前言
之前的文章讲解了RNN的基本结构和BPTT算法及梯度消失问题,说到了RNN无法解决长期依赖问题,本篇文章要讲的LSTM很好地解决了这个问题。本文部分内容翻译自Understanding LSTM Networks。
文章分为四个部分:


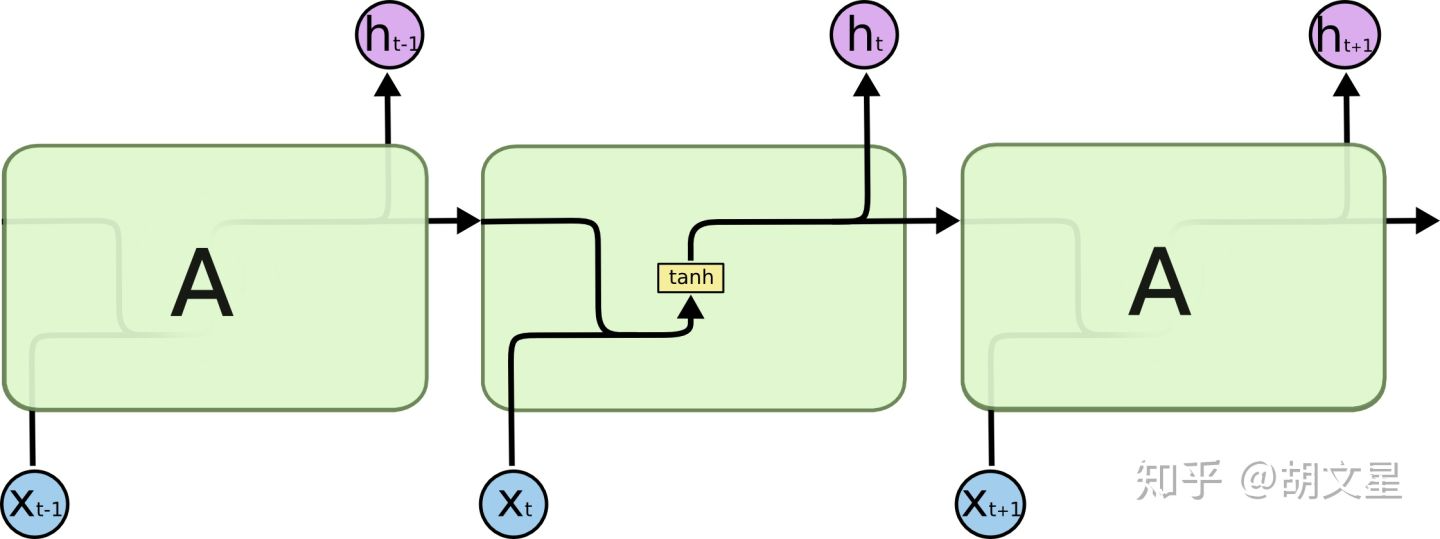
LSTM的重复模块中,有四个层,多了三个门(gate)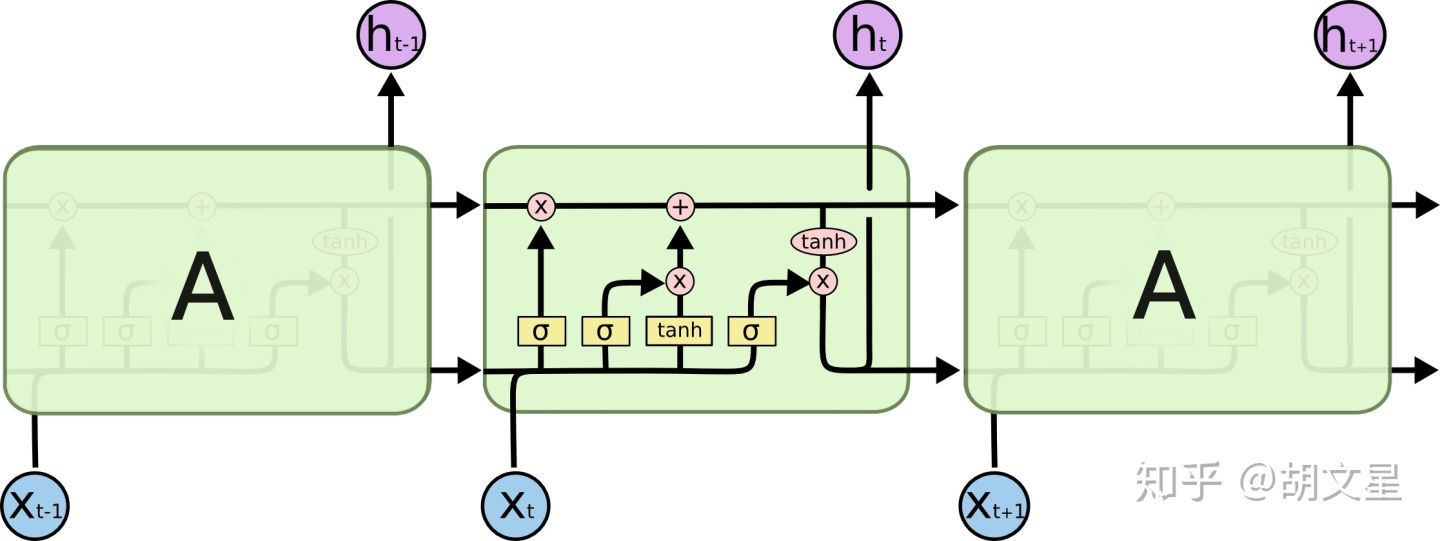
在上面两幅图中,每条黑线都代表一个向量,从上一个节点输出,输入到下一个节点。粉色圆圈代表对每个元素的操作(比如点乘),黄色方框代表神经网络层,两条黑线合并代表向量拼接,一条黑线分为两条代表复制。
二. LSTM的核心思想
