0. 背景故事
我最近的一个项目中需要大量查询一个词的相似词,而无论是英文的WordNet,还是中文的同义词词林,都覆盖面太窄,我决定借助训练好的Word2Vec模型,使用gensim库,调用它经典的.most_similar()函数来进行相似词查询。而由于程序中需要大量查询相似词,所以就需要大量调用.most_similar()函数,而这,就成为了整个程序的瓶颈,因为:
.most_similar()太慢了!
为什么它这么慢呢?因为这个gensim中查询相似词,默认是直接brute-force search,即我会把当前查询的词,跟词表里所有的词都计算一个相似度,然后给你排序返回。如果词典很大,词向量维度又很高,那这个计算代价是很大的!我还特地看了看gensim的源码(gensim/gensim/models/keyedvectors.py#L783):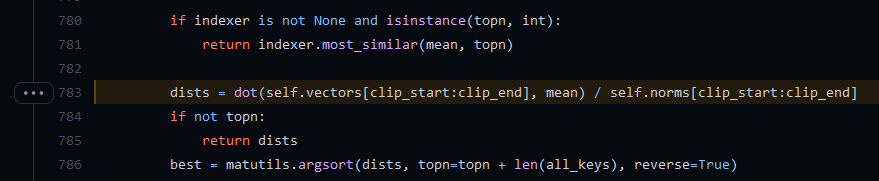
可看到,这个.most_similar()函数内部,就是通过对当前向量(代码中的mean)去跟所有的vectors计算dot product,然后再排序返回。
另外,虽然我们可以在每次跑程序的时候都维护一个词典,查询过的结果就直接保存,这对于当前程序是可以提升效率的,但是我之后再次运行程序,或者语料库改变了,那依然需要重新计算,所以必须想办法解决一下。
1. 想一劳永逸,那就把Word2Vec变成一个相似词词典
一个很直接的思路就是,既然我使用Word2Vec是为了查相似词,其他的功能不需要(比如我不需要获取向量),那么我可以把一个Word2Vec词向量模型,转化成一个相似词词典,这样通过一个现成的词典查询相似词,就比使用.most_similar()快得多了!
于是我开开心心得写下了如下代码(针对一个100维,40万词的中文词向量):
from gensim.models.keyedvectors import KeyedVectorsfrom tqdm import tqdm# synonyms_words.vector为一个100维的中文词向量模型w2v_model = KeyedVectors.load_word2vec_format("weights/synonyms_words.vector", binary=True, unicode_errors='ignore')# 获取该词向量的词汇表vocab = w2v_model.index_to_key# 把所有词遍历一遍,查询最相似的15个词,并保存到词典similars_dict = {}for w in tqdm(vocab):similar_words = [pair[0] for pair in w2v_model.most_similar(w, topn=15, indexer=indexer)]similars_dict[w] = similar_words
运行,耗时2小时20分钟。 基本上就是出去吃个晚饭,散个步,就跑完了,so easy~
心想着,后面直接把项目程序中所有的.most_similar(w),都替换成similars_dict[w],速度直接起飞~舒服!
(本文结束)
…
2. 问题来了…
我本来确实以为就这么结束了,直到我对一个英文Word2Vec模型重复了上面的操作:
from gensim.models.keyedvectors import KeyedVectorsfrom tqdm import tqdm# GoogleNews-vectors-negative300.bin为一个300维的英文词向量模型w2v_model = KeyedVectors.load_word2vec_format("weights/GoogleNews-vectors-negative300.bin", binary=True, unicode_errors='ignore')# 获取该词向量的词汇表vocab = w2v_model.index_to_key# 把所有词遍历一遍,查询最相似的15个词,并保存到词典similars_dict = {}for w in tqdm(vocab):similar_words = [pair[0] for pair in w2v_model.most_similar(w, topn=15, indexer=indexer)]similars_dict[w] = similar_words
给大家看看进度条:
预计用时150小时!天哪,为什么差别这么大?
原来我前面那么轻松,是因为使用了一个较小的词向量模型:
- 100维,40万词——> 2小时 (一次健身的时间)
- 300维,300万词——> 150小时(你可以去度一个假了,回来应该可以跑完吧)
我还试着用了一个线程池,发现依然需要80~100小时…
怎么办?
