title: Python 最佳实践
subtitle: Python环境搭建&Flask项目架构&代码风格
date: 2020-06-19
author: NSX
catalog: true
tags:
- 技术
- 教程
Python 最佳实践
Python 日常使用的最佳实践,包括:
- 从Python的官方网站下载Python 3.7对应的或32位安装程序
- 然后,运行下载的exe安装包。特别要注意勾上
Add Python 3.7 to PATH,然后点“Install Now”即可完成安装。
底层虚拟环境 virtualenv
virtualenv 是一个 Python 项目依赖管理工具
建议在开发项目时使用virtualenv做依赖隔离,便于使用pip freeze自动生成requirements文件
通过 pip 安装 virtualenv :
$ pip install virtualenv$ virtualenv --version
为项目创建一个虚拟环境,名叫my_project:
$ cd my_project_folder$ virtualenv my_project
virtualenv 会创建一个文件夹,其中包含使用 Python 项目所有所需的可执行文件。
开始使用虚拟环境前,需要先激活:
$ source my_project/bin/activate # linux$ my_project\Scripts\activate # windows
安装包的话就与往常一样,如:
$ pip install XXX
如果你在虚拟环境中暂时完成了工作,可以这样停用它:
$ deactivate
为了保持环境的一致性,“冻结” 当前环境包的状态是正确的选择:
$ pip freeze > requirements.txt
该命令将创建一个 requirements.txt 文件,里面包含有当前环境所有包的简单列表及对应的版本,这样就能完全搭建出与之前一致的环境了:
$ pip install -r requirements.txt
这样有助于在跨设备,跨部署,跨人员的情况下保证环境的一致性。
最后,记得将虚拟环境文件夹从源代码控制中排除,也就是将其添加到 ignore 列表中 ( 详见 Version Control Ignores).
写出优雅的 Python 代码
结构化您的工程
工程化的项目目录具备让项目跑起来的所有基本内容。它里边会包含你的项目文件布局、自动化测试代码,模组,以及安装脚本。当你建立一个新项目的时候,只要把这个目录复制过去,改改目录的名字,再编辑里边的文件就行了。
“结构化”意味着通过编写简洁的代码,并且正如文件系统中文件和目录的组织一样, 代码应该具有逻辑和依赖清晰。
目的:为了防止各个模块的依赖混乱,一般通过模块划分,对Python项目进行结构化。之后,就只剩下架构性的工作,包括设计、实现项目各个模块,并整理清他们之间 的交互关系。
项目架构&仓库
简单的仓库结构模板: 可以在GitHub上找到 。
| 布局 | 作用 |
|---|---|
| README.rst | 项目介绍 |
| LICENSE | 许可证. 法律相关 |
| setup.py | 安装、部署、打包的脚本-分发管理 使用 python setup.py install安装 |
| requirements.txt | 项目所需的依赖库 |
| sample/init.py sample/core.py sample/helpers.py sample/setting.py sample/configs/ sample/data/ sample/static/ sample/templates/ |
初始化应用并组合所有其它组件 核心代码/具体代码 helpers 工具模块 setting 用来作变量和常量的初始化 configs 配置文件包 data 数据文件包 包括了公共CSS, Javascript等 放置应用的Jinja2模板 |
| docs/conf.py docs/index.rst |
项目的参考文档 |
| tests/ | 包的集合和单元测试 上下文环境的文件 context.py -方便测试导包 |
| Makefile | 通用的管理任务 |
Makefile 模板:
init:pip install -r requirements.txttest:py.test tests.PHONY: init test
setup.py 模板:
from setuptools import setup, find_packageswith open('README.rst') as f:readme = f.read()with open('LICENSE') as f:license = f.read()setup(name='slot-extract',version='0.1.0',description='龙小湖对话机器人-槽位提取服务',long_description=readme,author='Ning Shixian',author_email='',url='http://git.longhu.net/ningshixian/slot-extract',license=license,packages=find_packages(exclude=('tests', 'docs')))
单个文件结构

包
Python提供非常简单的包管理系统,即简单地将模块管理机制扩展到一个目录上(目录扩 展为包)。
任意包含 **__init__.py** 文件的目录都被认为是一个Python包。导入一个包里不同 模块的方式和普通的导入模块方式相似,特别的地方是 __init__.py 文件将集合 所有包范围内的定义。
模块
Python模块对应的是一个**.py** 文件,是最主要的抽象层之一。抽象层允许将代码分为 不同部分,每个部分包含相关的数据与功能。
例如在项目中,一层控制用户操作 相关接口,另一层处理底层数据 操作。最自然分开这两 层的方式是,在一份文件里重组所有功能接口,并将所有底层操作封装到另一个文件中。这种情况下,接口文件需要导入封装底层操作的文件,可通过 import 和 from ... import 语句完成。一旦您使用 import 语句,就可以使用这个模块。
类
包含函数、变量。类中有属性和方法。一个对象就是一个类的实例。
可变和不可变类型
Python提供两种内置或用户定义的类型。数字、字符串、元组是不可变的,列表、字典是可变的。
对不可变类型的变量重新赋值,实际上是重新创建一个不可变类型的对象,并将原来的变量重新指向新创建的对象(如果没有其他变量引用原有对象的话(即引用计数为0),原有对象就会被回收)。
字符串是不可变类型。这意味着当需要组合一个 字符串时,将每一部分放到一个可变列表里,使用字符串时再组合 (‘join’) 起来的做法更高效。
差
# 创建将0到19连接起来的字符串 (例 "012..1819")nums = ""for n in range(20):nums += str(n) # 慢且低效print nums
好
# 创建将0到19连接起来的字符串 (例 "012..1819")nums = [str(n) for n in range(20)]print "".join(nums)
函数的参数
函数的参数可以使用四种不同的方式传递给函数。
- 必选参数 是没有默认值的必填的参数
point(x, y) - 关键字参数 是非强制的,且有默认值
point(x, y, z=None) - 任意参数列表 如果函数的参数数量是动态的,该函数可以被定义成
*args的结构send(message, *args) - 任意关键字参数字典 如果函数要求一系列待定的命名参数,我们可以使用
**kwargs的结构。在函数体中, kwargs 是一个字典,它包含所有传递给函数但没有被其他关键字参数捕捉的命名参数
返回值
当一个函数在其正常运行过程中有多个主要出口点时,它会变得难以调试其返回结果,所以保持单个出口点可能会更好。
def complex_function(a, b, c):if not a:return None # 抛出一个异常可能会更好if not b:return None # 抛出一个异常可能会更好# 一些复杂的代码试着用 a,b,c 来计算x# 如果成功了,抵制住返回 x 的诱惑if not x:# 使用其他的方法来计算出 xreturn x # 返回值 x 只有一个出口点有利于维护代码
pythonic风格
代码风格:
- 每个缩进层级使用4个空格
- 每行最多79个字符
- 顶层函数或类的定义之间空两行(特别容易漏,漏的话,是报E302 expected 2 blank lines, found 1)
- 采用ASCII或者UTF-8编码文件
- 每条import导入一个模块,导入放在代码顶端,导入顺序是先标准库,第三方库,本地库
- 小括号,大括号,中括号之间的逗号没有额外的空格
- 类命名采用骆驼命名法,CamelCase;函数用小写字符
- 函数命名使用小写字符,例如xxx_xxx_xxx; 用下划线开头定义私有的属性或方法,如_xxx
命名风格:
- 类名使用 UpperCamelCase 风格,必须遵从驼峰形式,如:XmlService