原始RNN的隐藏单元只有一个状态,即RNN详解中的  ,它对短期记忆敏感而对长期记忆不那么敏感。而LSTM增加了一个状态,即
,它对短期记忆敏感而对长期记忆不那么敏感。而LSTM增加了一个状态,即 ,用它来保存长期记忆,我们称之为单元状态(cell state),下文中简称为cell。
,用它来保存长期记忆,我们称之为单元状态(cell state),下文中简称为cell。
LSTM的核心就是多出来的这个cell state,下图中的水平黑线代表cell state通过时间序列不断向前传送。传送图中只有少量的线性运算作用在cell state上,所以cell state可以存储着信息并保持它们不怎么变而传送得很远。这就是它能解决长期依赖问题的原因。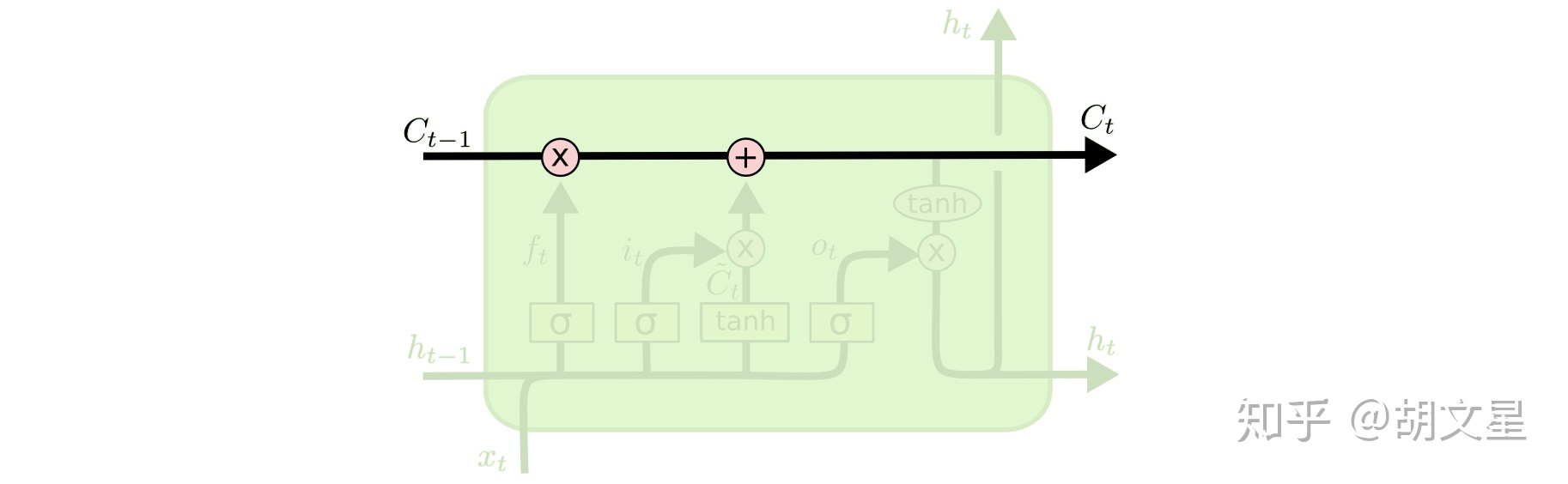
LSTM可以通过门(gate)来向cell state中添加信息或删除信息。
