- 命名实体识别简述
- 一、什么是NER
- 二、NER主要方法
- 三、NER模型效果优化
- 3.1 模型优化之数据增强
- 模型优化之词汇增强">3.2 模型优化之词汇增强
- Chinese NER Using Lattice LSTM">- Lattice LSTM:Chinese NER Using Lattice LSTM
- CNN-Based Chinese NER with Lexicon Rethinking">- LR-CNN:CNN-Based Chinese NER with Lexicon Rethinking
- Bipartite Flat-Graph Network for Nested Named Entity Recognition">- Bipartite Flat-Graph Network for Nested Named Entity Recognition
- Chinese NER Using Flat-Lattice Transformer(ACL2020)">- FLAT:Chinese NER Using Flat-Lattice Transformer(ACL2020)
- - Lex-BERT: Enhancing BERT based NER with lexicons(2021)
- - Simple-Lexicon
- 3.3 总结
- 四、评估标准
- 工业界如何解决NER问题?12个trick,与你分享~">五、工业界如何解决NER问题?12个trick,与你分享~
- 参考
title: 对话系统之NER
subtitle: 对话系统之NER
date: 2021-10-31
author: NSX
catalog: true
tags:
- NER
- 命名实体识别
命名实体识别简述
一、什么是NER
命名实体识别(Named Entity Recognition,简称NER),又称作“专名识别”,是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。NER是信息提取、问答系统、句法分析、机器翻译、面向Semantic Web的元数据标注等应用领域的重要基础工具,在自然语言处理技术走向实用化的过程中占有重要的地位。NER是深度查询理解(Deep Query Understanding,简称 DQU)的底层基础信号,主要应用于搜索召回、用户意图识别、实体链接等环节。
二、NER主要方法
2.1 基于规则和词典的方法
