词向量是什么
自然语言理解的问题要转化为机器学习的问题,第一步肯定是要找一种方法把这些符号数学化。
NLP 中最直观,也是到目前为止最常用的词表示方法是 One-hot Representation,采用稀疏方式存储,给每个词分配一个数字 ID。但 One-hot 表示存在“词汇鸿沟”现象:任意两个词之间都是孤立的。光从这两个向量中看不出两个词是否有关系,哪怕是话筒和麦克这样的同义词也不能幸免于难。
目前 NLP 常用的是 Distributed Representation,一种低维实数向量表示词。这种向量一般长成这个样子:[0.792, −0.177, −0.107, 0.109, −0.542, …]。Distributed representation 最大的贡献是可以通过欧氏距离/余弦距离来衡量词之间的相似程度。
词向量的训练
要介绍词向量是怎么训练得到的,就不得不提到语言模型。到目前为止我了解到的所有训练方法都是在训练语言模型的同时,顺便得到词向量的。从大量未标注的普通文本数据中,通过词频统计、词的共现、词的搭配之类的信息,无监督地学习出词向量(语言模型本来就是基于这个想法而来的)
词向量的训练最经典的有 3 个工作,C&W 2008、M&H 2008、Mikolov 2010。当然在说这些工作之前,不得不介绍一下语言模型。
语言模型是什么
在统计自然语言处理中,语言模型(language model) 指的是计算一个句子的概率模型,即计算一个单词序列的概率。用简单的短语概括就是在一个词序列中,预测下一个词的能力。
 |
 |
|---|---|
要计算出一个句子的概率,只要去估计出概率 ![2022-02-16-[ML]-重温Word2Vec及2种优化策略 - 图3](/uploads/projects/ningshixian@pz10h0/cd9ebddfc2f2efea6a8d2c47071c79e8.svg) 就可以了。具体原理就是利用概率统计里面的极大似然估计MLE方法,通过对大量样本进行统计,使用频率去逼近这个概率。其中
就可以了。具体原理就是利用概率统计里面的极大似然估计MLE方法,通过对大量样本进行统计,使用频率去逼近这个概率。其中![2022-02-16-[ML]-重温Word2Vec及2种优化策略 - 图4](/uploads/projects/ningshixian@pz10h0/ee24170bb80a16d6f1535b4c0436a62d.svg) 为统计的词频。
为统计的词频。
语言模型的历史
马尔可夫与语言模型
人类历史上第一个对语言模型进行研究的是马尔可夫(Andrey Markov),虽然当初并没有“语言模型”这个术语。
假设 ![2022-02-16-[ML]-重温Word2Vec及2种优化策略 - 图5](/uploads/projects/ningshixian@pz10h0/1eb6ac1d90de4178f3efe10c44b4a905.svg) 是单词的序列,则其概率可以通过概率公式计算得到:
是单词的序列,则其概率可以通过概率公式计算得到:![2022-02-16-[ML]-重温Word2Vec及2种优化策略 - 图6](/uploads/projects/ningshixian@pz10h0/3273d722b90e9009023f1f5743188dbb.svg)
直接计算上式计算量太大,所以 N-gram 模型引入马尔科夫假设,即当前词出现的概率只与其前 n-1 个词有关:
%3D%5Cprod%7Bi%3D1%7D%5Enp(w_i%7Cw%7Bi-n%2B1%7D%2Cw%7Bi-n%2B2%7D%2C…%2Cw%7Bi-1%7D)#card=math&code=p%28w1%2Cw2%2C…%2Cwn%29%3D%5Cprod%7Bi%3D1%7D%5Enp%28wi%7Cw%7Bi-n%2B1%7D%2Cw%7Bi-n%2B2%7D%2C…%2Cw%7Bi-1%7D%29&id=wxFps)
当语料足够大时![2022-02-16-[ML]-重温Word2Vec及2种优化策略 - 图8](/uploads/projects/ningshixian@pz10h0/13e1fd3f717f40d56224423c34cd2913.svg)
真正常用的 N-gram 的 n 不会超过 3,一般为 n=2。马尔可夫于1906年提出了马尔可夫链。他开始考虑的模型非常简单,只有两个状态,状态之间有转移概率。马尔可夫证明了如果依照转移概率在两个状态之间跳转,访问两个状态的频率就会收敛到期待值,这就是马尔可夫链的遍历性定理。
