layout: post # 使用的布局(不需要改)title: Python文本挖掘 # 标题
subtitle: 从非结构化文本中提取特定信息
date: 2019-09-10 # 时间
author: NSX # 作者
header-img: img/post-bg-2015.jpg #这篇文章标题背景图片
catalog: true # 是否归档
tags: #标签
- 技术
- 教程
- Python
用 Python 做文本分析
文本分析的本质是从给定文本中获取高质量、有用信息的自动化过程,其一般步骤为:数据采集、数据清洗、文本挖掘分析、可视化分析。
从非结构化文本中提取特定信息,如:实体、情感分析、关键词、主题、知识管理和发现(按主题对文档进行整理和分类以便于发现,然后向读者推荐与同一主题相关的其他文章,以提供个性化的内容推荐)、聚类…
在公司实际工作中,最好的大数据挖掘工程师一定是最熟悉和理解业务的人。对于大数据挖掘的学习心得,作者认为学习数据挖掘一定要结合实际业务背景、案例背景来学习,这样才是以解决问题为导向的学习方法。
文本分析的步骤
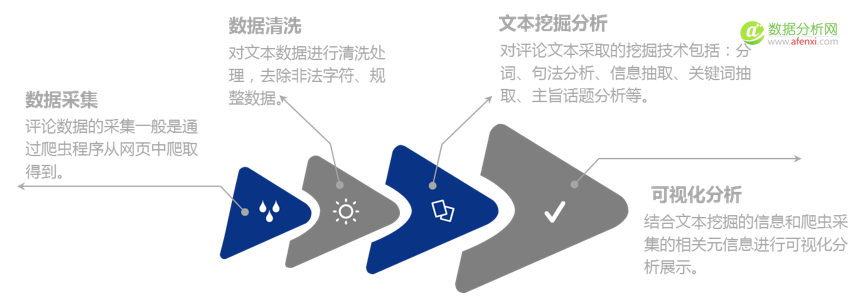
常见数据挖掘方法
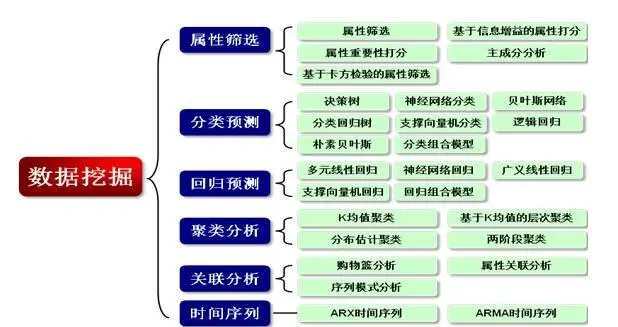
导包
import reimport osimport numpy as npimport codecsfrom time import timefrom tqdm import tqdmimport refrom wordCloud import doWordCloudimport jiebaimport jieba.posseg # 需要另外加载一个词性标注模块from jieba.analyse import *from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizerfrom sklearn.decomposition import LatentDirichletAllocationfrom sklearn.cluster import MiniBatchKMeans, SpectralCoclusteringfrom sklearn.metrics.cluster import v_measure_scoreimport stringfrom zhon.hanzi import punctuationimport gensimimport gensim.corpora as corporafrom snownlp import SnowNLPimport matplotlib.pyplot as pltfrom colorama import init, Fore, Back, Style
数据采集
读入我们的数据文件,显式指定编码类型,以免出现乱码错误
# 读取无结构文档for txt_file in tqdm(os.listdir(path)):if not os.path.isdir(txt_file):with codecs.open(path + "/" + txt_file, "r", "utf-8") as f:
数据预处理
数据分析/挖掘领域有一条金科玉律:“Garbage in, Garbage out”,做好数据预处理,对于取得理想的分析结果来说是至关重要的。本文的数据规整主要是对文本数据进行清洗,处理的条目如下:
- 去除文本噪声信息
处理编码问题 (codecs)
去掉停用词(没有实际意义的符号)
标点符号:, 。! /、*+-
特殊符号:❤❥웃유♋☮✌☏☢☠✔☑♚▲♪等
中文停用词 - 将文档分割成句子
- 中文分词 tokenize (jieba, 了避免歧义和切出符合预期效果的词汇,笔者采取的是精确(分词)模式)
- 词性标注。snownlp 是不二选择,还可以使用 pattern