一般来说,我们在做命名实体的时候,可以首先考虑一下可否使用正则。假如命名实体的名称规律比较简单,我们可以找出模式,然后设计相应的正则表达式或者规则,然后把符合模式的字符串匹配出来,作为命名实体识别的结果。
优点:这种NER系统的特点是高精确率与低召回率;
缺点:难以迁移应用到别的领域中去,基于领域的规则往往不通用,对新的领域而言,需要重新制定规则且不同领域字典不同;此外,需要保证用户输入的关键词和预存词表完全一致,且当词表数量较大时,正则表达式将面临匹配速度、内存占用等挑战。
2.2 无监督学习方法
主要是基于聚类的方法,根据文本相似度得到不同的簇,表示不同的实体类别组。常用到的特征或者辅助信息有词汇资源、语料统计信息(TF-IDF)、浅层语义信息(分块NP-chunking)等。
2.3 基于特征的监督学习方法
NER可以被转换为一个分类问题或序列标记问题。分类问题就是判断一个词语是不是命名实体、是哪一种命名实体。常见的做法就是,基于一个词语或者字的上下文构造特征,来判断这个词语或者字是否为命名实体;序列标注方法就是给句子中的每个词按照需求的方式打上一个标签,标签的格式通常有IOB2和IOBES两种标准。缺陷是无法处理嵌套实体的情况。
上述问题涉及到特征工程和模型选择,需要训练模型使其能够对句子给出标记序列作为预测。
- 特征工程:word级别特征(词法特征、词性标注等),词汇特征(维基百科、DBpdia知识),文档及语料级别特征。
- 模型选择:隐马尔可夫模型、决策树、最大熵模型、最大熵马尔科夫模型、支持向量机、条件随机场。
2.4 深度学习方法
近年来,基于DL的NER模型占据了主导地位并取得了最先进的成果。与基于特征的方法相比,深度学习有利于自动发现隐藏的特征。NN把语言看做是序列数据,然后用自身极强的拟合能力,把这种序列转换为标签序列。BiLSTM+CRF方案结合了神经网络的拟合能力和CRF的全局视野,是非常经典、有效的一种NER模型结构。
1)BiLSTM+CRF
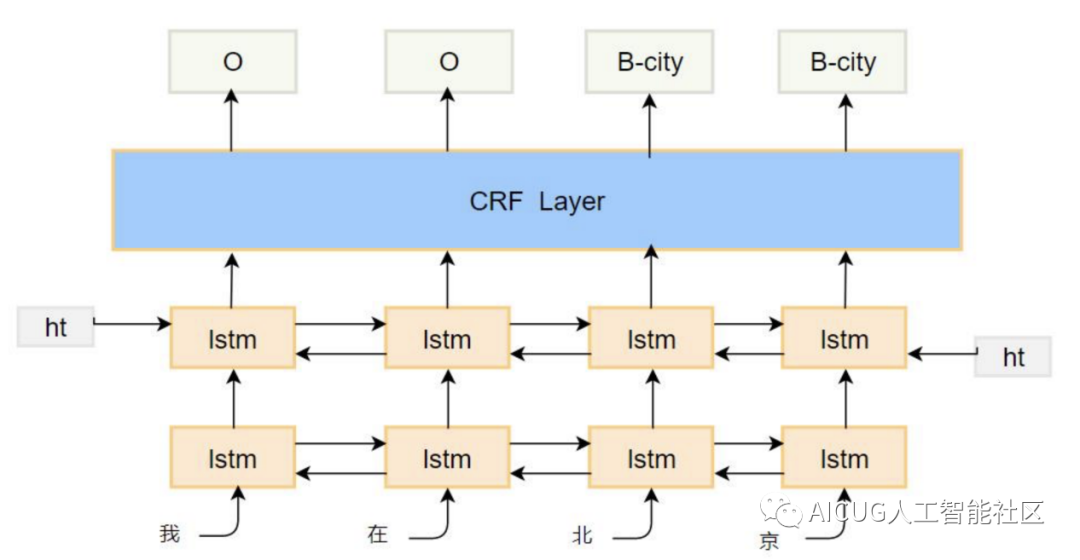
BiLSTM的输出作为CRF的发射概率矩阵,而CRF层可以加入一些约束来保证最终预测结果是有效的。这些约束可以在训练数据时被CRF层自动学习得到。
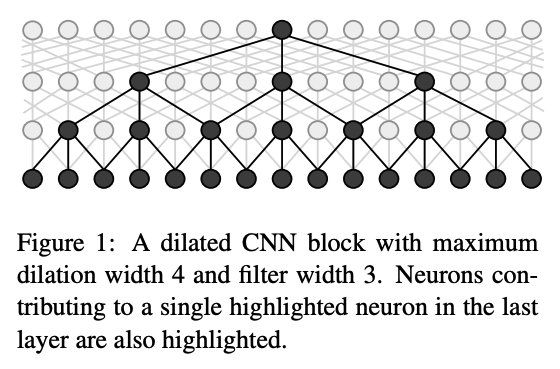
2)IDCNN+CRF
尽管BILSTM在NER任务中有很好的表现,但是却不能充分利用GPU的并行性,导致该模型的想能较差,因此出现了一种新的NER模型方案IDCNN+CRF。