香农与语言模型
1948年,香农(Claude Shannon)发表了奠基性论文《通信的数学理论》,开创了信息论领域。在论文中,香农提出了熵的概念,研究了n元模型的性质。
假设语言(单词序列)是由一个随机过程产生的数据,n元模型的熵的定义为:![2022-02-16-[ML]-重温Word2Vec及2种优化策略 - 图9](/uploads/projects/ningshixian@pz10h0/02fe655dbd60a85cf639e16b70fa4463.webp)
这里p表示生成数据的真实概率分布。n元模型的交叉熵的定义为:
%3D-%5Csum%7Bp(w1%2Cw2%2C…%2Cw_n)%C2%B7q(w1%2Cw2%2C…%2Cw_n)%7D#card=math&code=H_n%28p%2Cq%29%3D-%5Csum%7Bp%28w1%2Cw2%2C…%2Cw_n%29%C2%B7q%28w1%2Cw2%2C…%2Cw_n%29%7D&id=nDqrx)
这里p表示真实概率分布,q表示某一个模型确定的概率分布。有关系成立
![2022-02-16-[ML]-重温Word2Vec及2种优化策略 - 图11](/uploads/projects/ningshixian@pz10h0/5ab0337173327772f719c6115cd034b2.svg)
熵表示一个概率分布的不确定性,交叉熵表示一个概率分布相对于另一个概率分布的不确定性。熵是交叉熵的下界。如果一个语言模型比另一个语言模型能更准确地预测单词序列数据,那么它就应该有更小的交叉熵。香农的研究为语言模型学习提供了评价工具。
乔姆斯基与语言模型
乔姆斯基(Noam Chomsky)于1956年提出了著名的乔姆斯基层次结构,指出用n元模型描述自然语言存在局限性
乔姆斯基理论认为,语言由句子的有限或无限集合组成,每个句子是有限长度的单词序列,单词来自一个有限的词表,语法是能够产生这个语言所有句子的“装置”。语法有不同的复杂度,形成层次化结构。由有限状态机表示的语法称为有限状态语法。
基于马尔可夫链定义的语法是一个有限状态语法。这个语法或者任何一个有限状态语法不能生成英语的所有句子。英语的表示之间存在依存关系,比如以下的S1和S2之间、S3和S4之间。![2022-02-16-[ML]-重温Word2Vec及2种优化策略 - 图12](/uploads/projects/ningshixian@pz10h0/3bf4ec9df3ac1507e81ee847c7558658.webp)
原理上,依存关系可以无限组合,生成仍然正确的英语句子(如例(iii))。而有限状态语法无法描述这种组合,理论上存在不能覆盖的英语句子。因此,乔姆斯基认为,用有限状态语法刻画语言有很大局限性。受他的影响,在之后的几十年里,自然语言处理等领域中通常使用更复杂的上下文无关语法。
⭐️神经语言模型
N-gram 模型的表示和学习能力是有限的。传统的方法是从语料中统计n元模型中的条件概率,对未见过的n元组的概率通过平滑的方法估算。模型的参数个数是指数级的 #card=math&code=O%28V%5En%29&id=bnw84),其中
是词表的大小。当
增大时,无法准确地学到模型的参数。
使用语言模型产生词向量的一个里程碑论文是 Bengio 在 2003 年提出的 NNLM,该模型通过使用神经网络训练得到了一个语言模型,同时产生了副产品词向量。%3Df%5Ctheta(w%7Bi-n%2B1%7D%2Cw%7Bi-n%2B2%7D%2C…%2Cw%7Bi-1%7D)#card=math&code=p%28wi%7Cw%7Bi-n%2B1%7D%2Cw%7Bi-n%2B2%7D%2C…%2Cw%7Bi-1%7D%29%3Df%5Ctheta%28w%7Bi-n%2B1%7D%2Cw%7Bi-n%2B2%7D%2C…%2Cw%7Bi-1%7D%29&id=XSMkA)
模型的总体架构如下图所示,表达的思想是利用前 n-1 个词去预测第 n 个词的概率,所以这里的输入是 n-1 个词,输出是一个维度为词表大小的向量,代表每个词出现的概率。
Bengio从两个方面对N-gram 模型予以改进。一是用一个低维的实值向量表示一个单词或单词的组合;二是在使用词向量的基础上,用了一个三层的神经网络来构建语言模型,大幅减少模型的参数. 
