Boosting 要点
- 提升方法是将弱学习算法提升为强学习算法的统计学习方法。在分类学习中,提升方法通过反复修改训练数据的权值分布,构建一系列基本分类器(弱分类器),并将这些基本分类器线性组合,构成一个强分类器。代表性的提升方法是AdaBoost算法。
- AdaBoost算法的特点是通过迭代每次学习一个基本分类器。每次迭代中,提高那些被前一轮分类器错误分类数据的权值,而降低那些被正确分类的数据的权值。最后, AdaBoost将基本分类器的线性组合作为强分类器,其中给分类误差率小的基本分类器以大的权值,给分类误差率大的基本分类器以小的权值。
- AdaBoost的训练误差分析表明,AdaBoost的每次迭代可以减少它在训练数据集上的分类误差率,这说明了它作为提升方法的有效性。
- AdaBoost算法的一个解释是该算法实际是前向分步算法的一个实现。在这个方法里,模型是加法模型,损失函数是指数损失,算法是前向分步算法。每一步中极小化损失函数得到参数βm , m 。
- 提升树是以分类树或回归树为基本分类器的提升方法。提升树被认为是统计学习中最有效的方法之一。

Bagging 要点
Bagging 方法在训练过程中各基分类器之间无强依赖,可以进行并行训练。为了 让基分类器之间互相独立,训练集分为若干子集,最终做决策时,每个个体单独作出判断,再通过投票的方式做出最后的集体决策 。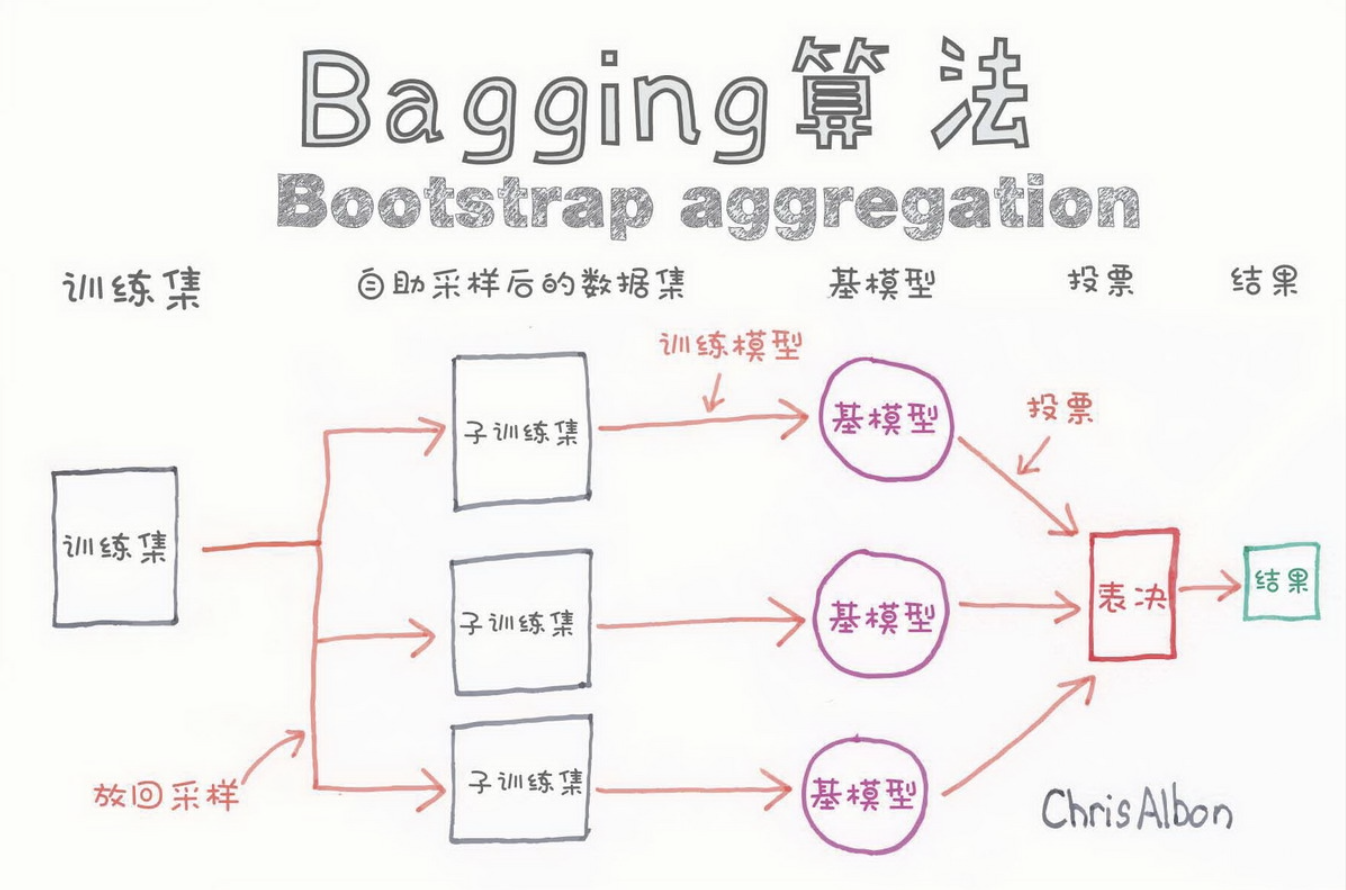
AdaBoost基本概念