一看时间,已经8:00 PM了,开启多线程让这玩意儿跑着吧,明早过来看看能跑多少吧,溜了溜了~
3. Approximate Nearest Neighbors Oh Yeah ! (Annoy)
第二天中午来到实验室,打开电脑一看,跑了50万了,还有250万没跑完… 摸一摸主机,已经滚烫了,我的8核CPU哼哧哼哧了一晚上才跑了1/5的词,现在一定怨声载道了…
我果断kill掉了程序,看着任务管理器缓缓下降的CPU利用率曲线,我和CPU们都进入了贤者时间。
之前也了解过ANN算法,即近似最近邻算法,于是我开始在Google上搜索有关ANN和gensim的内容,终于,找到了这篇文章的主角——Annoy,而且我发现,gensim其实已经对Annoy做了封装,支持使用Annoy来进行加速。
Annoy算法,是一种基于二叉树的近似最近邻算法,他的全称是:Approximate Nearest Neighbors Oh Yeah,别的不说,这个Oh Yeah直接让我对这个算法好感倍增。下面看看Annoy自己的介绍: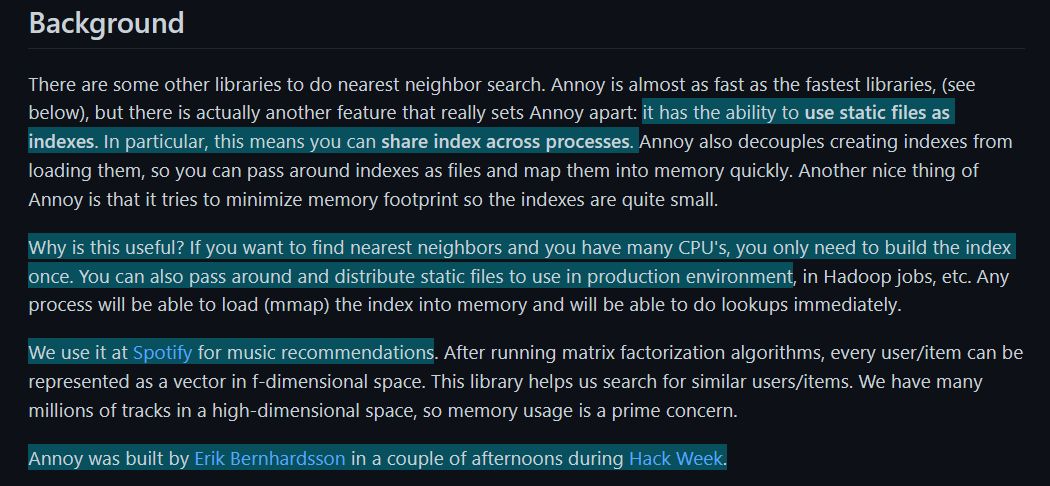
看最后一句话:
Annoy算法是Erik这个老哥,在Spotify的Hack Week期间,花了几个下午的时候开发的。
