layout: post
title: FastAPI工程部署Gunicorn+Uvicorn
subtitle: FastAPI工程部署Gunicorn+Uvicorn
date: 2020-06-16
author: NSX
header-img: img/post-bg-ios9-web.jpg
catalog: true
tags:
- FastAPI
- Gunicorn
- Uvicorn
Gunicorn
- 什么是 Gunicorn ?
答:Gunicorn (‘Green Unicorn’) 是一个 UNIX 下的纯 Python WSGI 服务器。好的,那这是什么意思呢?
- Gunicorn 启动了被分发到的一个主线程,然后因此产生的子线程就是对应的 worker。
- 主进程的作用是确保 worker 数量与设置中定义的数量相同。因此如果任何一个 worker 挂掉,主线程都可以通过分发它自身而另行启动。
- worker 的角色是处理 HTTP 请求
- 操作系统的内核就负责处理 worker 进程之间的负载均衡。
它没有其它依赖,容易安装和使用。它所在的位置通常是在反向代理(如 Nginx)或者 负载均衡(如 AWS ELB)和一个 web 应用(比如 Django 或者 Flask)之间.
- 什么是WSGI?
Wsgi是同步通信服务规范,客户端请求一项服务,并等待服务完成,只有当它收到服务的结果时,它才会继续工作。当然了,可以定义一个超时时间,如果服务在规定的时间内没有完成,则认为调用失败,调用方继续工作。

Gunicorn参数说明
- 安装
pip install gunicornpip install gevent
- 启动参数说明
|
-c CONFIG, --config=CONFIG| 指定配置文件 | | | —- | —- | —- | |-b BIND, --bind=BIND| 绑定运行的主机加端口 | | |-w INT, --workers INT| 工作进程数 (Worker Processes) | 默认为1。这个配置用于指定处理请求的工作进程的数量,单核机器上这个数量一般在2-4个之间。你需要找到最适合该服务器的进程数。 | |-k STRTING, --worker-class STRTING| 工作模式(worker_class) | 默认的工作模式是sync。
一共有五种工作模式,分别是 sync(同步模式), eventlet(协程异步), gevent(协程异步), tornado, gthread。gevent中,不能使用multiprocess库。 | |--threads INT| 线程数(threads) | 表示每个工作进程处理请求的线程数。指定threads参数的话则工作模式自动变成gthread模式。 | |--worker-connections INT| 最大客户端并发数量,默认1000 | 每个工作线程同时存在的连接数,该参数仅在Eventlet和Gevent 两种工作模式下有效 | |--backlog int| 等待连接的最大数,默认2048 | | |-p FILE, --pid FILE| 设置pid文件的文件名,如果不设置将不会创建pid文件 | | |--access-logfile FILE| 日志文件路径 | | |--access-logformat STRING| 日志格式,--access_log_format '%(h)s %(l)s %(u)s %(t)s'| | |--error-logfile FILE, --log-file FILE| 错误日志文件路径 | | |--log-level LEVEL| 日志输出等级 | | |--limit-request-line INT| 限制HTTP请求行的允许大小,默认4094。取值范围0~8190,此参数可以防止任何DDOS攻击 | | |--limit-request-fields INT| 限制HTTP请求头字段的数量以防止DDOS攻击,与limit-request-field-size一起使用可以提高安全性。默认100,最大值32768 | | |--limit-request-field-size INT| 限制HTTP请求中请求头的大小,默认8190。值是一个整数或者0,当该值为0时,表示将对请求头大小不做限制 | | |-t INT, --timeout INT| 超时设置 | 工作进程在超过设置的超时时间内没有响应将会被杀死并重启。
