目前,龙小湖智能客服偏向于【基于检索式的FAQ问答型对话系统】。整个流程主要是 QQ 匹配,也即使用用户的问题和问答库里的问题去匹配。涉及到传统文本匹配方法(信息检索中的BM25, 向量空间模型VSM)、深度语义匹配方法(孪生网络、交互网络 )、度量学习方法(margin-based softmax、对比学习)等。
FAQ(Frequently Asked Questions)指常见问题的解答,具体形式是问题和与问题相关的答案组成的问答对(QA pair),通常这类 QA pair 数量较多。
基本流程
当用户输入一个问题 query,首先通过检索(倒排索引+TFIDF/BM25)作q-q匹配来召回若干相关的 candidates;接着,使用考虑语义的深度文本匹配方法对召回的这些 candidates 进行 matching/reranking,从而挑选出和query最相似的问题(Q),然后将该Q所对应的回答(A)返回给客户,完成知识问答工作。
- 预处理模块:分词、实体识别、领域识别、句法分析、关键词抽取、同义词扩展、纠错等基本文本处理流程;
- 检索召回模块:通过同义词召回、传统BM25召回和语义召回,从 FAQ 库召回与 Query 相关的问题;
- 排序模块:通过 LTR 模型或者文本相似度模型对召回的问题进行排序,选出 Top k 返回;
- 最后是业务规则、流量干预等进行顺序调整;

对话框架技术细节
在智能客服的框架中,最重要的模块是 FAQ 问答库的构建、语义召回、相似度模型和模型更新,它们性能的好坏对用户的使用体验有很大影响。
问答知识库构建
QABot是基于问答知识库来实现的,问答知识库是由一系列的问题-答案对组成的数据集。我们将问题划分为标准问题和扩展问题,标准问题是对同一个语义的所有扩展问的抽象。如:”如何发布帖子”,”怎么样发布帖子”,”个人中心里是怎么发布帖子的呢?”等这些问题都表达的是同一个意思,这样我们就可以将”如何发布帖子”抽象为一个标准问,其他相似问题作为该问题的扩展问。有了问答知识库,用户来询问时就是一个问题匹配的过程了,只需要将用户输入的问题和知识库中的问题做匹配,得到意思最相近的那条问题,然后将对应的答案返回给用户,这就完成了一次问答操作。问答知识库的构建非常关键,这里会首先对客服团队历史积累的问题数据进行抽象,形成标准问题,然后结合算法和标注对标准问题做扩展,形成初始问答知识库,在系统上线后,对新产生的数据又会进行挖掘,不断扩充知识库。
由于我们的问答引擎是基于KB来实现的,所以知识库的构建就显得非常重要,那该如何构建知识库呢?
- 首先我们会对场景历史积累的问题进行整理,经过抽象、标注形成标准问和扩展问,同时对于扩展问较少的问题使用相关技术做问题扩展,形成初始问答知识库。
- 然后当系统上线以后,我们会不断的对场景进行问题挖掘,再经过标注整理来不断的扩充知识库。
- 半自动化挖掘新问题扩展知识库。从线上问答日志中挖掘用户提问,TextCNN新问题分类模型筛选出新标准问题,经过提前训练好的Word2Vec获取句向量,并用Kmeans聚类的方法对新标准问题进行聚类,将语义相同新标准问题聚为一类。最后将聚类结果交给编辑团队去审核,最终由编辑团队归纳总结出新的标准问题和对应的扩展问题并入知识库。
槽位提取Slot
在对话机器人中,经常需要槽位识别来提取用户回答中的关键信息,以便用于控制对话逻辑跳转和标识对话关键词等。我们通过命名实体识别(Named Entity Recognition,NER)技术来提取对话中的实体词(关键词),即对话机器人中的槽位词。
在公司业务场景下,NER任务具有以下特点:
- 领域相关性强:搜索中的实体识别与业务供给高度相关,除通用语义外需加入业务相关知识辅助判断,比如“剪了个头发”,通用理解是泛化描述实体,在搜索中却是个商家实体。
- 性能要求高:从用户发起搜索到最终结果呈现给用户时间很短,NER作为DQU的基础模块,需要在毫秒级的时间内完成。近期,很多基于深度网络的研究与实践显著提高了NER的效果,但这些模型往往计算量较大、预测耗时长,如何优化模型性能,使之能满足NER对计算时间的要求,也是NER实践中的一大挑战。