- 方法名、参数名、成员变量、局部变量都统一使用 lowerCamelCase 风格,必须遵从驼峰形式:localValue / getHttpMessage()
- 常量命名全部大写,单词间用下划线隔开
- 包名统一使用小写、单数、_
- 命名时,使用尽量完整的单词组合来表达其意
- 方法命名规约:
1) 获取单个对象的方法用 get 做前缀。
2) 获取多个对象的方法用 list 做前缀。
3) 获取统计值的方法用 count 做前缀。
4) 插入的方法用 save/insert 做前缀。
5) 删除的方法用 remove/delete 做前缀。
6) 修改的方法用 update 做前缀。 - 异常处理
对大段代码进行 try-catch,这是不负责任的表现。
捕获异常是为了处理它,不要捕获了却什么都不处理而抛弃之
finally 块必须对资源对象、流对象进行关闭
日志文件推荐至少保存 15 天 单元测试
保证测试粒度足够小,方法级别
必须使用 assert 来验证
编写单元测试代码遵守 BCDE 原则,以保证被测试模块的交付质量B: Border,边界值测试,包括循环边界、特殊取值、特殊时间点、数据顺序等。C: Correct,正确的输入,并得到预期的结果。D: Design,与设计文档相结合,来编写单元测试。E: Error,强制错误信息输入(如:非法数据、异常流程、非业务允许输入等),并得到预期的结果。
MySQL 数据库
表达是与否概念的字段,必须使用 isxxx 的方式命名,数据类型是 unsigned tinyint
表名、字段名必须使用小写字母或数字,如:aliyun_admin
小数类型为 decimal,禁止使用 float 和 double
varchar 是可变长字符串,不预先分配存储空间
表必备三字段: id, gmt_create, gmt_modified
表的命名最好是加上“业务名称表的作用”
阅读优质的代码
- Howdoi Howdoi 使用 Python 实现的代码搜索工具。
- Flask Flask 是基于 Werkzeug and Jinja2 的 Python 微框架。 它的目的是快速入门并开发实现你头脑中的好主意。
- Diamond Diamond 是使用 python 实现的用于收集监控数据的工具,主要收集 metrics 类型的数据,并将其发布到 Graphite 或其他后台。它能够收集 cpu , 内存, 网络, i/o ,负载和磁盘 metrics 数据。此外,它还提供 API 用以实现自定义收集器从任意来源中收集指标数据。
- Werkzeug Werkzeug 最初是 WSGI 应用程序的各种实用工具的简单集合,并已成为最先进的 WSGI 实用程序模块之一。它包括强大的调试器、功能齐全的请求和响应对象、处理实体标记的 HTTP 实用程序、缓存控制头、HTTP 日期、cookie 处理、文件上传、强大的 URL 路由系统和一群社区贡献的插件模块。
- Requests Requests 是一个用 Python 实现的 Apache2 授权的 HTTP 库供大家使用。
- Tablib 是用 Python 实现的无格式的表格数据集库。
项目文档
建议提供相关函数的更多信息,包括它是做什么的, 所抛的任何异常,返回的内容或参数的相关细节。
通常称为 Numpy style Docstrings
代码测试
py.test 测试工具功能完备,并且可扩展,语法简单
$ pip install pytest$ pytest tests.py
日志记录
日志记录一般有两个目的:
- 诊断日志 记录与应用程序操作相关的日志。例如,当用户遇到程序报错时, 可通过搜索诊断日志以获得上下文信息。
- 审计日志 为商业分析而记录的日志。从审计日志中,可提取用户的交易信息, 并结合其他用户资料构成用户报告,或者用来作为优化商业目标的数据支撑。
Python的logging模块提供了通用的日志系统,包括logger,handler,filter,formatter这四个方法:
- logger提供日志接口,供应用代码使用。
logger最长用的操作有两类:配置和发送日志消息。可以通过logging.getLogger(name)获取logger对象,如果不指定name则返回root对象,多次使用相同的name调用getLogger方法返回同一个logger对象。 - handler
将日志记录(log record)发送到合适的目的地(destination),比如文件,socket等。一个logger对象可以通过addHandler方法添加0到多个handler,每个handler又可以定义不同日志级别,以实现日志分级过滤显示。 - filter