在IDCNN+CRF模型结构中,待识别query先经过Embedding层获取向量表示;然后经过空洞卷积层(IDCNN),IDCNN通过空洞卷积增大模型的感受野, 相较于传统的CNN,IDCNN能够捕捉更长的上下文信息,更适合序列标注这类需要全局信息的任务;在IDCNN之后经过一层全连接神经网络(FF层)后引入CRF,同样CRF的目的在于防止非法槽位标记(BIO)的出现。
补充:尽管传统的CNN有明显的计算优势,但是传统的CNN在经过卷积之后,末梢神经元只能得到输入文本的一小部分信息,为了获取上下文信息,需要加入更多的卷积层,导致网络越来越深,参数越来越多,容易发生过拟合。
文本空洞卷积的示意图如下:
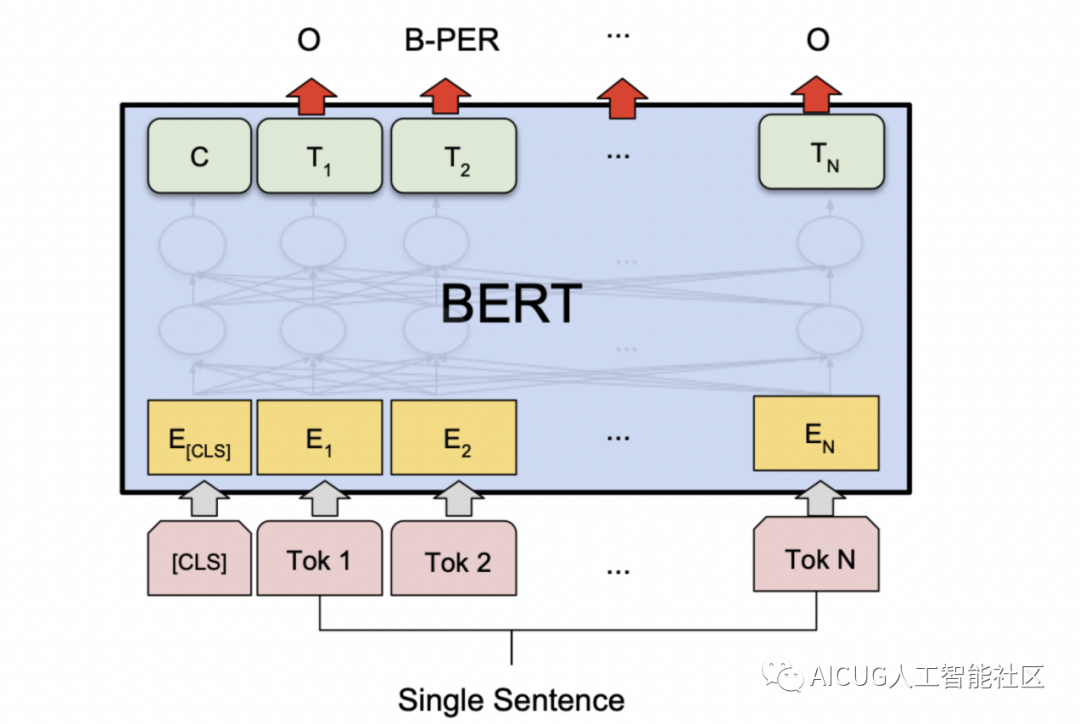
3)Bert+BiLSTM+CRF
Bert由谷歌大佬与2018年提出来,刚出来的时候横扫了11项NLP任务。BERT通过微调的方法可以灵活的应用到下游业务,所以这里我们也可以考虑使用Bert作为embedding层,将特征输入到Bilstm+CRF中,以谋求更好的效果。
PS:NER模型之CRF的作用
关于 CRF 的介绍可以参考《2021-02-22-条件随机场 (CRF) 概述》
在上述模型中,在NER任务上,我们看到很多深度学习之后都会接上一层CRF,那么CRF在整个过程中到底发挥着什么样的作用呢?通常我们直接使用逐帧softmax时,是将序列标注过程作为n个k分类问题,相当于每个token相互独立的进行分类(假设深度模型内部交互不明显的话),而采用CRF实质上是在进行一个 分类,相当于直接从所有的序列空间里找出转移概率最大的那条序列。其实质上是局部最优(token最优)与全局最优(序列最优)的区别,因而采用CRF能够有效避免出现非法的序列标记,从而确保序列有效。
分类,相当于直接从所有的序列空间里找出转移概率最大的那条序列。其实质上是局部最优(token最优)与全局最优(序列最优)的区别,因而采用CRF能够有效避免出现非法的序列标记,从而确保序列有效。
三、NER模型效果优化
3.1 模型优化之数据增强
针对启动阶段存在的数据不足问题,可以采用数据增强的方式来补充训练数据,NER做数据增强,和别的任务有啥不一样呢?很明显,NER是一个token-level的分类任务,在进行全局结构化预测时,一些增强方式产生的数据噪音可能会让NER模型变得敏感脆弱,导致指标下降、最终奔溃。
- An Analysis of Simple Data Augmentation for Named Entity Recognition
参考论文《An Analysis of Simple Data Augmentation for Named Entity Recognition》主要是将传统的数据增强方法应用于NER中、并进行全面分析与对比。效果如何?
