需求
编码->归纳->度量 三阶段架构中,目前只有编码->度量两个模块,需要完成归纳层研发。
- 数据经过一个 Encoder 编码层来得到每一个样本的向量表示;
- 然后 第二层的归纳层再把样本表示归纳为类别表示;
- 第三层的度量,或者叫关系层, 就是在新来一个样本之后,通过计算新样本与每一个类别中心的距离来判断新的 样本属于哪个类别。
归纳层具体细节
类别标签可能存在错误的情况,导致问句匹配错误。为提升算法的鲁棒性和对错误标签的容忍度,我们采用改进的Learning vector Quantization (LVQ) 监督聚类算法,目标是学得一组原型向量(聚类簇),从而将问句特征编码归纳为多个类别表示。
LVQ是由数据驱动的,数据搜索距离它最近的两个神经元,对于同类神经元采取拉拢,异类神经元采取排斥,这样相对于只拉拢不排斥能加快算法收敛的速度,最终得到数据的分布模式,开头提到,如果我得到已知标签的数据,我要求输入模式,我直接求均值就可以,用LVQ或者SOM的好处就是对于离群点并不敏感,少数的离群点并不影响最终结果,因为他们对最终的神经元分布影响很小。https://blog.csdn.net/jiabiao1602/article/details/43791897
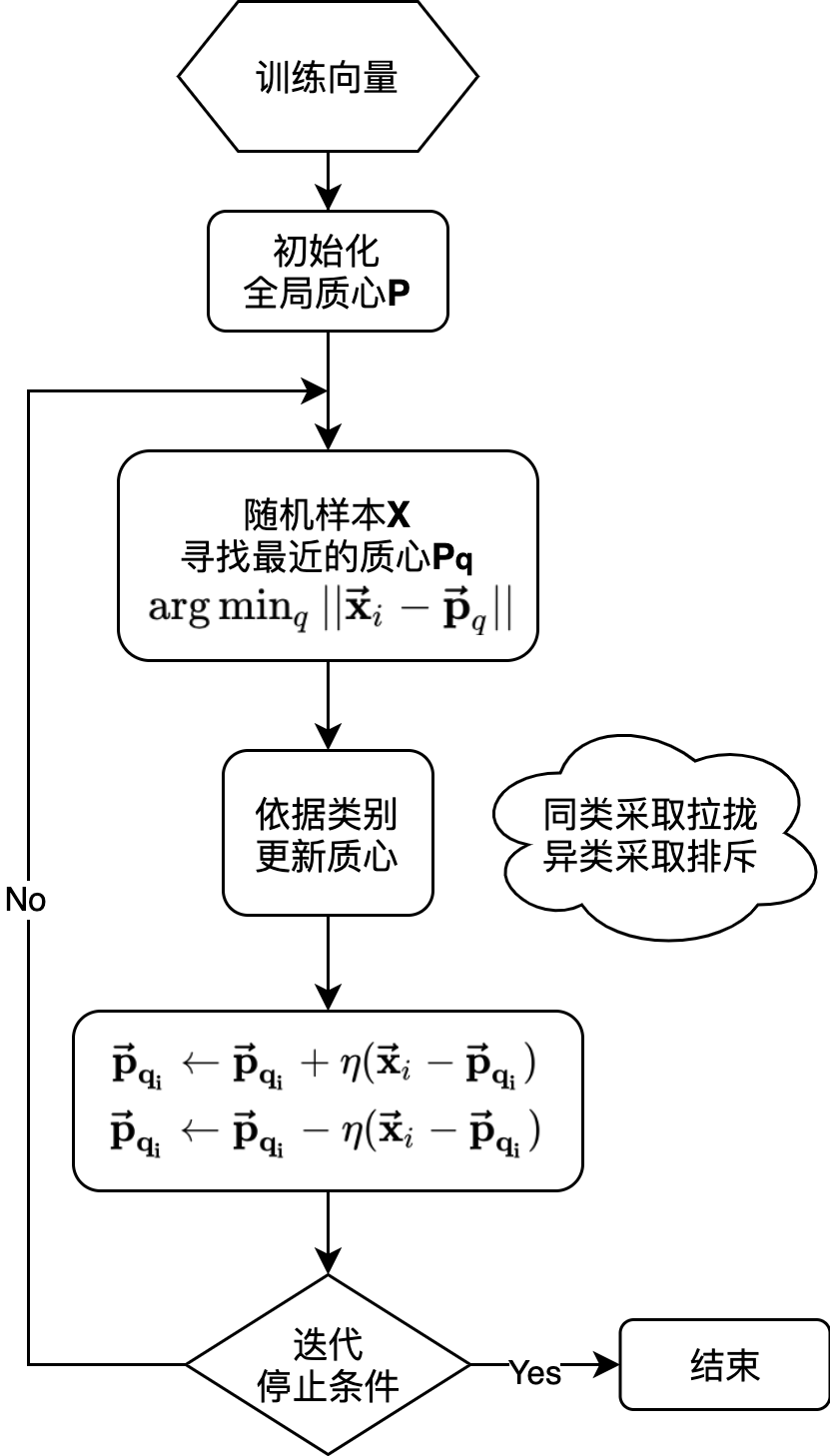
LVQ算法训练流程:①对原型向量进行随机初始化;②计算原型向量与问句特征向量之间的欧氏距离,寻找最近的获胜者;③采取同类神经元拉拢、异类神经元排斥的策略,对原型向量进行迭代优化,直到算法收敛;如下图所示: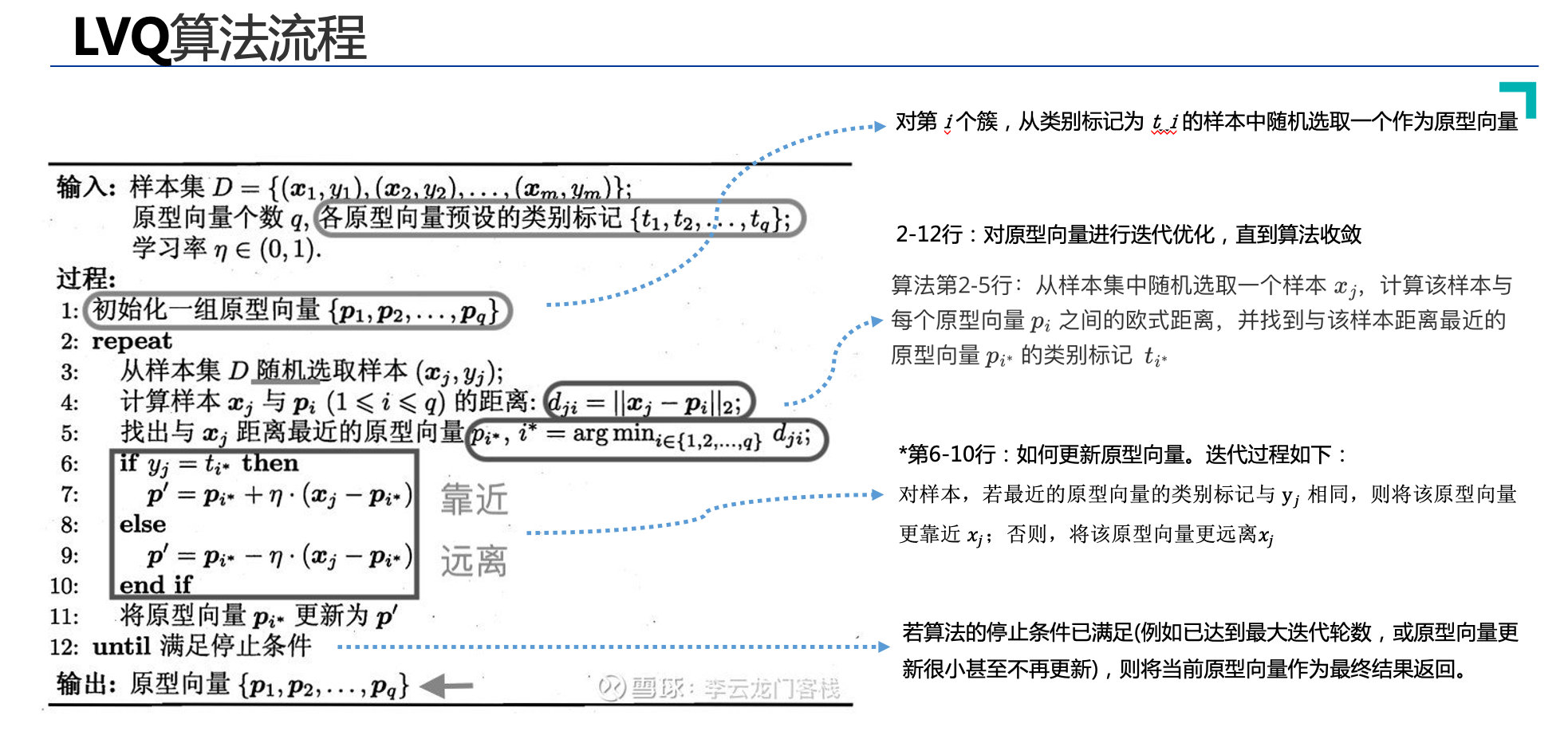