提供一种优雅的方式决定一个日志记录是否发送到handler。 - formatter
指定日志记录输出的具体格式。formatter的构造方法需要两个参数:消息的格式字符串和日期字符串,这两个参数都是可选的。
总的一个逻辑是这样的,我们需要创建一个logger,这样在代码执行中,可以使用logger.debug/info/warning/error等方法,将日志输出到指定的位置(可以是控制台、文件,可多选);创建logger之后,需要给logger添加处理句柄addHandler(),每个句柄就对应一种输出,比如StreamHandler表示输出到控制台(当然我这里简单化了),FileHandler输出到指定文件。然后给句柄设置格式Format,这就是你想要看见的格式。
1. logger的定义
Logging.Logger:Logger是Logging模块的主体,进行以下三项工作:
- 为程序提供记录日志的接口
- 判断日志所处级别,并判断是否要过滤
- 根据其日志级别将该条日志分发给不同handler
常用函数有:Logger.setLevel()设置日志级别Logger.addHandler()和Logger.removeHandler()添加和删除一个HandlerLogger.addFilter()添加一个Filter,过滤作用
2. handler的使用
所有的handler汇总,按需自取
StreamHandler:logging.StreamHandler;日志输出到流,可以是sys.stderr,sys.stdout或者文件FileHandler:logging.FileHandler;日志输出到文件BaseRotatingHandler:logging.handlers.BaseRotatingHandler;基本的日志回滚方式RotatingHandler:logging.handlers.RotatingHandler;日志回滚方式,支持日志文件最大数量和日志文件回滚TimeRotatingHandler:logging.handlers.TimeRotatingHandler;日志回滚方式,在一定时间区域内回滚日志文件SocketHandler:logging.handlers.SocketHandler;远程输出日志到TCP/IP socketsDatagramHandler:logging.handlers.DatagramHandler;远程输出日志到UDP socketsSMTPHandler:logging.handlers.SMTPHandler;远程输出日志到邮件地址SysLogHandler:logging.handlers.SysLogHandler;日志输出到syslogNTEventLogHandler:logging.handlers.NTEventLogHandler;远程输出日志到Windows NT/2000/XP的事件日志MemoryHandler:logging.handlers.MemoryHandler;日志输出到内存中的指定bufferHTTPHandler:logging.handlers.HTTPHandler;通过"GET"或者"POST"远程输出到HTTP服务器
3. Formater的使用
format:指定输出的格式和内容,format可以输出很多有用的信息
参数:作用%(levelno)s:打印日志级别的数值%(levelname)s:打印日志级别的名称%(pathname)s:打印当前执行程序的路径,其实就是sys.argv[0]%(filename)s:打印当前执行程序名%(funcName)s:打印日志的当前函数%(lineno)d:打印日志的当前行号%(asctime)s:打印日志的时间%(thread)d:打印线程ID%(threadName)s:打印线程名称%(process)d:打印进程ID%(message)s:打印日志信息
举个例子
console_fmt = '%(asctime)-15s [%(TASK)s] %(message)s'console_formatter = logging.Formatter(console_fmt)
4. Level级别
level:设置日志级别,默认为logging.WARNNING;
可以给logger和handler设置不同的级别,比如logger设置为debug,然后handler1设置为error,这样这个输出只会记录error以上的日志级别信息,另一个handler2设置为info,记录info级别以上的信息。有下面这几种可以设置