对提升方法来说,有两个问题需要回答:
- 在每一轮如何改变训练数据的权值或概率分布
AdaBoost的做法是,提高那些被前一轮弱分类器错误分类样本的权值,而降低那些被正确分类样本的权值。 这样一来,那些没有得到正确分类的数据,由于其权值的加大而受到后一轮的弱分类器的更大关注。于是,分类问题被一系列的弱分类器“分而治之”。
- 如何将弱分类器组合成一个强分类器。
AdaBoost采取加权多数表决的方法。具体地,加大分类误差率小的弱分类器的权值, 使其在表决中起较大的作用,减小分类误差率大的弱分类器的权值,使其在表决中起较小的作用。
Adaboost算法

输入:训练数据集 ;弱学习方法;
;弱学习方法;
输出:最终分类器#card=math&code=G%28x%29&id=JkMqf)
训练步骤:
- 初始化训练数据的权值分布

- 对m个弱分类器

- 使用具有权值分布
 的训练数据集学习,得到基本分类器
的训练数据集学习,得到基本分类器
- 使用具有权值分布

计算
在训练集上的分类误差率
%5Cne%20yi)%3D%5Csum%7Bi%3D1%7D%5E%7BN%7Dw%7Bmi%7DI(G_m(x_i)%5Cne%20y_i)#card=math&code=e_m%3D%5Csum%7Bi%3D1%7D%5E%7BN%7DP%28Gm%28x_i%29%5Cne%20y_i%29%3D%5Csum%7Bi%3D1%7D%5E%7BN%7Dw_%7Bmi%7DI%28G_m%28x_i%29%5Cne%20y_i%29&id=zPVIK)
计算
#card=math&code=G_m%28x%29&id=ehcaw)的系数
- 更新训练数据集的权值分布

)%E2%80%8B#card=math&code=w%7Bm%2B1%2Ci%7D%3D%5Cfrac%7Bw%7Bmi%7D%7D%7BZm%7Dexp%28-%5Calpha_my_iG_m%28x_i%29%29%E2%80%8B&id=EaV0E)
这里, 是规范化因子
是规范化因子
)#card=math&code=Z_m%3D%5Csum%7Bi%3D1%7D%5ENw_%7Bmi%7Dexp%28-%5Calpha_my_iG_m%28x_i%29%29&id=QTbnB)
- 构建基本分类器的线性组合
%3D%5Csum%7Bm%3D1%7D%5EM%5Calpha_mG_m(x)#card=math&code=f%28x%29%3D%5Csum%7Bm%3D1%7D%5EM%5Calpha_mG_m%28x%29&id=cDGK5)
- 得到最终分类器
%3Dsign(f(x))%3Dsign(%5Csum%7Bm%3D1%7D%5EM%5Calpha_mG_m(x))#card=math&code=G%28x%29%3Dsign%28f%28x%29%29%3Dsign%28%5Csum%7Bm%3D1%7D%5EM%5Calpha_mG_m%28x%29%29&id=tldZS)

若有收获,就点个赞吧
0 人点赞