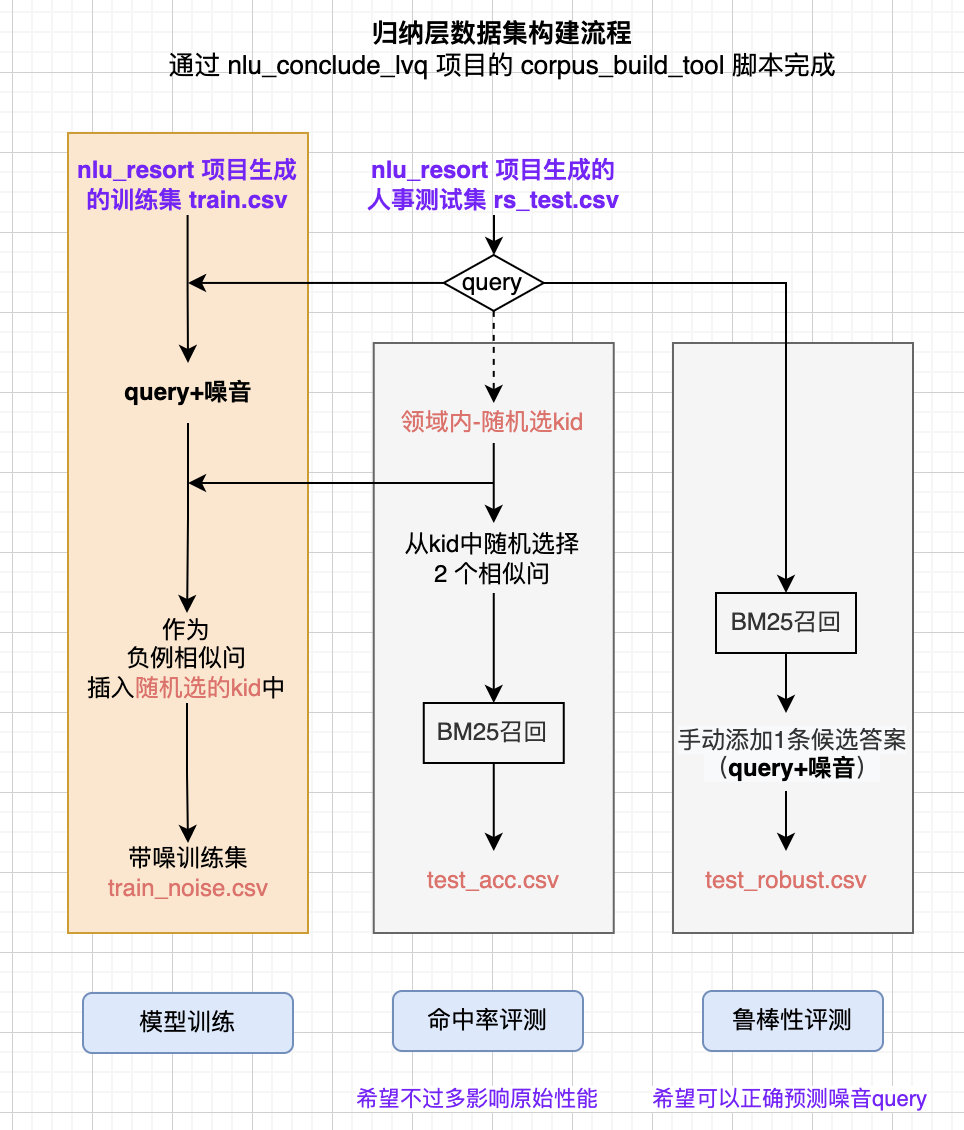
数据集构造
1、train_noise.csv
利用nlu-resort项目生成训练集 train.csv,将测试集样本(添加噪音)作为负例相似问随机加入一个 kid 中,组成带噪训练集 train_noise.csv
2、test_acc & test_robust
利用 nlu-resort项目已生成的测试集 test_xxx.csv,通过本地nlu-conclude-lvq项目的 corpus_build_tool.py 来生成 train_noise.csv、test_acc.csv、test_robust.csv.
