语义搜索是一种信息检索系统,其重点是句子的含义,而不是常规的关键字匹配。基于关键词的搜索引擎通常会遇到以下问题:
- 复杂查询或具有双重含义的单词。
- 长查询,如论文摘要或博客中的一段。
- 不熟悉某个领域术语的用户或想要进行探索性搜索的用户。
基于向量(也称为语义)的搜索引擎通过使用最先进的语言模型找到文本查询的数字表示,在高维向量空间中对它们进行索引,并度量查询向量与索引文档的相似程度,从而解决了这些缺陷。
在本文中,我将讨论如何使用SOTA句子嵌入(句子转换器)和FAISS来实现最小语义搜索引擎,实现从海量文章中求topk相似文章。
经典的语义检索方法简述
向量相似度检索,即根据一个向量Q从海量的向量库中寻找TopK个与Q最相似或者距离最近的向量,其在工业中有着广泛的应用场景,比如图像检索、文本语义检索以及推荐系统中基于User与Item的Embedding向量召回等。在生产环境中,被查找的向量库往往是海量,甚至超过了内存的限制,而且面临着高并发与低延迟的需求。当前涌现出了一系列高质量的向量化工具。
1、Gensim
Gensim是 Radim Řehůřek开源的一个主题建模、文本向量化计算工具库,用于从原始的非结构化的文本中,无监督地学习到文本隐层的主题向量表达,支持包括TF-IDF,LSA,LDA,和word2vec在内的多种主题模型算法,提供了针对向量的多种操作,如相似度计算,信息检索等一些常用任务的API接口,如找到与一个词相似度最高的词语集合,比较两个词语之间的相似度值。
地址:https://radimrehurek.com/gensim/
Gensim的提供了wordvec模块提供了cbow和skipgram两种词向量训练接口,用户可以通过训练自有语料来得到特定的向量文件。因此,我们一方面可以直接使用该向量文件实现检索操作,也可以预先将预先得到的embedding【如DeepWalk、Node2vec得到的向量,根据TFIDF得到的文本向量,从其他开源渠道下载得到的向量等】按照gensim所规定的格式【一般是文件首行为词表大小、空格、向量维度,第二行至最后一行为每个词、空格、以空格连接的各维度向量】,调用该工具完成加载和使用,实验表明,gensim加载模型耗时很长,会将所有的词向量加载进入内存,占用内存很大,most_similar函数耗时较长。
2、Annoy
Annoy是Spotify开源的一个用于近似最近邻查询的C++/Python工具,在 Spotify 使用它进行音乐推荐。Annoy对内存使用进行了优化,索引可以在硬盘保存或者加载,提供欧式距离,曼哈顿距离,余弦距离,汉明距离,內积距离等距离的度量方法,可以使用 Annoy 对 word2vec 等向量建立索引。不过,Annoy仅支持树结构的索引类型,且不支持批量插入和查询,仅支持一种索引类型,单步查询速度快,另外,annoy中向量的item-id只接受非负数,如果自己的数据不符合要求需要自己维护一份映射。
地址:https://github.com/spotify/annoy
3、FAISS
Faiss是Facebook AI团队开源的针对聚类和相似性搜索的开源库,为稠密向量提供高效相似度搜索服务,支持十亿级别向量的搜索,是目前最为成熟的近似近邻搜索库之一。支持多种索引方式(详细介绍可参考Faiss Indexes)以及CPU和GPU计算,Faiss 支持多种向量检索方式,包括内积、欧氏距离等,同时支持精确检索与模糊搜索,并使用 GPU 来获得更高的内存带宽和计算吞吐量。不过,Faiss本身只是一个能够单机运行的支持各种向量检索模型的机器学习算法基础库,不支持分布式实时索引和检索,同时也不支持标量字段的存储和索引等功能。
地址:https://github.com/facebookresearch/faiss
4、SPTAG
SPTAG(空间分区树和图)是微软开源的BING搜索算法库,作为一种分布式近似最近邻域搜索(ANN)库,可用于大规模矢量搜索场景提供高质量矢量的索引构建,搜索和分布式在线服务。SPTAG内置L2 距离或余弦距离来计算向量之间的相似度,并提供KD-Tree 和相对邻域图(SPTAG-KDT)、以及平衡 k-means 树和相对邻域图(SPTAG-BKT)两种搜索算法。前者在指数构建成本方面能够有效降低成本,后者则在非常高维数据中保持较高的搜索精度。
地址:https://github.com/microsoft/SPTAG
5、Vearch
Vearch 是由京东开源的一个分布式向量搜索系统,考虑到开发及可扩展性,vearch 中的 Master,Router 和 PS 均采用 GO 语言编写。出于性能考虑,核心的存储检索引擎 gamma 基于 faiss 采用 c++ 语言实现, 提供了快速的向量检索功能,以及类似 Elasticsearch 的 Restful API 可以方便地对数据及表结构进行管理查询等工作。
此外,为满足实际业务场景需要,Vearch 还提供了算法插件服务模块,通过选择默认的 VGG,Resnet 或自定义算法模型等,能够提供端到端的图像检索,视频流智能监控等业务应用场景的实现。
