论文:《Transformer Quality in Linear Time》 博客:FLASH:可能是近来最有意思的高效Transformer设计 开源地址:https://github.com/ZhuiyiTechnology/GAU-alpha
本文主要记录了苏神博客《FLASH:可能是近来最有意思的高效Transformer设计》的学习笔记,方便日后快速回忆相关内容。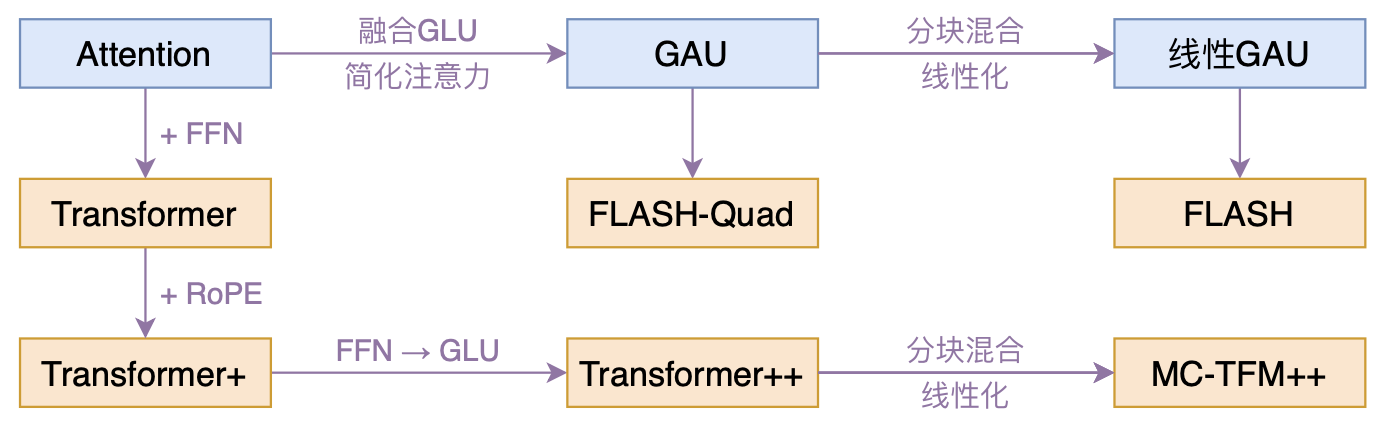
Flash模型脉络图
文章摘要:
本文介绍了Google新出的一个高效Transformer工作,里边将Attention和FFN融合为一个新的GAU层,从而得到了Transformer变体FLASH-Quad,作者还进一步提出了一种“分块混合”线性化方案,得到了具有线性复杂度的FLASH。目前的实验结果显示,不管FLASH-Quad还是FLASH,跟标准Transformer相比都是更快、更省、更好。
FLASH 的优势:
1、提出了一种新的Transformer变体,它依然具有二次的复杂度,但是相比标准的Transformer,它有着更快的速度、更低的显存占用以及更好的效果; 2、提出一种新的线性化Transformer方案,它不但提升了原有线性Attention的效果,还保持了做Decoder的可能性,并且做Decoder时还能保持高效的训练并行性。
FLASH&GAU要点:
- 标准的Transformer其实是Attention层和FFN层交替构建的;
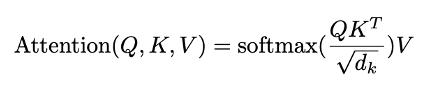
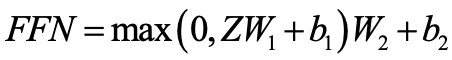
- GLU(Gated Linear Unit,门控线性单元)对FFN做了改进,效果更好


- GLU各个token之间没有进行交互,也就是矩阵U,V 的每一行都是独立运算的。为了补充这点不足,加入Attention矩阵来融合token之间的信息,实现Attention和FFN的一个简单而自然的融合,也即 GAU(Gated Attention Unit,门控注意力单元)