- 准确性测试集 test_acc.csv:随机选的 kid 下选择 2 个相似问,通过 BM25 召回 recall_id.
- 鲁棒性测试集 test_robust.csv:针对测试集中的样本query,直接 BM25 召回 recall_id.
评测标准
- 准确性测试:和不加归纳层比较,NLU评测集效果无明显下降;
- 鲁棒性测试:①能够不被训练集中的噪音数据影响;②训练样本和预测样本分布不同下,依然可以给出较好的预测结果
实验结果
尝试聚类算法LVQ算法及其变体LVQ2、LVQ3,在 sklearn 数据集上的可视化实验结果如下: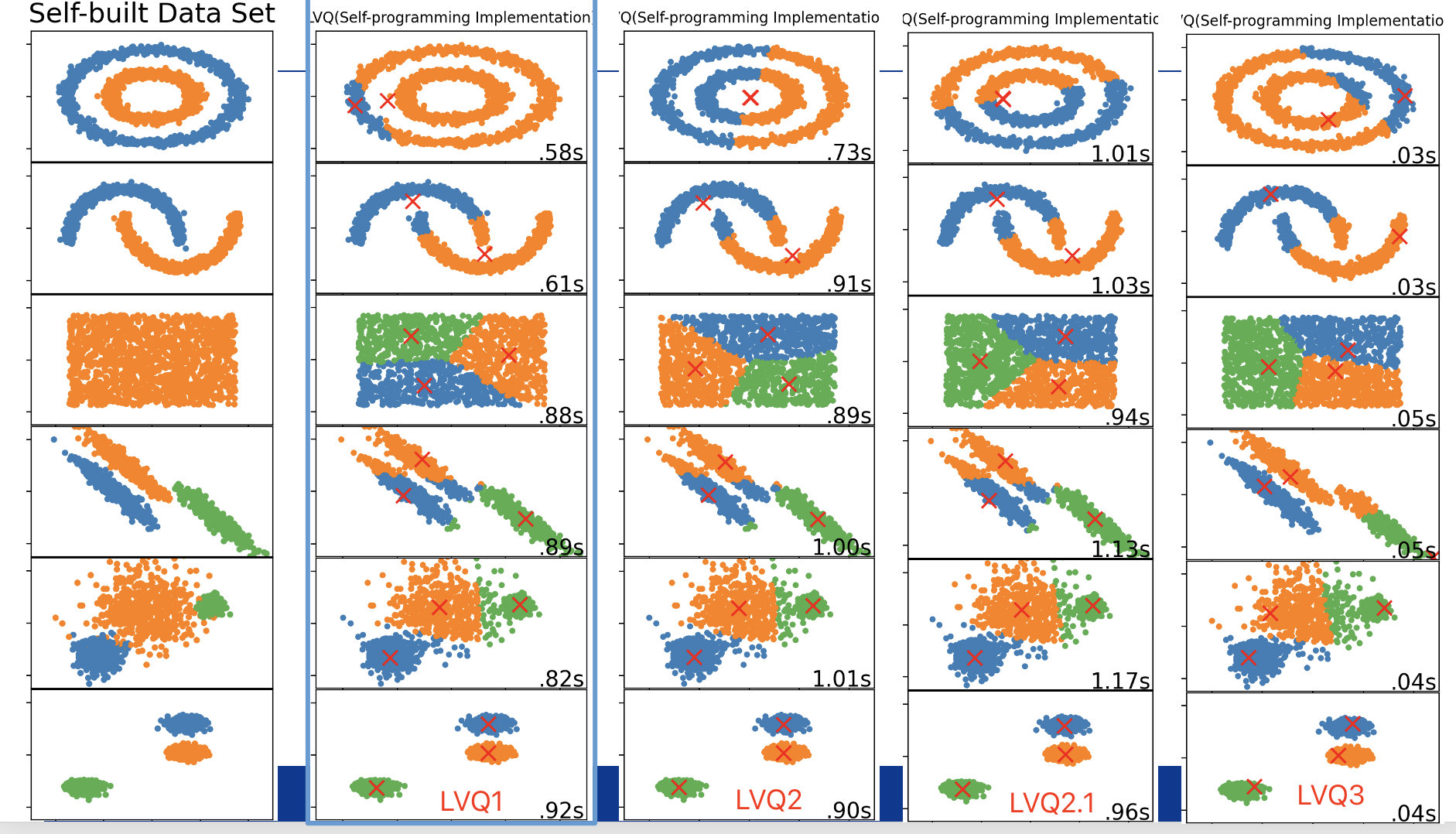
尝试聚类算法LVQ算法及其变体LVQ2、LVQ3,在 test_acc 和 test_robust 评测集的实验结果如下: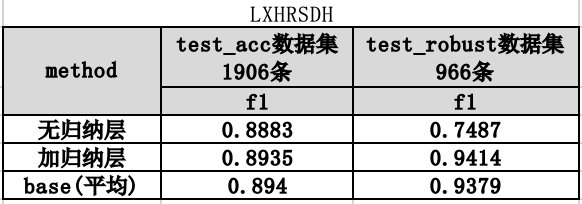
实验比较了无归纳层、有归纳层以及平均的方式下,评估模型的性能。分析如下:在保证准确率不下降的同时,鲁棒性得到较大提升,且归纳层更胜一筹。工程化
1、定时拉取最新的回流数据用于训练;2、调用embedding接口向量化数据;3、生成原型向量,并更新ES Index(intent字段以特殊符号插入)
注意:归纳层这块由之前的定时训练任务,改为提供一个训练api,交给文杰合并到NLU中统一分配和训练下一步规划
- 参考达摩院在DataFunTalk 上分享的 Induction Network (EMNLP2019),通过神经网络来显式建模类表示,引入胶囊思想和动态路由算法来构建归纳能力;
- 步骤:先初始化参数,通过初始化的参数来计算得到一个初步的类别向量;再通 过计算当前类别向量与样本向量的距离来更新整个参数;根据更新之后的参数可 以重新计算得到新的类别向量;如此迭代即可得到最终的比较合理的类别向量。
新归纳层