日志等级:使用范围FATAL:致命错误CRITICAL:特别糟糕的事情,如内存耗尽、磁盘空间为空,一般很少使用ERROR:发生错误时,如IO操作失败或者连接问题WARNING:发生很重要的事件,但是并不是错误时,如用户登录密码错误INFO:处理请求或者状态变化等日常事务DEBUG:调试过程中使用DEBUG等级,如算法中每个循环的中间状态NOTSET:如果设置了日志级别为NOTSET,那么这里可以采取debug、info的级别的内容也可以显示在控制台上了
示例代码
import loggingimport auxiliary_module# 创建名为'spam_application'的记录器logger = logging.getLogger('spam_application')logger.setLevel(logging.DEBUG)# 创建级别为DEBUG的日志处理器fh = logging.FileHandler('spam.log')fh.setLevel(logging.DEBUG)# 创建级别为ERROR的控制台日志处理器ch = logging.StreamHandler()ch.setLevel(logging.ERROR)# 创建格式器,加到日志处理器中formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')fh.setFormatter(formatter)ch.setFormatter(formatter)logger.addHandler(fh)logger.addHandler(ch)logger.debug('debug message')logger.info('info message')logger.warn('warn message')logger.error('error message')logger.critical('critical message')
配置文件和数据
- 如框架无特殊规定,配置文件应放置于项目根目录下的
**config**文件夹中 - 配置文件在部署、预发布、生产环境、开发环境等环境中会有很大差异,因此请不要将配置文件在上传到git、svn等版本库中, 而是建议在版本库中上传一个配置的示例文件(如:config.example)
- 上传到版本库中配置示例文件不允许出现密码、证书、token等敏感信息
- 数据和程序应该尽量分离,不要将数据写在代码中,需要持久化存储数据必须使用数据库
python 有用的内置库
100 Helpful Python Tips You Can Learn Before Finishing Your Morning Coffee
itertools-迭代器工具
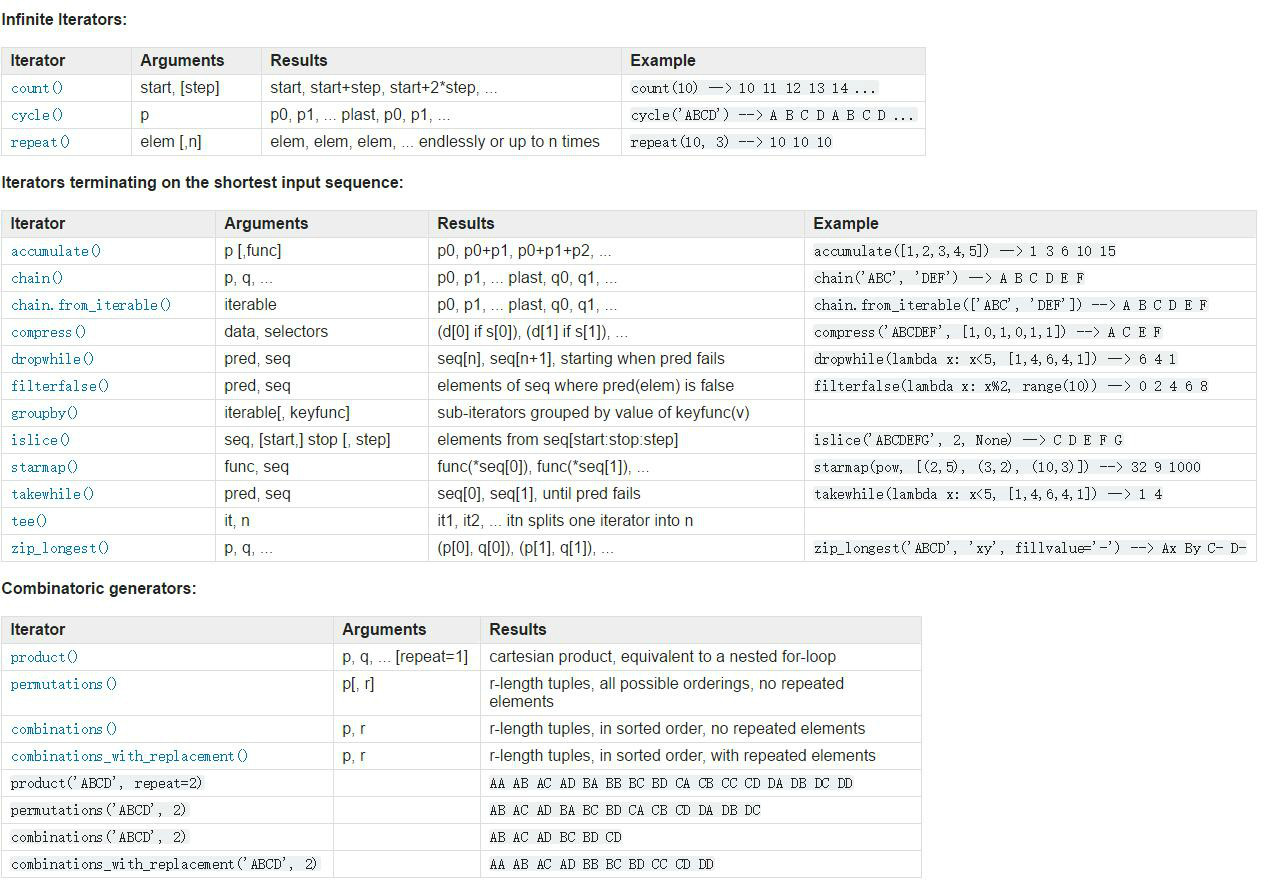
- permutations(iterable,r=None) 表示从 n 个不同元素中拿出 r 个元素的排列结果,
 ;
```python
import itertools
for i in itertools.permutations(‘abc’):
print(i)
;
```python
import itertools
for i in itertools.permutations(‘abc’):
print(i)
(‘a’, ‘b’, ‘c’) (‘a’, ‘c’, ‘b’) (‘b’, ‘a’, ‘c’) (‘b’, ‘c’, ‘a’) (‘c’, ‘a’, ‘b’) (‘c’, ‘b’, ‘a’)
当然,第 2 个参数默认为None,它表示的是返回元组(tuple) 的长度,我们来尝试一下传入第二个参数。```pythonimport itertoolsfor i in itertools.permutations('abc',2):print(i)('a', 'b')('a', 'c')('b', 'a')('b', 'c')('c', 'a')('c', 'b')
- combinations(iterable,r) 表示从 n 个不同元素中拿出 r 个元素的组合结果,
 。「排列」和「组合」的主要区别在于是否考虑顺序的差异,组合结果不重复。
```python
import itertools
for i in itertools.combinations(‘1234’,2):
print(i)
。「排列」和「组合」的主要区别在于是否考虑顺序的差异,组合结果不重复。
```python
import itertools