在公司业务场景下,我们需要识别以下类别的槽位:
- 客服对话中的槽位提取(Slot Filling)
航道、城市、城市类型、单据号、职级序列、婚姻状况、订票类型、请假类型、分公司、*姓名 - 冠寓录音文本的成分分析
all:联系方式(主要是电话号码)、*看房时间、预算、姓氏 - 辅助Askdata Query中的特定实体(标签)识别/抽取
ALM产品名和角色名抽取 - 坐席知识库库名提槽
即产品名(完全匹配+模糊匹配) - 未使用
C1客户描摹分析、人事员工评价、地产项目名
要解决的问题:
- 复杂场景下,能高效结合多种匹配方法,获取最优槽位组合;
- 针对嵌套实体下的槽位冗余情况,能高效合并和输出有效槽位结果;
槽位提取的方法选择
1、针对智能客服的复杂场景,我们会预定义所有槽位及其对应的提取方法。如果槽位结果是有限集,当满足领域相关性强和性能要求高两个条件时,优先选取精确匹配方法;而当性能要求可放宽且需要近似地(而不是精确地)查找与模式匹配的字符串时,选取模糊匹配方法;如果所需槽位是通用的、无固定模式,如姓名、地点等,则可以通过序列标注模型来解决。
2、精确匹配,也叫词典匹配,主要是解决用户头部查询。关键词快速匹配FlashText算法介绍:a.根据词表中预存的一系列关键词,建立前缀树字典,利用字符串的公共前缀最大限度地减少不必要的字符串比较,提高查询效率;b.对输入查询中的字符进行逐个遍历,基于Aho-Corasick算法在构建好的前缀树上实现多模串匹配;c.当匹配到EOT特殊字符时,意味着匹配成功,将匹配到的字符序列所对应的标准关键词进行输出。值得注意的是,精确匹配得到的结果可能会存在区间重叠的情况,如“从上海南出发,目的地海南”提取城市时,“上海南”中的“上海”与“海南”存在交集。通过构建区间树来判断槽位区间是否重叠,当发现区间有重叠时,继续往后匹配,最终匹配出正确结果“到海南”中的城市“海南”。相比穷举法,区间树可以降低区间重叠判断的复杂度。
3、模糊匹配采用了动态规划策略,具体过程为:①寻找句子中不包含“垃圾”元素的最长连续匹配子串。所谓“垃圾”元素是指其在某种意义上没有价值,例如空白行或空白符;②接着查找由一组非连续匹配子串组成的新字符串,非连续子串之间的最大间隔设置为1;③计算候选序列和用户输入的字符余弦相似度,取其中超过阈值的最大者作为模糊匹配的结果。
4、当同时使用精确匹配、模糊匹配、序列标注模型三种提取方法时,仍存在实体重叠和冗余的情况。我们通过多叉树来解决嵌套实体的问题,输出所有槽位提取结果的排列组合。多叉树的构建原则如下:①构造一个ROOT 根节点,并将第一个槽位区间加入多叉树;②依次读取每个槽位结果区间,与所有的叶节点进行比较,若二者的区间存在交集,则叶节点的父节点新增一个子节点,保存当前槽位区间(拉宽);否则叶节点新增一个子节点,保存当前槽位区间(加深);③最后返回根节点到所有叶结点的遍历路径,每一条路径即代表了一个可能的槽位组合结果。

为什么需要实体词典匹配?
答:主要有以下四个原因:
- 搜索中用户查询的头部流量通常较短、表达形式简单,且集中在商户、品类、地址等三类实体搜索,实体词典匹配虽简单但处理这类查询准确率也可达到 90%以上。
- NER领域相关,通过挖掘业务数据资源获取业务实体词典,经过在线词典匹配后可保证识别结果是领域适配的。
- 新业务接入更加灵活,只需提供业务相关的实体词表就可完成新业务场景下的实体识别。
- NER下游使用方中有些对响应时间要求极高,词典匹配速度快,基本不存在性能问题。
有了实体词典匹配为什么还要模型预测?
答:有以下两方面的原因:
- 随着搜索体量的不断增大,中长尾搜索流量表述复杂,越来越多OOV(Out Of Vocabulary)问题开始出现,实体词典已经无法满足日益多样化的用户需求,模型预测具备泛化能力,可作为词典匹配的有效补充。
实体词典匹配无法解决歧义问题,比如“黄鹤楼美食”,“黄鹤楼”在实体词典中同时是武汉的景点、北京的商家、香烟产品,词典匹配不具备消歧能力,这三种类型都会输出,而模型预测则可结合上下文,不会输出“黄鹤楼”是香烟产品
PS:追问提槽的代码逻辑。通过槽位提取 API 实现追问判断!