地址:https://github.com/vearch/vearch
6、Milvus
Milvus 是一款国产开源的、针对海量特征向量的相似性搜索引擎。Milvus能够很好地应对海量向量数据,它集成了目前在向量相似性计算领域的几个开源库,并针对性做了定制,支持结构化查询、多模查询等业界比较急需的功能,并支持cpu、gpu、arm等多种类型的处理器,能够PC(16GB内存)上实现 1 亿级向量(数据来自SIFT1billion)的搜索。
在实际实验中发现,与FAISS相比,Milvus多平台通用,mac,windows和linux都是支持的,可以通过docker部署,在平台通用性上好了不少,并且支持Java,c,c++和python等多种编程语言。值得注意的是,Milvus 专门开通了训练营们,对了解向量数据库的操作及各种应用场景做了索引,例如如何进行 Milvus 性能测评,搭建智能问答机器人、推荐系统、以图搜图系统、分子式检索系统。
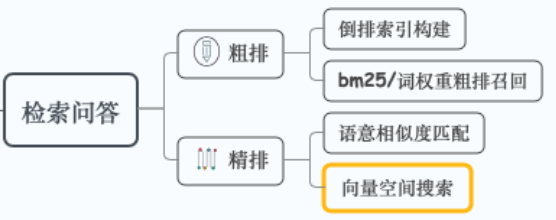
FAQ检索方法
1、关键字检索(倒排索引)
传统召回模块基于关键字检索
- 计算关键字在问题集中的 TF-IDF 以及BM25 得分,并建立倒排索引表
- 第三方库 ElasticSearch,Lucene,Whoosh
以Elasticsearch为例。Elasticsearch使用标记器将文档分割成标记(即有意义的文本单位),这些标记映射到数字序列,并用于构建反向索引。
- 反向索引: 与检查每个文档是否包含查询词不同,反向索引使我们能够查找一个词并检索包含该词的所有文档列表。
- 同时,Elasticsearch用一个高维加权向量表示每个索引文档,其中每个不同的索引项是一个维度,它们的值(或权重)是用TF-IDF计算的。
- 在搜索过程中,使用相同的TF-IDF管道将查询转换为向量,文档d对查询q的VSM得分为加权查询向量V(q)和V(d)的余弦相似度。
2、向量检索(语义召回)
随着语义表示模型的增强、预训练模型的发展,基于 BERT 向量的语义检索得到广泛应用
- 对候选问题集合进行向量编码,得到 corpus 向量矩阵
- 当用户输入 query 时,同样进行编码得到 query 向量表示
- 然后进行语义检索(矩阵操作,KNN,FAISS)
针对小规模 FAQ 问题集直接计算 query 和 corpus 向量矩阵的余弦相似度,从而获得 topk 候选问题
句向量获取解决方案
| Python Lib | Framework | Desc | Example |
|---|---|---|---|
| bert-as-serivce | TensorFlow | 高并发服务调用,支持 fine-tune,较难拓展其他模型 | getting-started |
| Sentence-Transformers | PyTorch | 接口简单易用,支持各种模型调用,支持 fine-turn(单GPU) | using-Sentence-Transformers-model using-Transformers-model |
| 🤗 Transformers | PyTorch | 自定义程度高,支持各种模型调用,支持 fine-turn(多GPU) | sentence-embeddings-with-Transformers |
SBERT +Faiss 语义搜索引擎
使用 Sentence transformers 对用户 query 进行向量表示,借助 Faiss 对问题集做相似性召回和打分,最后对 topk 结果进行精排序。
详细步骤(附代码)
Faiss 总体使用过程可以分为三步:
- 构建训练数据(以矩阵形式表达)
- 挑选合适的 Index (Faiss 的核心部件),将训练数据 add 进 Index 中。
- Search,也就是搜索,得到最后结果
1.加载SBERT进行矢量化
首先,让我们安装和加载所需的库
!pip install faiss-cpu!pip install -U sentence-transformersimport numpy as npimport torchimport osimport pandas as pdimport faissimport timefrom sentence_transformers import SentenceTransformer
然后,加载数据集
我使用了来自Kaggle的数据集,其中包含十七年来发布的新闻头条。
data = ['This framework generates embeddings for each input sentence','Sentences are passed as a list of string.','The quick brown fox jumps over the lazy dog.']
