近年来,受人类选择性视觉注意力的启发,注意力机制(Attention Mechanism)被广泛应用于自然语言处理的各种任务中,它旨在从大量的信息中选择出对当前目标任务更为关键和有效的信息。
Attention机制可分为如下三类:软性注意力(Soft Attention)、硬性注意力(Hard Attention)和自注意力(Self Attention)。软性注意力是对所有的数据进行关注,计算出相应的注意力权值,且不设置任何筛选条件。硬性注意力会在生成注意力权重后,筛选掉一部分不符合条件的注意力,即不再注意这些不符合条件的部分。自注意力是指句子内部元素之间发生的相互关注的机制。它可以“动态”地生成任意两个单词间不同的连接权重,大大缩短词之间的距离,更易于捕获序列之间的长距离依赖关系。
Attention机制的具体计算过程可以抽象为三个阶段,如图2.6所示。

- 根据查询Query和Key计算两者的相似性或者相关性;常见的相似度计算方法包括:向量点积(Dot)、拼接(Concat)、双线性操作(Bilinear)以及多层感知机(MLP),具体的计算公式如下所示:
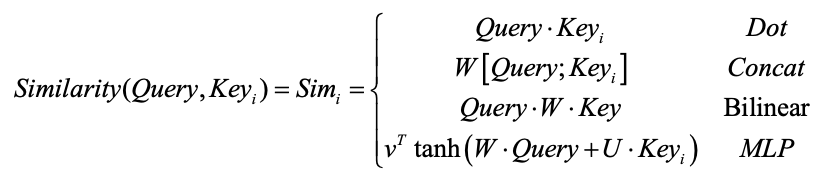
其中, 均是可训练的参数。
均是可训练的参数。
- 对(1)中计算的原始分值进行归一化处理,通过softmax函数将其整理成所有元素权重之和为1的概率分布,获得权重系数。计算公式如下:
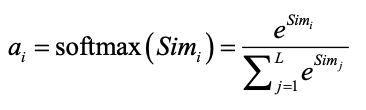
- 根据权重系数对Value进行加权求和:
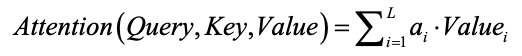
其中, 是输入序列长度。在大多任务中,Key和Value通常由同一个对象表示。
是输入序列长度。在大多任务中,Key和Value通常由同一个对象表示。

若有收获,就点个赞吧
0 人点赞