当值为0就表示禁用超时设置。 | |--reload| 在代码改变时自动重启,默认False | | |--daemon| 是否以守护进程启动,默认False | | |--chdir| 在加载应用程序之前切换目录 | | |--graceful-timeout INT| 默认30,在超时(从接收到重启信号开始)之后仍然活着的工作将被强行杀死;一般默认 | | |--keep-alive INT| 连接的存活时间 | 默认值是2。连接超时时间,在keep-alive连接上等待请求的秒数,通常设置在1-5秒范围内。 | |--spew| 打印服务器执行过的每一条语句,默认False。此选择为原子性的,即要么全部打印,要么全部不打印 | | |--check-config| 显示当前的配置,默认False,即显示 | | |-e ENV, --env ENV| 设置环境变量 | |
- 配置文件示例
# 并行进程数workers = 4# 指定每个工作的线程数threads = 2# worker超时时间,超时重启timeout = 30# 监听端口8000bind = '0.0.0.0:8000'# 守护进程,将进程交给supervisor管理daemon = 'false'# 工作模式协程# worker_class = 'gevent'worker_class = "uvicorn.workers.UvicornWorker"# 最大并发量worker_connections = 1000# 进程文件pidfile = '/var/run/gunicorn.pid'# 访问日志和错误日志accesslog = '/var/log/gunicorn_acess.log'errorlog = '/var/log/gunicorn_error.log'# 日志级别loglevel = 'info'
- 启动
gunicorn -c gunicorn.conf main:app
关于如何配置 Gunicorn 的实用建议
为了提高使用 Gunicorn 时的性能,我们必须牢记 3 种并发方式:
第一种并发方式(workers 模式,又名 UNIX 进程模式)
每个worker都是一个加载 Python 应用程序的 UNIX 进程。worker之间没有共享内存。
建议的workers数量是(2*CPU)+1。
对于一个双核(两个CPU)机器,5 就是建议的worker数量。gunicorn --workers=5 main:app
第二种并发方式(多线程)
Gunicorn 还允许每个 worker 拥有多个线程。在这种场景下,Python 应用程序每个 worker 都会加载一次,同一个 worker 生成的每个线程共享相同的内存空间。
为了在 Gunicorn 中使用多线程。我们使用了threads模式。每一次我们使用threads模式,worker 的类就会是gthread:
在我们的例子里面最大的并发请求数就是worker * 线程,也就是10。
在使用worker和多线程模式时建议的最大并发数量仍然是(2*CPU)+1。gunicorn --workers=5 --threads=2 main:app
第三种并发方式(“伪线程”)
有一些 Python 库比如(gevent 和 Asyncio)可以在 Python 中启用多并发。那是基于协程实现的“伪线程”。
Gunicrn 允许通过设置对应的 worker 类来使用这些异步 Python 库。
这里的设置适用于我们想要在单核机器上运行的gevent:
在这种情况下,最大的并发请求数量是3000。(3 个 worker * 1000 个连接/worker)gunicorn --worker-class=gevent --worker-connections=1000 --workers=3 main:app
Uvicorn与Gunicorn一起使用
Uvicorn包括一个Gunicorn工人类,它使您可以运行ASGI应用程序,同时具有Uvicorn的所有性能优势,同时还为您提供Gunicorn的全功能进程管理。
在生产环境中,Guicorn 大概是最简单的方式来管理 Uvicorn 了,生产环境部署我们推荐使用 Guicorn 和 Uvicorn 的 worker 类,这样的话,可以动态增加或减少进程数量,平滑地重启工作进程,或者升级服务器而无需停机
gunicorn example:app -w 4 -k uvicorn.workers.UvicornWorker
Uvicorn
- 什么是 Uvicorn ?
答:Uvicorn 是基于 uvloop 和 httptools 构建的非常快速的 ASGI 服务器。
- 什么是 uvloop 和 httptools ?
答:uvloop 用于替换标准库 asyncio 中的事件循环,使用 Cython 实现,它非常快,可以使 asyncio 的速度提高 2-4 倍。asyncio 不用我介绍吧,写异步代码离不开它。httptools 是 nodejs HTTP 解析器的 Python 实现。
- 什么是ASGI?
Asgi是异步通信服务规范。客户端发起服务呼叫,但不等待结果。调用方立即继续其工作,并不关心结果。如果调用方对结果感兴趣,有一些机制可以让其随时被回调方法返回结果。

uvicorn设计的初衷?
