title: 用人话解释交叉熵
subtitle: 转载自《一文搞懂交叉熵在机器学习中的使用,透彻理解交叉熵背后的直觉》
date: 2020-07-23
author: NSX
catalog: true
tags:
- 交叉熵
交叉熵(cross entropy)是深度学习中常用的一个概念,一般用来求目标与预测值之间的差距。以前做一些分类问题的时候,没有过多的注意,直接调用现成的库,用起来也比较方便。最近开始发现自己对交叉熵的理解有些模糊,不够深入。遂花了几天的时间从头梳理了一下相关知识点,才算透彻的理解了,特地记录下来,以便日后查阅。
- 信息论(熵概念介绍)
- 为什么要用交叉熵做loss函数?
- 交叉熵在单分类问题中的使用
- 交叉熵在多分类问题中的使用
信息论
交叉熵是信息论中的一个概念,要想了解交叉熵的本质,需要先从最基本的概念讲起。
1 信息量
首先是信息量。假设我们听到了两件事,分别如下:
- 事件A:巴西队进入了2018世界杯决赛圈。
- 事件B:中国队进入了2018世界杯决赛圈。
仅凭直觉来说,显而易见事件B的信息量比事件A的信息量要大。究其原因,是因为事件A发生的概率很大,事件B发生的概率很小。所以当越不可能的事件发生了,我们获取到的信息量就越大。越可能发生的事件发生了,我们获取到的信息量就越小。那么信息量应该和事件发生的概率有关。
假设是一个离散型随机变量,其取值集合为
,概率分布函数
%3DPr(X%3Dx)%EF%BC%8Cx%E2%88%88%CF%87#card=math&code=p%28x%29%3DPr%28X%3Dx%29%EF%BC%8Cx%E2%88%88%CF%87&id=dRNjW),则定义事件
的信息量为:
%3D%E2%88%92log(p(x_0))%0A#card=math&code=I%28X%3Dx_0%29%3D%E2%88%92log%28p%28x_0%29%29%0A&id=j8QQR)
由于是概率所以#card=math&code=p%28x0%29&id=qxlq2)的取值范围是
,绘制为图形如下:
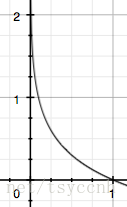
可见该函数符合我们对信息量的直觉。
2 熵
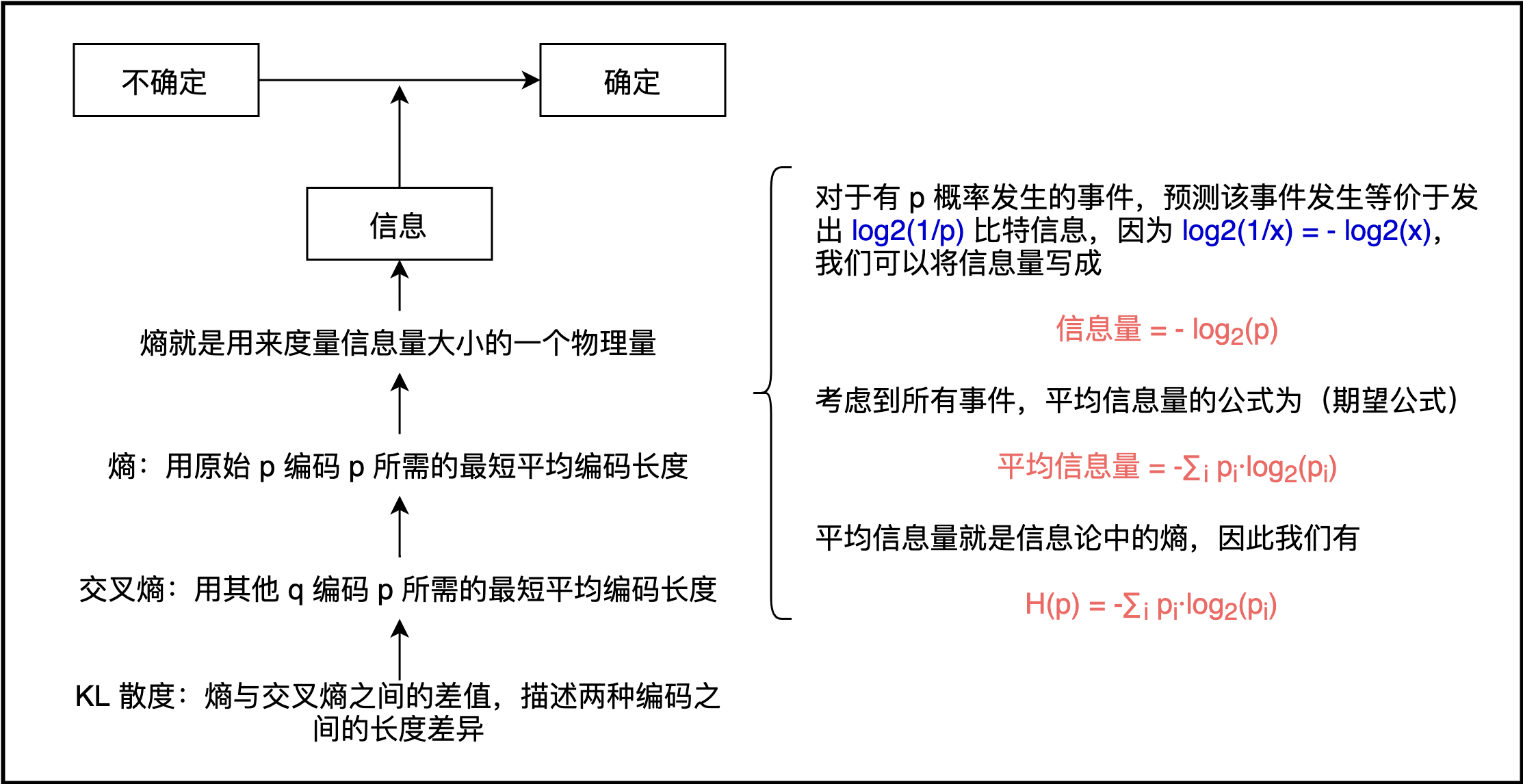
信息论主要研究如何量化数据中的信息。最重要的信息度量单位是熵Entropy,一般用H表示。分布的熵的公式如下:%C2%B7log%20p(xi)%0A#card=math&code=H%3D%E2%88%92%E2%88%91%7Bi%3D1%7D%5Enp%28x_i%29%C2%B7log%20p%28x_i%29%0A&id=KCHF5)
上面对数没有确定底数,可以是2、e或10,等等。熵的主要作用是告诉我们最优编码信息方案的理论下界(存储空间),以及度量数据的信息量的一种方式。理解了熵,我们就知道有多少信息蕴含在数据之中。
考虑如下例子,对于某个事件,有种可能性,每一种可能性都有一个概率
#card=math&code=p%28x_i%29&id=NszLl),这样就可以计算出某一种可能性的信息量。举一个例子,假设你拿出了你的电脑,按下开关,会有三种可能性,下表列出了每一种可能的概率及其对应的信息量:
| 序号 | 事件 | 概率p | 信息量I |
|---|---|---|---|
| A | 电脑正常开机 | 0.7 | -log(p(A))=0.36 |
| B | 电脑无法开机 | 0.2 | -log(p(B))=1.61 |
| C | 电脑爆炸了 | 0.1 | -log(p(C))=2.30 |
那么,熵用来表示所有信息量的期望,即:

3 相对熵(KL散度)
K-L散度定义见文末附录1。另外在附录5中解释了为什么在深度学习中,训练模型时使用的是
Cross Entropy而非K-L Divergence。
相对熵(Kullback-Leibler Divergence),即K-L散度,是一种量化两种概率分布P和Q之间差异的方式。在概率学和统计学上,我们经常会使用一种更简单的、近似的分布来替代观察数据或太复杂的分布。K-L散度能帮助我们度量使用一个分布来近似另一个分布时所损失的信息量。
KL散度的计算公式:
注:n为事件的所有可能性。显然,根据上面的公式,K-L散度其实是数据的原始分布p和近似分布q之间的对数差值的期望。的值越小,表示q分布和p分布越接近.
在机器学习中,往往用来表示样本的真实分布,比如[1,0,0]表示当前样本属于第一类。
用来表示模型所预测的分布,比如[0.7,0.2,0.1]。直观的理解就是如果用P来描述样本,那么就非常完美。而用Q来描述样本,虽然可以大致描述,但是不是那么的完美,信息量不足,需要额外的一些“信息增量”才能达到和P一样完美的描述。如果我们的Q通过反复训练,也能完美的描述样本,那么就不再需要额外的“信息增量”,Q等价于P。
4 交叉熵
交叉熵计算公式:%3D%E2%88%92%E2%88%91%7Bi%3D1%7D%5En%7Bp(x_i)log(q(x_i))%7D%0A#card=math&code=H%28p%2Cq%29%3D%E2%88%92%E2%88%91%7Bi%3D1%7D%5En%7Bp%28x_i%29log%28q%28x_i%29%29%7D%0A&id=N6Egq)
其中,p是结果的真实分布,q是近似分布,n表示类别数量
在机器学习中,单样本的交叉熵定义为:
多样本的总交叉熵为:
其中,y是真实标签;p(y)是近似分布,即分类器的概率预测;n表示类别数量,m 表示样本总数;
如果你熟悉神经网络,你肯能已经猜到我们接下来要学习的内容。除去神经网络结构的细节信息不谈,整个神经网络模型其实是在构造一个参数数量巨大的函数(百万级,甚至更多),不妨记为f(x),通过设定目标函数,可以训练神经网络逼近非常复杂的真实函数g(x)。训练的关键是要设定目标函数,反馈给神经网络当前的表现如何。训练过程就是不断减小目标函数值的过程。
我们已经知道K-L散度用来度量在逼近一个分布时的信息损失量。K-L散度能够赋予神经网络近似表达非常复杂数据分布的能力。由于KL散度中的前一部分#card=math&code=%E2%88%92H%28y%29&id=legrm)不变,故在优化过程中,只需要关注交叉熵就可以了。所以一般在机器学习中直接用用交叉熵做loss,评估模型。
参考
- 为什么交叉熵(cross-entropy)可以用于计算代价?-知乎
- Why You Should Use Cross-Entropy Error Instead Of Classification Error Or Mean Squared Error For Neural Network Classifier Training
- 如何理解K-L散度(相对熵)
附录
1.K-L 散度的定义