你都可以想想那个场景,Erik在阳光的午后,边喝咖啡,边写代码,构思着一个巧妙的ANN算法,几天后他做到了,成功地发明了一种新的ANN算法,他高呼”Oh Yeah!”,遂取名ANNOY~(纯属个人遐想,请勿当真)
Annoy算法原理
一个有追求的programmer,除了知道有这么个算法外,一定还想了解一下它背后的原理,所以我花了一天阅读Annoy作者的博客,找到YouTube上一些介绍的视频,配合一些代码一起理解,算是搞懂了Annoy的原理。下面我来简单讲解一下:
(下面的一些图,引自Erik的博客)
首先我们有一大堆点,每个点都是一个向量:
然后,对于一个新的点,我们希望找到它的最近邻。
然而,如果对全局都扫一遍,那复杂度就是 ,这样如果我们的搜索量很大的话就太费劲了。
,这样如果我们的搜索量很大的话就太费劲了。
Annoy的核心思想就是: 把空间分割成一个个的子空间,且在子空间中的点都是彼此间比较接近的。那么对于一个新的点,我们只需要搜索它所在的子空间中的那些点,就可以找到它的近似的最近邻们。
所以,Annoy最终实现的效果是这样的: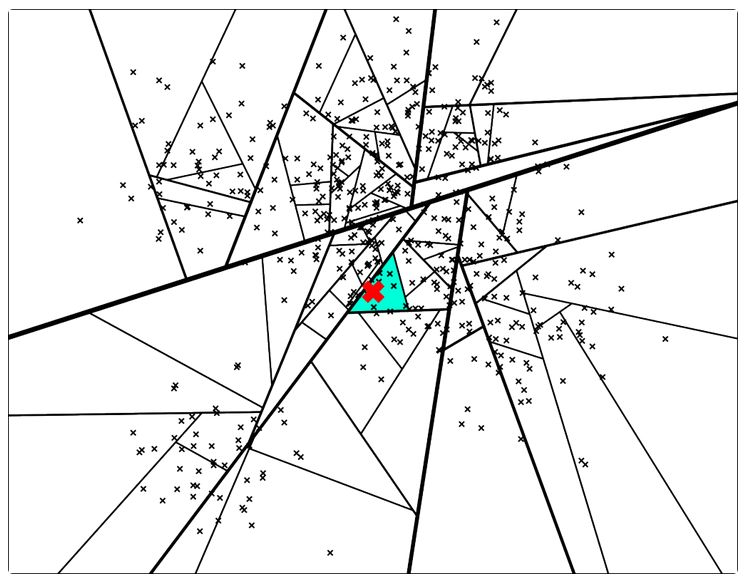
图中红色叉叉就是新的点,整个空间已经被分成了很多个小区域,我们只需要在图中蓝色的那一小块搜索即可,这样,复杂度就大大大大降低了。
关键在于——如何划分空间?