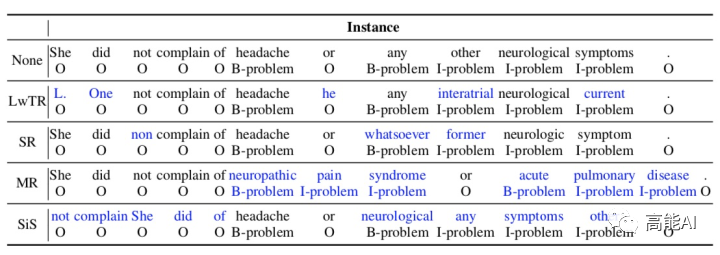
作者借鉴sentence-level的传统数据增强方法,将其应用于NER中,共有4种方式(如上图所示):
- Label-wise token replacement (LwTR) :即同标签token替换,采用二项分布概率对句子进行采样,概率替换某位置的token为同标签其它token,如果token长度不一致,则进行延展,句子长度发生变化。
- Synonym replacement (SR) :即同义词替换,利用WordNet查询同义词,然后根据二项分布随机替换。如果替换的同义词大于1个token,那就依次延展BIO标签。
- **Mention replacement (MR) :即实体提及替换,与同义词方法类似,利用训练集中的相同实体类型进行替换,如果替换的mention大于1个token,那就依次延展BIO标签,如上图:「headache」替换为「neuropathic pain syndrome」,依次延展BIO标签。
- Shuffle within segments (SiS) :按照mention来切分句子,然后再对每个切分后的片段进行shuffle。如上图,共分为5个片段: [She did not complain of], [headache], [or], [any other neurological symptoms], [.]. 。也是通过二项分布判断是否被shuffle(mention片段不会被shuffle),如果shuffle,则打乱片段中的token顺序。
- 总结规则模板,直接生成数据。(收益不小)
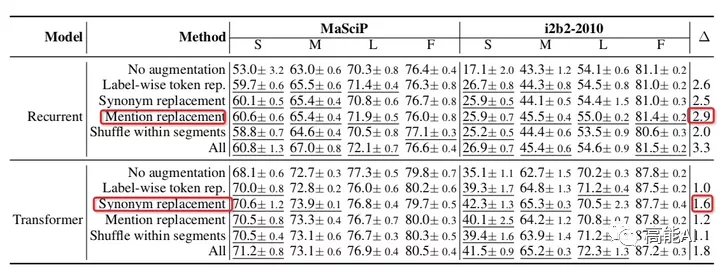
由上图得出以下结论:
- 各种数据增强方法都超过不使用任何增强时的baseline效果。
- 对于RNN网络,实体提及替换优于其他方法;对于Transformer网络,同义词替换最优。
- 总体上看,所有增强方法一起使用(ALL)会由于单独的增强方法。
- 低资源条件下,数据增强效果增益更加明显;
- 充分数据条件下,数据增强可能会带来噪声,甚至导致指标下降;
3.2 模型优化之词汇增强
有的学者开始另辟蹊径,利用外部词汇信息力求与BERT一战;
- Lattice LSTM:Chinese NER Using Lattice LSTM
引入词汇信息,在原有的输入序列的基础上添加匹配到的词汇作为额外的链路,整体看起来有点像ResNet的短路链接,两端分别连接原始输入序列的词首尾,称之为Latttice-LSTM。事实也证明词典带来的提升是明显的,一举超越BERT,重回武林宝座。缺点: 计算性能低下,不能batch并行化;信息损失:每个字符只能 获取以它为结尾的词汇信息;可迁移性差;

- LR-CNN:CNN-Based Chinese NER with Lexicon Rethinking
该篇指出Latttice-LSTM第一:速度太慢,第二:无法进行词汇匹配的选择。为了解决这两个问题,将原始输入序列按照词典匹配的词汇信息进行Bigram,Trigram合并然后CNN特征提取,然后将匹配到词汇信息,进行时间维度上attention计算后,利用Rethinking机制,反馈到原始Bigram,Trigram层,进行词汇匹配的选择,以解决词汇冲突的问题。

- Bipartite Flat-Graph Network for Nested Named Entity Recognition
将引入的词汇作为额外的链路,与原始序列一起构建成输入图,字作为节点,链接是关系,然后通过对图进进行建模获得图节点的嵌入式表征,最后使用CRF进行解码。
- FLAT:Chinese NER Using Flat-Lattice Transformer(ACL2020)
FLAT的基本思想来源于Lattice-LSTM,Lattice-LSTM采取的RNN结构无法捕捉长距离依赖,同时引入词汇信息是有损的,同时动态的Lattice结构也不能充分进行GPU并行。为解决计算效率低下、引入词汇信息有损的这两个问题,FLAT基于Transformer结构进行了两大改进:
改进1:Flat-Lattice Transformer,无损引入词汇信息。FLAT不去设计或改变原生编码结构,设计巧妙的位置向量就融合了词汇信息。具体来说,对于每一个字符和词汇都构建两个head position encoding 和tail position encoding,词汇信息直接拼接到原始输入序列的末尾(避免了引入额外的链路,增加模型复杂度),并用位置编码与原始输入序列的对应位置相关联,间接指明了添加词汇所在的位置信息。

改进2:相对位置编码,让Transformer适用NER任务

- Lex-BERT: Enhancing BERT based NER with lexicons(2021)
Lex-BERT相比于FLAT有三点:1. 不需要利用word embedding;2. 可以引入实体类型type信息,作者认为在领域内,可以收集包含类型信息的词汇;3. 相比FLAT,Lex-BERT推断速度更快、内存占用更小;

- Simple-Lexicon
博客:Simplify the Usage of Lexicon in Chinese NER
词汇信息是有用的,但是如何使用,学术界还未形成统一。可以看得出来,上述文章在引入词汇的方式上五花八门,计算复杂度都比较高。Simple-Lexicon该篇论文直击痛点,对于词汇信息的引入更加简单有效,采取静态加权的方法可以提前离线计算。作者首先分析列举了几种引入词汇信息方法;最终论文发现,将词汇的信息融入到特殊token{B,M,E,S}中,并和原始词向量进行concat,能够带来明显的提升。通过特殊token表征额外信息的方式,在NER与NRE联合学习任务中也逐渐成为一种趋势。具体细节可参考视频讲解
3.3 总结
最后,我们来看一下,上述各种「词汇增强」方法在中文NER任务上的性能:
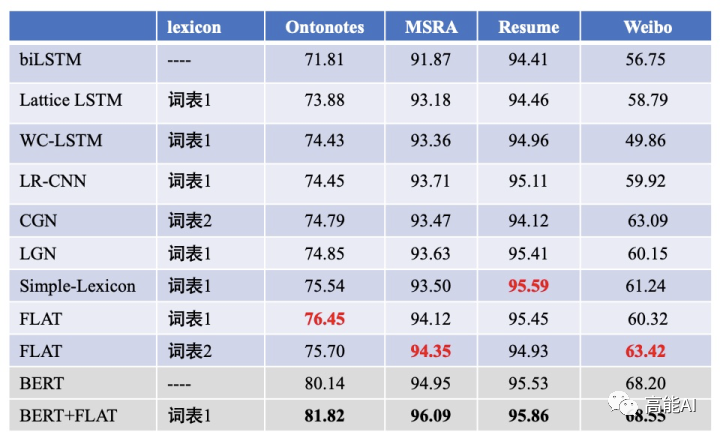
上图可以发现:总的来看,ACL2020中的FLAT和Simple-Lexicon效果最佳。具体地说:
- 引入词汇信息的方法,都相较于baseline模型biLSTM+CRF有较大提升,可见引入词汇信息可以有效提升中文NER性能。
- 采用相同词表对比时,FLAT和Simple-Lexicon好于其他方法。
- 结合BERT效果会更佳。
四、评估标准
NER任务的目标,通常是“尽量发现所有的命名实体,发现的命名实体要尽量纯净”,也就是要求查全率和查准率比较高。当然,场景也有可能要求其中一项要非常高。
通常通过与人类标注水平进行比较判断NER系统的优劣。评估分两种:精确匹配评估和宽松匹配评估。
4.1 精确匹配评估
NER任务需要同时确定实体边界以及实体类别。在精确匹配评估中,只有当实体边界以及实体类别同时被精确标出时,实体识别任务才能被认定为成功。
基于数据的 true positives(TP),false positives(FP),以及false negatives(FN),可以计算NER任务的精确率,召回率以及 F-score 用于评估任务优劣。
对NER中的 true positives(TP),false positives(FP)与false negatives(FN)有如下解释:
- true positives(TP):NER能正确识别实体
- false positives(FP):NER能识别出实体但类别或边界判定出现错误
- false negatives(FN):应该但没有被NER所识别的实体
P\R\F的计算公式如下:
精确率: 
召回率: 
F-score:
其中 F1 值又可以分为 macro-averaged 和 micro-averaged,前者是按照不同实体类别计算 F1,然后取平均;后者是把所有识别结果合在一起,再计算 F1。这两者的区别在于实体类别数目不均衡,因为通常语料集中类别数量分布不均衡,模型往往对于大类别的实体学习较好。
4.2 宽松匹配评估
简言之,可视为实体位置区间部分重叠,或位置正确类别错误的,都记为正确或按照匹配的位置区间大小评测。
五、工业界如何解决NER问题?12个trick,与你分享~
5.1 工业界中的NER问题为什么不易解决?