2.计算K-L的注意事项

3.遇到log 0时怎么办

4.信息熵 vs. 交叉熵 vs. 相对熵
细节见知乎如何通俗的解释交叉熵与相对熵?
- 信息熵,即熵,香浓熵。编码方案完美时,最短平均编码长度。
- 交叉熵,cross-entropy。编码方案不一定完美时(由于对概率分布的估计不一定正确),平均编码长度。是神经网络常用的损失函数。
- 相对熵,即K-L散度,relative entropy。编码方案不一定完美时,平均编码长度相对于最小值的增加值。
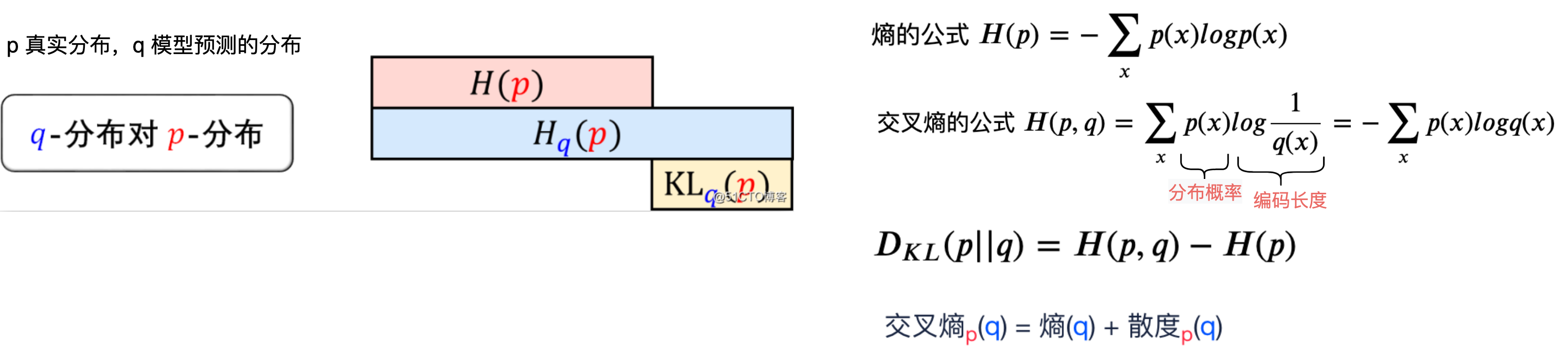
5.为什么在神经网络中使用交叉熵损失函数,而不是K-L散度?
K-L散度=交叉熵-熵,即 D_KL( p||q )=H(p,q)−H(p)。
在神经网络所涉及到的范围内,H(p)不变,则DKL( p||q )等价H(p,q)。
更多讨论见Why do we use Kullback-Leibler divergence rather than cross entropy in the t-SNE objective function?和Why train with cross-entropy instead of KL divergence in classification?

若有收获,就点个赞吧
0 人点赞