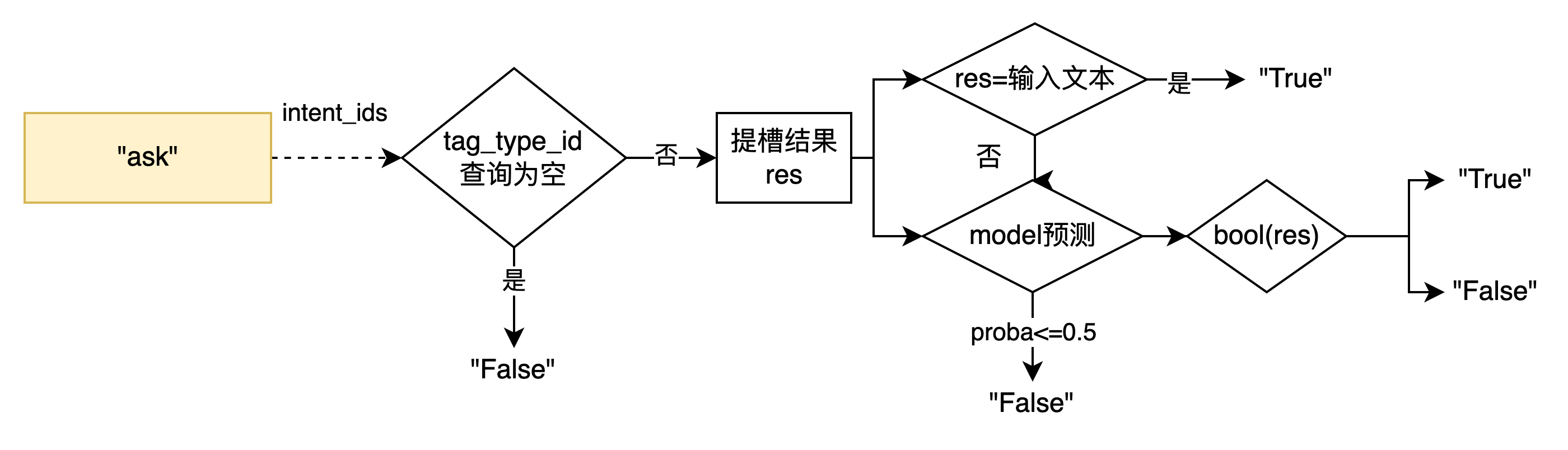
意图识别NLU
NLU1.0
一般作为多分类问题,需求是对给定query进行分类,找到最可能的主问题类别。
- 适用于业务场景少、语料充分、准召要求高的场景; - 优势:方差小(向量空间集中)、泛化能力强; - 缺点:偏差大(离目标远)、样本数少则效果不好,意图类别必须固定; - Cross Entropy Loss - 优化目标是提升分类效果; |
 |
|---|---|
NLU2.0
核心思路是以搜代分(检索+排序),整个流程主要是QQ 匹配,属于NLP中的问句匹配/相关性度量,目的是判断两个语句的语义是否等价。检索召回阶段使用用户的问题和问答库里的问题去匹配,通过传统检索方法(BM25,VSM)召回top n候选集。此阶段注重召回算法的效率、召回率、覆盖率;目标是缩减问题规模,降低排序阶段的复杂度。排序阶段负责对召回数据进行打分和重排序,每个问题会被打上一个分值,最终挑选出top1,将这个问题对应的答案返回给用户,这就完成了一次对话流程。在实际应用中,我们还会设置阈值来保证回答的准确性,若最终每个问题的得分低于阈值,会将头部的几个问题以列表的形式返回给用户,最终用户可以选择他想问的问题,进而得到具体的答案。。此阶段注重排序算法的精确率;目标:采用深度语义匹配方法或者 Learning to Rank 相关策略进行排序最优解求解。