门可以选择性地让信息通过,门的结构是用一个sigmoid层来点乘cell state: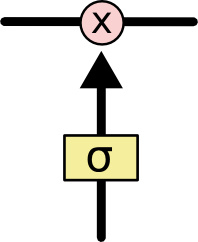
sigmoid层输出的值从0到1,这个值描述多少信息能通过。0表示啥也过不去,1表示啥都放过去。
LSTM一共有三个门,来帮助cell state遗忘、输入、输出。
三. 分四步详细讲解LSTM★
1.决定什么信息需要从cell中丢弃掉。
通过构建一个遗忘门(forget gate):输入当前时刻的  和上一时刻的输出
和上一时刻的输出  ,输出一个和
,输出一个和  同维度的向量,矩阵中每一个值都代表
同维度的向量,矩阵中每一个值都代表  中对应参数的去留情况,0代表彻底丢掉,1代表完全保留。
中对应参数的去留情况,0代表彻底丢掉,1代表完全保留。
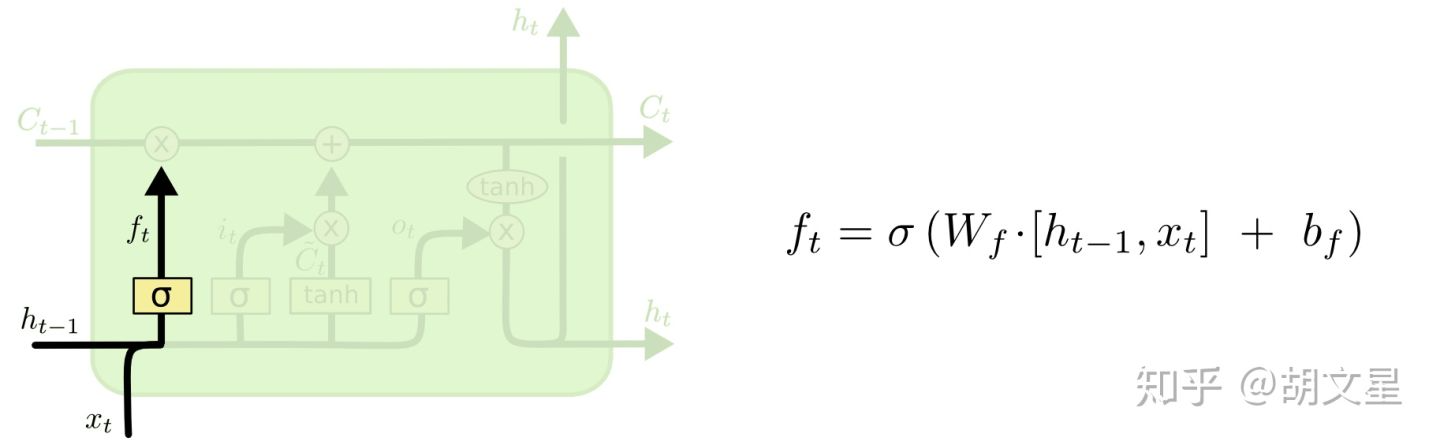
举个例子:比如一个语言模型,根据之前的所有词预测下一个词。在这个问题中,cell可能已经记住了当前人物的性别,以便下次预测人称代词(他、她)时使用。但是当我们遇到一个新人物时,我们需要将旧人物的性别忘掉。
2.决定要往cell中存储哪些新信息。
这一步有两个部分:
a.通过构建一个输入门(input gate),决定要更新哪些信息。

b.然后构建一个候选值向量(cell):  ,之后会用输入门点乘这个候选值向量,来选出要更新的信息。
,之后会用输入门点乘这个候选值向量,来选出要更新的信息。

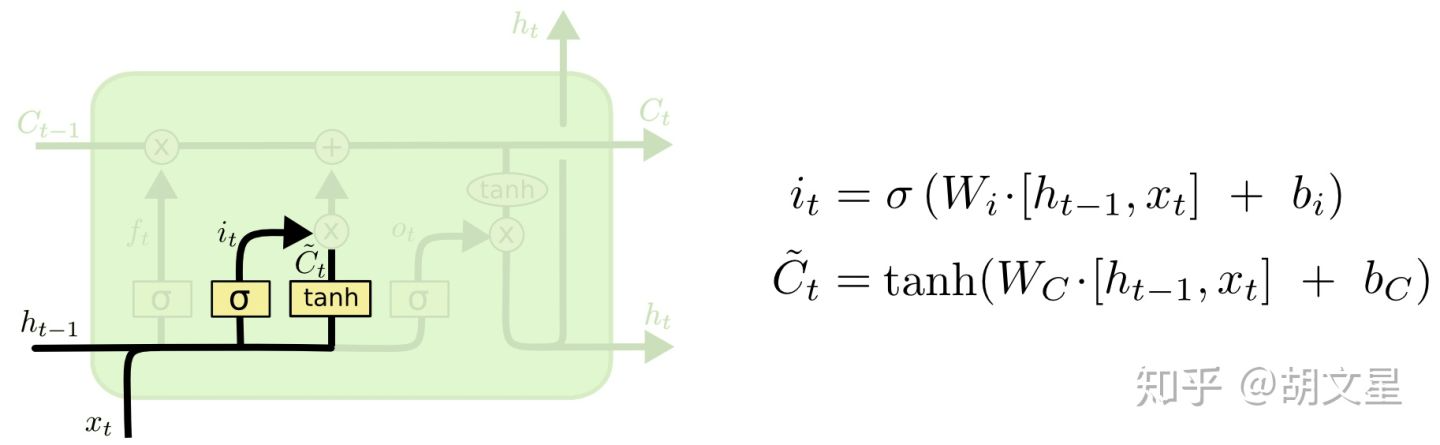
在语言模型的例子中:这一步我们是想要把新人物的性别记住。