- 计算Bigrams:如果两个词经常一起毗邻出现,那么这两个词可以结合成一个新词 (未使用)
stop_words = []with codecs.open(stopWord_path, "r", "utf-8") as f:for line in f:stop_words.append(line.strip("\n").strip())...with codecs.open(path + "/" + txt_file, "r", "utf-8") as f:file_content = f.read() # 以列表形式读取日志数据file_content = re.sub(r"^\s+$", "", file_content) # 去除换行符和空白字符# 去除字符串中的所有数字和字母file_content = re.sub("[0-9a-zA-Z_-]+", "", file_content)# 去除特殊中文标点file_content = re.sub(r"[%s]+" % punctuation, "", file_content)# 去除特殊英文标点file_content = re.sub(r"[%s]+" % string.punctuation, "", file_content)# if word >= u'\u4e00' and word <= u'\u9fa5':#判断是否是汉字# # 仅保留名词或特定POS (HMM)# s = SnowNLP(file_content)# pos_list = s.tags # [(u'这个', u'r'), (u'东西', u'n')]# word_list = [# w for w, pos in pos_list if pos in ["n", "a", "v", "d"]# ] # 'NN', 'ADJ', 'VB', 'ADV'# # 关键词 (TextRank算法)# kw_list = s.keywords(3)# # 文档摘要 (TextRank算法)# summmary_list = s.summary(3)# jieba分词word_list = jieba.cut(file_content)# 去除停用词word_list = [w for w in word_list if w not in stop_words]segments.append(" ".join(word_list))
单词之间都已经被空格区分开了。下面我们需要做一项重要工作,叫做文本的向量化。
不要被这个名称吓跑。它的意思其实很简单。因为计算机不但不认识中文,甚至连英文也不认识,它只认得数字。我们需要做的,是把文章中的关键词转换为一个个特征(列),然后对每一篇文章数关键词出现个数。
特征抽取
我们希望获取到的词汇,既能保留文本的信息,同时又能反映它们的相对重要性。
特征选取的方式:
- 构建词向量空间:统计文本词频,生成文本的词向量空间
- 权重策略——TF-IDF:使用TF-IDF发现特征词,并抽取为反映文档主题的特征
经过上面的步骤之后,我们就可以把文本集转化成一个矩阵。
TF-IDF向量化
vectorizer = TfidfVectorizer(stop_words=stop_words, sublinear_tf=True, max_df=0.5)print("\nvectorizing...")vector = vectorizer.fit_transform(segments)# 查看结果# print(vectorizer.vocabulary_) # 词表索引# print(vectorizer.idf_) # 词表中每个词的IDF权重# print(vector.toarray()) # 向量化结果 [[0. 0. 0.07097325 ... 0. 0. 0. ]...]
