转载自 解读《Few-Shot Text Classification with Induction Network》
代码:
Induction-Network Pytorch实现
Induction-Network-on-FewRel TF实现
Induction Network是阿里达摩院在EMNLP2019发表的工作,主要是用来做few-shot对话场景中的意图识别。训练过程如下,简单来讲就是从训练集中,每一个episode的时候,都随机选择C个类(训练集中的类别个数大于C),然后每一个类别都同样随机选择K个样本,这样每一个episode中的数据样本个数便是C * K个,这CK个样本组成support set S,此外,再从剩余的样本中随机选择n个样本作为query set Q,每一个episode都在这样选择出来的S和Q上进行训练,重复迭代 n 次,直至所有的 step 都走完了。我们将该策略称为基于episode的元训练,并且细节在算法1中展示。使用episodes使训练过程更加忠实于测试环境,从而改善了泛化。
归纳网络,如下图所示,主要由三个模块组成:编码器模块,归纳模块和关系模块。 编码器模块采用LSTM+self-attention;归纳模块利用了Capusule Network的动态路由算法来构建归纳能力,将每一个类别中的样本表征转化凝练成为类表示;关系模块采用 dense+sigmoid计算query 和类表示的相关性。
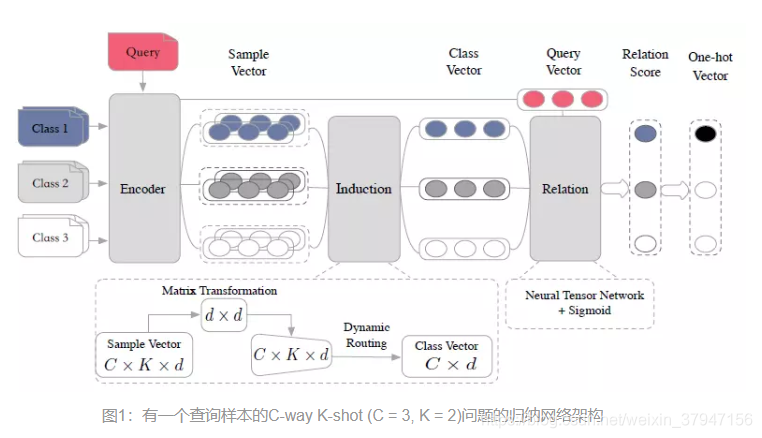
核心是归纳模块,利用了Capusule Network的动态路由概念,将每一个类别中的样本表征,最后转化凝练成为class-level的表征,可以用数学语言表达如下: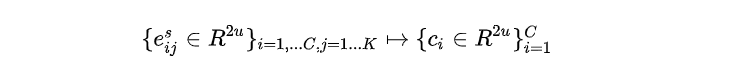
具体来说,分为如下几个步骤(细节可以参考2022-02-14-Capsule胶囊网络学习):
- 将样本表征进行一次transformation,这里为了能够支持不同大小的类表示 C(共享权重 W)
- 对转化之后的样本表征进行加权求和,得到初始的类别表征;
- 将类别表征 C 进行squash激活;
- 对耦合系数 b 进行更新;
整体算法如下:
关系模块
损失函数
损失函数选择 MSE 均方误差.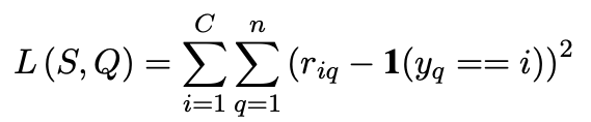
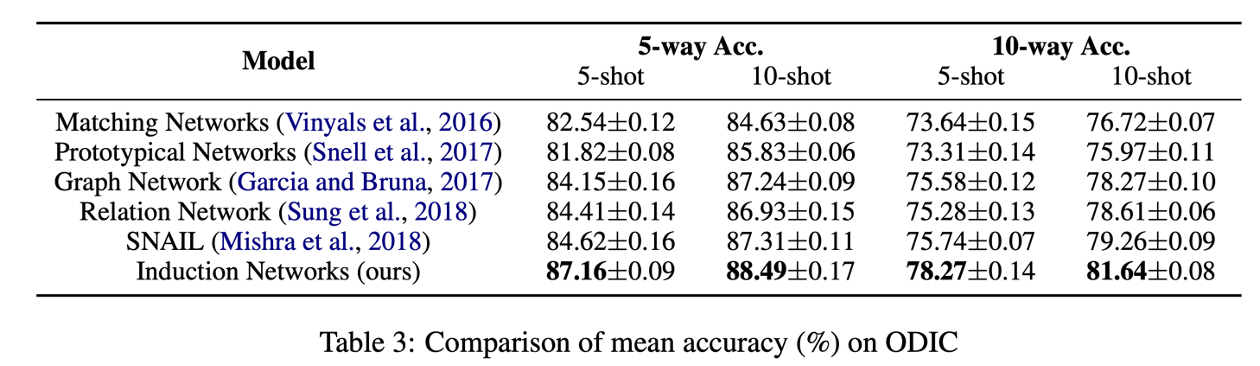
实验效果

结论
在本文中,介绍了归纳网络,一种针对小样本文本分类的新神经模型。 所提出的模型重建支持训练样本的分层表示,并动态地将样本表示引入类表示。 我们将动态路由算法与典型的元学习框架相结合,以模拟人类归纳能力。 结果表明,我们的模型优于其他最先进的小样本文本分类模型。
[
](https://github.com/wuzhiye7/Induction-Network-on-FewRel/blob/master/model/layer_module.py)

若有收获,就点个赞吧
0 人点赞
