BLEU
BLEU,全称为Bilingual Evaluation Understudy(双语评估替换),是一种对生成语句进行评估的指标,用于比较候选文本翻译与参考翻译的 n-gram 重合程度
BLEU分数值范围是[0.0, 1.0]:如果两个句子完美匹配(perfect match),则BLEU取值为1.0;如果两个句子完美不匹配(perfect mismatch),,则BLEU取值为0.0。
上图的公式变量解析:
 :一般 n-gram 种的 N 设置为 4;
:一般 n-gram 种的 N 设置为 4; :n-gram的精确率.
:n-gram的精确率.- 1-gram精确率表示模型摘要忠于人工摘要的程度, 2-gram, 3-gram等等表示模型摘要的语义流畅程度.
 :n-gram的权重, 一般设置为均匀权重, 即对于任意n, 都有Wn = 1/n.
:n-gram的权重, 一般设置为均匀权重, 即对于任意n, 都有Wn = 1/n. :惩罚因子, 如果模型摘要的长度小于最短的参考摘要, 则BP < 1.
:惩罚因子, 如果模型摘要的长度小于最短的参考摘要, 则BP < 1.


ROUGE
类似于 BLEU,是基于 n-gram 覆盖的算法,不同之处在于:
- 没有简洁惩罚
- 基于召回率 recall,BLEU 是基于准确率的
- 可以说,准确率对于机器翻译来说是更重要的 (通过添加简洁惩罚来修正翻译过短),召回率对于摘要来说是更重要的 (假设你有一个最大长度限制),因为需要抓住重要的信息
- 但是,通常使用 F1 (结合了准确率和召回率)
- BLEU 是一个单一的数字,它是
 的精度的组合
的精度的组合 每 n-gram 的 ROUGE 得分分别报告,常见有:
分母是统计在参考译文中 N-gram 的个数
- 分子是统计参考译文与机器译文共有的 N-gram 个数
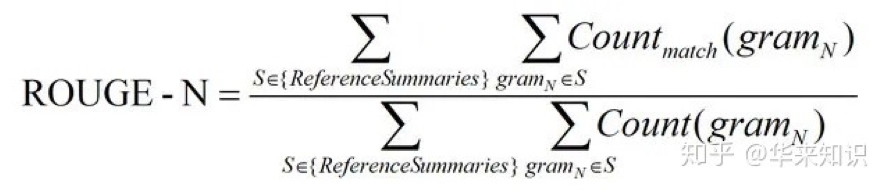

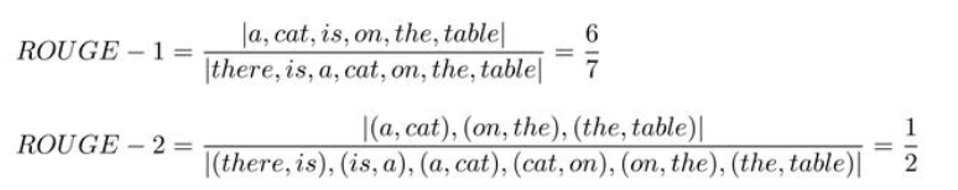
ROUGE-L
ROUGE-L采用的是评估模型输出和参考文本之间的最长公共子序列(LCS)。其计算公式如下:
上图的公式变量解析:
- ROUGE-L 中的 L 指最长公共子序列

 和
和 分别表示「参考文本和生成文本」的长度
分别表示「参考文本和生成文本」的长度- R 表示召回率,P 表示精确率,𝑭_𝑳𝑪𝑺 就是 ROUGE-L
- 𝜷 用于调节对精确率和召回率的关注度
ROUGE-S
ROUGE-S 允许n-gram出现跳词(skip)。即在model和reference进行匹配时,不要求gram之间必须是连续的,可以“跳过”几个单词。
上图的公式变量解析:
- 先统计共有2-gram的数量Skip-Bigram(2-gram不一定连续)
- 然后分别计算Skip-Bigram在参考文本和生成文本的比重 R / P
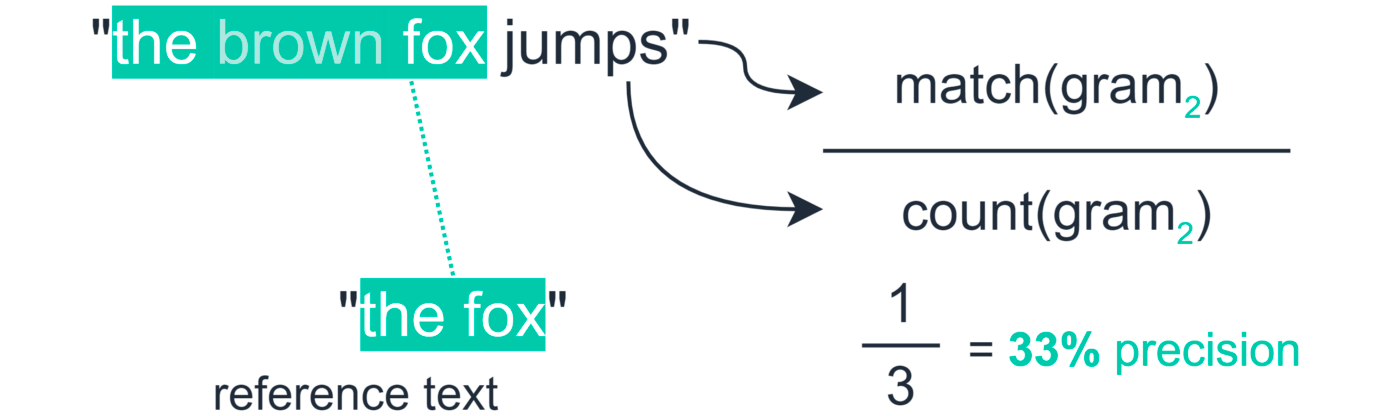

参考

若有收获,就点个赞吧
0 人点赞