3.执行前两步:遗忘旧的、保存新的。
这一步我们对旧cell  进行更新,变成新cell
进行更新,变成新cell  。
。

 点乘
点乘  代表我们丢弃掉要遗忘的信息。
代表我们丢弃掉要遗忘的信息。  点乘
点乘  代表我们从候选值向量中挑出要更新记住的信息。
代表我们从候选值向量中挑出要更新记住的信息。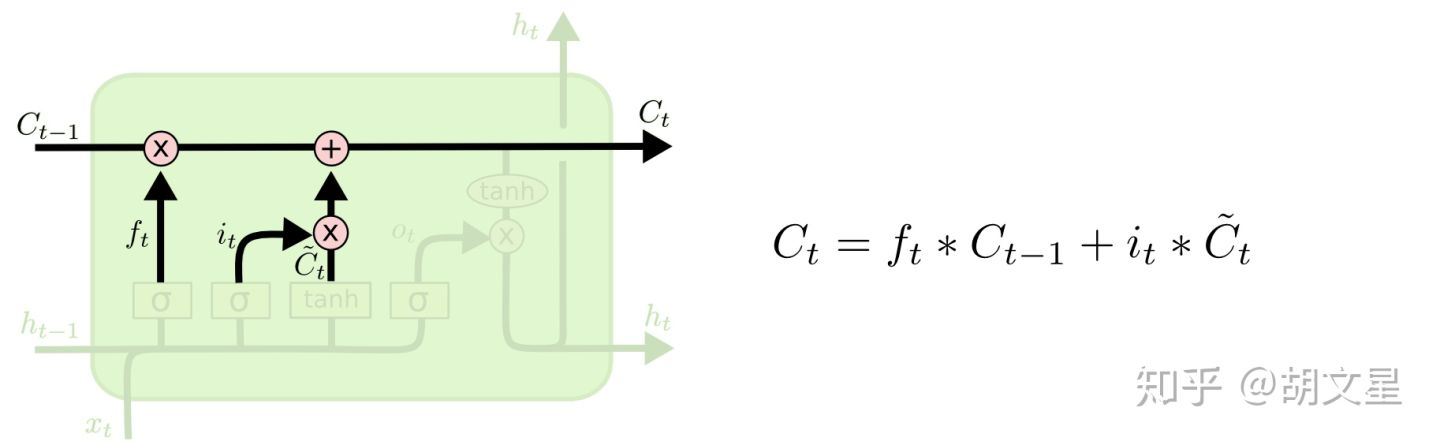
在语言模型的例子中:这一步真正执行下面的操作:忘旧人物的性别,记住新人物的性别。
4.决定输出什么。
分为两步:
a.构建一个输出门(output gate):决定要输出哪些信息。

b.将cell  输入
输入  函数将所有参数值压缩为-1到1之间的值。然后将其点乘输出门,输出我们想输出的部分。