在真实的工业界场景中,通常面临标注成本昂贵、泛化迁移能力不足、可解释性不强、计算资源受限等问题,想要将NER完美落(bian)地(xian)可不简单,那些在经典benchmark上自称做到SOTA的方法放在现实场景中往往“也就那样”。以医疗领域为例:
- 不同医院、不同疾病、不同科室的文本描述形式不一致,而标注成本又很昂贵,一个通用的NER系统往往不具备“想象中”的泛化迁移能力。当前的NER技术在医疗领域并不适合做成泛化的工具。
- 由于医疗领域的严肃性,我们既要知其然、更要知其所以然:NER系统往往不能采用“一竿子插到底”的黑箱算法,处理过程应该随着处理对象的层次和深度而逐步叠加模块,下级模块使用上级结果,方便进行迭代优化、并具备可解释性,这样做可解耦医学事件、也便于进行医学实体消歧。
- 仅仅使用统计模型的NER系统往往不是万能的,医疗领域相关的实体词典和特征挖掘对NER性能也起着关键作用。此外,NER结果往往不能直接使用,还需进行医学术语标准化。
- 由于医院数据不可出院,需要在院内部署NER系统。而通常医院内部的GPU计算资源又不是很充足(成本问题),我们需要让机器学习模型又轻又快(BERT上不动哇),同时要更充分的利用显存。
以上种种困难,导致了工业界场景求解NER问题不再那么容易,不是一个想当然的事情。
5.2 做NER的几条教训(趟过的坑)
下面给出笔者在医疗领域做NER的经验教训(趟过的坑):
1、提升NER性能(performance)的⽅式往往不是直接堆砌⼀个BERT+CRF,这样做不仅效果不一定会好,推断速度也非常堪忧。就算BERT效果还不错,付出的代价也是惨重的。
就算直接使用BERT+CRF进行finetune,BERT和CRF层的学习率也不要设成一样,让CRF层学习率要更大一些(一般是BERT的5~10倍),要让CRF层快速收敛。
2、在NER任务上,也不要试图对BERT进⾏蒸馏压缩,很可能吃⼒不讨好。
哈哈,也许废了半天劲去蒸馏,效果下降到还不如1层lstm+crf,推断速度还是慢~
3、NER任务是⼀个重底层的任务,上层模型再深、性能提升往往也是有限的(甚至是下降的)。
不要盲目搭建很深的网络,也不要痴迷于各种attention了。
4、NER任务不同的解码方式(CRF/指针网络/Biaffine[1])之间的差异其实也是有限的,不要过分拘泥于解码⽅式。
5、通过QA阅读理解的方式进行NER任务,效果也许会提升,但计算复杂度上来了,你需要对同⼀⽂本进行多次编码(对同⼀文本会构造多个question)。
6、设计NER任务时,尽量不要引入嵌套实体,不好做,这往往是一个长尾问题。
7、不要直接拿Transformer做NER,这是不合适的,详细可参考TENER[2]。
补充:TENER: Adapting Transformer Encoder for Named Entity Recognition
论文详细分析了为什么原始BERT模型在NER上表现不佳的原因:位置编码只具有距离感受能力,不具有方向感受能力;并在借鉴XL-Net的基础上,提出了相对位置编码的方法;使用相对位置编码后,明显提升了BERT在NER上的效果。
5.3 工业界中NER问题的12个trick
笔者首先给出一个非常直接的打开方式:1层lstm+crf!
从模型层面看,你也许会问:为什么非是1层lstm+crf?1层lstm+crf不能解决业务问题怎么办?遇到更为复杂的场景该怎么办?不着急,且听我慢慢道来。
让我们回到一开始列出的那12个问题,并逐一解答:
Q1、如何快速有效地提升NER性能?
如果1层lstm+crf,这么直接的打开方式导致NER性能达不到业务目标,这一点也不意外(这是万里长征的第一步~)。这时候除了badcase分析,不要忘记一个快速提升的重要手段:规则+领域词典。
- 在垂直领域,一个不断积累、不断完善的实体词典对NER性能的提升是稳健的,基于规则+词典也可以快速应急处理一些badcase;
- 对于通⽤领域,可以多种分词工具和多种句法短语⼯具进行融合来提取候选实体,并结合词典进行NER。
Q2、如何在模型层面提升NER性能?
如果想在模型层面(仍然是1层lstm+crf)搞点事情,上文讲过NER是一个重底层的任务,1层lstm足以很好捕捉NER任务中的方向信息和局部特征了。我们应该集中精力在embedding层下功夫,那就是引入丰富的特征:比如char、bigram、词典特征、词性特征、elmo等等,还有更多业务相关的特征;在垂直领域,如果可以预训练一个领域相关的字向量&语言模型,那是最好不过的了。
总之,底层的特征越丰富、差异化越大越好。我们需要构造不同视角下的特征。
Q3、如何构建引入词汇信息(词向量)的NER?