- 优势:偏差小(离目标近)、样本数少时效果好(准确率)、意图拓展性强(可控性); - 缺点:方差大(向量空间分散)、易受噪声样本影响 - Loss:Hinge Loss、Triple Loss、AMSoftMax等 - 优化目标:加大正例和负例在语义空间的区分度 |
|---|
 |
语义检索架构 (NLU2.0)的排序阶段包括离线和在线两部分:
- 离线负责数据预处理、数据集构建、模型构建、模型训练、物料/索引问的向量预测、索引构建入库的核心操作,当然一些服务的基本配件,比如一键打包/部署的脚本、定时任务、日志、监控、校验等任务也会有。
- 训练一个语义相似度表征模型。语义编码模型是多分类方法的主要训练目标,目的是能够将所有的问句进行语义空间的投射。我们基于预训练语言模型作为向量初始化层,通过对应的多类别标签和特定的损失函数,利用反向传播对语义编码模型进行优化调整。
- 用表征模型预测每一个知识库内标准问的语义向量。
- 将语义向量入库,即存入检索es库中
- 在线(来了一个query请求):
- 用上面训练的表征模型预测query的向量。
- 通过传统检索方法(BM25,VSM)召回top n候选集。
- 根据相似度完成对top n候选的粗排序。
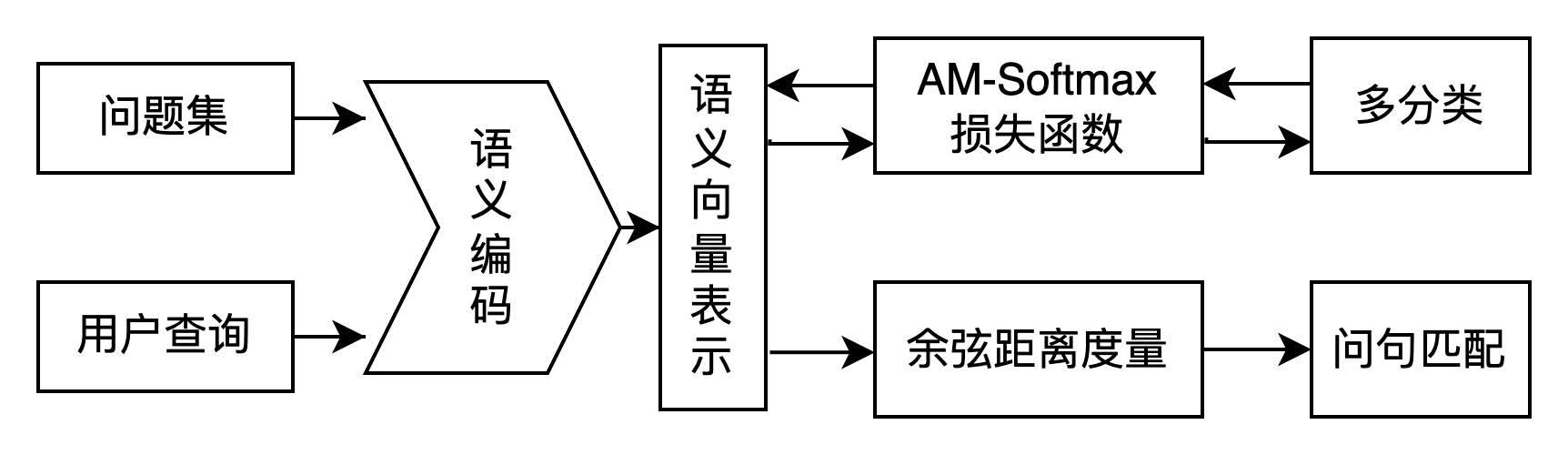
其中,语义相似度表征模型的选择最为重要,我们尝试了度量学习方法(margin-based softmax、对比学习)、表示型文本匹配模型(如 DSSM)、交互型文本匹配模型(如 MatchPyramid, ESIM, BIMPM 等)、Poly-encoders(解决双塔式交互不足以及交互式速度慢的问题)、SimNet(Paddle短文本语义匹配—SimNet)。