layout: post
title: 度量学习之采样策略
subtitle: 度量学习之采样策略
date: 2021-12-12
author: NSX
header-img: img/post-bg-ios9-web.jpg
catalog: true
tags:
- 度量学习
- 采样策略
在metric learning中(尤其是pairwise inputs),采样方法也同样重要。甚至在Sampling Matters in Deep Embedding Learning中,作者指出在metric learning中,采样方法比损失函数具有同等或更重要的作用。
为什么要采样
以triplet loss为例,它的输入为(anchor,positive,negative)。如果有一个人脸训练集,共m个人(m=10000),每个人的人脸图片有n张(n=100),那么所有可能的triplet pair为  个(假设anchor固定,positive有99个选择,negative有9999个选择)。如果这些pair全参与训练,则复杂度为O(mn^2),显然是不可行的。考虑classification loss,如果每一张人脸图片都参与训练,那么共有
个(假设anchor固定,positive有99个选择,negative有9999个选择)。如果这些pair全参与训练,则复杂度为O(mn^2),显然是不可行的。考虑classification loss,如果每一张人脸图片都参与训练,那么共有  张训练图片,此时复杂度是O(mn);如果以人为单位,每个epoch随机从100张里面抽一张人脸作为这个人的训练图片,那么每个epoch的训练集为10000张,此时复杂度为O(m)。因此需要找一种对标classification loss的方法,当遍历所有图片(以图片为单位)时,为每个图片找到合适的triplet pair,此时复杂度为O(mn);当以人为单位时,为每个人找到合适的triplet pair,此时复杂度为O(m)。为了叙述清晰,统一以后一种作为目标。
张训练图片,此时复杂度是O(mn);如果以人为单位,每个epoch随机从100张里面抽一张人脸作为这个人的训练图片,那么每个epoch的训练集为10000张,此时复杂度为O(m)。因此需要找一种对标classification loss的方法,当遍历所有图片(以图片为单位)时,为每个图片找到合适的triplet pair,此时复杂度为O(mn);当以人为单位时,为每个人找到合适的triplet pair,此时复杂度为O(m)。为了叙述清晰,统一以后一种作为目标。
为了完成上面说的目标,我们需要进行采样,包括:
- 随机采样
- hard/semi-hard 采样
- distance weighted采样
1.随机采样
对于某一个人,先随机选一张这个人的人脸图片作为anchor,再在这个人的其它99张人脸图片里面随机选一张图片作为positive,再随机选一张其他人的人脸图片作为negative。目标达到了吗?达到了。还有其它问题吗?有,margin。
写到这里就得回顾一下metric learning中的loss function了。metric learning的所有损失函数都有一个包含margin的max函数,用来达到类内相近,类间分离的目标。这个max函数有个特性,就是如果已经满足了公式,那么它是不参与梯度回传的。例如triplet loss:

当d(a,n)小于d(a, p)+margin时,左边这一项是正数,模型通过反向传播使d(a,p)和d(a,n)分别往更小/更大的方向梯度下降;但当d(a,n)大于d(a, p)+margin时,是公式右边的0起作用,左边这一项不再参与梯度回传,对模型训练没有帮助。然而,它们依然参与计算,使计算时间增加,影响模型的收敛速度。而且越到训练后期,模型越来越好,这种无用的pair越多。因此,需要合适的采样方法选择适当的pair,至少保证它们对训练是有帮助的。
2.hard/semi-hard 采样
根据直觉,既然满足了公式的pair无贡献,那么我们找到不满足公式的pair,用它们训练不就可以了吗?可以,又有两个新的问题来了:(1)怎么找到这些合适的pair?如果所有pair都计算,复杂度又变高了。(2)找到合适的pair之后,从这些pair里怎么进一步挑选?
问题一,FaceNet 中提出了两种方法:第一种是离线计算,每隔n个epoch用当前最优模型计算;第二种是在线计算,在每个batch里面计算。如今的负采样方法基本都是选择第二种在线计算的方式。那又有问题了,如果一个batch里面都没有合适的怎么办?那只能调大batchsize了。可能一些论文就是靠调大batchsize才得到提升的,只是他们没明说:)
问题二,就是各个采样方法进一步研究的问题了。一种直觉上容易想到的方法是选择所有pair里最难的pair(即d(a,n)-d(a,p)最小),这种方式就叫做hard sampling。然而,FaceNet 指出:在实验中,选择最困难的负样本可能会导致训练初期收敛到不好的局部最小值,而且会导致模型崩溃。为了减轻这种情况,作者提出了semi-hard sampling方法,即保证d(a,p)<d(a,n),意思是我们要选择困难的负样本,但这些负样本不要太困难,即负样本和anchor不能比正样本和anchor更相似。
hard/semi-hard 采样的问题
hard/semi-hard采样算是比较符合直觉的采样方法了。但实际使用时,作者们发现了一个问题:“ FaceNet报告了一个一致的发现:损失的减少在某个点后急剧减慢,他们的最终系统花了80天的时间进行训练。”这是为什么呢?Sampling Matters 给出了解释。
进一步介绍之前,需要有一个先验知识:对于n>=128的n维向量,在normalize后被约束到一个n-1维的球体上。如果点在球体上分布均匀,则两个点之间距离的分布属于以下公式:

