本文参考和总结自:
苏剑林. (Dec. 26, 2019). 《“非自回归”也不差:基于MLM的阅读理解问答 》[Blog post]. Retrieved from https://kexue.fm/archives/7148 代码链接:task_reading_comprehension_by_mlm.py
两种生成#
广义来讲,MLM的生成方式也算是seq2seq模型,只不过它属于“非自回归”生成,而我们通常说的(狭义的)seq2seq,则是指自回归生成。本节对这两个概念做简单的介绍。
自回归生成#
顾名思义,自回归 (AutoRegressive) 生成指的是解码阶段是逐字逐字地递归生成的,它建模的是如下的概率分布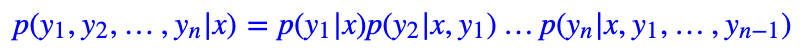
我们通常说的seq2seq(通过encoder编码 sequence,再通过 decoder 解码生成另一个 sequence),都是指自回归生成。更详细的介绍可以参考《玩转Keras之seq2seq自动生成标题》和《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》,在此不对自回归生成做过多介绍。
非自回归生成#
由于自回归生成需要递归地进行解码,无法并行,所以解码速度比较慢,因此近年来有不少工作在研究非自回归生成,也取得不少成果。简单来说,非自回归生成就是想办法使得每个字的解码可并行化,最简单的非自回归模型就是直接假设每个字是独立的: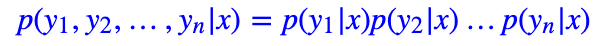
这是一个很强的假设,只有在一些比较特殊的情况下才适用,直接用它来做普通的文本生成如自动摘要的话,效果会很差的。更复杂的非自回归生成的相关工作,大家在Arxiv或Google上搜索non-autoregressive text generation就可以找到很多。
对Bert模型有所了解的读者应该知道,MLM(Masked Language Model)本质上是一个降噪自编码器 (给 input引入噪声[MASK], 通过双向上下文信息表征恢复原始的字词,完成重构 input),所以基于MLM所做的生成模型,属于“非自回归”生成的范畴。
自回归seq2seq vs. 非自回归 MLM
二者都可以做生成任务,那什么时候该用MLM,什么时候该用seq2seq?
- seq2seq最大的问题就是慢,如果长文本生成就更慢了;seq2seq的训练是通过teacher forcing的方式来做的,所以存在“exposure bias”的问题。
- 基于MLM的方案在训练和预测时的行为是一致的,因为不需要真实标签作为输入(预测时答案部分的位置也输入[MASK]),因此不存在误差累积情况。而且也正好因为这个特点,因此解码时不再需要递归,而是可并行化,提高解码速度。此外,MLM等非自回归生成,相对来说更加①适用于短文本生成,②适用于“正确的答案只有一个”的场景
MLM 介绍
MLM,全称“Masked Language Model”,可以翻译为“掩码语言模型”,实际上就是一个完形填空任务,随机Mask掉文本中的某些字词,然后要模型利用上下文信息去预测被Mask的字词,示意图如下:
和我们了解的 CBOW 的核心原理的区别就是,这里只预测 MASK 位置,而不是每个位置都预测