具体可参考专栏文章《中文NER的正确打开方式:词汇增强方法总结》。ACL2020的Simple-Lexicon[4]和FLAT[5]两篇论文,不仅词汇增强模型十分轻量、而且可以比肩BERT的效果。
Q4、如何解决NER实体span过长的问题?
如果NER任务中某一类实体span比较长(⽐如医疗NER中的⼿术名称是很长的),直接采取CRF解码可能会导致很多连续的实体span断裂。除了加入规则进行修正外,这时候也可尝试引入指针网络+CRF构建多任务学习解决。
指针网络会更容易捕捉较长的span,不过指针网络的收敛是较慢的,可以对CRF和指针网络设置不同学习率,或者设置不同的loss权重。
Q5、如何客观看待BERT在NER中的作用?
对于工业场景中的绝大部分NLP问题(特别是垂直领域),都没有必要堆资源。但这绝不代表BERT是“一无是处”的,在不受计算资源限制、通用领域、小样本的场景下,BERT表现会更好。我们要更好地去利用BERT的优势:
- 在低耗时场景中,BERT可以作为一个“对标竞品”,我们可以采取轻量化的多种策略组合去逼近甚至超越BERT的性能;
- 在垂直领域应用BERT时,我们首先确认领域内的语料与BERT原始的预训练语料之间是否存在gap,如果这个gap越大,那么我们就不要停止预训练:继续在领域内进行预训练,继续在具体任务上进行预训练。
- 在小样本条件下,利用BERT可以更好帮助我们解决低资源问题:比如基于BERT等预训练模型的文本增强技术[6],又比如与主动学习、半监督学习、领域自适应结合(后续详细介绍)。
- 在竞赛任务中,BERT很有用!我们可以选取不同的预训练语⾔模型在底层进行特征拼接。具体地,可以将char、bigram和BERT、XLNet等一起拼接喂入1层lstm+crf中。语⾔模型的差异越⼤,效果越好。如果需要对语言模型finetune,需要设置不同的学习率。
Q6、如何冷启动NER任务?
如果⾯临的是⼀个冷启动的NER任务,业务问题定义好后,首先要做的就是维护好一个领域词典,而不是急忙去标数据、跑模型;当基于规则+词典的NER系统不能够满足业务需求时,才需要启动人工标注数据、构造机器学习模型。
当然,我们可以采取一些省成本的标注方式,如结合领域化的预训练语言模型+主动学习,挖掘那些“不确定性高”、并且“具备代表性”的高价值样本。
需要注意的是,由于NER通常转化为一个序列标注任务,不同于传统的分类任务,我们需要设计一个专门针对序列标注的主动学习框架。
Q7、如何有效解决低资源NER问题?
如果拿到的NER标注数据还是不够,又不想标注人员介入,这确实是一个比较困难的问题。
低资源NLP问题的解决方法通常都针对分类任务,这相对容易一些,如可以采取文本增强、半监督学习等方式,可参考专栏文章《标注样本少怎么办?「文本增强+半监督学习」总结 》。
上述解决低资源NLP问题的方法,往往在NER中提升并不明显。NER本质是基于token的分类任务,其对噪声极其敏感的。如果盲目应用弱监督方法去解决低资源NER问题,可能会导致全局性的性能下降,甚至还不如直接基于词典的NER。
这里给出一些可以尝试的解决思路(笔者个人建议,也许还会翻车啊):
- 上文已介绍BERT在低资源条件下能更好地发挥作用:我们可以使用BERT(领域预训练的BERT)进行数据蒸馏(半监督学习+置信度选择),同时利用实体词典辅助标注。
- 还可以利用实体词典+BERT相结合,进行半监督自训练,具体可参考文献[7]。
- 工业界毕竟不是搞学术,要想更好地解决低资源NER问题,RD在必要时还是要干预、并进行核查的。
Q8、如何缓解NER标注数据的噪声问题?