NNLM 模型在获取词向量上的工作是奠基性的,但是其模型训练的复杂度还是过高,后续很多算法都是在 NNLM 的基础上进行改进,比如耳熟能详的 Word2vec(下一节介绍)对其训练的复杂度进行了针对性的改进,
预训练语言模型
上述类型的嵌入主要有两个缺陷:一是嵌入是静态的,词在不同的上下文中的嵌入表示是相同的,因此无法处理一词多义;二是未登录词(out-of-vocabulary,OOV)问题。为了解决上述问题,基于上下文的动态词嵌入出现了。优势:可作为初始词向量、解决处理一词多义问题、能增强模型的泛化能力
预训练语言模型的基本想法是,基于Transformer模型的编码器或解码器实现语言模型。首先使用大规模的语料通过无监督学习的方式学习模型的参数,即进行预训练;之后将模型用于一个具体任务,使用少量的标注数据通过监督学习的方式进一步调节模型的参数,即进行微调。
预训练语言模型的应用给自然语言处理带来了极大的成功。(微调后的)BERT在语言理解任务上,比如阅读理解,准确率已超过人类;(微调后的)GPT在语言生成任务上也达到了让人惊叹的程度,比如生成的假新闻能够以假乱真,说明预训练语言模型已经能够学习和表示大量的语言知识。具体细节可参考《2020-04-10-预训练语言模型小酌》
Word2Vec 详解
Word2Vec 是一款开源词向量工具包(Mikolov et al. 2013a),该工具包在算法理论上参考了 Benjio(2003)设计的NNLM模型,在处理大规模、超大规模的语料时,可以简单并且 高效地获取高精度的词向量,在学术界和业界都获得了广泛的关注。
Word2vec 的实现主要有连续词袋模型(CBOW,Continuous Bag-of-Words)和跳跃元语法模型(Skip-Gram)两种。这两个模型目的都是通过训练语言模型任务,得到词向量。