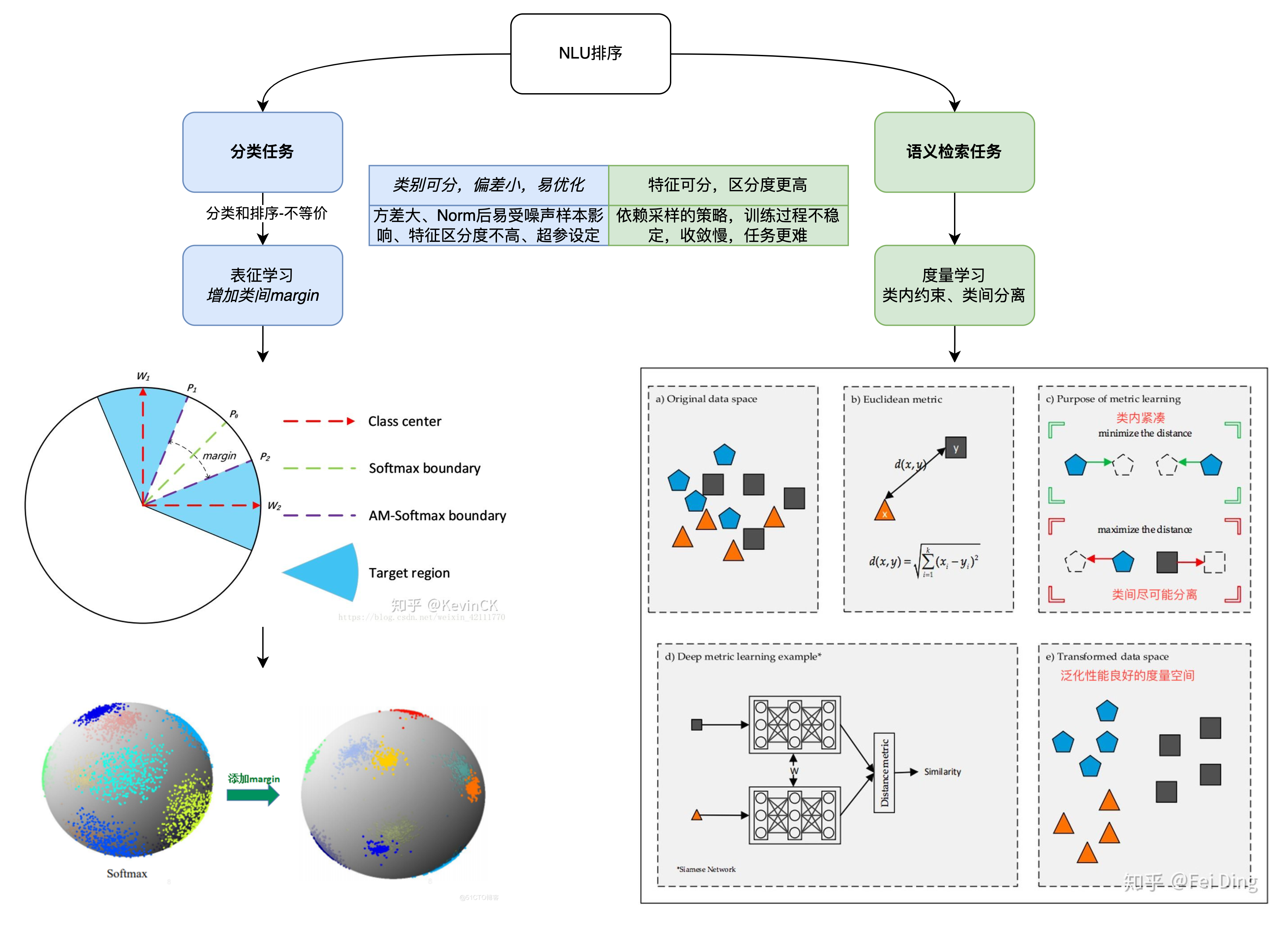
最终通过自有数据集实验发现,AM-softmax在平均 和性能平衡上取得最佳效果。
和性能平衡上取得最佳效果。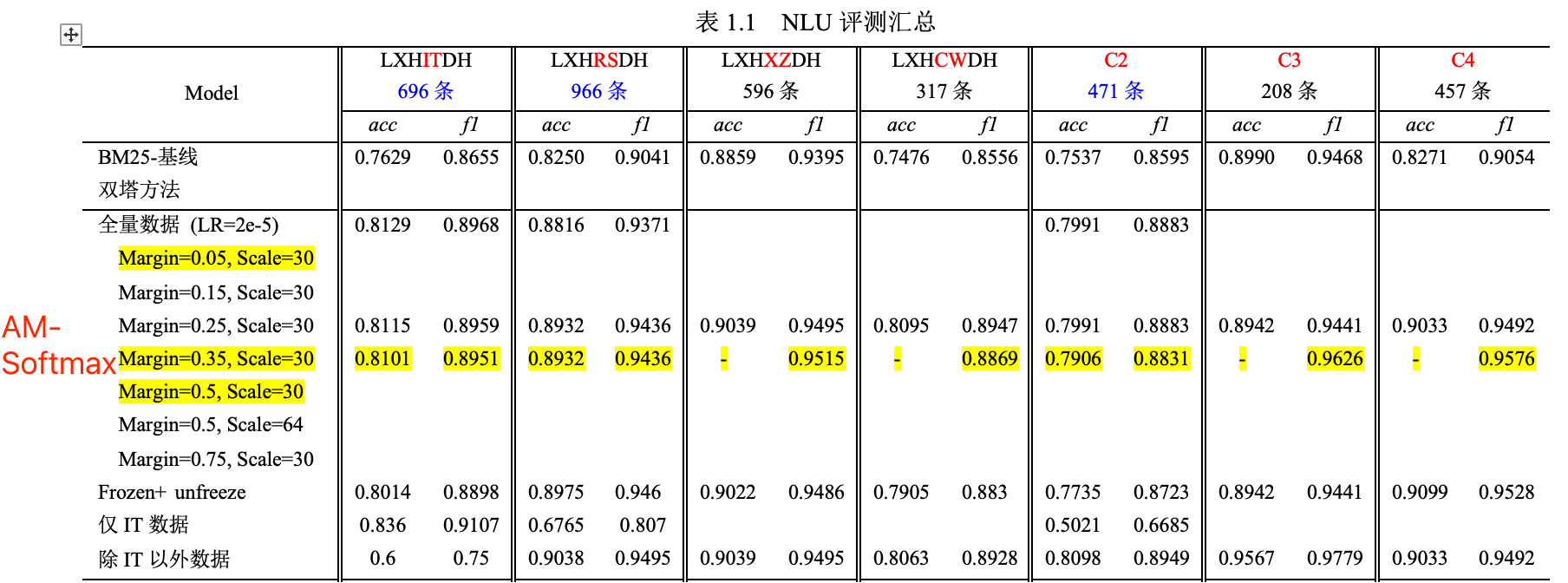
AM-Softmax方案简介
2021-11-26-度量学习之AMSoftmax理解 2021-11-09-度量学习之AM-Softmax Loss详解 科学空间:基于GRU和am-softmax的句子相似度模型 科学空间:从三角不等式到Margin Softmax
基础共识:像人脸识别或者句子相似度等场景,在预测阶段我们是拿特征去排序的,我们自然希望随便拿一个样本,就能够检索出所有同类样本,这就要求“类内差距小于类间差距”;但是,如果我们将其作为分类任务训练的话,则未必能达到这个目的,因为分类和语义匹配相关但不等价,也就是分类分对了,但是将编码特征用于匹配排序可能错误。分类任务的目标是“最靠近所属类的中心”,而排序的目标是“类内差距小于类间差距”。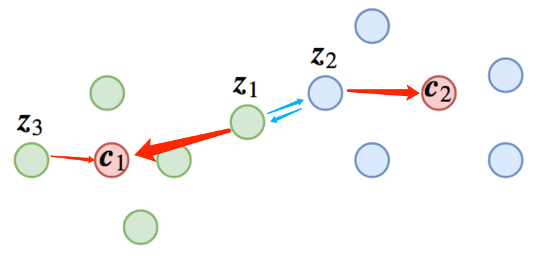
