MAE
不少读者可能已经听说过何凯明最近提出的MAE(Masked Autoencoder)模型,它以一种简单高效的方式将MLM任务引入到图像的预训练之中,并获得了有效的提升。
MLM的介绍可以参考《2022-04-25-MLM(Masked Language Model)》
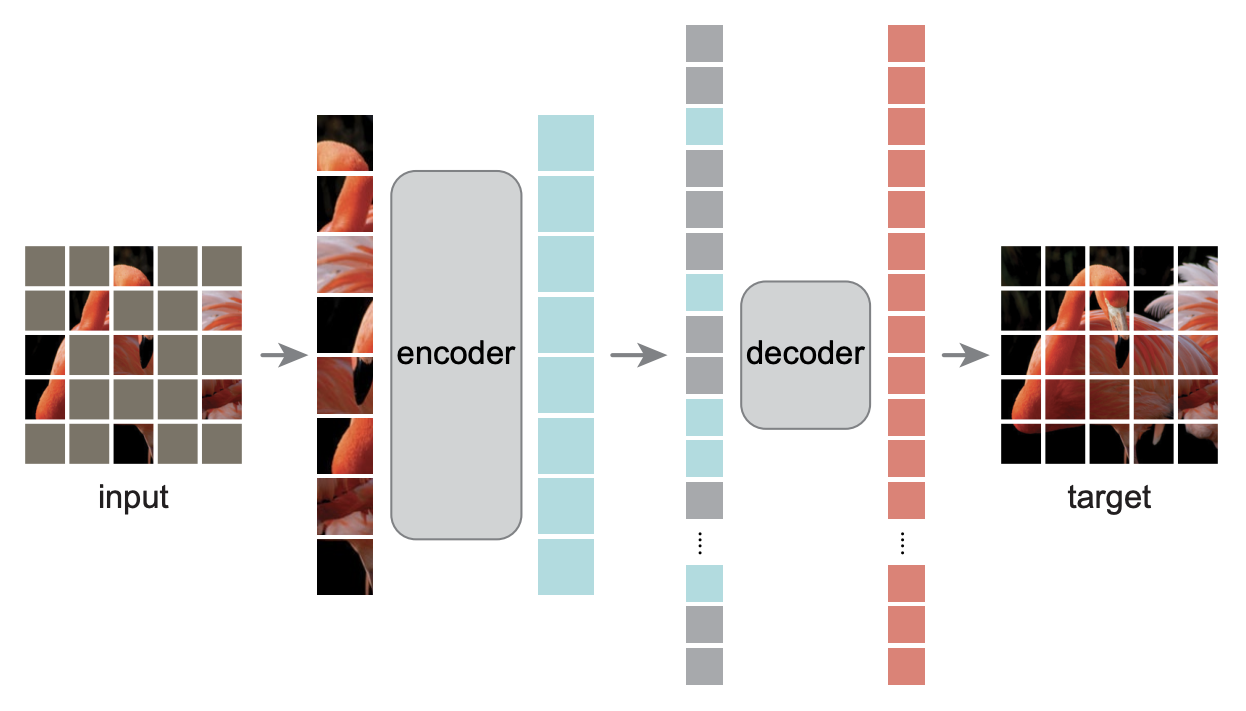
MAE模型示意图
what makes masked autoencoding different between vision and language \?