- CBOW 在已知 context(w) 的情况下,向量求和,softmax 预测 w;
- Skip-Gram在已知 w 的情况下预测 context(w) ;
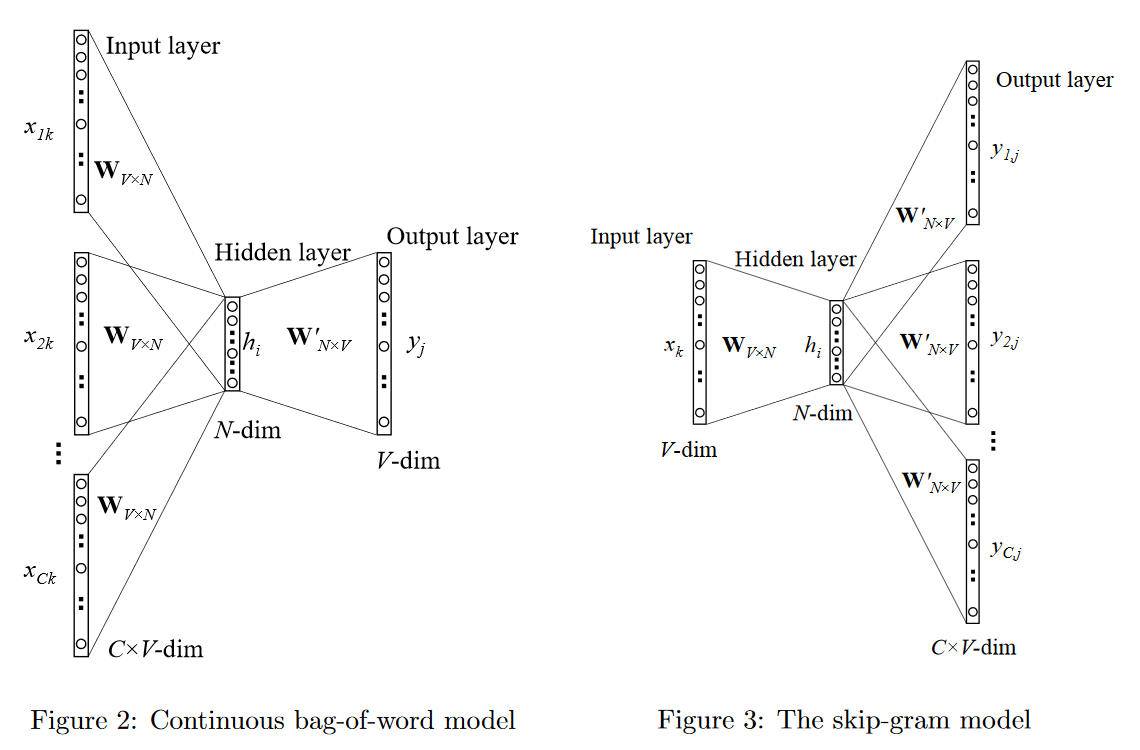
存在问题:Word2vec 本质上是一个语言模型,它的输出节点数是 V 个,对应了 V 个词语,也是一个多分类问题。考虑到sofmax归一化需要遍历整个词汇表(时间复杂度为 O(|V|)),当词汇表较大时,计算量巨大!如何优化和加速呢?word2vec支持两种优化方法:hierarchical softmax 和 negative sampling。此部分仅做关键介绍,数学推导请仔细阅读《word2vec 中的数学原理详解》。
(1)基于hierarchical softmax 的 CBOW 和 Skip-gram
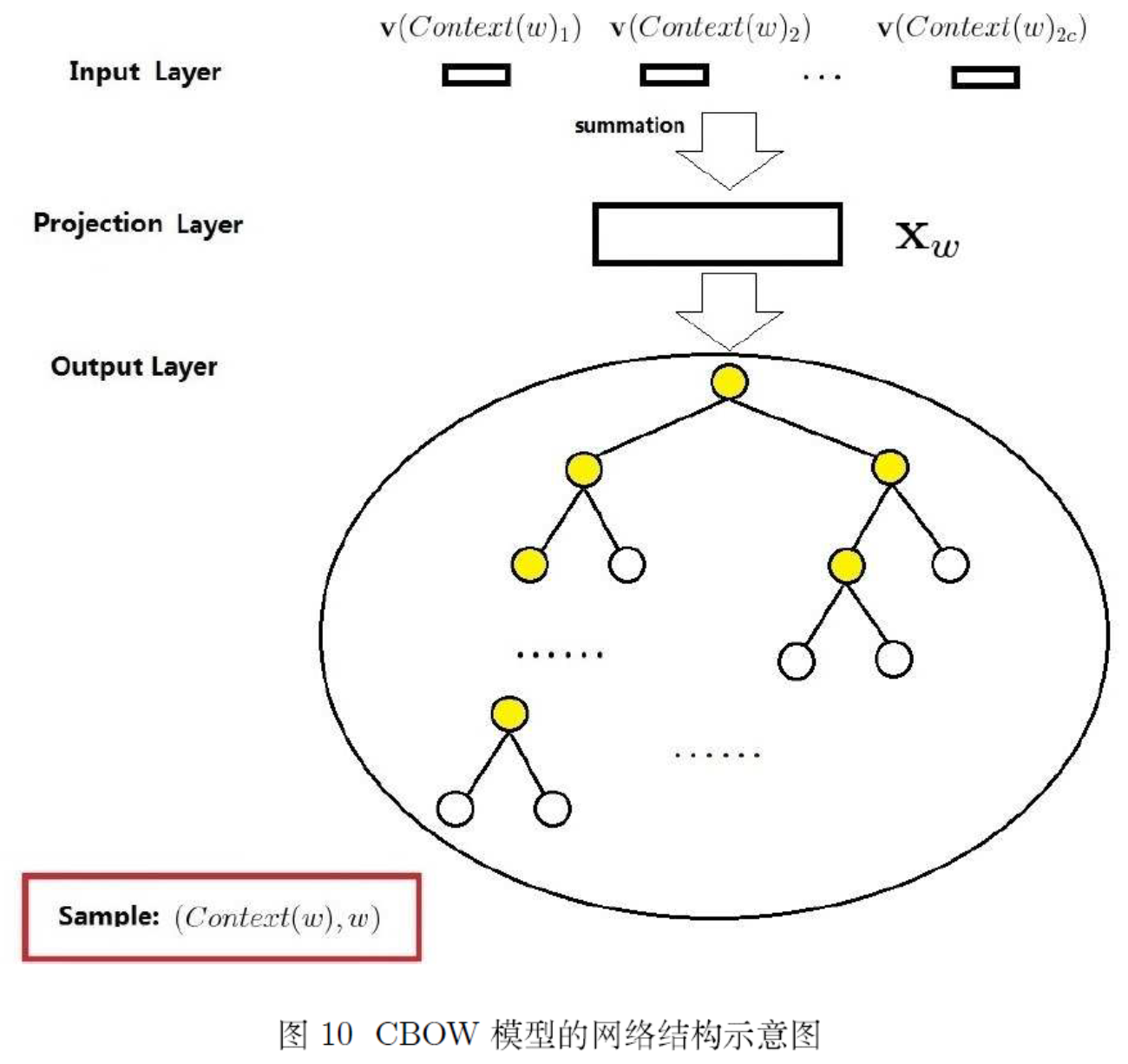 |
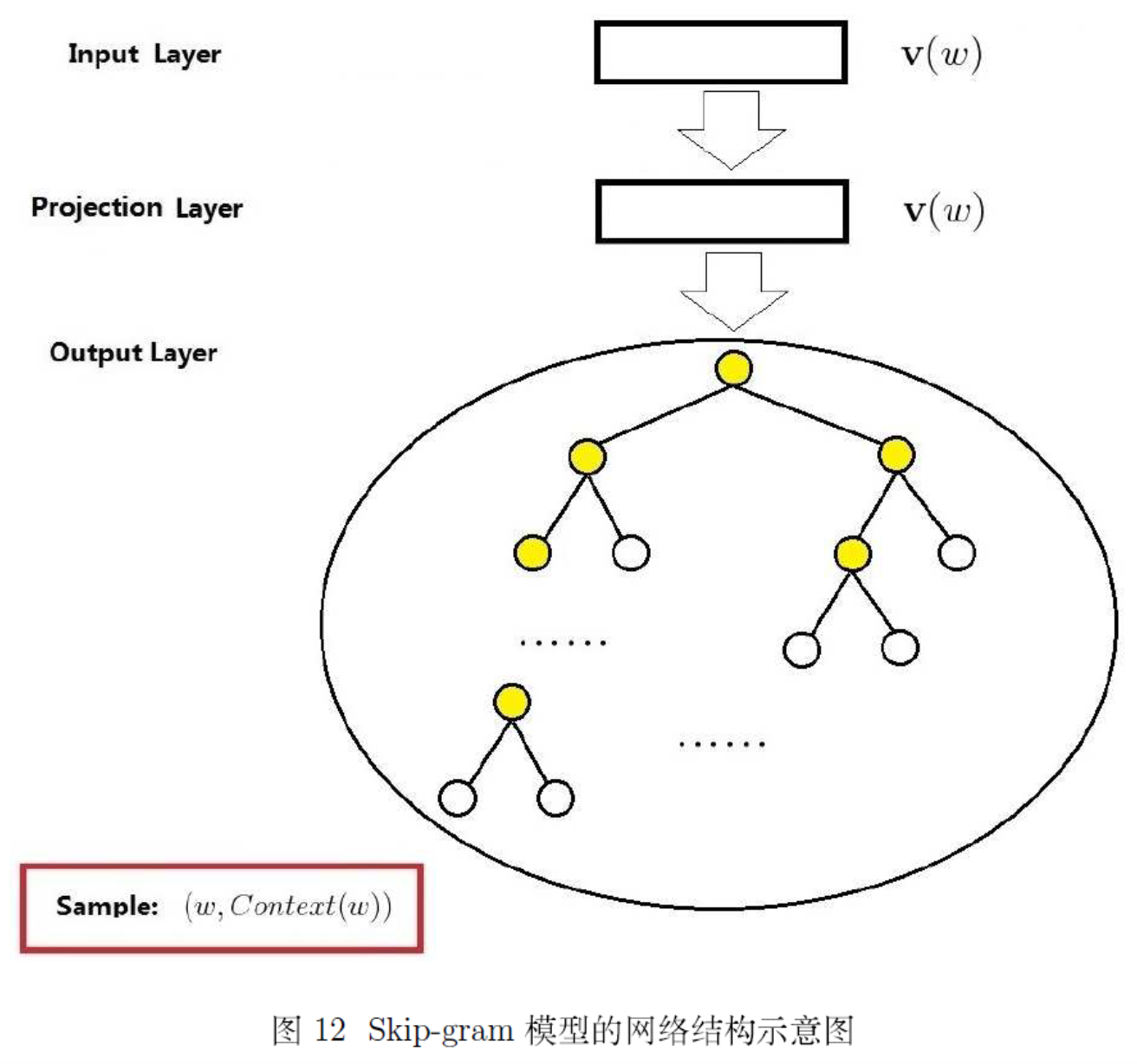 |
|---|---|
之前说过,NNLM 的主要运算量就是在于隐藏层和输出层的 softmax 的计算量,基于 Hierarchical Softmax 的方法通过对这些关键点进行了针对性的优化,去掉了隐藏层,更改了输出结构,大大提升了运算效率。
Hierarchical Softmax把原始 softmax 输出层改成了一颗哈夫曼Huffman树,通过哈夫曼编码来保证高频词的搜索路径短,低频词的路径长,这种编码方式很大程度减少了计算量。