- 使用
[uvloop](https://github.com/MagicStack/uvloop)和[httptools](https://github.com/MagicStack/httptools)实现一个极速的asyncio服务器。 - 实现一个基于
[ASGI(异步服务器网关接口)](http://channels.readthedocs.io/en/stable/asgi.html)的最小的应用程序接口。
- uvicorn 命令行选项
Usage: uvicorn [OPTIONS] APPOptions:--host TEXT 绑定套接字到ip地址,默认127.0.0.1--port INTEGER 绑定套接字到端口号,默认8000--uds TEXT 绑定到UNIX域套接字--fd INTEGER 从此文件描述符绑定到套接字--reload 启用自动重载(内容修改后)--reload-dir TEXT 显式设置重载目录,而不使用当前工作目录--workers INTEGER 工作进程数。不适用于--reload启用--loop [auto|asyncio|uvloop|iocp] 事件循环实现,默认:auto--http [auto|h11|httptools] HTTP协议实现,默认:auto--ws [auto|none|websockets|wsproto] WebSocket协议实现,默认:auto--lifespan [auto|on|off] 生命周期实施,默认:auto--interface [auto|asgi3|asgi2|wsgi] 应用程序界面选择,默认:auto--env-file PATH 环境配置文件--log-config PATH 日志配置文件--log-level [critical|error|warning|info|debug|trace]Log level. [default: info]--access-log / --no-access-log 启用/禁用访问日志--use-colors / --no-use-colors 启用/禁用彩色日志记录--proxy-headers / --no-proxy-headers启用/禁用X-Forwarded-Proto,X-Forwarded-For,X-Forwarded-Port以填充远程地址信息--forwarded-allow-ips TEXT 逗号分隔的IP列表,以信任代理标头。如果可用,则默认为$ FORWARDED_ALLOW_IPS环境变量,或者为'127.0.0.1'--root-path TEXT--limit-concurrency INTEGER 在发出HTTP 503响应之前允许的最大并发连接数或任务数。--backlog INTEGER 积压的最大连接数--limit-max-requests INTEGER 终止进程之前服务的最大请求数--timeout-keep-alive INTEGER 如果在此超时时间内未收到新数据,则关闭“保持活动”连接。 [默认值:5]--ssl-keyfile TEXT SSL key file--ssl-certfile TEXT SSL certificate file--ssl-version INTEGER 要使用的SSL版本 [默认值:2]--ssl-cert-reqs INTEGER 是否需要客户端证书 [默认值:0]--ssl-ca-certs TEXT CA证书文件--ssl-ciphers TEXT 要使用的密码 [默认值:TLSv1]--header TEXT 自定义默认HTTP响应标头--help 显示帮助消息并退出
有关更多信息,请参阅[设置文档](https://www.uvicorn.org/settings/)。
- 使用方法
# pip install uvicornuvicorn demo:app --host 0.0.0.0 --port 8080 --workers 10 --limit-concurrency 100 --timeout-keep-alive 5 --reload
import uvicornasync def app(scope, receive, send):...if __name__ == "__main__":uvicorn.run("example:app", host="127.0.0.1", port=5000, log_level="info")
supervisor
supervisor 是一款基于Python的进程管理工具,可以很方便的管理服务器上部署的应用程序。supervisor的功能如下:
a. 启动、重启、关闭包括但不限于python进程。
b.查看进程的运行状态。
c.批量维护多个进程。
为什么要用supervisor来管理进程,是因为相对于linux传统的进程管理(即系统自带的init 进程管理)方式来说,它有很多的优势:
1) 简单方便
a)supervisor管理进程,只要在supervisor的配置文件中,把要管理的进程的可执行文件的路径写进去就OK了;b)被管理进程作为supervisor的子进程,当子进程挂掉的时候,父进程可以准确获取子进程挂掉的信息的,所以也就可以对挂掉的子进程进行自动重启了, 至于重启还是不重启,也要看配置文件里面有没有设置autostart=true。
2) 精确
linux对进程状态的反馈有时候不太准确, 也就是说linux进程通常很难获得准确的up/down状态, Pidfiles经常说谎! 而supervisor监控子进程,得到的子进程状态无疑是准确的。supervisord将进程作为子进程启动,所以它总是知道其子进程的正确的up/down状态,可以方便的对这些数据进行查询.