for i in itertools.combinations(‘1234’,2):
print(i)
(‘1’, ‘2’) (‘1’, ‘3’) (‘1’, ‘4’) (‘2’, ‘3’) (‘2’, ‘4’) (‘3’, ‘4’)
- **combinations_with_replacement(iterable, r)** 与combinations区别就是同一元素可以使用多次```pythonimport itertoolsfor i in itertools.combinations_with_replacement('1234',2):print(i)('1', '1')('1', '2')('1', '3')('1', '4')('2', '2')('2', '3')('2', '4')('3', '3')('3', '4')('4', '4')
- accumulate(iterable [,func]) 前缀和计算,结果是一个迭代器,func默认函数为求和函数
- 适用于快速计算一个索引区间内的元素之和 ```python import itertools for i in itertools.accumulate([0,1,0,1,1,2,3,5]): print(i)
0 1 1 2 3 5 8 13
- **product(*iterables, repeat=1)** **可以说是combinations的升级版,对多个序列进行组合,且无重复,**得到的是可迭代对象的笛卡儿积。*iterables参数表示需要多个可迭代对象。这些可迭代对象之间的笛卡儿积,也可以使用for循环来实现,例如 **product(A, B)** 与 **((x,y) for x in A for y in B)**就实现一样的功能。```pythonlist1=[1,2,3]list2=[4,5]list3=['a']for i in itertools.product(list1,list2,list3):print(i)#结果:(1, 4, 'a')(1, 5, 'a')(2, 4, 'a')(2, 5, 'a')(3, 4, 'a')(3, 5, 'a')
- zip_longest:对多个数据按索引进行组合,并根据迭代对象的大小,不足使用fillvalue默认值替代 ```python a=[1,2,3] b=[‘a’,’b’]
for i in zip_longest(a,b,fillvalue=”nihao”): print(i) for i in zip(a,b): print(i)
结果对比:
zip_lengest: zip: (1, ‘a’) (1, ‘a’) (2, ‘b’) (2, ‘b’) (3, ‘nihao’)
<a name="wDVjg"></a>## heapq-堆> 默认是最小堆,也叫优先队列> 参考 [https://zhuanlan.zhihu.com/p/138834830](https://zhuanlan.zhihu.com/p/138834830)- heapify(heap):对序列进行堆排序- heappush(heap, x):在堆序列中添加值- heappop(heap):从堆中弹出(删除)最小值并返回- heappushpop(heap, x):将 x 压入堆中,然后弹出最小元素(添加之后删除)- heapreplace(heap, x):弹出最小元素,并将 x 压入堆中- nlargest(n, iterable, key=None) :返回 iter 中最大的 n 个元素- nsmallest(n, iterable, key=None):返回 iter 中最小的 n 个元素**heappush,heappop,heapify,heapreplace,heappushpop**<br />**堆结构特点:heap[0]永远是最小的元素**(利用此特性排序)```pythonnums=[54,23,64.,323,53,3,212,453,65]heapify(nums) #先进行堆排序print(heappop(nums)) #3print(heappush(nums,50)) #添加操作,返回Noneprint(heappushpop(nums,10)) #由于是添加后删除,所以返回10print(heappop(nums)) #23print(heapreplace(nums,10)) #和heappushpop,返回50print(nums) #[10, 53, 54, 65, 323, 64.0, 212, 453]