如图中白色的叶子节点表示词汇表中所有的|V|个词,黄色节点表示非叶子节点;每一个叶子节点也就是每一个单词,词频作为节点的权重,对应唯一的一条从root节点出发的路径。我们的训练目标是使得从根节点到目标叶节点这条路径的概率最大,然后去更新这条路径上所有节点的参数即可,而不需要更新所有的词的出现概率,这样大大的缩小了模型训练更新的时间。
那么,我们应该如何得到某个叶子结点的概率呢?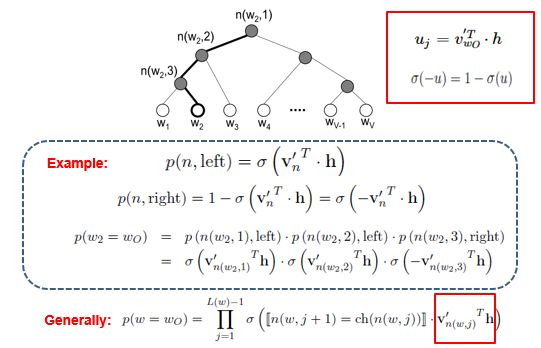
假设我们要计算![2022-02-16-[ML]-重温Word2Vec及2种优化策略 - 图23](/uploads/projects/ningshixian@pz10h0/738cc1209244fa3fe80eaebbc07e7f9e.svg) 叶子节点的概率,我们需要从根节点到叶子结点 计算所有概率的乘积。其中,路径上每个非叶子节点的值经过
叶子节点的概率,我们需要从根节点到叶子结点 计算所有概率的乘积。其中,路径上每个非叶子节点的值经过![2022-02-16-[ML]-重温Word2Vec及2种优化策略 - 图24](/uploads/projects/ningshixian@pz10h0/4e4f2f9013ca0e6de5a527d0ecd395c9.svg) 映射后接一个
映射后接一个 ![2022-02-16-[ML]-重温Word2Vec及2种优化策略 - 图25](/uploads/projects/ningshixian@pz10h0/2eb96f8dbc78479dbf3ca1c069155399.svg) 激活,得到节点该往左子树走的概率