证明:The Sphere Game in n Dimensions 。在高维空间,q(d)符合 的正态分布。换句话说,如果样本分散均匀,随机采样时采样到
的正态分布。换句话说,如果样本分散均匀,随机采样时采样到  附近的概率很大。如果margin小于
附近的概率很大。如果margin小于  ,这个采样就没有帮助了。对于学习到的embeddings,分布类似:
,这个采样就没有帮助了。对于学习到的embeddings,分布类似:
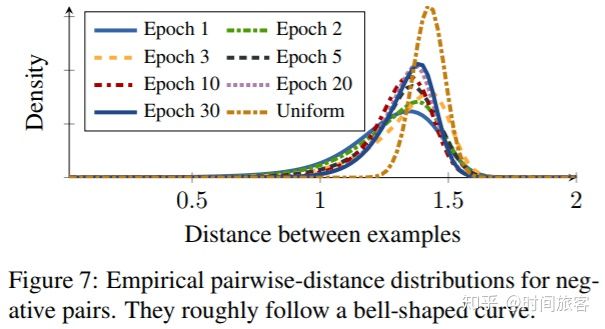
选择hard negative samples导致另一个问题。负例的梯度为:

当d很小时,如果embedding有noise,则梯度的方向为:
 ,
,
梯度的方向就会被改变。
3.distance weighted采样
根据以上分析,随机采样时总会采样到  附近的值,hard采样又会被噪声影响。那么有没有一种方法使所有区间的概率相同呢?方法很简单,乘一个概率的倒数:
附近的值,hard采样又会被噪声影响。那么有没有一种方法使所有区间的概率相同呢?方法很简单,乘一个概率的倒数:

其中  是为了避免噪声样本加入的cutoff。
是为了避免噪声样本加入的cutoff。
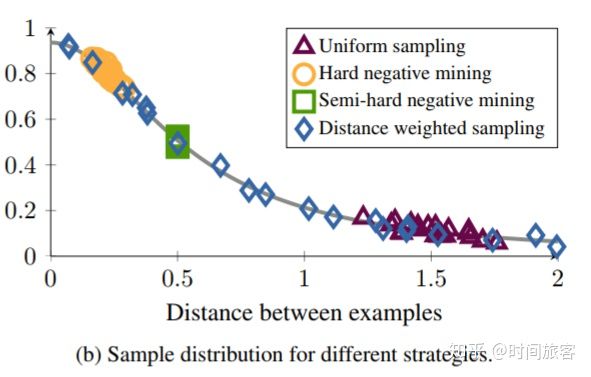
上图比较了几个采样方法的样本分布,hard sampling总是在高方差区域采样,被噪声影响。随机采样的样本都在1.4附近。semi-hard采样找到了一个狭窄的范围,尽管一开始它可能会很快收敛,但是在某些时候,该频段内没有任何实例,网络将停止更新。distance weighted采样方法对所有分布提供了相同的可能,使得训练中总能提供有用的样本。
采样的实现方法
刚才我们叙述的过程中,都是以“人”为单位,为每个人找到一个合适的triplet pair。以pytorch为例,具体的实现方式是先对每一个人采样一个(anchor,positive,negative)pair,再把它们送到batch中。如果每个batch里的人数为k,则每个batch里有k个pair。把这种实现方式推到以图片为单位的情况,则对每张图片采样一个pair,再把它们送入batch中。例如batch中有2个人,每个人有3张图片。则采样到的pair为:(a1,ax,by);(a2,ax,by);(a3,ax,by);(b1,bx,ay);(b2,bx,ay);(b3,bx,ay),其中x,y根据采样方法可能是1-3中的任意一个(positive与anchor不同)。
这种实现方法有两个问题
- 一是计算重复,例如a1作为anchor计算了一次,也可能作为a2的positive又计算了一次,又可能作为b1的negative再计算了一次。
- 二是pair少,最开始的时候提到过接受不了
 的复杂度,是因为m和n都很大。但当调整batchsize使m和n到合适的大小k和q时,我们在batch内已经可以接受
的复杂度,是因为m和n都很大。但当调整batchsize使m和n到合适的大小k和q时,我们在batch内已经可以接受 的复杂度了,这时我们就希望batch内能有更多的pair,使模型收敛更快。
的复杂度了,这时我们就希望batch内能有更多的pair,使模型收敛更快。
以上两个问题可以用同一种方法解决,思路来自Lifted Structured Loss:即先组好batch(设置好每个batch里的人数和人脸图片个数),计算好每张图片的向量,再找到batch内所有满足margin条件的pair,并在此基础上进行采样(semihard、distanceweighted等)。这种方法现在已经是成为一种通用做法了。找到batch内所有满足margin条件的pair之后,如果使用semihard采样,则剔除掉所有hard的样本;或者可以把条件设置得更严格一些,例如设置一个epsilon,只选择比最难正例-epsilon大的负例,以及比最难负例+epsilon小的正例(来自Multi-Similarity Loss)。
参考
Implementing Triplet Loss Function in Tensorflow 2.0
Triplet Loss and Online Triplet Mining in TensorFlow
triplet loss稳定在margin附近?—hardTri & l2_normalize

若有收获,就点个赞吧
0 人点赞