nlargest与nsmallest
import heapqnumbers = [1, 4, 2, 100, 20, 50, 32, 200, 150, 8]print(heapq.nlargest(4, numbers))# 输出:[200, 150, 100, 50]people = [{'firstname': 'John', 'lastname': 'Doe', 'age': 30},{'firstname': 'Jane', 'lastname': 'Doe', 'age': 25},{'firstname': 'Janie', 'lastname': 'Doe', 'age': 10},{'firstname': 'Jane', 'lastname': 'Roe', 'age': 22},{'firstname': 'Johnny', 'lastname': 'Doe', 'age': 12},{'firstname': 'John', 'lastname': 'Roe', 'age': 45}]#使用了key参数,利用匿名函数将key指定为每个字典元素的age属性youngest = heapq.nsmallest(2, people, key=lambda s: s['age'])print(youngest)# 输出: [{'firstname': 'Janie', 'age': 10, 'lastname': 'Doe'}, {'firstname': 'Johnny', 'age': 12,'lastname': 'Doe'}]
collections-更丰富的数据类型
collections模块实现一些特定的数据类型,可以替代Python中常用的内置数据类型如dict, list, set, tuple,简单说就是对基本数据类型做了更上一层的处理,包括:
- deque:list-like容器,两端都有快速追加和弹出类
- defaultdict:多值字典
- Counter:计数器,在底层中为一个字典
- OrderedDict:保持元素被插入的顺序,结构是一个双向链表
- ChainMap:合并多个字典
collections.deque 双向队列
双端队列,头部和尾部都能以O(1)时间复杂度插入和删除元素。类似于列表的容器。与Python内置的list区别在于:头部插入与删除的时间复杂度为O(1)。代码示例:
from collections import dequea=deque("str")a.appendleft("a") #在头部插入数据a.append("b") #在尾部插入数据>>> a #deque(['a', 's', 't', 'r', 'b'])a.popleft() # 队首出列a.pop() # 队尾出列>>> a #deque(['s', 't', 'r'])a.count("a") #查看字符出现的次数a.insert(2,"y") #根据索引插入值>>> a #deque(['s', 't', 'y', 'r'])a.reverse() # 队列反转>>> a #deque(['r', 'y', 't', 's'])a.rotate(2) # 队列轮转>>> a #deque(['t', 's', 'r', 'y'])a.clear() #清空双端队列
collections.defaultdict
带有默认值的字典。父类为Python内置的dict。字典带默认值有啥好处?举个栗子,一般来讲,创建一个多值映射字典是很简单的。但是,如果你选择自己实现的话, 那么对于值的初始化可能会有点麻烦。
collections.OrderedDict 有序字典
OrderedDict类在迭代操作的时候会保持元素被插入时的顺序,这样一个哈希链表在查找、增删操作上具有O(1)时间复杂度,可以用于实现 LRU/LFU 缓存机制!
其背后实现就是一个哈希链表。哈希链表是哈希表和双向链表的结合体,哈希表的每一个位置存放的实际上是一个链表的节点,这些节点又通过首尾相连形成双向链表。
需要注意的是,一个OrderedDict的大小是一个普通字典的两倍,因为它内部维护着另外一个链表。 所以如果你要构建一个需要大量OrderedDict 实例的数据结构的时候(比如读取100,000行CSV数据到一个 OrderedDict 列表中去),那么你就得仔细权衡一下是否使用 OrderedDict带来的好处要大过额外内存消耗的影响。
参数说明:
- popitem(last=True):
该方法返回并删除一对键值.如果last为True(默认值),则为LIFO(后进先出);否则为FIFO(先进先出).