激活,得到节点该往左子树走的概率![2022-02-16-[ML]-重温Word2Vec及2种优化策略 - 图26](/uploads/projects/ningshixian@pz10h0/7a16c7af8470d0b257f0399ddf1aa95e.svg) 和往右子树走的概率
和往右子树走的概率![2022-02-16-[ML]-重温Word2Vec及2种优化策略 - 图27](/uploads/projects/ningshixian@pz10h0/a83f16c937fbf6724849f7994e2d9efb.svg) 。关于 Huffman 树的训练方式比较复杂,但也是通过梯度下降等方法,这里不详述,感兴趣的可以阅读论文《word2vec Parameter Learning Explained》
。关于 Huffman 树的训练方式比较复杂,但也是通过梯度下降等方法,这里不详述,感兴趣的可以阅读论文《word2vec Parameter Learning Explained》
最后,我们的训练目标是使得从根节点到目标叶节点这条路径的概率最大。注意,CBOW和Skip-gram的目标函数稍有区别,CBOW中的目标函数是使条件概率![2022-02-16-[ML]-重温Word2Vec及2种优化策略 - 图28](/uploads/projects/ningshixian@pz10h0/74c36e00cbc42ab3a794348608986824.svg) 最大化,其等价于:
最大化,其等价于:
Skip-gram中的目标函数是使条件概率![2022-02-16-[ML]-重温Word2Vec及2种优化策略 - 图30](/uploads/projects/ningshixian@pz10h0/60f3ccd3df6e76390164c0668a7a70fa.svg) 最大化,其等价于:
最大化,其等价于: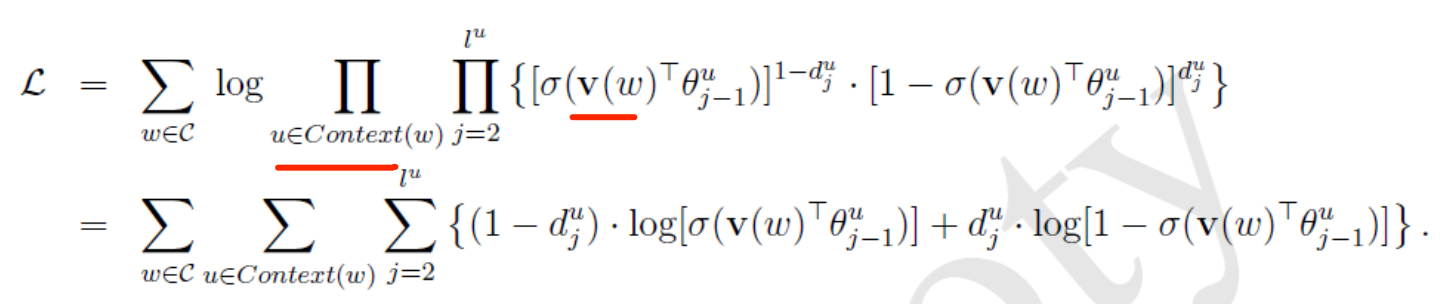
(2)基于negative sampling的 CBOW 和 Skip-gram
关于 Negative Sampling 的推导: https://arxiv.org/pdf/1402.3722.pdf

Negative Sampling 是Noise-Contrastive Estimation(简写NCE,噪声对比估计)的简化版本,目的是进一步提升训练速度,同时改善词向量的质量。Negative Sampling 不再使用相对复杂的 huffman 树,而是使用简单的随机负采样,大幅度提升性能。
过程:1、把语料中的一个词串的中心词替换为别的词,构造语料 D 中不存在的词串作为负样本;2、CBOW和Skip-Gram模型在输出端使用一个二分类器(即Logistic Regression),来区分目标词和词库中其他的 k个词(也就是把目标词作为一类,其他词作为另一类);3、在这种策略下,优化目标变为了:最大化正样本的概率,同时最小化负样本的概率。
对于CBOW,其目标函数是最大化: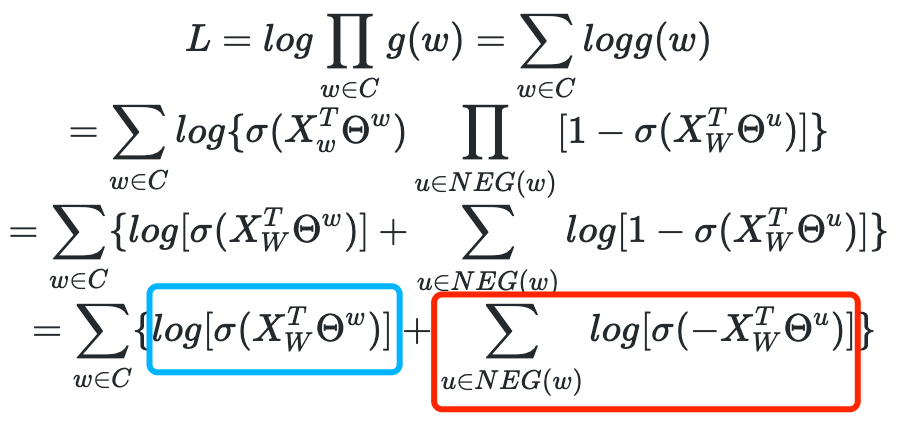
对于Skip-gram,同样也可以得到其目标函数是最大化: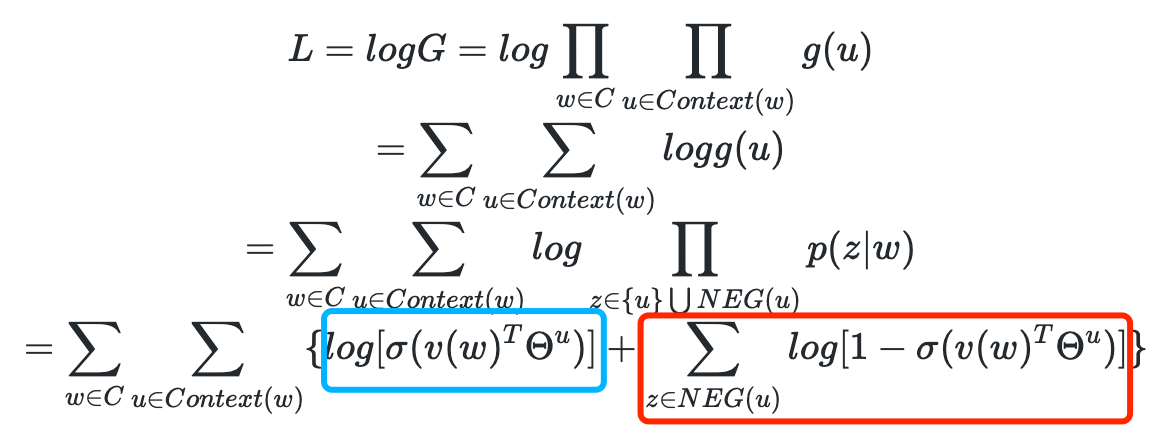
在负采样中,对于给定的词w,如何生成它的负采样集合NEG(w)呢?
以 CBOW 为例,已知一个词w,它的上下文是context(w),那么词w就是一个正例,将当前词w替换为其他词就构成了一个负例。但是负例样本太多了,我们怎么去选取呢?