答案是使用随机投影(random projection)来构建二叉树(binary tree)。
回到最开始的散点图,我们先随机挑两个点,这两个点的正中间就确定了一个分割超平面:
这样,就能将空间一分为二,所有的点,就都分配到一个子空间了。
这里可能有人会问,在确定超平面之后,如何把所有点进行区间划分呢?是不是还是得把所有点都计算一遍距离,再确定呢?答案是“是的,我们需要做一个linear scan来确定归属”。为了确认,我查看作者Erik给出的一个示例代码(并非Annoy代码,Annoy使用C++写的,我还看不太明白,但作者为了展示Annoy算法的代码,也用python写了一个简单例子):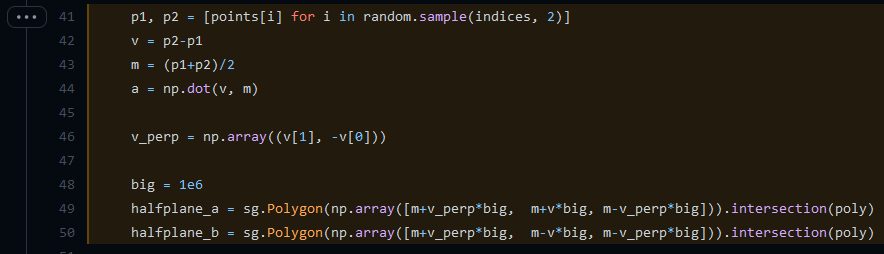
上述代码我画了一个图来表示,应该就很清楚了,所以不再赘述: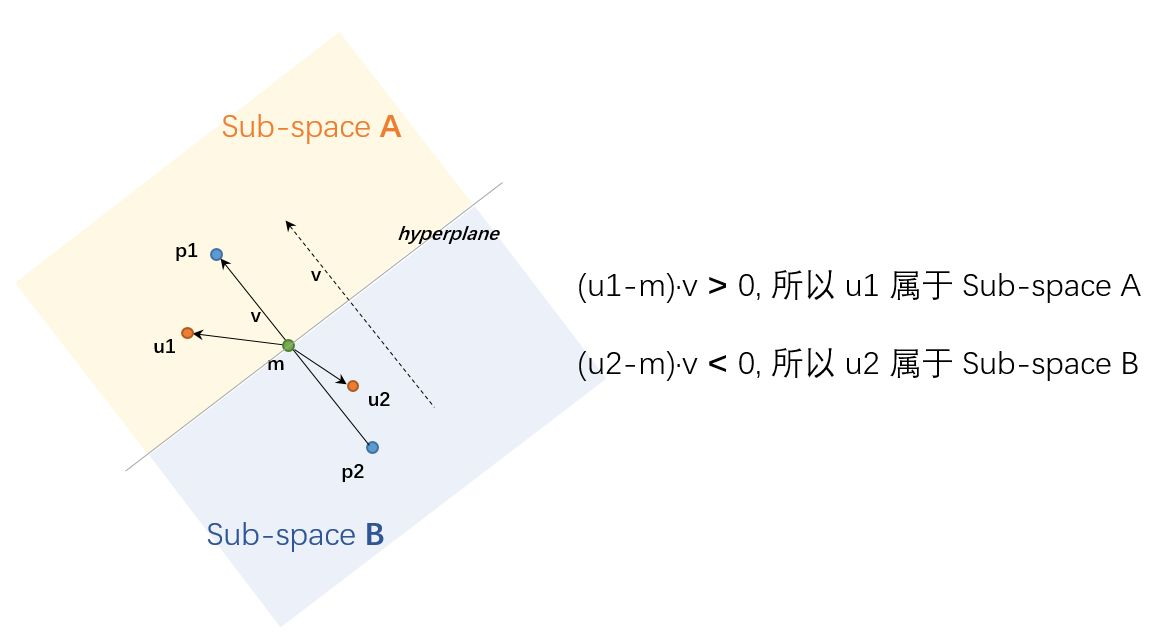
好,接下来我们可以在每个子空间中,都使用类似的方法,继续划分,不断迭代这个过程(可设定一个超参数K,最多迭代K次):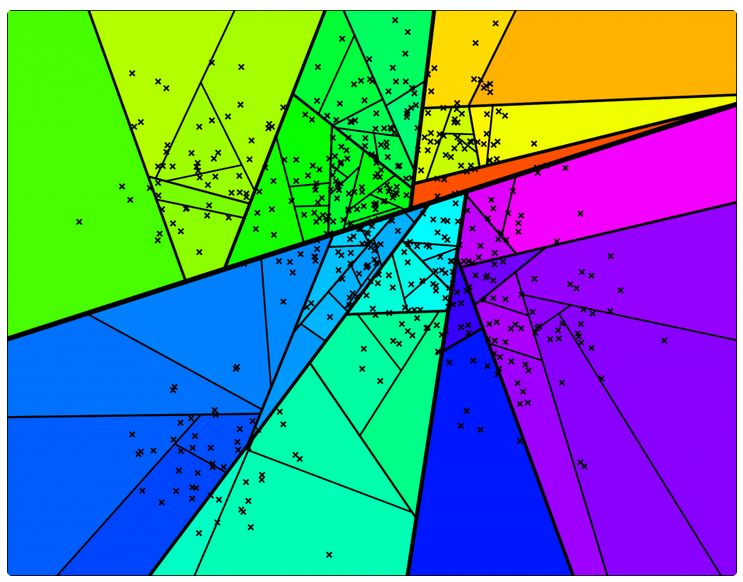
如果我们把每个超平面当做一个树的分支,最终每个小区域中的点当做树的叶子节点,那么就可以得到一下的一棵树: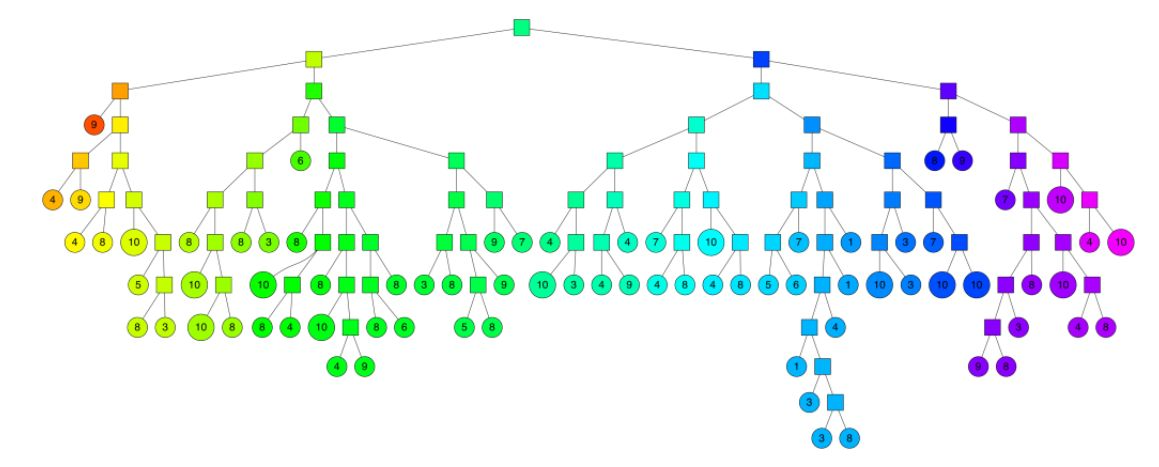