3) 进程分组
进程支持分组启动和停止,也支持启动顺序,即‘优先级’,supervisor允许为进程分配优先级,并允许用户通过supervisorctl客户端发出命令,如“全部启动”和”重新启动所有“,它们以预先分配的优先级顺序启动。还可以将进程分为”进程组“,一组逻辑关联的进程可以作为一个单元停止或启动。进程组supervisor可以对进程组统一管理,也就是说我们可以把需要管理的进程写到一个组里面,然后把这个组作为一个对象进行管理,如启动,停止,重启等等操作。而linux系统则是没有这种功能的,想要停止一个进程,只能一个一个的去停止,要么就自己写个脚本去批量停止。
4) 集中式管理
supervisor管理的进程,进程组信息,全部都写在一个ini格式的文件里就OK了。管理supervisor时, 可以在本地进行管理,也可以远程管理,而且supervisor提供了一个web界面,可以在web界面上监控,管理进程。 当然了,本地,远程和web管理的时候,需要调用supervisor的xml_rpc接口。
5) 可扩展性
supervisor有一个简单的事件(event)通知协议,还有一个用于控制的XML-RPC接口,可以用Python开发人员来扩展构建。
6) 权限
总所周知, linux的进程特别是侦听在1024端口之下的进程,一般用户大多数情况下,是不能对其进行控制的。想要控制的话,必须要有root权限。然而supervisor提供了一个功能,可以为supervisord或者每个子进程,设置一个非root的user,这个user就可以管理它对应的进程了。
7) 兼容性,稳定性
supervisor由Python编写,在除Windows操作系统以外基本都支持,如linux,Mac OS x,solaris,FreeBSD系统
1.组成部分
Supervisor 包括以下四个组件:
- supervisord 服务端程序,主要功能是启动 supervisord 服务及其管理的子进程,记录日志,重启崩溃的子进程,等。
- supervisorctl supervisor命令行的客户端名称是supervisorctl。它为supervisord提供了一个类似于shell的交互界面。使用supervisorctl,用户可以查看不同的supervisord进程列表,获取控制子进程的状态,如停止和启动子进程
- Web Server 实现在界面上管理进程,还能查看进程日志和清除日志。
- XML-RPC 接口 可以通过 XML_RPC 协议对 supervisord 进行远程管理,达到和 supervisorctl 以及 Web Server 一样的管理功能。
Supervisor 管理的进程运行状态图: 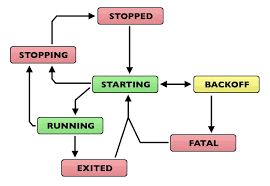
- running:进程处于运行状态
- starting:Supervisor 收到启动请求后,进程处于正在启动过程中
- stopped:进程处于关闭状态
- stopping:Supervisor 收到关闭请求后,进程处于正在关闭过程中
- backoff:进程进入 starting 状态后,由于马上就退出导致没能进入 running 状态
- fatal:进程没有正常启动
- exited:进程从 running 状态退出
2.安装
centos系统下可以直接yum安装, 前提是需要下载epel源, 下载地址: http://dl.fedoraproject.org/pub/epel/
yum install supervisor
3.常用命令
| supervisord | 初始启动Supervisord,启动、管理配置中设置的进程 |
|---|---|
| supervisorctl stop programxxx | 停止某一个进程 |
| supervisorctl start programxxx | 启动某个进程 |
| supervisorctl restart programxxx | 重启某个进程 |
| supervisorctl stop groupworker | 停止所有属于名为groupworker这个分组的进程(start,restart同理) |
| supervisorctl stop all | 停止全部进程,注:start、restart、stop都不会载入最新的配置文件 |
| supervisorctl reload | 载入最新的配置文件,停止原有进程并按新的配置启动、管理所有进程 |
| supervisorctl update | 根据最新的配置文件,启动新配置或有改动的进程,配置没有改动的进程不会受影响而重启 |
| supervisord -c /etc/supervisor/supervisord.conf | 制定让其读取的配置文件 |
| supervisorctl status programxxx | 查看状态 |
设置开机启动
centos7下:新建文件supervisord.service
#supervisord.service[Unit]Description=Supervisor daemon[Service]Type=forkingExecStart=/usr/bin/supervisord -c /etc/supervisord.confExecStop=/usr/bin/supervisorctl shutdownExecReload=/usr/bin/supervisorctl reloadKillMode=processRestart=on-failureRestartSec=42s[Install]WantedBy=multi-user.target
将文件拷贝到/usr/lib/systemd/system/
cp supervisord.service /usr/lib/systemd/system/
启动服务
systemctl enable supervisord
验证一下是否为开机启动
systemctl is-enabled supervisord
4.配置参数说明