加载预训练的模型并执行推理
model = SentenceTransformer('distilbert-base-nli-mean-tokens')encoded_data = model.encode(data, show_progress_bar=True)
2.Faiss索引数据集
通过参考指南,我们可以根据用例选择不同的索引选项。
让我们定义索引并向其中添加数据
index = faiss.IndexIDMap(faiss.IndexFlatIP(768))index.add_with_ids(encoded_data, np.array(range(0, len(data))))d, nlist = 768, 1000 # 聚类中心的个数# # 精确的内积搜索,对归一化向量计算余弦相似度(不太准?)# faiss.normalize_L2(encoded_data) # 归一化# index = faiss.IndexFlatIP(d) # 内积建立索引# index.add(encoded_data) # 添加矩阵# # 精确的L2距离搜索# index = faiss.IndexFlatL2(d)# print(index.is_trained)# index.add(encoded_data)# print(index.ntotal) # 查看建立索引的向量数目# """# 倒排文件检索# 为了加速查询,可以把数据集切分成多个,采用基于Multi-probing(best-bin KD树变体)的分块方法。# 这便是IndexIVFFlat,它需要另一个索引来记录倒排列表。# """# quantizer = faiss.IndexFlatIP(d) # 建立一个量化器# index = faiss.IndexIVFFlat(quantizer, d, nlist, faiss.METRIC_INNER_PRODUCT)# index.train(encoded_data)# index.add(encoded_data)# print(index.ntotal)
序列化索引
faiss.write_index(index, 'abc_news')
然后可以将序列化的索引导出,迁移至托管搜索引擎的任何计算机中!
反序列化索引
index = faiss.read_index('abc_news')
3.执行语义相似度搜索
首先让我们构建一个包装函数进行搜索
def search(query):t=time.time()query_vector = model.encode([query])k = 5top_k = index.search(query_vector, k)print('totaltime: {}'.format(time.time()-t))return [data[_id] for _id in top_k[1].tolist()[0]]
执行搜索
query=str(input())results=search(query)print('results :')for result in results:print('\t',result)
4.索引更新
每隔2分钟创建一个更新索引的task,要求更新所有handler对应的索引,worker接收到task之后从生产数据库上下载对应的主问题,下载对应的向量文件,加载向量构建索引,然后将索引序列化到文件,Faiss server提供gRPC接口来接收celery的通知(调用),接到通知后直接加载索引文件更新索引。
最后的想法
很多场景下,基于关键字的倒排索引召回结果已经足够,可以考虑综合基于关键字和基于向量的召回方法,参考知乎语义检索系统 Beyond Lexical: A Semantic Retrieval Framework for Textual SearchEngine
参考文献
[1] Nils Reimers和Iryna Gurevych。“使用知识提炼使多语言的单语言句子嵌入成为多语言。” arXiv(2020):2004.09813。
[2] Johnson,Jeff和Douze,Matthijs和J {‘e} gou,Herv {‘e} 。“使用GPU进行十亿规模的相似性搜索” arXiv预印本arXiv:1702.08734 。

若有收获,就点个赞吧
0 人点赞
