layout: post # 使用的布局(不需要改)
title: 从零开始用Python搭建神经网络 # 标题
subtitle: 前向传播、损失函数、反向传播、神经网络函数 # 副标题
date: 2018-11-12 # 时间
author: NSX # 作者
header-img: img/post-bg-2015.jpg # 这篇文章标题背景图片
catalog: true # 是否归档
tags: # 标签
- 技术
- 教程
从零开始用Python构建神经网络
这是一份用于理解深度学习内部运作方式的初学者指南,内容涵盖
- 神经网络定义
- 损失函数
- 前向传播
- 反向传播
- 梯度下降算法
感知机和神经网络
感知机(perceptron)是由两层神经元组成的结构,输入层用于接受外界输入信号,输出层(也被称为是感知机的功能层)就是M-P神经元。下图表示了一个输入层具有三个神经元(分别表示为𝑥0、𝑥1、𝑥2)的感知机结构: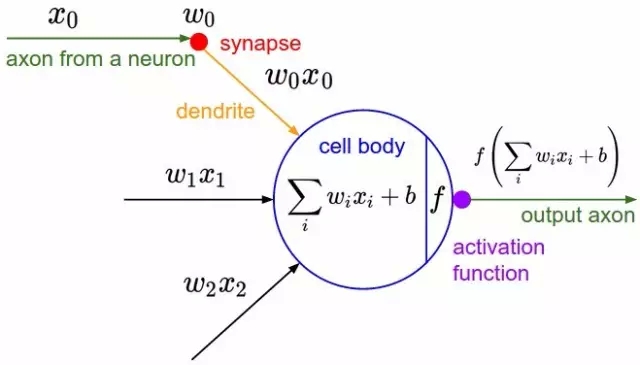
根据上图不难理解,感知机模型可以由如下公式表示:
其中,𝑤为感知机输入层到输出层连接的权重,𝑏表示输出层的偏置, f 表示非线性激活函数(增强模型对复杂函数的拟合能力)。事实上,感知机是一种判别式的线性分类模型,可以解决与、或、非这样的简单的线性可分(linearly separable)问题,线性可分问题的示意图见下图:
但是由于它只有一层功能神经元,所以学习能力非常有限。事实证明,单层感知机无法解决最简单的非线性可分问题——异或问题(有想了解异或问题或者是感知机无法解决异或问题证明的同学请移步这里《证:单层感知机不能表示异或逻辑》)。
关于感知机解决异或问题还有一段历史值得我们简单去了解一下:感知器只能做简单的线性分类任务。但是当时的人们热情太过于高涨,并没有人清醒的认识到这点。于是,当人工智能领域的巨擘Minsky指出这点时,事态就发生了变化。Minsky在1969年出版了一本叫《Perceptron》的书,里面用详细的数学证明了感知器的弱点,尤其是感知器对XOR(异或)这样的简单分类任务都无法解决。Minsky认为,如果将计算层增加到两层,计算量则过大,而且没有有效的学习算法。所以,他认为研究更深层的网络是没有价值的。由于Minsky的巨大影响力以及书中呈现的悲观态度,让很多学者和实验室纷纷放弃了神经网络的研究。神经网络的研究陷入了冰河期。这个时期又被称为“AI winter”。接近10年以后,对于两层神经网络的研究才带来神经网络的复苏。
我们知道,我们日常生活中很多问题,甚至说大多数问题都不是线性可分问题,那我们要解决非线性可分问题该怎样处理呢?这就是这部分我们要引出的“多层”的概念。既然单层感知机解决不了非线性问题,那我们就采用多层感知机,我们通常将多层感知机这样的多层结构称之为是神经网络。
神经网络的基本训练过程
训练过程的每一次迭代包含以下步骤:
- 计算预测的输出 ŷ,称为前向传播;
- 更新权重和偏置,称为反向传播;

前提条件
- 首先是我们已经有了训练数据
- 我们已经根据数据的规模、领域,建立了神经网络的基本结构,比如有几层,每一层有几个神经元
- 定义好损失函数来合理地计算误差
前向传播
一个简单 2 层神经网络的输出 ŷ 可以表示为:
%2Bb_2)%0A#card=math&code=%5Chat%20y%3D%CF%83%28W_2%CF%83%28W_1%2AX%2Bb_1%29%2Bb_2%29%0A&id=KwiXw)
也可以写成:%0A#card=math&code=layer1%3D%5Csigma%28W_1X%2Bb_1%29%0A&id=vmqf4)
%0A#card=math&code=output%3D%5Csigma%28W_2layer1%2Bb_2%29%0A&id=u5olS)
其中,权重  和偏置
和偏置  是影响输出
是影响输出  的参数。
的参数。
我们可以在 Python 代码中添加一个前向传播函数来做到这一点。(把b的值永远设置为1):
def sigmoid(x):return 1/(1+np.exp(-x))class NeuralNetwork:def __init__(self, x, y):self.input = xself.weights1 = np.random.rand(self.input.shape[1],4)self.weights2 = np.random.rand(4,1)self.y = yself.output = np.zeros(self.y.shape)def feedforward(self):self.layer1 = sigmoid(np.dot(self.input, self.weights1))self.output = sigmoid(np.dot(self.layer1, self.weights2))
得到输出 之后,如何判断预测结果的好坏呢?这就需要用到损失函数了。
之后,如何判断预测结果的好坏呢?这就需要用到损失函数了。
损失函数
其目标是根据数据自动学习网络的权重,以便让所有输入 𝑥 的预测输出 接近目标 𝑦
接近目标 𝑦
为了衡量与该目标的差距,我们使用了一个误差平方和损失函数(加上平均就是 MSE 均方误差):