函数将所有参数值压缩为-1到1之间的值。然后将其点乘输出门,输出我们想输出的部分。
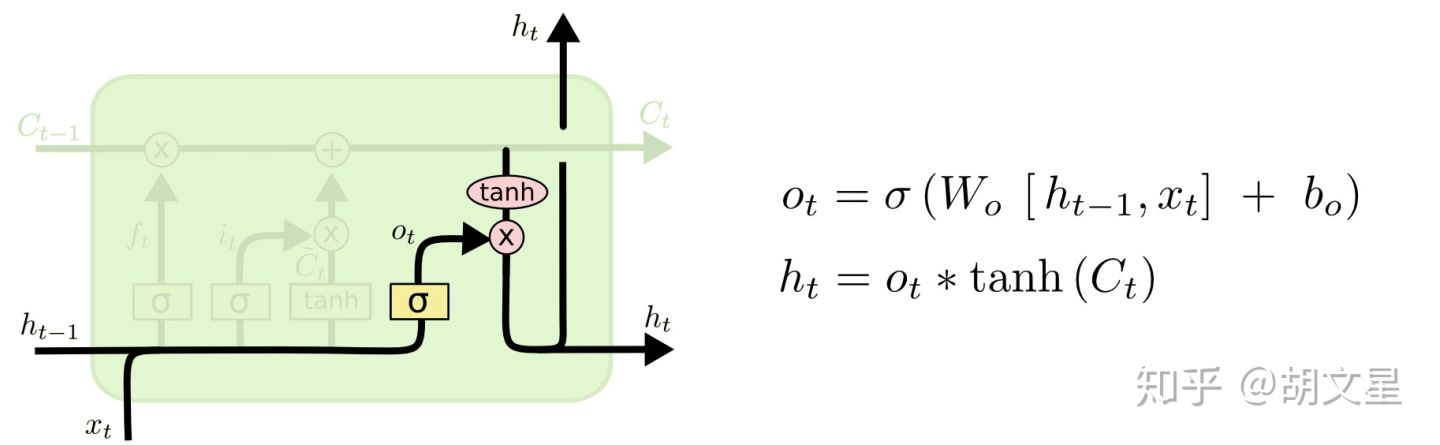
在语言模型的例子中:比如刚看到一个人称代词he或they(cell状态已经存储),而下一个词可能是一个动词,那么我们从人称代词(cell状态)就可以看出下一个动词的形式,比如(makes, make),he对应makes,they对应make。
四. LSTM的变体
上述的LSTM是最原始的LSTM,还有很多变体。
第一种变体由Gers & Schmidhuber (2000)提出,这种变体添加了窥视孔连接(peephole connections)。具体操作就是每个门(gate)的输入多加了cell state。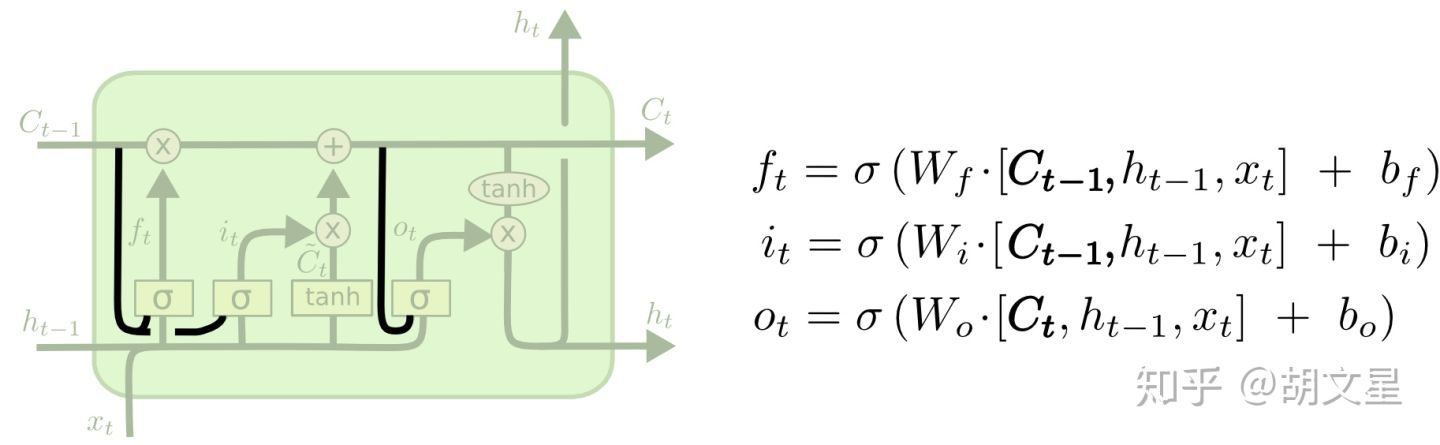