文本挖掘
关于文本挖掘方面的相关知识,请参看《数据运营|数据分析中,文本分析远比数值型分析重要!(上)》、《在运营中,为什么文本分析远比数值型分析重要?一个实际案例,五点分析(下)》。
本文的文本挖掘部分主要涉及:
高频词统计/关键词提取/关键词云TF-IDF的关键词提取方法文章标题聚类文章内容聚类文章内容LDA主题模型分析词向量/关联词分析ATM模型词汇分散图词聚类分析
用Python提取中文关键词
对于关键词提取,笔者没有采取词频统计的方法,因为词频统计的逻辑是:一个词在文章中出现的次数越多,则它就越重要。因而,笔者采用的是TF-IDF(termfrequency–inverse document frequency)的关键词提取方法:
- 关键字抽取步骤:
# TextRank关键词提取print(Fore.RED + "关键词提取结果如下:")topk_list = textrank("\n".join(segments), withWeight=True, topK=100)topk_keyword = []with codecs.open('result/TextRank算法提取的 TOP100 关键词.txt', 'w', 'utf-8') as f:for keyword, weight in topk_list:f.write("{}\t{}\n".format(keyword, weight))topk_keyword.append(keyword)print(Fore.GREEN + "%s\t%s" % (keyword, weight))# 选取TOP100关键词来绘制关键词云doWordCloud(' '.join(topk_keyword), stop_words)
下面是笔者利用jieba在经预处理后的、近70MB的语料中抽取出的TOP100关键词(略)
统计性分析
只从文本中提取1000个最重要的特征关键词,然后停止
# CountVectorizer统计词频n_features = 1000 # 提取1000个最重要的特征关键词vectorizer = CountVectorizer(max_df=0.95,min_df=2,max_features=n_features,strip_accents="unicode",stop_words=stop_words,)vector = vectorizer.fit_transform(segments)vocab = vectorizer.vocabulary_cipin = vector.toarray() # 词频统计 [[1 1 1 1 1 1 1 2]]
利用LDA进行主题抽取
刚才针对关键词的分类较为粗略,且人为划分,难免有失偏颇,达不到全面的效果。因此,笔者采用LDA主题模型来发现该语料中的潜在主题。关于LDA主题模型的相关原理,请参看《【干货】用大数据文本挖掘,来洞察“共享单车”的行业现状及走势》的第4部分。
LDA是一种典型的无监督(也就是说,我们事先不知道每段文本里面说的是啥,每个文本没有啥标签)、基于统计学习的词袋模型,即它认为一篇文档是由一组词构成的一个集合,词与词之间没有顺序以及先后的关系。一篇文档可以包含多个主题,文档中每一个词都由其中的一个主题生成。主题模型通过分析文本中的词来发现文档中的主题、主题之间的联系方式和主题的发展,通过主题模型可以使我们组织和总结无法人工标注的海量电子文档。
def trainLDA(vector):# 主题分析n_topics = [5]perplexityLst = [1.0]*len(n_topics)#训练LDA并打印训练时间lda_models = []for idx, n_topic in enumerate(n_topics):lda = LatentDirichletAllocation(n_components=n_topic,max_iter=100,learning_method='batch', # 'batch' 'online'evaluate_every=200,learning_offset=50.0,random_state=0)t0 = time()lda.fit(vector)# 收敛效果(perplexity)perplexityLst[idx] = lda.perplexity(vector)lda_models.append(lda)print("# of Topic: %d, " % n_topics[idx])print("done in %0.3fs, N_iter %d, " % ((time() - t0), lda.n_iter_))print("收敛效果 Perplexity Score (越小越好) %0.3f" % perplexityLst[idx])#打印最佳模型best_index = perplexityLst.index(min(perplexityLst))best_n_topic = n_topics[best_index]best_model = lda_models[best_index]print(Fore.RED + "Best # of Topic: ", best_n_topic)print('\n')# 定义以下的函数,把每个主题里面的前若干个关键词显示出来def print_top_words(model, feature_names, n_top_words):with codecs.open("result/主题簇.txt", "w", "utf-8") as f:for topic_idx, topic in