有了这棵树之后,我们想搜索一个点的最近邻,就只用访问这棵树的一个分支即可,即使用上面说的那个确定一个点归属的算法,从root节点一直找到最下面的小分支,然后跟那个分支上的leaf节点逐一计算相似度,就完事儿了: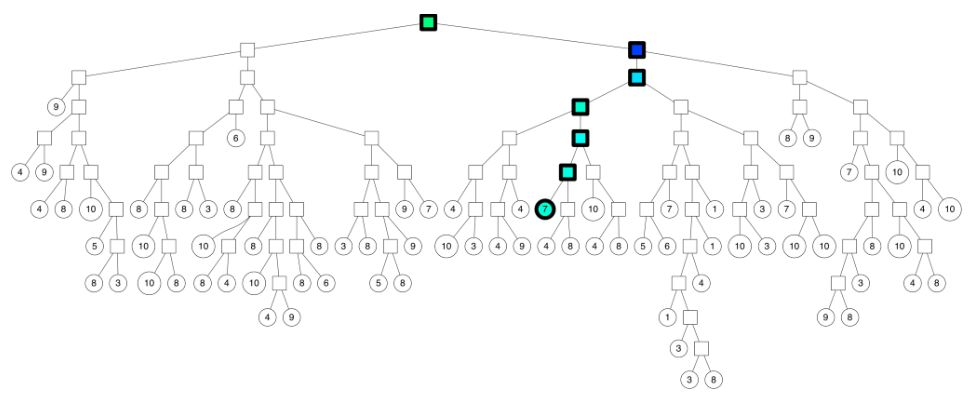
这样,我们就将相似节点查询的复杂度都 降低到了
降低到了 .
.
Annoy的问题
很明显,我们可以知道上述的构件树并查询相似点的方法是不精确的,因为我们发现每个超平面,都是随机挑选两个点来确定的,这就导致很有可能有些相近的点,会被分开,而一旦分开,在树的搜索中很可能就被丢弃了。
一个解决方法就是构建多棵树!形成一个森林!然后把所有树的结果进行平均,或者把所有树找到的最小区域进行合并: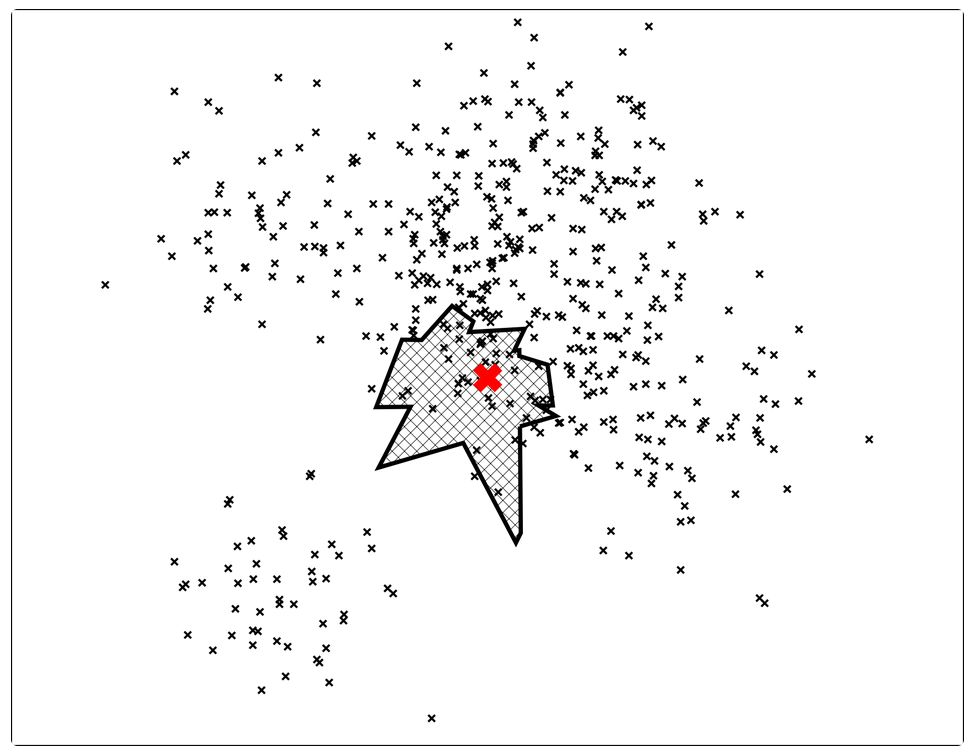
这样,就可以大大提升准确率。当然,还有一些其他技巧,比如使用priority queue等等,这里也不赘述了。
研究了一天,终于把Annoy这优美的算法搞明白了,很是兴奋。晚上,老婆一直睡不着觉,想聊天,于是我绘声绘色地跟她讲解Annoy算法的原理,算法名称的来历,怎么诞生的…… 当我激动地完成了演讲,转头一看,老婆已经呼呼大睡~~
第二天早上,我要求她复述这个算法的基本原理,她说:“Oh Yeah?”