期望达成目标:为了能够让分类模型的特征可以用于排序,那么每个样本不仅仅要最靠近类中心,而且是距离加上 之后还要最靠近类中心(用分类模型做排序任务时margin的必要性)。即除了分类正确还必须将类间的间隔拉得更大,保证“类间距离大于类内距离”这一目标。
之后还要最靠近类中心(用分类模型做排序任务时margin的必要性)。即除了分类正确还必须将类间的间隔拉得更大,保证“类间距离大于类内距离”这一目标。
技术方案:采用Additive Margin Softmax (AM-Softmax) 训练一个多分类模型,最后仅保留其中的特征提取模型(编码器),用于对比排序。AM-Softmax 引入间隔的思想加强分类边界条件,实现类内差距小于类间差距的目标,使得语义空间中的向量可以通过距离度量实现对比排序,无需负采样的同时保证高时效性。具体来说,Softmax损失函数只着重于对不同类之间区分能力,而AM-Softmax在Softmax损失基础上引入了加性间隔,对相同类之间进行了约束(即每个样本不仅仅要最靠近类中心,而且是距离加上 之后还要最靠近类中心);同时增加特征/权重归一化,使得内积变成了余弦计算,将匹配分值的范围限制在;增加伸缩因子(也称温度系数)用于控制余弦分数的幅度,从而保证对目标函数的近似效果和泛化性能。AM-Softmax Loss的公式如下:

其中,代表
的夹角。在 AM-Softmax 原论文中,所使用的是
。
我们对AM-Softmax进行推导,可得:
可见,加入 margin 的 Softmax,本质是希望【目标相似度】比【非自标相似度】大一个margin。(SVM?) 