[unix_http_server]file=/tmp/supervisor.sock ; socket文件的路径,supervisorctl用XML_RPC和supervisord通信就是通过它进行的。如果不设置的话,supervisorctl也就不能用了不设置的话,默认为none。 非必须设置;chmod=0700 ; 这个简单,就是修改上面的那个socket文件的权限为0700不设置的话,默认为0700。 非必须设置;chown=nobody:nogroup ; 这个一样,修改上面的那个socket文件的属组为user.group不设置的话,默认为启动supervisord进程的用户及属组。非必须设置;username=user ; 使用supervisorctl连接的时候,认证的用户不设置的话,默认为不需要用户。 非必须设置;password=123 ; 和上面的用户名对应的密码,可以直接使用明码,也可以使用SHA加密如:{SHA}82ab876d1387bfafe46cc1c8a2ef074eae50cb1d默认不设置。。。非必须设置;[inet_http_server] ; 侦听在TCP上的socket,Web Server和远程的supervisorctl都要用到他不设置的话,默认为不开启。非必须设置;port=127.0.0.1:9001 ; 这个是侦听的IP和端口,侦听所有IP用 :9001或*:9001。这个必须设置,只要上面的[inet_http_server]开启了,就必须设置它;username=user ; 这个和上面的uinx_http_server一个样。非必须设置;password=123 ; 这个也一个样。非必须设置[supervisord] ;这个主要是定义supervisord这个服务端进程的一些参数的这个必须设置,不设置,supervisor就不用干活了logfile=/tmp/supervisord.log ; 这个是supervisord这个主进程的日志路径,注意和子进程的日志不搭嘎。默认路径$CWD/supervisord.log,$CWD是当前目录。。非必须设置logfile_maxbytes=50MB ; 这个是上面那个日志文件的最大的大小,当超过50M的时候,会生成一个新的日志文件。当设置为0时,表示不限制文件大小默认值是50M,非必须设置。logfile_backups=10 ; 日志文件保持的数量,上面的日志文件大于50M时,就会生成一个新文件。文件数量大于10时,最初的老文件被新文件覆盖,文件数量将保持为10当设置为0时,表示不限制文件的数量。默认情况下为10。。。非必须设置loglevel=info ; 日志级别,有critical, error, warn, info, debug, trace, or blather等默认为info。。。非必须设置项pidfile=/tmp/supervisord.pid ; supervisord的pid文件路径。默认为$CWD/supervisord.pid。。。非必须设置nodaemon=false ; 如果是true,supervisord进程将在前台运行默认为false,也就是后台以守护进程运行。。。非必须设置minfds=1024 ; 这个是最少系统空闲的文件描述符,低于这个值supervisor将不会启动。系统的文件描述符在这里设置cat /proc/sys/fs/file-max默认情况下为1024。。。非必须设置minprocs=200 ; 最小可用的进程描述符,低于这个值supervisor也将不会正常启动。ulimit -u这个命令,可以查看linux下面用户的最大进程数默认为200。。。非必须设置;umask=022 ; 进程创建文件的掩码默认为022。。非必须设置项;user=chrism ; 这个参数可以设置一个非root用户,当我们以root用户启动supervisord之后。我这里面设置的这个用户,也可以对supervisord进行管理默认情况是不设置。。。非必须设置项;identifier=supervisor ; 这个参数是supervisord的标识符,主要是给XML_RPC用的。当你有多个supervisor的时候,而且想调用XML_RPC统一管理,就需要为每个supervisor设置不同的标识符了默认是supervisord。。。非必需设置;directory=/tmp ; 这个参数是当supervisord作为守护进程运行的时候,设置这个参数的话,启动supervisord进程之前,会先切换到这个目录默认不设置。。。非必须设置;nocleanup=true ; 这个参数当为false的时候,会在supervisord进程启动的时候,把以前子进程产生的日志文件(路径为AUTO的情况下)清除掉。有时候咱们想要看历史日志,当然不想日志被清除了。所以可以设置为true默认是false,有调试需求的同学可以设置为true。。。非必须设置;childlogdir=/tmp ; 当子进程日志路径为AUTO的时候,子进程日志文件的存放路径。默认路径是这个东西,执行下面的这个命令看看就OK了,处理的东西就默认路径python -c "import tempfile;print tempfile.gettempdir()"非必须设置;environment=KEY="value" ; 这个是用来设置环境变量的,supervisord在linux中启动默认继承了linux的环境变量,在这里可以设置supervisord进程特有的其他环境变量。supervisord启动子进程时,子进程会拷贝父进程的内存空间内容。 所以设置的这些环境变量也会被子进程继承。小例子:environment=name="haha",age="hehe"默认为不设置。。。非必须设置;strip_ansi=false ; 这个选项如果设置为true,会清除子进程日志中的所有ANSI 序列。什么是ANSI序列呢?就是我们的\n,\t这些东西。默认为false。。。非必须设置; the below section must remain in the config file for RPC; (supervisorctl/web interface) to work, additional interfaces may be; added by defining them in separate rpcinterface: sections[rpcinterface:supervisor] ;这个选项是给XML_RPC用的,当然你如果想使用supervisord或者web server 这个选项必须要开启的supervisor.rpcinterface_factory = supervisor.rpcinterface:make_main_rpcinterface[supervisorctl] ;这个主要是针对supervisorctl的一些配置serverurl=unix:///tmp/supervisor.sock ; 这个是supervisorctl本地连接supervisord的时候,本地UNIX socket路径,注意这个是和前面的[unix_http_server]对应的默认值就是unix:///tmp/supervisor.sock。。