在Gensim中使用Annoy,加速75倍
第三天,在搞懂了原理之后,终于开始动手了。幸运的是,Gensim早就为我们封装好了Annoy工具,所以我们可以直接使用:
from gensim.similarities.annoy import AnnoyIndexerindexer = AnnoyIndexer(w2v_model, 200)similars_dict = {}for w in tqdm(vocab):similar_words = [pair[0] for pair in w2v_model.most_similar(w, topn=15, indexer=indexer)]similars_dict[w] = similar_words
您猜怎么着?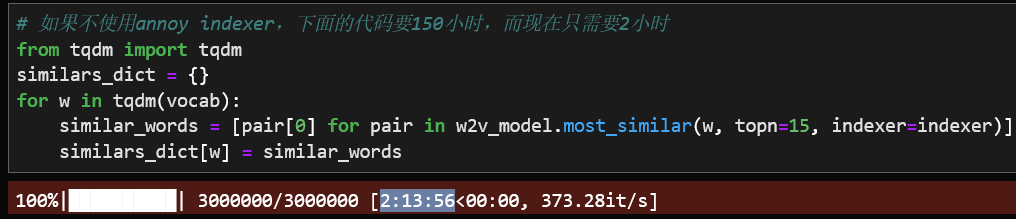
300维向量,300万的词汇量,300万次查询,只要 2小时13分钟!记得在不使用Annoy indexer的情况下,上面代码需要跑150小时!(我们不用去度假啦,健个身代码就跑完啦~)所以这个Annoy足足把速度加速了75倍!
一些细节需要说明:
- 首先需要构造Indexer,这时我们要指定构建多少棵树。上面例子中我构建了200棵,建树时间大概20分钟。树越多,结果越精确,但建树和查询的速度会变慢;
- 我也测试了100或者500棵树,前者的相似度精度不够,后者则太慢(大概30~50小时?)
4. 使用多线程,把CPU榨的一滴不剩
通过上面的方法,我们已经把耗时从150小时缩短到2小时了。
然而,我的CPU们跃跃欲试,说“我们还可以为你做更多”。
注意到,上面的代码中,我是通过for循环来遍历这个长度为300万的vocab词典,而这正好可以通过多线程来进行并发,因此我写下了如下代码: ```python from multiprocessing.dummy import Pool as ThreadPool from logger import logger pool = ThreadPool()
similars_dict = {} def process(w): similar_words = [pair[0] for pair in w2v_model.most_similar(w, topn=15, indexer=indexer)] similars_dict[w] = similar_words c = len(similars_dict) if c % 10000 == 0: logger.info(‘already processed ‘+str(c)+’ items.’)
logger.info(‘start’)
pool.map函数,可以把一个list中的所有item,分配到不同线程并行执行
pool.map(process, vocab) pool.close() pool.join()
这里主要使用到了pool.map(process_for_item, your_list)函数,这个函数可以使用你自定义的process_for_item函数,在多个线程中并行地对your_list中所有item进行处理,非常方便。<br />查看输出:```python[23/Feb/2022 20:11:46] INFO - start[23/Feb/2022 20:11:51] INFO - already processed 10000 items....[23/Feb/2022 20:35:29] INFO - already processed 2990000 items.[23/Feb/2022 20:35:46] INFO - already processed 3000000 items.
总共耗时25分钟!!这是值得铭记的历史的一刻!