NLU现阶段问题&解决方案总结

- 字面相似case,但不同义(一两个字差别,False Positive)
问题1属于语义焦点匹配错误。原因分析如下:一是模型偏向注重整体语义,对实体词的词义区分度不高;而是由于句子的核心实体词识别错误导致模型误判,因此可以引入一些额外特征强化模型对核心词的学习。参考小米的做法:加入关键词特征,通过PLM对关键词进行表征,并与原句子的特征进行级联以计算相似度。 解决方案:1、加入实体对齐规则,在排序前对query和question进行实体对齐,filter不匹配的候选;2、多任务学习,同时or轮流进行文本分类和文本匹配,结合二者的优势解决长尾问题;3、LTR,浅层语义特征+深层语义+实体词特征等。此外,部分问题可以选择干预等规则的方式解决。
 |
 |
|---|---|
同义case,但表述不同(False Negative)
问题2属于鲁棒性/泛化性较差。原因分析如下:一是相似问存在重叠、错误、遗漏;二是 query 多口语化表达,语义不明确;三是模型高方差,易受语料中的噪音样本影响,over fitting典型表现。 解决方案:1、另外标注一些回流数据(预测概率在0.3~0.8之间),通过加入归纳层来改进泛化性(龙小湖之NLU归纳层介绍);2、数据增强,引入随机噪声来提升鲁棒性,但会对句子结构和语义造成影响,可能会产生标签错误的句子(如EDA、回译等,不建议),可以尝试R-drop、SimCSE等方式;3、同义词策略:对Query中的专有词进行同义词替换,提升鲁棒性;4、句式泛化策略(占位符+句式模板),并作为新的相似问加入训练;5、对抗训练:在某个输⼊上有意的加⼊⾜够小的扰动,能够使⽹络预测
错误且预测概率较高的样本;6、防止模型过拟合的一些列 trick表达冗余。不同的term对于搜索的意义不同,在意图识别时应该根据核心词来确认,示例如下: | 桃子味的牙膏 | 这里的桃子是修饰牙膏的,核心词为“牙膏”,核心词应该就有更高的查询分值 | | —- | —- | | 孙子兵法智慧的现代意义 | “智慧”是一个无关紧要的词,应该降低召回“智慧”的结果 |
问题 3 其实跟问题1语义焦点匹配错误差不多… 解决方案:可以提前对query做标点符号处理、同义词转化、词性分析POS,命名实体识别NER,计算词语权重Term Weight等方法,过滤语气词、过渡词、修饰词、停用词(query改写),将会帮助检索。
