本文参考和总结自苏剑林. (Sep. 18, 2019). 《从语言模型到Seq2Seq:Transformer如戏,全靠Mask 》[Blog post]. Retrieved from https://kexue.fm/archives/6933。目标是理清Attention矩阵的Mask方式与各种预训练方案的关系;
背景:语言模型的结构
图中方块代表序列中的元素,线代表attention。深色的线代表全可见attention,浅色的线代表因果掩码(causal masking),即当前时刻只能看见之前的元素,不能看见未来的元素。

- 左图:完全可见矩阵,模型输出可以看见任意时刻的输入。Transformers 的 Encoder,BERT 用的就是这种掩码。
- 中图:因果掩码矩阵,模型输出只能看见当前时刻之前的输入(黑色部分),这样可以防止未来的输入干预当前输出的结果。Transformers 的 Decoder,GPT 等单向语言模型使用的就是这种掩码。
- 右图:带有前缀的因果掩码矩阵,前缀部分和完全可见矩阵一样,输出能够看见前缀任意时刻的输入,超过前缀范围使用因果掩码。UniLM采用这种掩码。
单向语言模型#
语言模型可以说是一个无条件的文本生成模型,即是给定序列,预测下一个token出现的概率分布。我们一般说的“语言模型”,就是指单向的(更狭义的只是指正向的)语言模型。单向语言模型相当于把训练语料通过下述条件概率分布的方式“记住”了: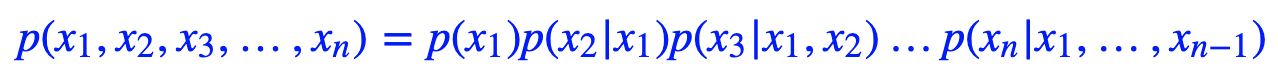
语言模型的关键点是要防止看到“未来信息”。如上式,预测x1的时候,是没有任何外部输入的;而预测x2的时候,只能输入x1,预测x3的时候,只能输入x1,x2;依此类推。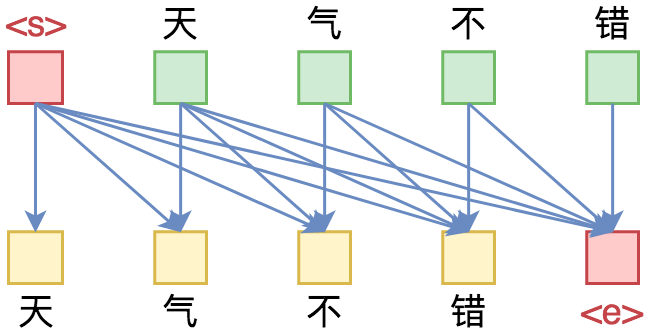
单向语言模型图示。每预测一个token,只依赖于前面的token。
要想使用 Transformer做语言模型,那需要一个下三角矩阵形式的Attention矩阵: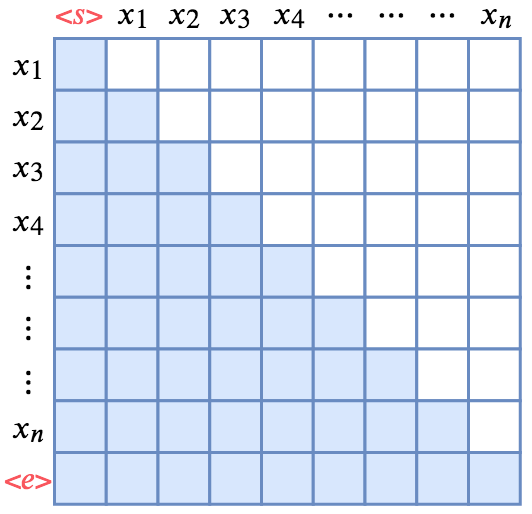
单向(正向)语言模型的Mask方式
行代表着输出,列代表着输入;白色方格代表0
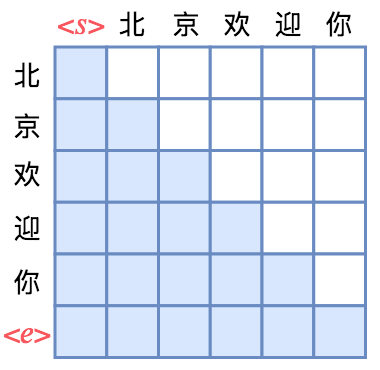