非必须设置;serverurl=http://127.0.0.1:9001 ; 这个是supervisorctl远程连接supervisord的时候,用到的TCP socket路径注意这个和前面的[inet_http_server]对应默认就是http://127.0.0.1:9001。。。非必须项;username=chris ; 用户名默认空。。非必须设置;password=123 ; 密码默认空。。非必须设置;prompt=mysupervisor ; 输入用户名密码时候的提示符默认supervisor。。非必须设置;history_file=~/.sc_history ; 这个参数和shell中的history类似,我们可以用上下键来查找前面执行过的命令默认是no file的。。所以我们想要有这种功能,必须指定一个文件。。。非必须设置; The below sample program section shows all possible program subsection values,; create one or more 'real' program: sections to be able to control them under; supervisor.;[program:theprogramname] ;这个就是咱们要管理的子进程了,":"后面的是名字,最好别乱写和实际进程有点关联最好。这样的program我们可以设置一个或多个,一个program就是要被管理的一个进程;command=/bin/cat ; 这个就是我们的要启动进程的命令路径了,可以带参数例子:/home/test.py -a 'hehe'有一点需要注意的是,我们的command只能是那种在终端运行的进程,不能是守护进程。这个想想也知道了,比如说command=service httpd start。httpd这个进程被linux的service管理了,我们的supervisor再去启动这个命令这已经不是严格意义的子进程了。这个是个必须设置的项;process_name=%(program_name)s ; 这个是进程名,如果我们下面的numprocs参数为1的话,就不用管这个参数了,它默认值%(program_name)s也就是上面的那个program冒号后面的名字,但是如果numprocs为多个的话,那就不能这么干了。想想也知道,不可能每个进程都用同一个进程名吧。;numprocs=1 ; 启动进程的数目。当不为1时,就是进程池的概念,注意process_name的设置默认为1 。。非必须设置;directory=/tmp ; 进程运行前,会前切换到这个目录默认不设置。。。非必须设置;umask=022 ; 进程掩码,默认none,非必须;priority=999 ; 子进程启动关闭优先级,优先级低的,最先启动,关闭的时候最后关闭默认值为999 。。非必须设置;autostart=true ; 如果是true的话,子进程将在supervisord启动后被自动启动默认就是true 。。非必须设置;autorestart=unexpected ; 这个是设置子进程挂掉后自动重启的情况,有三个选项,false,unexpected和true。如果为false的时候,无论什么情况下,都不会被重新启动,如果为unexpected,只有当进程的退出码不在下面的exitcodes里面定义的退出码的时候,才会被自动重启。当为true的时候,只要子进程挂掉,将会被无条件的重启;startsecs=1 ; 这个选项是子进程启动多少秒之后,此时状态如果是running,则我们认为启动成功了默认值为1 。。非必须设置;startretries=3 ; 当进程启动失败后,最大尝试启动的次数。。当超过3次后,supervisor将把此进程的状态置为FAIL默认值为3 。。非必须设置;exitcodes=0,2 ; 注意和上面的的autorestart=unexpected对应。。exitcodes里面的定义的退出码是expected的。;stopsignal=QUIT ; 进程停止信号,可以为TERM, HUP, INT, QUIT, KILL, USR1, or USR2等信号默认为TERM 。。当用设定的信号去干掉进程,退出码会被认为是expected非必须设置;stopwaitsecs=10 ; 这个是当我们向子进程发送stopsignal信号后,到系统返回信息给supervisord,所等待的最大时间。 超过这个时间,supervisord会向该子进程发送一个强制kill的信号。默认为10秒。。非必须设置;stopasgroup=false ; 这个东西主要用于,supervisord管理的子进程,这个子进程本身还有子进程。那么我们如果仅仅干掉supervisord的子进程的话,子进程的子进程有可能会变成孤儿进程。所以咱们可以设置可个选项,把整个该子进程的整个进程组都干掉。 设置为true的话,一般killasgroup也会被设置为true。需要注意的是,该选项发送的是stop信号默认为false。。非必须设置。。;killasgroup=false ; 这个和上面的stopasgroup类似,不过发送的是kill信号;user=chrism ; 如果supervisord是root启动,我们在这里设置这个非root用户,可以用来管理该program默认不设置。。。非必须设置项;redirect_stderr=true ; 如果为true,则stderr的日志会被写入stdout日志文件中默认为false,非必须设置;stdout_logfile=/a/path ; 子进程的stdout的日志路径,可以指定路径,AUTO,none等三个选项。设置为none的话,将没有日志产生。设置为AUTO的话,将随机找一个地方生成日志文件,而且当supervisord重新启动的时候,以前的日志文件会被清空。当 redirect_stderr=true的时候,sterr也会写进这个日志文件;stdout_logfile_maxbytes=1MB ; 日志文件最大大小,和[supervisord]中定义的一样。