- move_to_end(key, last=True):
将现有的key移到字典的一端.如果last为True(默认值),移动到末尾(最新加入的元素);否则,移动到开头(最早加入的元素).
from collections import OrderedDictod=OrderedDict([("name","jim"),("age",19),("sex","男")])od.setdefault("high",178) #添加一组数据,或者使用od["high"]=178# OrderedDict([('name', 'jim'), ('age', 19), ('sex', '男'), ('high', 175)])od.move_to_end('name') #将name组放置末尾# OrderedDict([('age', 19), ('sex', '男'), ('high', 175), ('name', 'jim')])od.popitem(last=False)# OrderedDict([('sex', '男'), ('high', 175), ('name', 'jim')])for i in od.items():print(i)
Counter 计数器,在底层中为一个字典
用途:统计可哈希的对象,寻找序列中出现次数最多的元素。假设你有一个单词列表并且想找出哪个单词出现频率最高,代码如下:
from collections import Counterwords = ['look', 'into', 'my', 'eyes', 'look', 'into', 'my', 'eyes','the', 'eyes', 'the', 'eyes', 'the', 'eyes', 'not', 'around', 'the','eyes', "don't", 'look', 'around', 'the', 'eyes', 'look', 'into','my', 'eyes', "you're", 'under']word_counts = Counter(words)# 出现频率最高的三个单词top_three = word_counts.most_common(3)print(top_three)# Outputs [('eyes', 8), ('the', 5), ('look', 4)]print(word_counts['eyes']) # 8
ChainMap:合并多个字典
dict1={'name':'jim','age':21}dict2={'high':175,'gender':'男'}new_dict=ChainMap(dict1,dict2)print(new_dict) #ChainMap({'name': 'jim', 'age': 21}, {'high': 175, 'gender': '男'})#前dict中存在的键值对将会使后面dict中的键值对不会被重新合并,也可以使用update()方法对原字典更新新字典到里面,不过和直接合并的区别是,update会重新创建新字典,原字典更新删除数据不会影响新字典# 快速字典合并merged = {**dict1, **dict2}print(merged) # {'name': 'jim', 'age': 21, 'high': 175, 'gender': '男'}
其他
global:global 是python中的一个关键字,作用在变量上,用来声明该变量为全局变量。
# 例如下面变量a,定义在函数外面的是全局变量a,定义在fun函数里面的a是另一个a,是局部变量a,两者没有任何关系。好比这个地区有个叫张三的人,公办室里有个另一个叫张三的人。他们是两个不同的人a = 10def fun():a = 2fun()print(a) # 输出 10# 如果想要函数里面的那个a就代表外面的全局变量a,那么就要将函数里面的a 用关键字 global 声明为全局变量a = 10def fun():global aa = 2fun()print(a) # 输出 2
ast:Convert a string into a list of strings
import astdef string_to_list(string):return ast.literal_eval(string)string = "[[1, 2, 3],[4, 5, 6]]"my_list = string_to_list(string)print(my_list) # [[1, 2, 3], [4, 5, 6]]
== vs. is
- “is” checks whether 2 variables are pointing to the same object in memory.
- “==” compares the equality of values that these 2 objects hold. ```python first_list = [1, 2, 3] second_list = [1, 2, 3]
Is their actual value the same?
print(first_list == second_list) # True
Are they pointing to the same object in memory
print(first_list is second_list)
False, since they have same values, but in different objects in memory
third_list = first_list
print(third_list is first_list)
True, since both point to the same object in memory
**快速字典合并**```pythondictionary_one = {"a": 1, "b": 2}dictionary_two = {"c": 3, "d": 4}merged = {**dictionary_one, **dictionary_two}print(merged) # {'a': 1, 'b': 2, 'c': 3, 'd': 4}
参考
Python 最佳实践指南 2018
必须知道的collections模块
python之排序操作及heapq模块
itertools模块超实用方法

若有收获,就点个赞吧
0 人点赞