enumerate(model.components_):f.write("Topic #%d:\n" % topic_idx)f.write("\n".join([feature_names[i] for i in topic.argsort()[: -n_top_words - 1 : -1]]))f.write("\n")print(Fore.RED + "Topic #%d:" % topic_idx)print(Fore.GREEN+ " ".join([feature_names[i] for i in topic.argsort()[: -n_top_words - 1 : -1]]))print("\n")# 打印主题建模的结果n_top_words = 10 # 主题数量tf_feature_names = vectorizer.get_feature_names()print_top_words(lda, tf_feature_names, n_top_words)# 将doc转换为话题分布的函数doc_topic_dist = lda.transform(vector)trainLDA(vector)
一般情况下,笔者将主题的数量设定为10个,经过数小时的运行,得到如下结果:
Topic #0:学习 模型 使用 算法 方法 机器 可视化 神经网络 特征 处理 计算 系统 不同 数据库 训练 分类 基于 工具 一种 深度Topic #1:这个 就是 可能 如果 他们 没有 自己 很多 什么 不是 但是 这样 因为 一些 时候 现在 用户 所以 非常 已经Topic #2:企业 平台 服务 管理 互联网 公司 行业 数据分析 业务 用户 产品 金融 创新 客户 实现 系统 能力 产业 工作 价值Topic #3:中国 2016 电子 增长 10 市场 城市 2015 关注 人口 检索 30 或者 其中 阅读 应当 美国 全国 同比 20Topic #4:人工智能 学习 领域 智能 机器人 机器 人类 公司 深度 研究 未来 识别 已经 医疗 系统 计算机 目前 语音 百度 方面
- 利用LDA做了主题抽取,不论是5个还是10个主题,可能都不是最优的数量选择。你可以根据程序反馈的结果不断尝试。
ATM模型
ATM模型(author-topic model)也是“概率主题模型”家族的一员,是LDA主题模型(Latent Dirichlet Allocation )的拓展,它能对某个语料库中作者的写作主题进行分析,找出某个作家的写作主题倾向,以及找到具有同样写作倾向的作家,它是一种新颖的主题探索方式。
词向量/关联词分析
词聚类
文档聚类
- 参照博客《如何用Python从海量文本提取主题?》,面对的是大量的文档,利用主题发现功能对文章聚类
- 参照博客《使用Gensim进行主题建模(一)
每一条评论都围绕一个或几个核心主旨进行阐述,这个核心主旨就是评论的中心思想。基于主旨话题分析技术获取文本主旨,每一条评论可能包含多个主旨话题,每一个话题包含多个主题词,通过评论的隶属度确定评论所属的主旨话题,通过主题词的分布确定主旨的含义。评论话题的具体分析流程如下,此过程要依次进行词法分析、文本过滤、主旨话题分析:
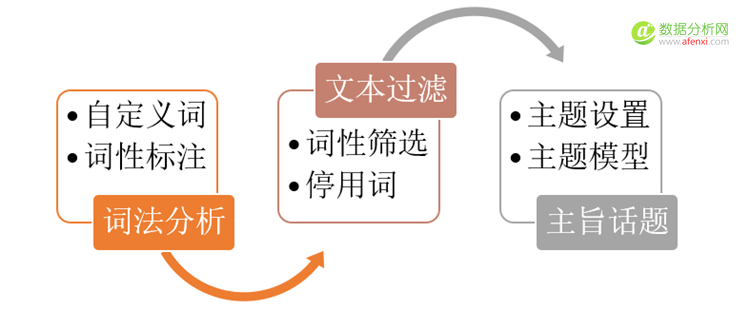
接下来采用的是基于谱联合聚类算法(Spectral Co-clustering algorithm)的文档聚类,这部分的原理涉及到艰深的数学和算法知识,可能会引起小伙伴们的阅读不适感,如果是这样,请快速跳过,直接看后面的操作和结果。
先将待分析的文本经TF-IDF向量化构成了词频矩阵,然后使用Dhillon的谱联合聚类算法(Spectral Co-clustering algorithm)进行双重聚类(Biclusters)。所得到的“文档-词汇”双聚类(Biclusters)会把某些文档子集中的常用词汇聚集在一起,由若干个关键词构成某个主题。
# 将聚类结果写入文件def writeClusterResult(y):result_dict = {}for i in range(len(y)):if y[i] not in result_dict:result_dict[y[i]] = []result_dict[y[i]].append(os.listdir(path)[:15][i].strip())# 按value长度逆序排序,写入result_list = sorted(result_dict.items(), key=lambda d: len(d[1]), reverse=True)with codecs.open("result/prediction_cluster.txt", "w", encoding='utf-8') as target:for item in result_list:target.write("{}\n{}\n\n".format(item[0], "\n".join(item[1])))print('聚类结果写入文件完成!!!')# 文本聚类n_clusters = 5kmeans = MiniBatchKMeans(n_clusters=n_clusters, batch_size=20000, random_state=0)print("MiniBatchKMeans...")y_kmeans = kmeans.fit_predict(vector).tolist()y_kmeans = np.array(y_kmeans)writeClusterResult(y_kmeans)
参考

若有收获,就点个赞吧
0 人点赞