- GAU示意图及其伪代码
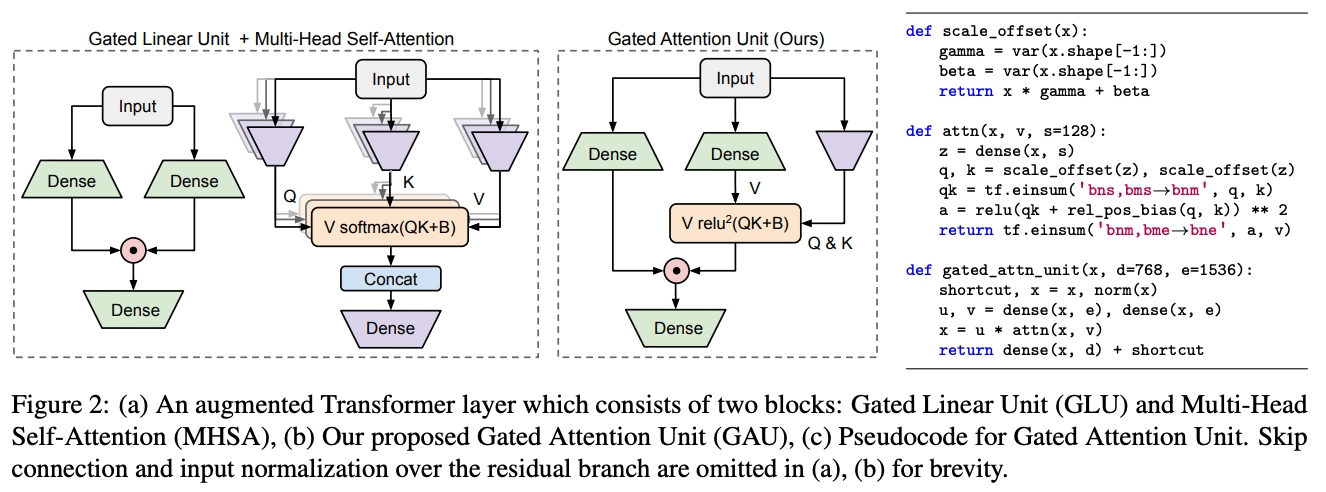
- FLASH-Quad:将Transformer的Attention+FFN换成了两层GAU(苏神比较过两层GAU的计算量和参数量大致相当于Attention+FFN组合)。只要一个头的GAU,就可以达到Transformer的多头注意力机制相同甚至更好的效果。尽管FLASH-Quad和Transformer都是二次复杂度,但FLASH-Quad效果更好、速度更快、显存占用量更低;
- 进一步将FLASH-Quad从二次复杂度降至线性复杂度,提出了 FLASH(Fast Linear Attention with a Single Head)。FLASH采取了“局部-全局”分块混合的方式:
- 分块:对于长度为n的输入序列,我们将它不重叠地划分为n/c个长度为c的块;
- 混合:将GAU的 Attention 和线性 Attention二者的结果结合起来,整合到GAU中,得到线性版本的GAU



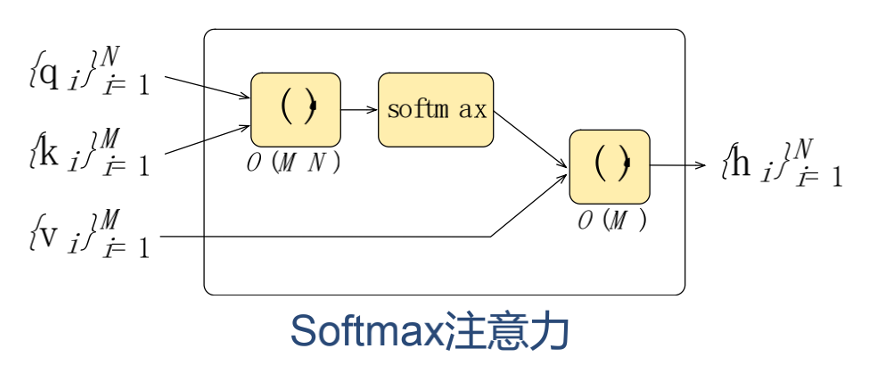
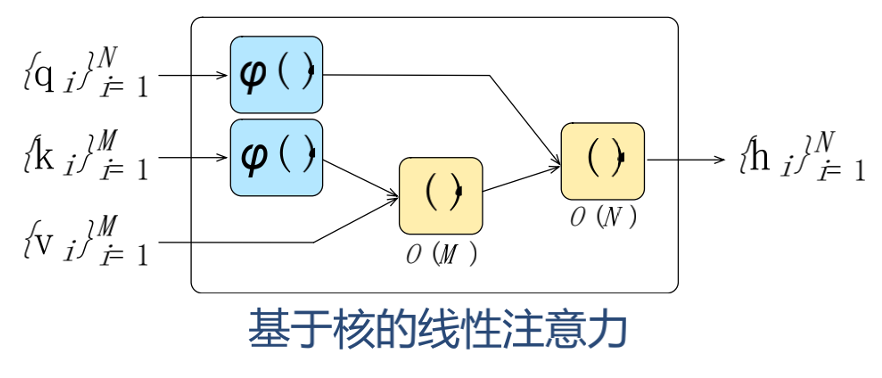
- 线性 Attention


若有收获,就点个赞吧
0 人点赞