NLP领域的BERT提出的预训练方法本质上也是一种masked autoencoding:去除数据的一部分然后学习恢复。NLP领域已经在BERT之后采用这种方法在无监督学习上取得非常大的进展,比如目前已经可以训练超过1000亿参数的大模型,但是图像领域却远远落后,而且目前主流的无监督训练还是对比学习。那么究竟是什么造成了masked autoencoding方法在NLP和CV上的差异呢?MAE论文从三个方面做了分析,这也是MAE方法的立意:
结构: CNN天然适合图像领域,而应用Transformer却显得不那么自然,不过这个问题已经被ViT解了。再看上面几篇工作,会发现相比iGPT的马赛克、dVAE的离散化来说,patch形态是对信息损失最少且相对高效的。
信息密度: 人类的语言太博大精深了,你女朋友的每一句话,都有18层含义图片。而照片(ImageNet)不一样,它就那么多信息,两三个词就能概括。所以预测的时候,预测patch要比预测词语容易很多,只需要对周边的patch稍微有些信息就够了。所以我们可以放心大胆地mask。因此,在 CV 中,如果要使用 mask 这种玩法,就应该要 mask 掉图片中的较多的部分,这样才能使任务本身具有足够的挑战性,从而使模型学到良好的潜在特征表示。
3. 解码的目标不一致:CV 和 NLP 在解码器的设计上应该有不一样的考虑:NLP 解码输出的是对应被 mask 掉的词语,本身包含了丰富的语义信息;而 CV 要重建的是被 mask 掉的图像块(像素值),是低语义的。因此,NLP 的解码器可以很简单,比如 BERT,严格来说它并没有解码器,最后用 MLP 也可以搞定。因为来自编码器的特征也是高度语义的,与需要解码的目标之间的 gap 较小;而 CV 的解码器设计则需要“谨慎”考虑了,因为它要将来自编码器的高级语义特征解码至低级语义层级。
基于以上三点的自我分析(作者很入戏,估计还喝了口咖啡),灵感一来,MAE 就被 present 出来了。
MAE 的做法可以用一句话概述:以一定比例随机 mask 掉图片中的一些图像块(patch)然后重建这些部分的像素值。MAE 方法的特点主要有:高掩码率的随机 mask 策略(75%)、非对称的编、解码器设计 以及 重建的目标是像素值。
上面所述的“非对称”主要体现在 输入形式 与 网络结构 上:编码器(Encoder)仅对可见(unmasked)的图像块进行编码,而解码器(Decoder)的输入则是所有的图像块;同时具有“encoder深、decoder浅”的特点,即Decoder 可以是比较轻量的(比如 Encoder 通常是多层堆叠的 Transformer,而 Decoder 仅需较少层甚至1层就 ok)。这也表明 Encoder 与 Decoder 之间是解耦的。由于 Encoder 仅处理 unmasked 的 patch(占所有输入的少数),因此,尽管其本身网络结构比较重载,但依然能够高效训练,特别是对于大模型,能够加速3倍以上,同时配合较高的掩码率,还能够涨点。
Mask 策略
不同于 NLP,在 CV 中可能要配合较高的 mask 比例才能作为 “有效” 的自监督代理任务。“有效”指的是任务本身足够困难,这样模型才能学到有效的潜在特征表示。具体来说,首先,沿袭 ViT 的做法,将图像分成一块块(ViT 中是 16x16 大小)不重叠的 patch,然后使用服从均匀分布(uniform distribution) 的采样策略对这些 patches 随机采样一部分,同时 mask 掉余下的另一部分。被 mask 掉的 patches 占所有 patches 的大部分(实验效果发现最好的比例是 75\%),它们不会输入到 Encoder。
Encoder
记住最重要的一点,Encoder 仅处理可见(unmasked)的图像块 patches。Encoder 本身可以是 ViT 或 ResNet(其它 backbone 也 ok,就等你去实现了,大神给了你机会)
Decoder
Decoder 嘛..就别想着偷懒了,它不仅需要处理经过 Encoder 编码的 unmasked 的 tokens,还需要处理mask tokens。但请注意,mask token 并非由之前 mask 掉的 patch 经过 embedding 转换而来,而是可学习的、所有 masked patch 都共享的1个向量,对,仅仅就是1个!
那么你会问:这样如何区分各个 maked patch 所对应的 token 呢?别忘了,我们还有 position embedding 嘛…
任务目标:重建像素值
MAE 预训练任务的目标是重建像素值,并且仅仅是 masked patch 的像素值,也就是仅对 mask 掉的部分计算 loss,而 loss 就是很大众的 MSE。为何仅计算 mask 部分的 loss?实验结果发现这样做模型的性能会更好,而如果对所有 patches 都计算 loss 的话会掉点。
MAE 实战代码

若有收获,就点个赞吧
0 人点赞