默认为50;stdout_logfile_backups=10 ; 和[supervisord]定义的一样。默认10;stdout_capture_maxbytes=1MB ; 这个东西是设定capture管道的大小,当值不为0的时候,子进程可以从stdout发送信息,而supervisor可以根据信息,发送相应的event。默认为0,为0的时候表达关闭管道。。。非必须项;stdout_events_enabled=false ; 当设置为ture的时候,当子进程由stdout向文件描述符中写日志的时候,将触发supervisord发送PROCESS_LOG_STDOUT类型的event默认为false。。。非必须设置;stderr_logfile=/a/path ; 这个东西是设置stderr写的日志路径,当redirect_stderr=true。这个就不用设置了,设置了也是白搭。因为它会被写入stdout_logfile的同一个文件中默认为AUTO,也就是随便找个地存,supervisord重启被清空。。非必须设置;stderr_logfile_maxbytes=1MB ; 这个出现好几次了,就不重复了;stderr_logfile_backups=10 ; 这个也是;stderr_capture_maxbytes=1MB ; 这个一样,和stdout_capture一样。 默认为0,关闭状态;stderr_events_enabled=false ; 这个也是一样,默认为false;environment=A="1",B="2" ; 这个是该子进程的环境变量,和别的子进程是不共享的;serverurl=AUTO ;; The below sample eventlistener section shows all possible; eventlistener subsection values, create one or more 'real'; eventlistener: sections to be able to handle event notifications; sent by supervisor.;[eventlistener:theeventlistenername] ;这个东西其实和program的地位是一样的,也是suopervisor启动的子进程,不过它干的活是订阅supervisord发送的event。他的名字就叫listener了。我们可以在listener里面做一系列处理,比如报警等等楼主这两天干的活,就是弄的这玩意;command=/bin/eventlistener ; 这个和上面的program一样,表示listener的可执行文件的路径;process_name=%(program_name)s ; 这个也一样,进程名,当下面的numprocs为多个的时候,才需要。否则默认就OK了;numprocs=1 ; 相同的listener启动的个数;events=EVENT ; event事件的类型,也就是说,只有写在这个地方的事件类型。才会被发送;buffer_size=10 ; 这个是event队列缓存大小,单位不太清楚,楼主猜测应该是个吧。当buffer超过10的时候,最旧的event将会被清除,并把新的event放进去。默认值为10。。非必须选项;directory=/tmp ; 进程执行前,会切换到这个目录下执行默认为不切换。。。非必须;umask=022 ; 淹没,默认为none,不说了;priority=-1 ; 启动优先级,默认-1,也不扯了;autostart=true ; 是否随supervisord启动一起启动,默认true;autorestart=unexpected ; 是否自动重启,和program一个样,分true,false,unexpected等,注意unexpected和exitcodes的关系;startsecs=1 ; 也是一样,进程启动后跑了几秒钟,才被认定为成功启动,默认1;startretries=3 ; 失败最大尝试次数,默认3;exitcodes=0,2 ; 期望或者说预料中的进程退出码,;stopsignal=QUIT ; 干掉进程的信号,默认为TERM,比如设置为QUIT,那么如果QUIT来干这个进程那么会被认为是正常维护,退出码也被认为是expected中的;stopwaitsecs=10 ; max num secs to wait b4 SIGKILL (default 10);stopasgroup=false ; send stop signal to the UNIX process group (default false);killasgroup=false ; SIGKILL the UNIX process group (def false);user=chrism ;设置普通用户,可以用来管理该listener进程。默认为空。。非必须设置;redirect_stderr=true ; 为true的话,stderr的log会并入stdout的log里面默认为false。。。非必须设置;stdout_logfile=/a/path ; 这个不说了,好几遍了;stdout_logfile_maxbytes=1MB ; 这个也是;stdout_logfile_backups=10 ; 这个也是;stdout_events_enabled=false ; 这个其实是错的,listener是不能发送event;stderr_logfile=/a/path ; 这个也是;stderr_logfile_maxbytes=1MB ; 这个也是;stderr_logfile_backups ; 这个不说了;stderr_events_enabled=false ; 这个也是错的,listener不能发送event;environment=A="1",B="2" ; 这个是该子进程的环境变量默认为空。。。非必须设置;serverurl=AUTO ; override serverurl computation (childutils); The below sample group section shows all possible group values,; create one or more 'real' group: sections to create "heterogeneous"; process groups.;[group:thegroupname] ;这个东西就是给programs分组,划分到组里面的program。