如图所示,Attention矩阵的每一行事实上代表着输出,而每一列代表着输入,而Attention矩阵就表示输出和输入的关联。假定白色方格都代表0,那么第1行表示“北”只能跟起始标记相关了,而第2行就表示“京”只能跟起始标记和“北”相关了,依此类推。所以,只需要在Transformer的Attention矩阵中引入下三角形形式的Mask,并将输入输出错开一位训练,就可以实现单向语言模型了。(至于Mask的实现方式,可以参考《“让Keras更酷一些!”:层中层与mask》的Mask一节。)
乱序语言模型#
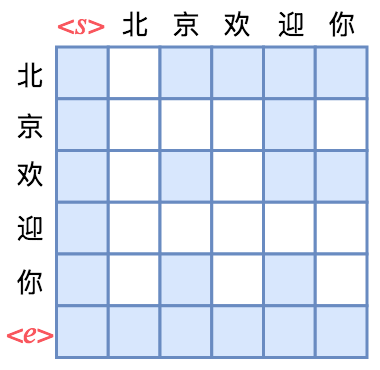
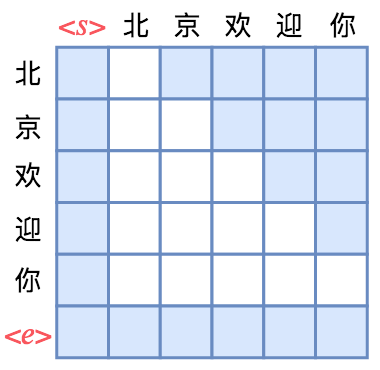
乱序语言模型是XLNet提出来的概念,它主要用于XLNet的预训练上。那怎么做到这一点呢?还是以“北京欢迎你”的生成为例,假设随机的一种生成顺序为“ → 迎 → 京 → 你 → 欢 → 北 →
 正向语言模型的Mask |
 乱序语言模型的Mask |
 倒序语言模型的Mask |
|---|---|---|
跟前面的单向语言模型类似,第4行只有一个蓝色格,表示“迎”只能跟起始标记相关,而第2行有两个蓝色格,表示“京”只能跟起始标记和“迎”相关,依此类推。直观来看,这就像是把单向语言模型的下三角形式的Mask“打乱”了。
也就是说,实现某种特定顺序的语言模型,就相当于将原来的下三角形式的Mask以某种方式打乱。正因为Attention提供了这样的一个 的Attention矩阵,我们才有足够多的自由度去以不同的方式去Mask这个矩阵,从而实现多样化的效果。
的Attention矩阵,我们才有足够多的自由度去以不同的方式去Mask这个矩阵,从而实现多样化的效果。
Seq2Seq#
将Bert与Seq2Seq结合的比较知名的工作有两个:MASS和UNILM,两者都是微软的工作,两者还都在同一个月发的~其中MASS还是普通的Seq2Seq架构,分别用Bert类似的Transformer模型来做encoder和decoder,它的主要贡献就是提供了一种Seq2Seq思想的预训练方案;真正有意思的是UNILM,它提供了一种很优雅的方式,能够**让我们直接用单个Bert模型就可以做Seq2Seq任务,而不用区分encoder和decoder**。而实现这一点几乎不费吹灰之力——只需要一个特别的Mask。