至此,我们经历了将150小时,缩短到100小时(多线程),再缩短到2小时(Annoy近似搜索),最终缩短到25分钟(Annoy+多线程),将任务在我的单机上提速了360倍。
其他尝试
其实我还尝试过Faiss框架,使用IndexFlatL2作为quantizer,使用IndexIVFFlat作为indexer,使用nlist = 1000,nprobe = 10,结果对300万个query查询完毕,需要8小时。而且目测的效果,并没有比我前面使用Annoy的结果好,再加上这玩意儿调参困难,所以后面就没有继续尝试Faiss。
根据ANN-benchmark: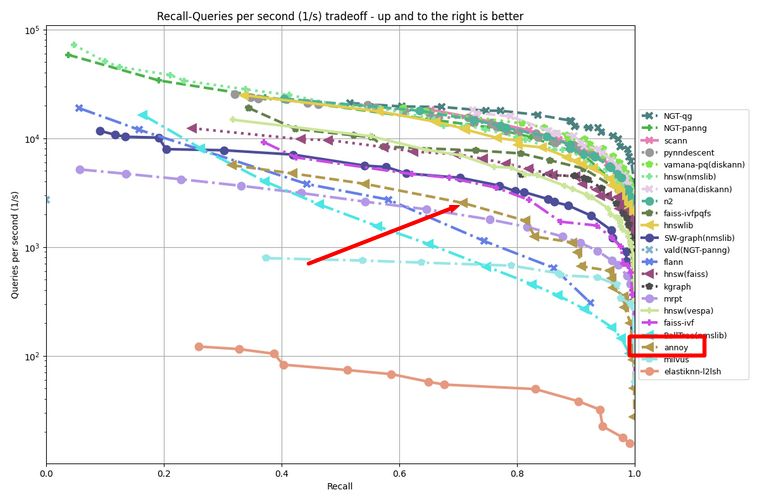
Annoy算法算是一个中规中矩的,还算可以的算法。而Gensim还提供了NMSLIB算法支持,所以有兴趣的同学,可以把Annoy换成NMSLIB看看效果。
后记
—— “如果当初不做改进,让它占着电脑慢慢跑,你现在应该度假还没结束吧~”
—— “也许吧,可能我的假期还有100小时呢,哈哈”
—— “你高兴啥,度假不是更快乐吗?”
—— “那不是真正的快乐!” 我扶着发际线,骄傲的说
—— “… 那你的快乐是什么?”
—— “是我只用25分钟,把.most_similar()给加速了 倍~”
倍~”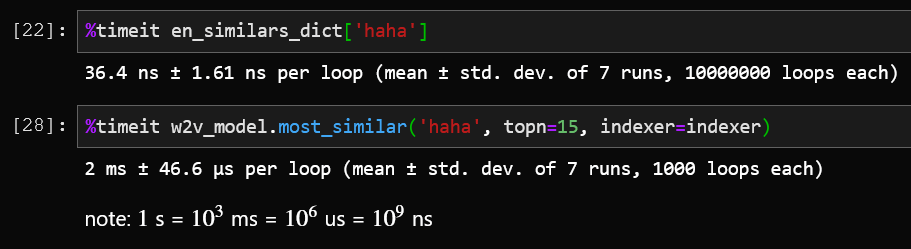
最后,拜谢以下资料,陪我走过这几天:
- Annoy作者博客:https://erikbern.com/2015/10/01/nearest-neighbors-and-vector-models-part-2-how-to-search-in-high-dimensional-spaces.html
- Annoy官方GitHub:https://github.com/spotify/annoy
- gensim上的Annoy支持:https://radimrehurek.com/gensim/similarities/annoy.html
- Ball-tree & KD-tree:https://towardsdatascience.com/tree-algorithms-explained-ball-tree-algorithm-vs-kd-tree-vs-brute-force-9746debcd940 另外Wikipedia上的KD-tree也讲的非常好:https://en.wikipedia.org/wiki/K-d_tree
- Faiss Wiki:https://github.com/facebookresearch/faiss/wiki/Getting-started
- ANN算法benchmark:http://ann-benchmarks.com/index.html#algorithms
- python多线程并行:https://chriskiehl.com/article/parallelism-in-one-line
- Random Projection:https://medium.com/data-science-in-your-pocket/random-projection-for-dimension-reduction-27d2ec7d40cd
- CVPR20上一个关于ANN的分享:https://speakerdeck.com/matsui_528/cvpr20-tutorial-billion-scale-approximate-nearest-neighbor-search?slide=115

若有收获,就点个赞吧
0 人点赞