新归纳层主要参考阿里达摩院在EMNLP2019发表的 Induction Network,主要是用来做few-shot对话场景中的意图识别。目前的新归纳层主要由三个模块组成:编码器模块,归纳模块和关系模块。
- 编码器模块采用已训好的 NLU 模型;
- 归纳模块引入胶囊网络Capusule Network的动态路由算法来构建归纳能力,通过神经网络来显式建模类表示,从而将每一个类别中的样本表征转化凝练成为类表示;
- 关系模块采用 cosine相似度 / 神经张量网络NTN 计算query 和类表示的相关性;
模型输入:
- shape=(1, 训练集样本数, 768) 的张量数据
- 需要在模型实现中划分数据集为 suport set 和 query set 两部分;
- suport set 用于训练模型;
- query set 用作验证集评估模型;
核心是归纳模块:
- 将样本表征进行一次transformation,共享矩阵乘法;
- 对转化之后的样本表征进行加权求和,得到初始的类别表征 c;
- 将类别表征进行 squash 函数激活;
- 对零初始化的耦合系数 b 进行更新;
- 迭代更新。最后输出归纳模块中的 class_vector c,即类表示。

关系模块:
- 神经张量网络NTN计算关系得分存在如下问题:参数量过大,收敛速度很慢。可以将 NTN 关系建模改为计算余弦相似度降低复杂度。
损失函数选择:
- MSE 均方误差
目前问题:
- 归纳网络 OOM,主要是跟 capsule 网络的参数量、输入训练样本张量过大、以及 epoch 有关。NTN 网络 or 余弦相似度层影响不大….
- 打算尝试的解决方案:① shape=(1, 训练集样本数, 768) 的张量输入,改为输入一个一个 batch,即 shape=(batch, 768)
- 保存下每次实验的 badcase

若有收获,就点个赞吧
0 人点赞