在语料库C中,各个词出现的频率是不一样的,我们采样的时候要求高频词选中的概率较大,而低频词选中的概率较小。这就是一个带权采样的问题,任何采样算法都应该保证频次越高的样本越容易被采样出来。基本的思路是对于长度为1的线段,根据词语的词频将其公平地分配给词典D中的每个词语:
![2022-02-16-[ML]-重温Word2Vec及2种优化策略 - 图35](/uploads/projects/ningshixian@pz10h0/411f178b56e774fbe1c191a06c1ab7dc.svg)
counter就是w的词频。 于是我们将该线段公平地分配了: 
接下来我们只要生成一个0-1之间的随机数,看看落到哪个区间,就能采样到该区间对应的单词了,很公平。但怎么根据小数找到对应的区间呢?速度慢可不行。
word2vec用的是一种查表的方式,将上述线段标上M个“刻度”,刻度之间的间隔是相等的,即1/M: 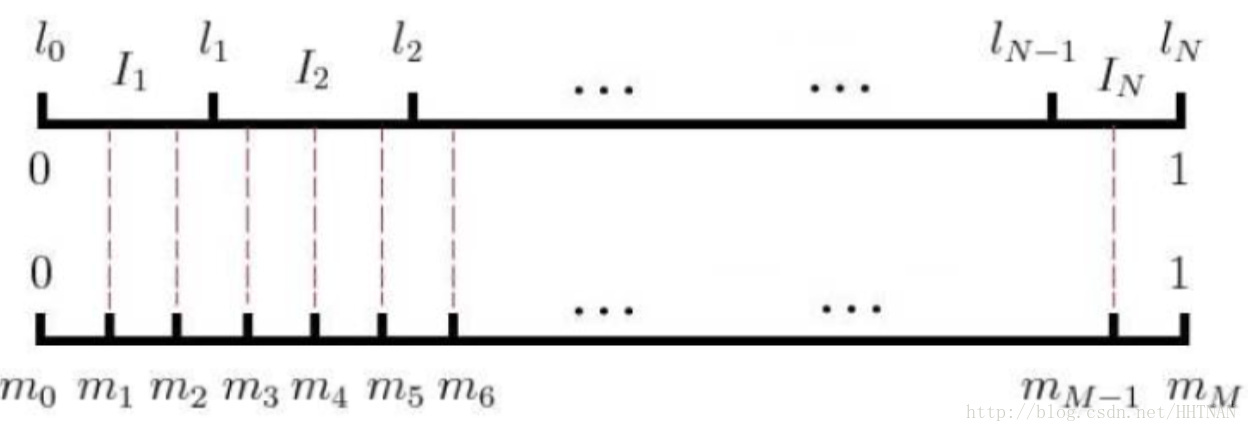
接着我们就不生成0-1之间的随机数了,我们生成0-M之间的整数,去这个刻度尺上一查就能抽中一个单词了。
在word2vec中,该“刻度尺”对应着table数组。具体实现时,对词频取了0.75次幂:
![2022-02-16-[ML]-重温Word2Vec及2种优化策略 - 图38](/uploads/projects/ningshixian@pz10h0/2b1eb00ded148496a7a45196edd130da.svg)
这个幂实际上是一种“平滑”策略,能够让低频词多一些出场机会,高频词贡献一些出场机会,劫富济贫。
CBOW 是利用上下文预测当前词,那么将当前词替换为其他词时,就构成了一个负样本。
拿到负采样集合NEG(w)之后,对于给定的语料库 C,我们最小化如下的目标函数: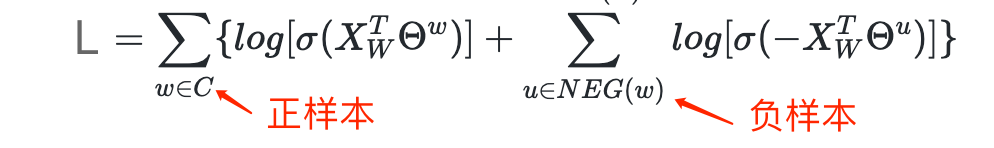

参考
Deep Learning in NLP (一)词向量和语言模型
贝壳找房【语言模型系列】原理篇一:从 one-hot 到 Word2vec
详细图解哈夫曼Huffman编码树
word_embedding的负采样算法,Negative Sampling 模型
知乎:nlp中的词向量对比:word2vec/glove/fastText/elmo/GPT/bert
知乎:word2vec(cbow+skip-gram+hierarchical softmax+Negative sampling)模型深度解析

若有收获,就点个赞吧
0 人点赞