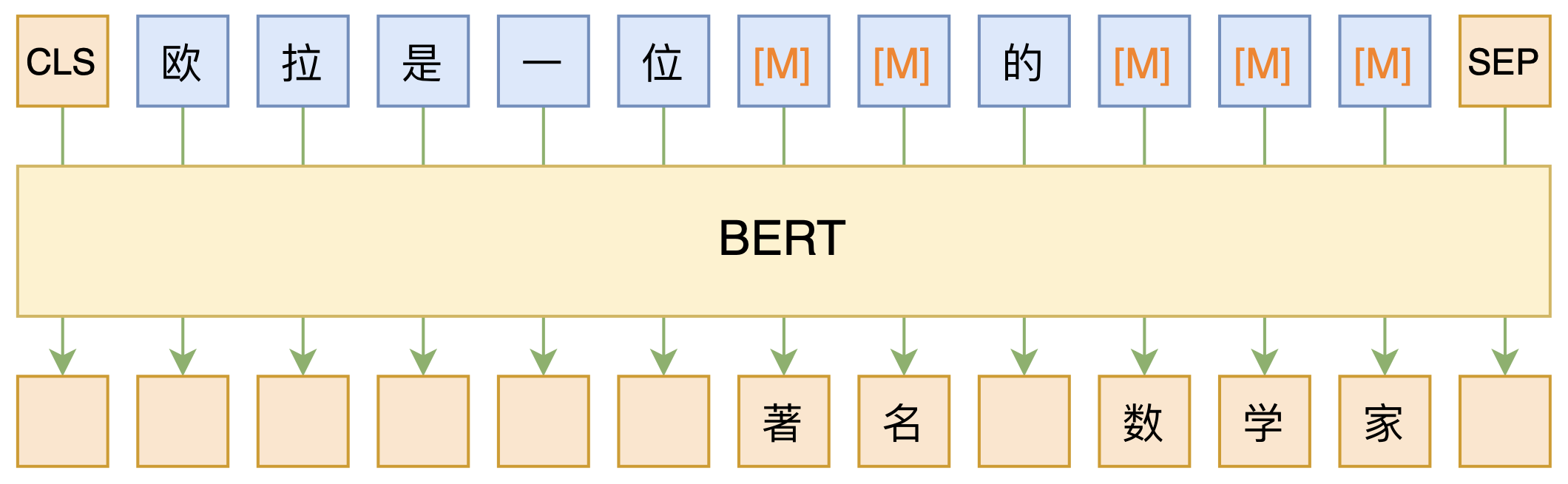
BERT的MLM模型简单示意图
其中被Mask掉的部分,可以是直接随机选择的Token,也可以是随机选择连续的能组成一整个词的Token,后者称为WWM(Whole Word Masking)。
但是,直接这么做的话会有一些问题,训练预料中出现了大量的[MASK]标记,会让模型忽视上下文的影响,只关注当前的[MASK]。举个栗子,当输入一句 my dog is hairy ,其中 hairy 被选中,那么输入变为 my dog is [MASK],训练目的就是将[MASK]这个 token 预测称 hairy,模型会过多的关注[MASK]这个标记,也就是模型认为[MASK]==hairy,这显然是有问题的。而且在预测的过程中,也不会再出现[MASK]这种标记。那么为了避免这种问题,BERT 的实际操作步骤是:
- 随机选择 15% 的词
- 将选中词的 80% 替换成 [MASK],比如 my dog is hairy → my dog is [MASK]
- 将选中词的 10% 随机替换,比如 my dog is hairy → my dog is apple
- 将选中词的 10% 不变,比如 my dog is hairy → my dog is hairy
这样做之后,训练过程中预测当前词时,该位置对应的 token 可以是任何词,那么这样就会强迫模型去学习更多的上下文信息,不会过多的关注于当前 token。
另外,由于在训练过程中只有15%的token被预测,正常的语言模型实际上是预测每个token的,因此Masked LM相比正常LM会收敛地慢一些,ACL 2020的论文《Fast and Accurate Deep Bidirectional Language Representations for Unsupervised Learning》也思考了这个问题,并且提出了一种新的MLM模型设计,能够有更高的训练效率和更好的效果。
MLM 进阶
开始,MLM仅被视为BERT的一个预训练任务,训练完了就可以扔掉的那种,因此有一些开源的模型干脆没保留MLM部分的权重,比如brightmart版和clue版的RoBERTa,而哈工大开源的RoBERTa-wwm-ext-large则不知道出于什么原因随机初始化了MLM部分的权重,因此如果要复现本文后面的结果,这些版本是不可取的。
然而,随着研究的深入,研究人员发现不止BERT的Encoder很有用,预训练用的MLM本身也很有用。比如论文《BERT has a Mouth, and It Must Speak: BERT as a Markov Random Field Language Model》指出MLM可以作为一般的生成模型用,论文《Spelling Error Correction with Soft-Masked BERT》则将MLM用于文本纠错,笔者之前在《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》的实验也表明MLM的预训练权重也可以当作UniLM来用做Seq2Seq任务,还有《无监督分词和句法分析!原来BERT还可以这样用》一文将MLM的思想用于无监督分词和句法分析了。可以说MLM已经是大放异彩了。
下面介绍如何将 MLM用于小样本学习或半监督学习,某些场景下甚至能做到零样本学习。