我们就不用一个一个去操作了我们可以对组名进行统一的操作。 注意:program被划分到组里面之后,就相当于原来的配置从supervisor的配置文件里消失了。。。supervisor只会对组进行管理,而不再会对组里面的单个program进行管理了;programs=progname1,progname2 ; 组成员,用逗号分开这个是个必须的设置项;priority=999 ; 优先级,相对于组和组之间说的默认999。。非必须选项; The [include] section can just contain the "files" setting. This; setting can list multiple files (separated by whitespace or; newlines). It can also contain wildcards. The filenames are; interpreted as relative to this file. Included files *cannot*; include files themselves.;[include] ;这个东西挺有用的,当我们要管理的进程很多的时候,写在一个文件里面就有点大了。我们可以把配置信息写到多个文件中,然后include过来;files = relative/directory/*.ini
5.demo
python程序进程一般都用supervisor进行管理
分享一个线上曾经用过的supervisor监控python程序的配置
[program:xcspam]command=/usr/bin/python /app/web/xcspam/bin/main.py --port=93%(process_num)02dprocess_name=%(program_name)s_%(process_num)02dnumprocs=16numprocs_start=1directory=/app/web/xcspamuser=workautostart=trueautorestart=truestopsignal=QUITstdout_logfile=/data/log/xcspam/xcspam.logstderr_logfile=/data/log/xcspam/xcspam_error.logstdout_logfile_maxbytes=0stderr_logfile_maxbytes=0environment=PYTHONPATH=/app/web/xcspam, KEVIN_ENV=production[program:uwsgi]command=/usr/local/python3/bin/uwsgi /usr/local/nginx/conf/uwsgi.inidirectory=/data/www/APPServer/startsecs=0stopwaitsecs=0autostart=trueautorestart=true
重启supervisor服务
[root@localhost ~]# /etc/init.d/supervisord restartStopping supervisord: [ OK ]Starting supervisord: [ OK ]
查看supervisor管理的两个进程状态
[root@localhost ~]# supervisorctlmain RUNNING pid 16183, uptime 0:00:12uwsgi RUNNING pid 19043, uptime 0:00:13supervisor> statusmain RUNNING pid 16183, uptime 0:00:17uwsgi RUNNING pid 19043, uptime 0:00:18
查看管理的这两进程的运行情况
[root@localhost ~]# ps -ef|grep mainroot 16183 16181 0 21:38 ? 00:00:00 /usr/local/bin/mainroot 16207 15953 0 21:42 pts/0 00:00:00 grep main[root@localhost ~]# ps -ef|grep uwsgiroot 16595 16064 0 21:40 pts/0 00:00:00 grep --color=auto uwsgiroot 19043 17056 0 21:44 ? 00:00:04 /usr/local/python3/bin/uwsgi /usr/local/nginx/conf/uwsgi.ini
6.开启Supervisor Web 管理界面
在supervisord.conf配置中添加以下配置:
[inet_http_server]port=*:9000username=userpassword=123
7.错误收集
ps:supervisor 比较适合监控业务应用,且只能监控前台程序,如果你的程序是以daemon的方式启动,就不能使用supervisor监控了,那么执行:supervisor status 会提示:BACKOFF Exited too quickly (process log may have details)。
FATAL Exited too quickly (process log may have details)
出现这个问题原因:a、配置出错,查看错误日志;b.Supervisor 管理的进程不能设置为 daemon 模式如我们使用supervisor守护redis:如果 Redis 无法正常启动,可以查看一下 Redis 的配置,并将daemonize选项设置为 no。
参考
*Supervisor (进程管理利器) 使用说明 - 运维笔记
https://www.cnblogs.com/freely/p/10087950.html
Centos+Gunicorn+Nginx+Supervisor部署Flask – 简书
Flask Gunicorn Supervisor Nginx 项目部署小总结
【已解决】CentOS中用python2的pip去安装supervisor后找不到/etc/supervisor中的默认配置文件supervisord.conf

若有收获,就点个赞吧
0 人点赞