第二种变体是去掉输入门(input gate)。不去分开决定遗忘什么输入什么,而是一起做决定,只有要遗忘的值才去对它们输入更新。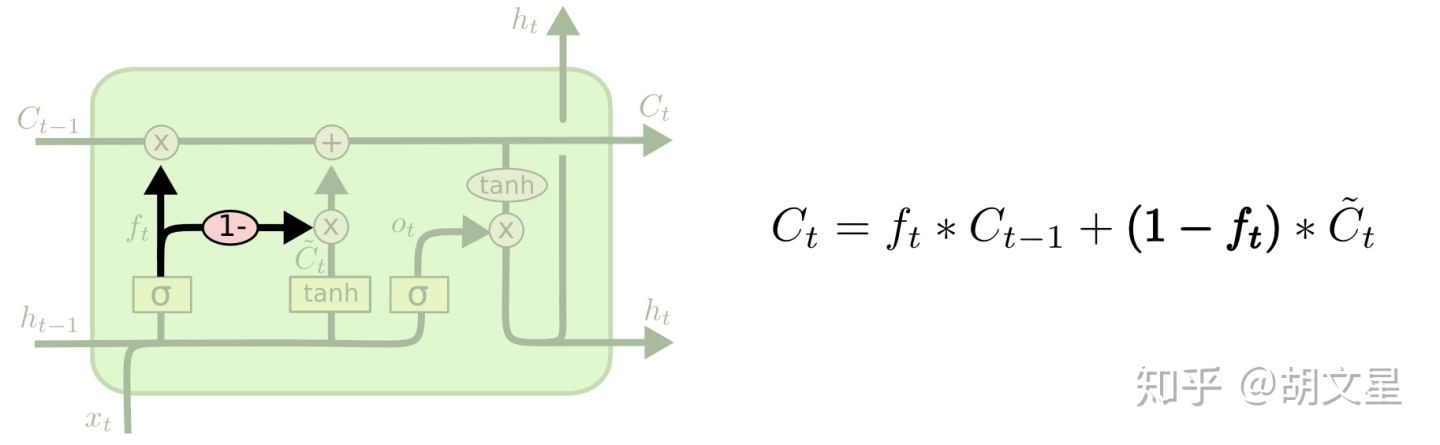
第三种变体由Cho, et al. (2014)提出,名为GRU。它将遗忘门和输入们简化为一个更新门,还将cell state和隐藏单元(hidden state)合并起来。结构相对LSTM更简单,也很流行。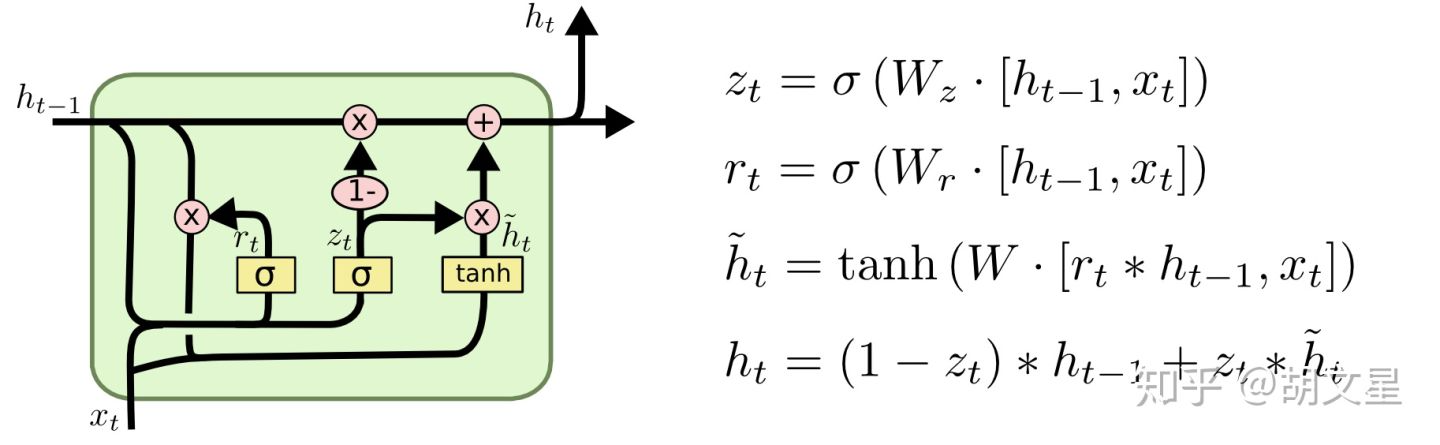
References:
[1] Understanding LSTM Networks
[2] 零基础入门深度学习(6) - 长短时记忆网络(LSTM)
[3] Bengio的深度学习(花书)

若有收获,就点个赞吧
0 人点赞
