型。lightgbm.create_tree_digraph(): 绘制指定的树模型,但是返回一个digraph,而不是直接绘制。
参考
https://www.jianshu.com/p/ba9ab1adbfe1
附录:自动超参数优化
网格搜索
lg = lgb.LGBMClassifier(silent=False)param_dist = {"max_depth": [4,5, 7],"learning_rate" : [0.01,0.05,0.1],"num_leaves": [300,900,1200],"n_estimators": [50, 100, 150]}grid_search = GridSearchCV(lg, n_jobs=-1, param_grid=param_dist, cv = 5, scoring="roc_auc", verbose=5)grid_search.fit(train,y_train)grid_search.best_estimator_, grid_search.best_score_
贝叶斯优化
import warningsimport timewarnings.filterwarnings("ignore")from bayes_opt import BayesianOptimizationdef lgb_eval(max_depth, learning_rate, num_leaves, n_estimators):params = {"metric" : 'auc'}params['max_depth'] = int(max(max_depth, 1))params['learning_rate'] = np.clip(0, 1, learning_rate)params['num_leaves'] = int(max(num_leaves, 1))params['n_estimators'] = int(max(n_estimators, 1))cv_result = lgb.cv(params, d_train, nfold=5, seed=0, verbose_eval =200,stratified=False)return 1.0 * np.array(cv_result['auc-mean']).max()lgbBO = BayesianOptimization(lgb_eval, {'max_depth': (4, 8),'learning_rate': (0.05, 0.2),'num_leaves' : (20,1500),'n_estimators': (5, 200)}, random_state=0)lgbBO.maximize(init_points=5, n_iter=50,acq='ei')print(lgbBO.max)
optuna超参数优化,参考《GIVE OPTUNA A SHOT!》
import optunadef objective(trial):x = trial.suggest_uniform('x', -10, 10)return (x - 2) ** 2study = optuna.create_study()study.optimize(objective, n_trials=100)study.best_params # E.g. {'x': 2.002108042}

若有收获,就点个赞吧
0 人点赞