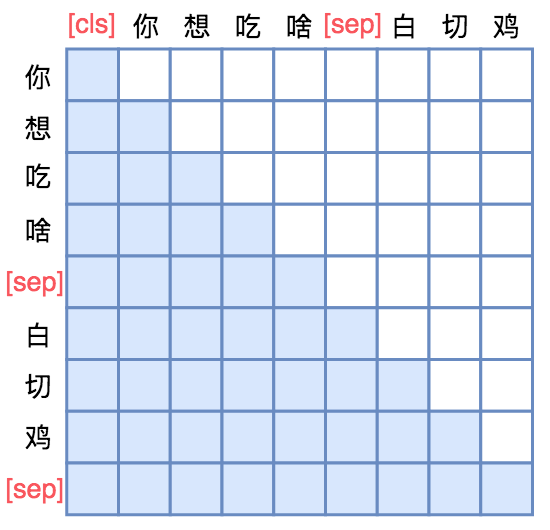
UNILM直接将Seq2Seq当成句子补全来做。假如输入是“你想吃啥”,目标句子是“白切鸡”,那UNILM将这两个句子拼成一个:[CLS] 你 想 吃 啥 [SEP] 白 切 鸡 [SEP]。经过这样转化之后,最简单的方案就是训练一个语言模型,然后输入“[CLS] 你 想 吃 啥 [SEP]”来逐字预测“白 切 鸡”,直到出现“[SEP]”为止,即如下面的左图的Mask矩阵:
 用单向语言模型的方式做Seq2Seq 行代表着输出,列代表着输入;白色方格代表0,蓝色方格代表 1 |
 设计更适合的Mask做Seq2Seq 白色方格代表0,蓝色方格代表 1 |
|---|---|
不过左图只是最朴素的方案,它把“你想吃啥”也加入了预测范围了(导致它这部分的Attention是单向的,即对应部分的Mask矩阵是下三角),事实上这是不必要的,属于额外的约束。真正要预测的只是“白切鸡”这部分,所以我们可以把“你想吃啥”这部分的Mask去掉,得到上面的右图的Mask。
这样一来,输入部分的Attention是双向的,输出部分的Attention是单向,满足Seq2Seq的要求,而且没有额外约束。这便是UNILM里边提供的用单个Bert模型就可以完成Seq2Seq任务的思路,只要添加上述右边形状的Mask,而不需要修改模型架构,并且还可以直接沿用Bert的 Masked Language Model 预训练权重,收敛更快。
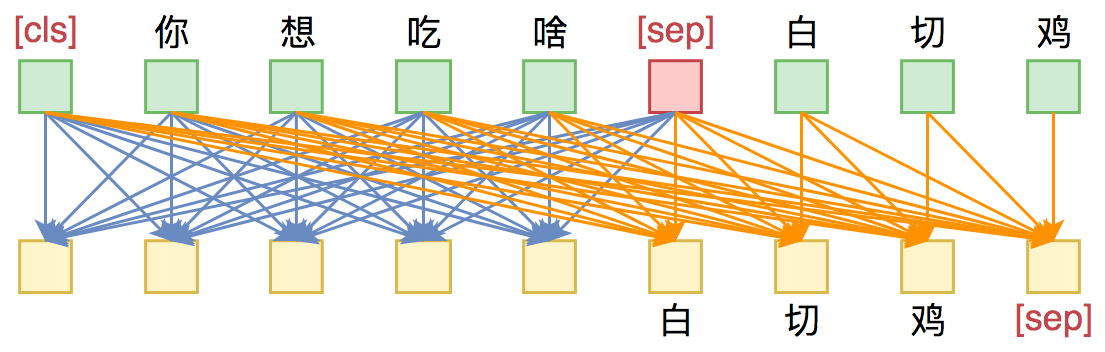
UNILM做Seq2Seq模型图示。输入部分内部可做双向Attention,输出部分只做单向Attention。
利用UNILM的思路做Seq2Seq示例
- THUCNews的原始数据集
- 以字为基本单位,并且引入了4个额外标记,分别代表mask、unk、start、end
- 以 UniLM 为基础架构,训练一个Seq2Seq模型
- 代码实现:task_seq2seq_autotitle.py

若有收获,就点个赞吧
0 人点赞