实际工作中,我们常常会遇到NER数据可能存在标注质量问题,也许是标注规范就不合理(一定要提前评估风险,不然就白干了),当然,正常的情况下只是存在一些小规模的噪声。
一种简单地有效的方式就是对训练集进行交叉验证,然后人工去清洗这些“脏数据”。当然也可以将noisy label learning应用于NER任务,惩罚那些噪音大的样本loss权重,具体可参考文献[8]。
Q9、如何克服NER中的类别不平衡问题?
NER任务中,常常会出现某个类别下的实体个数稀少的问题,而常规的解决方法无外乎是重采样、loss惩罚、Dice loss[9]等等。而在医疗NER中,我们常常会发现这类实体本身就是一个长尾实体(填充率低),如果能挖掘相关规则模板、构建词典库也许会比模型更加鲁棒。
Q10、如何对NER任务进行领域迁移?
在医疗领域,我们希望NER模型能够在不同医院、不同疾病间进行更好地泛化迁移(这是一个领域自适应问题:源域标注数据多,目标域标注数据较少),领域自适应针对NER的相关研究不多,通常是对抗迁移[10]或特征迁移[11]。
在具体实践中,对抗&特征迁移通常还不如直接采取finetune方式(对源域进行预训练,在目标域finetune),特别是在后BERT时代。此外,在医疗领域,泛化迁移问题并不是一个容易解决的问题,试图去将NER做成一个泛化工具往往是困难的。或许我们更应该从业务角度出发去将NER任务定制化,而不是拘泥于那些无法落地的前沿技术。
Q11、如何让NER系统变得“透明”且健壮?
一个好的NER系统并不是“一竿子插到底”的黑箱算法。在医疗领域,实体类型众多,我们往往需要构建一套多层级、多粒度、多策略的NER系统。 例如:
- 多层级的NER系统更加“透明”,可以回溯实体的来源(利于医学实体消歧),方便“可插拔”地迭代优化;同时也不需要构建数目众多的实体类型,让模型“吃不消”。
- 多粒度的NER系统可以提高准召。如,第⼀步抽取⽐较粗粒度的实体,通过模型+规则+词典等多策略保证⾼召回;第⼆步进⾏细粒度的实体分类,通过模型+规则保证⾼准确。
Q12、如何解决低耗时场景下的NER任务?
笔者经验,重点应放在工程层面,而不是模型层面的压缩:
因为,从模型层面来看,1层lstm+CRF已经够快了
- 如果觉得lstm会慢,换成cnn或transformer也许更快一些,不过效果好不好要具体分析;通常来说,lstm对于NER任务的⽅向性和局部特征捕捉会好于别的编码器。
- 如果觉得crf的解码速度慢,引入label attention机制把crf拿掉,比如LAN这篇论文[12];当然可以⽤指针网络替换crf,不过指针网络收敛慢⼀些。
- 如果想进行模型压缩,比如对lstm+crf做量化剪枝也是⼀个需要权衡的⼯作,有可能费力不讨好~
lstm+crf已经够小了,对小模型进行压缩往往不如对大模型压缩更加健壮[13]。
从模型+工程层面来看,重点应放在如何在多层级的NER系统中进行显存调度、或者使当前层级的显存占用最大化等。
5.4 总结
我们要更加稳妥地解决复杂NER问题(词汇增强、冷启动、低资源、噪声、不平衡、领域迁移、可解释、低耗时),这是一个需要权衡的过程,切记不要盲目追前沿,很多脏活累活还是要干一干的。综上:
- 我们要在1层lstm+CRF的基础上,引入更丰富的embedding特征,并进行多策略组合,这大概率可以解决垂直领域的NER问题。
- 我们要更好地利用BERT、使其价值最大化。BERT虽好,可不要过度信任啊~
- 我们要更加稳妥地解决复杂NER问题(词汇增强、冷启动、低资源、噪声、不平衡、领域迁移、可解释、低耗时),这是一个需要权衡的过程,切记不要盲目追前沿,很多脏活累活还是要干一干的。
参考
- snips-nlu
- 2021-Recent Trends in Named Entity Recognition (NER)
- 2020- Survey on Deep Learning for Named Entity Recognition
- 2019-A survey on recent advances in named entity recognition from deep learning models
- 2018-Recognizing complex entity mentions: A review and future directions
- 2018-Recent named entity recognition and classification techniques: A systematic review
- 2013-Named entity recognition: fallacies, challenges and opportunities
- 2007-A survey of named entity recognition and classification
- NER相关数据集可以参考:SimmerChan/corpus
- 美团搜索中NER技术的探索与实践

若有收获,就点个赞吧
0 人点赞