误差平方和,即每个预测值和真实值之间差值的平均值。这个差值是取了平方项的,所以我们测量的是差值的绝对值。在训练过程中,我们的目标是找到一组最佳的权重和偏置,使损失函数最小化。
反向传播
现在,我们已经找到了预测误差的方法(损失函数),那么我们需要一种方法将错误「传播」回去,从而更新权重和偏置。这个方法就是BP算法,简称“误差反向传播”,是一种与最优化方法(如梯度下降法)结合使用的,用来训练人工神经网络的常见方法。该方法对网络中所有权重及偏置计算损失函数的梯度/偏导数。这个梯度会反馈给最优化方法,用来更新权值以最小化损失函数。
一句话总结:反向传播是用来快速求解目标函数关于各个参数的梯度;而梯度下降则是根据计算得到的梯度来更新各个权重。
知道了偏导数之后,我们可以通过简单增加或减少偏导数的方式来更新权重和偏置。w 的更新公式如下:
下面,我们开始反向传播误差导数。根据误差函数 ,通过链式法则可以得出:
,通过链式法则可以得出:
%0A#card=math&code=layer1%3D%5Csigma%28W_1X%2Bb_1%29%0A&id=zsd9s)
%0A#card=math&code=output%3D%5Csigma%28W_2layer1%2Bb_2%29%0A&id=lkHyn)
%2Bb_2%3DW_2layer1%2Bb_2%0A#card=math&code=z%3DW_2%CF%83%28W_1%2AX%2Bb_1%29%2Bb_2%3DW_2layer1%2Bb_2%0A&id=ZlsME)

(1-%5Chat%20y)%0A#card=math&code=%5Cfrac%7BdL%7D%7Bdx%7D%3D%5Cfrac%7BdL%7D%7Bd%5Chat%20y%7D%5Cfrac%7Bd%5Chat%20y%7D%7Bdx%7D%3D%28y-%5Chat%20y%29%281-%5Chat%20y%29%0A&id=t234A)
%5Chat%20y(1-%5Chat%20y)layer1%0A#card=math&code=%5Cfrac%7BdL%7D%7Bdw_2%7D%3D%5Cfrac%7BdL%7D%7Bd%5Chat%20y%7D%5Cfrac%7Bd%5Chat%20y%7D%7Bdz%7D%5Cfrac%7Bdz%7D%7Bdw_2%7D%3D%28y-%5Chat%20y%29%2A%5Chat%20y%281-%5Chat%20y%29%2Alayer1%0A&id=Os8sI)
%5Chat%20y(1-%5Chat%20y)%5Cfrac%7Bdz%7D%7Bdw_1%7D%5C%5C%3D(y-%5Chat%20y)%5Chat%20y(1-%5Chat%20y)W_2layer1(1-layer1)X%0A#card=math&code=%5Cfrac%7BdL%7D%7Bdw_1%7D%3D%5Cfrac%7BdL%7D%7Bd%5Chat%20y%7D%5Cfrac%7Bd%5Chat%20y%7D%7Bdz%7D%5Cfrac%7Bdz%7D%7Bdw_1%7D%5C%5C%3D%28y-%5Chat%20y%29%2A%5Chat%20y%281-%5Chat%20y%29%2A%5Cfrac%7Bdz%7D%7Bdw_1%7D%5C%5C%3D%28y-%5Chat%20y%29%2A%5Chat%20y%281-%5Chat%20y%29%2AW_2layer1%281-layer1%29X%0A&id=G0q0B)
反向传播函数的代码如下:
def sigmoid(x):return 1/(1+np.exp(-x))def sigmoid_derivative(x):return x * (1-x) # sigmoid函数的导数class NeuralNetwork:def __init__(self, x, y):self.input = xself.weights1 = np.random.rand(self.input.shape[1],4)self.weights2 = np.random.rand(4,1)self.y = yself.output = np.zeros(self.y.shape)def feedforward(self):self.layer1 = sigmoid(np.dot(self.input, self.weights1))self.output = sigmoid(np.dot(self.layer1, self.weights2))def backprop(self):# application of the chain rule to find derivative of the loss function with respect to weights2 and weights1d_weights2 = np.dot(self.layer1.T, (2*(self.y - self.output) * sigmoid_derivative(self.output)))d_weights1 = np.dot(self.input.T, (np.dot(2*(self.y - self.output) * sigmoid_derivative(self.output), self.weights2.T) * sigmoid_derivative(self.layer1)))# update the weights with the derivative (slope) of the loss functionself.weights1 += d_weights1self.weights2 += d_weights2
为了更深入地理解微积分和链式法则在反向传播中的应用,我强烈推荐 3Blue1Brown 的视频教程。
测试
既然我们已经有了做前向传播和反向传播的完整 Python 代码,我们可以将神经网络应用到一个示例中,看看它的效果。
x = np.array([[0,0,1], [0,1,1], [1,0,1], [1,1,1]]) # datay = np.array([[0],[1],[1],[0]]) # labelnn = NeuralNetwork(x,y)for i in range(1000): # 迭代1000次nn.feedforward()nn.backprop()print(nn.output)
结果
| prediction | Y |
|---|---|
| 0.02191928 | 0 |
| 0.97279658 | 1 |
| 0.95721863 | 1 |
| 0.04292296 | 0 |
通过前向传播和反向传播算法成功训练了神经网络,预测值收敛到了真实值。
参考

若有收获,就点个赞吧
0 人点赞