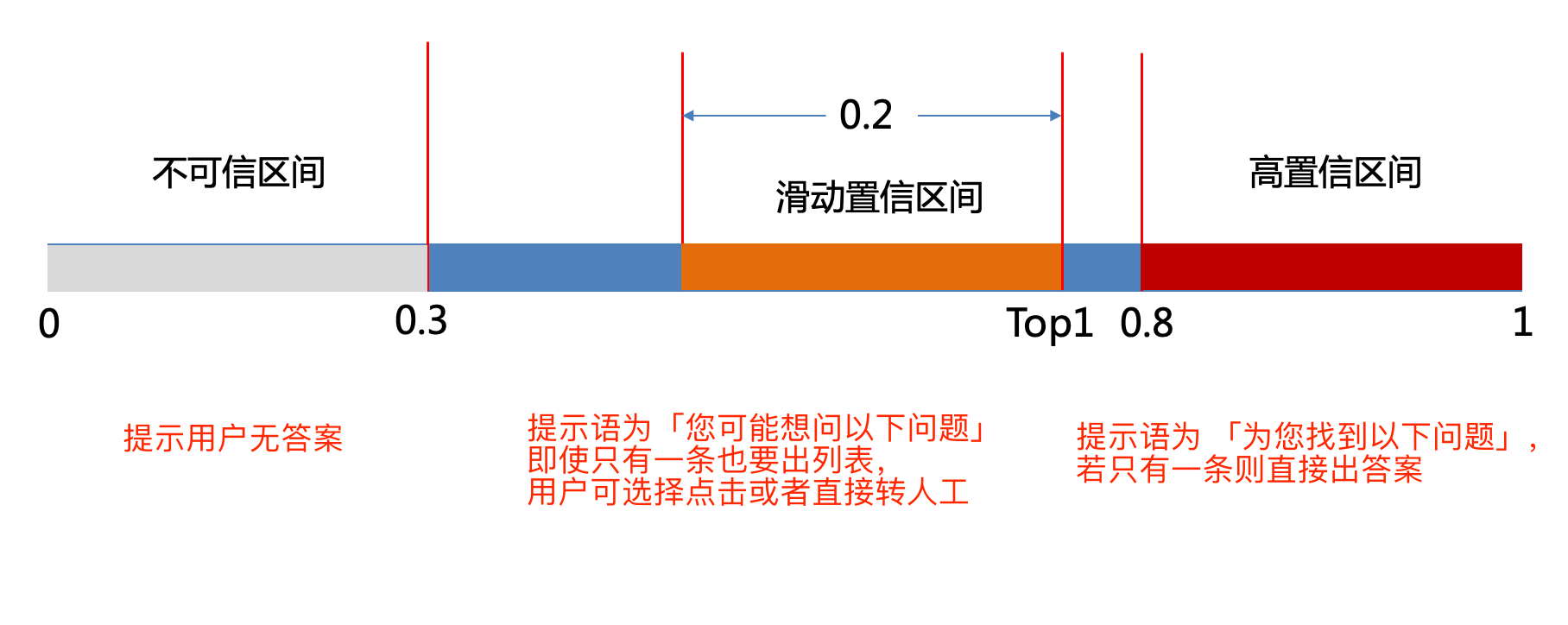
- 阈值设定问题
若置信度高于0.8,则提示语为 「为您找到以下问题」,若只有一条则直接出答案 若置信度低于0.8,但高于0.3,则提示语为「您可能想问以下问题」,即使只有一条也要出列表,用户可选择点击或者直接转人工 若置信度均低于0.3,则提示用户无答案
- 短语 query 效果不理想
针对长度小于等于 4 的 query,加入短语策略(具体技术细节参考《2022-05-12-长短句语义匹配》)
- 分词采用 paddle,并去除停用词
- 每次同时计算主问题和max相似问的$ctr_cqr_with_tfidf $,取大者作为
- 得分归一化采用 sigmoid
- 增加字符匹配相似度,缓解分词导致的零匹配问题
- 阈值设为 0.7

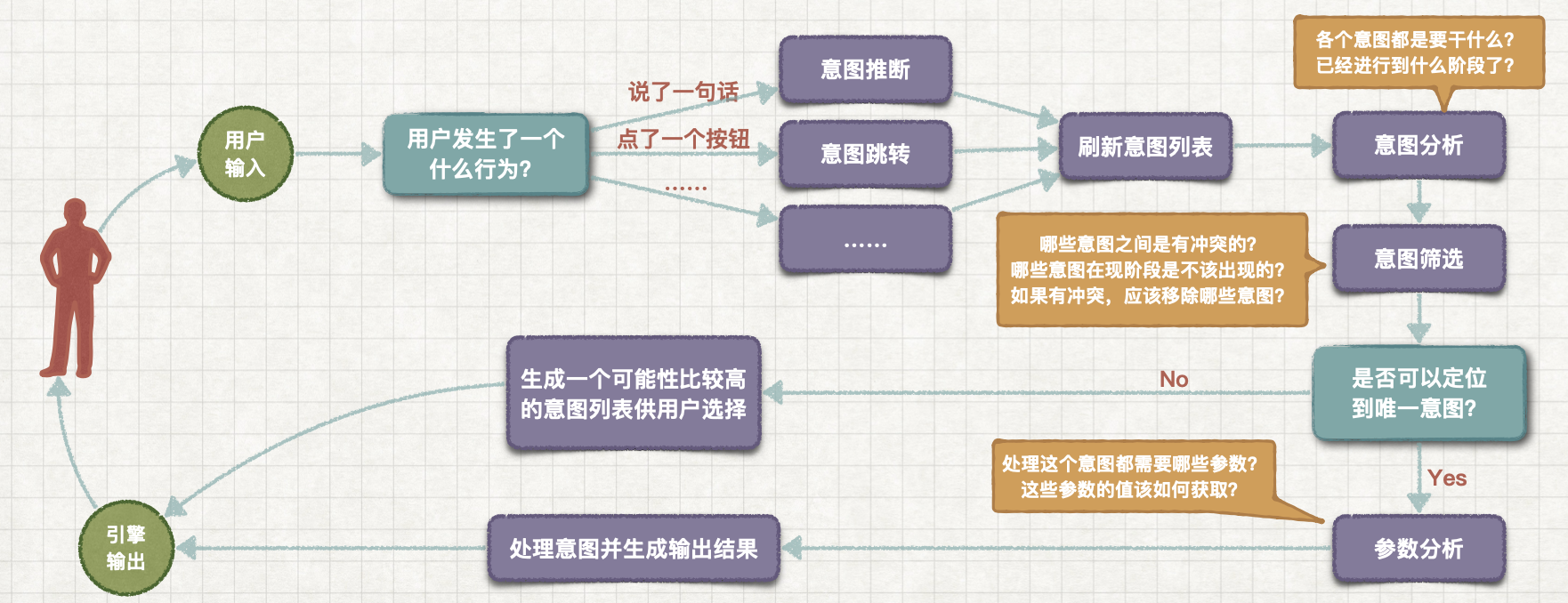
对话管理 DM
DM的要点回顾:
- DM 是实现多轮对话的重要组件;
- DM 包含两个模块:对话状态追踪Dialogue State Tracking和对话策略学习Dialogue Policy Learning。
- DST模块功能:根据 ①当前轮的系统状态 state(一般是指new intent和slot);② 对话历史(一般是指上一轮的state和action);以及 ③ 本轮对话过程中的用户动作 action,来记录和更新 state 表。
- DPL 根据 DST 中的对话状态 state,产生系统行为 action,并完成这个action,把结果传给NLG模块,生成最终的回复。

评测指标
- 召回率(R):回复数/总数
- 精确率(P):回复正确数/回复数
- F1:(2RP)/(R+P)
- 直推率:只推一条且正确的数量/标注正确答案里只有一条的数量
参考
心法利器[26] | 以搜代分:文本多分类新思路
心法利器[16] | 向量表征和向量召回
心法利器[20] | NLU落地场景-智能对话交互
填槽与多轮对话 | AI产品经理需要了解的AI技术概念
槽填充和意图识别任务相关论文发展脉络

若有收获,就点个赞吧
0 人点赞