MLM 应用小样本学习
1、苏剑林. (Sep. 27, 2020). 《必须要GPT3吗?不,BERT的MLM模型也能小样本学习 》[Blog post]. Retrieved from https://kexue.fm/archives/7764 2、苏剑林. (Apr. 03, 2021). 《P-tuning:自动构建模版,释放语言模型潜能 》[Blog post]. Retrieved from https://kexue.fm/archives/8295
怎么将 few-show learning 任务跟MLM结合起来呢?很简单,给任务一个文本描述,然后转换为完形填空问题即可。举个例子,假如给定句子“这趟北京之旅我感觉很不错。”,那么我们补充个描述,构建如下的完形填空:
______满意。这趟北京之旅我感觉很不错。
进一步地,我们限制空位处只能填一个“很”或“不”,问题就很清晰了,就是要我们根据上下文一致性判断是否满意,如果“很”的概率大于“不”的概率,说明是正面情感倾向,否则就是负面的,这样我们就将情感分类问题转换为一个完形填空问题了,它可以用MLM模型给出预测结果,而MLM模型的训练可以不需要监督数据,因此理论上这能够实现零样本学习了。
Pattern-Exploiting#
读到这里,读者应该不难发现其中的规律了,借助由自然语言构成的描述模版(英文常称Pattern或Prompt),并且Mask掉某些Token,将下游任务也转化为一个完形填空任务,这样就可以用BERT的MLM模型来进行预测了。比如下图中通过条件前缀来实现情感分类和主题分类的例子:


然后,我们需要构建预测Token的候选空间,并且建立Token到实际类别的映射,这在原论文中称为Verbalizer,比如情感分类的例子,我们的候选空间是{很,不},映射关系是很→正面,不→负面,候选空间与实际类别之间不一定是一一映射,比如我们还可以加入“挺”、“太”、“难”字,并且认为{很,挺,太}→正面以及{不,难}→负面,等等。不难理解,不少NLP任务都有可能进行这种转换,但显然这种转换一般只适用于候选空间有限的任务,说白了就是只用来做选择题,常见任务的就是文本分类。
这种训练模式被称为Pattern-Exploiting Training(PET),它首先出现在论文《Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference》,而《It’s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners》进一步肯定和完善了Pattern-Exploiting Training的价值和结果。它通过人工构建的模版与BERT的MLM模型结合,并整合&统一了预训练任务和下游任务,能够起到非常好的零样本、小样本乃至半监督学习效果,在SuperGLUE榜单上的小样本学习效果超过了GPT3。两篇论文的作者是相同的,是一脉相承的作品。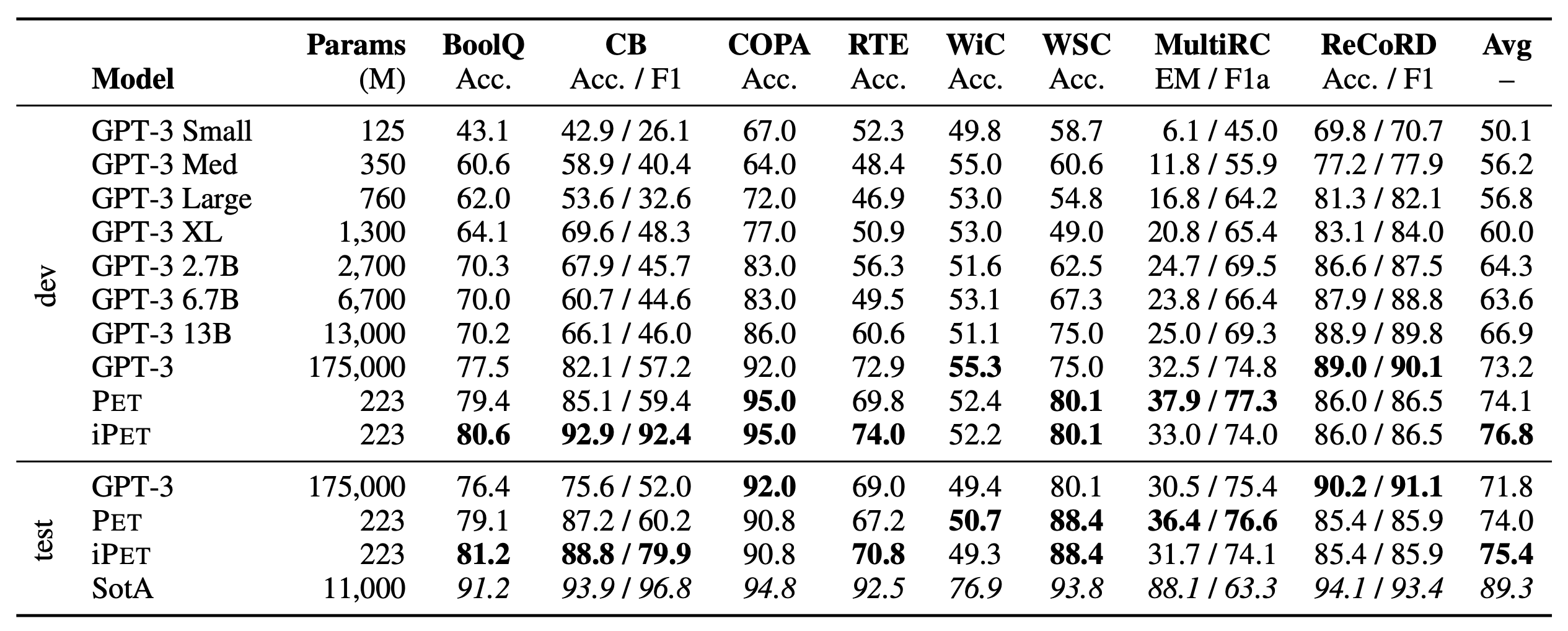
PET在SuperGLUE上的小样本学习的结果
小结:某种意义上来说,模版属于语言模型的“探针”,我们可以通过模版来抽取语言模型的特定知识,从而做到不错的零样本效果,而配合少量标注样本,可以进一步提升效果。

若有收获,就点个赞吧
0 人点赞
